はじめに
この記事は アイスタイル Advent Calendar 2023 22日目の記事です。
こんにちは。アイスタイルでショッピングを担当しているtsuboikeと申します。
12月に入っても温かいなぁと思っていたら中旬を越えてから急に冷え込んできました。
寒いと言えば北極。北極と言えばオーロラ。オーロラと言えばAWS。
(ちょっと強引なくらいが丁度いいと思っている昭和世代のためご了承ください)
今回は新システムを構築した中で、既存のAuroraからのデータ連携において、連携数が一時的に多くなる時間帯においてエラーが頻発した事象についての対応を記します。
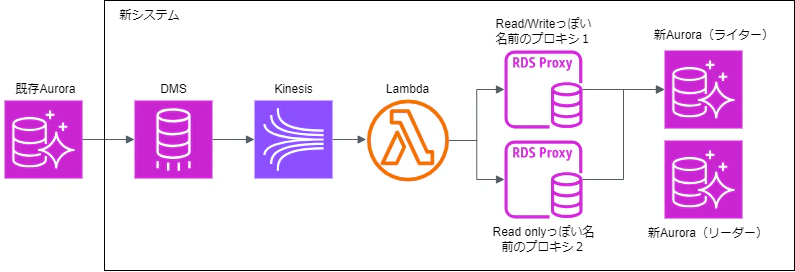
システム構成
- 既存Auroraの更新をDMSで更新を察知し、新Auroraに連携する
【システム構成図】
問題
既存Auroraの更新が多い時間帯で、新AuroraでTimed-out waiting to acquire database connectionエラーが発生していた
エラーの分析
Timed-out waiting to acquire database connection をググってみると公式ドキュメントが見つかりました。
ERROR 9501 (HY000): Timed-out waiting to acquire database connection
プロキシは、データベース接続の取得を待機中にタイムアウトしました。次のような原因が考えられます。
最大接続数に達したため、プロキシはデータベース接続を確立できません
データベースが使用不能であるため、プロキシはデータベース接続を確立できません。
なるほど。
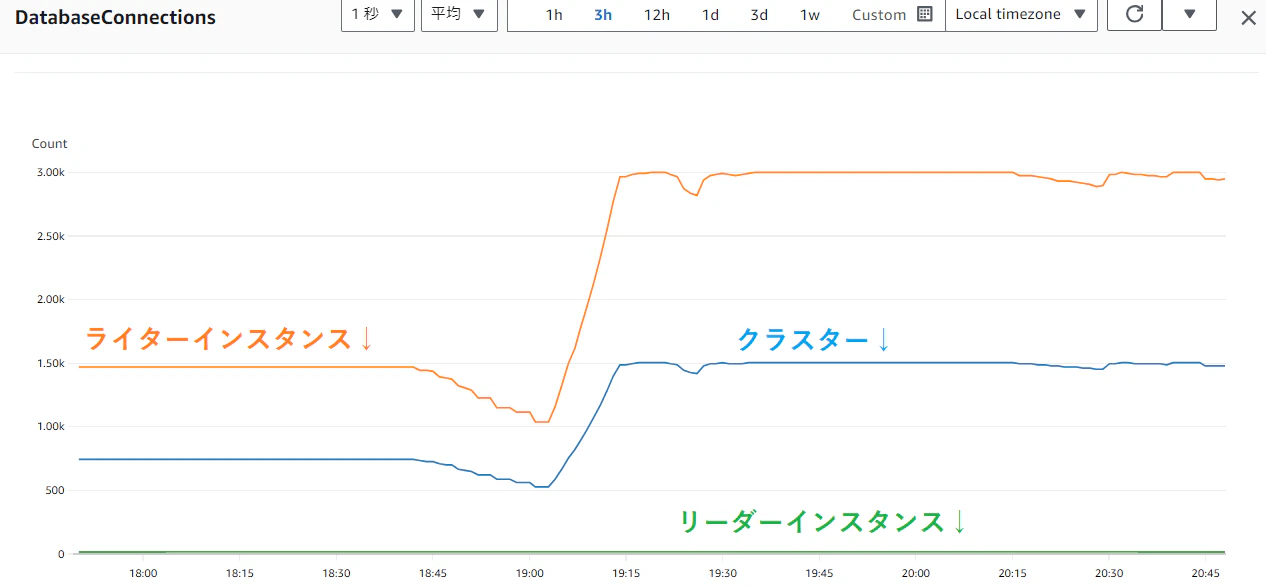
新Aurora(ライターインスタンス)のコネクション数を確認したら max connections(3000) になっていました。
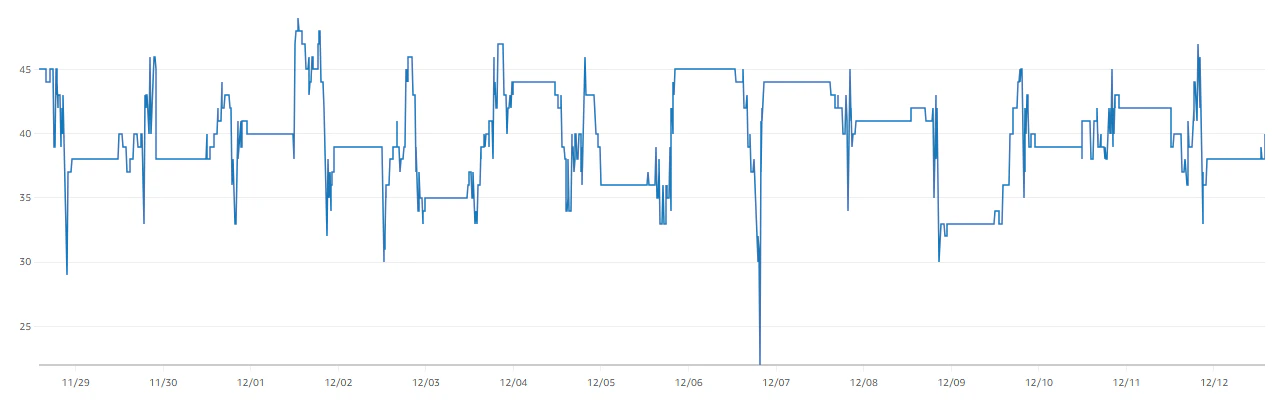
続いて Lambda→新Aurora で使用している2つあるプロキシからの接続数を確認。
【プロキシ1】
【プロキシ2】
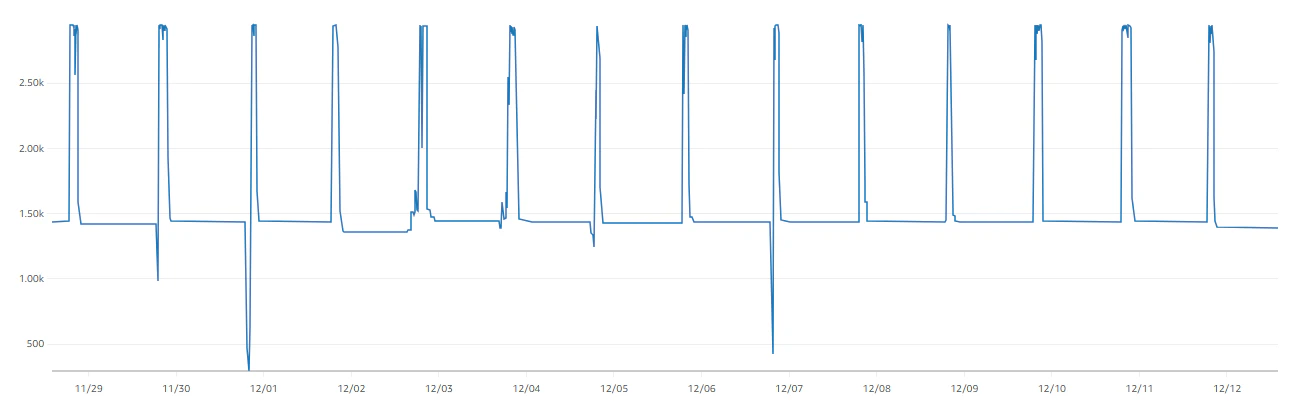
プロキシ2が常時1400コネクションぐらいあったのですが、こちらはコネクションプーリングのため問題無しと判断しました。
そして冒頭のシステム構成図でアレ?と思われた方もいたと思いますが、プロキシ識別子を確認すると、プロキシ1がRead/Write、プロキシ2がReadOnlyっぽい命名だったが、両プロキシとも新Aurora(ライターインスタンス)に繋がっている謎設定。
CPU使用率(CPUUtilization)も念のため確認しましたが、5%程度で問題無かったため、単純にコネクション数の問題の様でした。
改修方針
Lambdaのコードを修正して検証&リリースまで持って行くのは年内に間に合わないため、設定変更でできるところまで改善する。
設定を変更して検証
プロキシの設定を確認した所、プロキシ1、プロキシ2とも「接続プールの最大接続数」が100%(併せると200%)となっており、これが悪さしてるかも?と言う事で新たな設定値を見つけます。
接続プールの最大接続数 - プロキシで使用できる最大接続数の割合 (%) を調整できます。
合計100%にしてしまうとアドホックな接続もできなくなるかもしれないと助言を頂き、2つのプロキシを併せて 90% となるように計算。
- プロキシ1:過去2週間の推移で、MAX50コネクション程度なので倍の100とする
100はmax connections(3000)の 3.3% なので 3% とする - プロキシ2:2つのプロキシを併せて 90% なので、90 - 3 = 87% とする
と、それっぽい数字を出してみたのですが、AWSのユーザーガイドを見たところ下記の推奨値があったため、プロキシ1:20%、プロキシ2:70% としました(算出した意味…)
MaxConnectionsPercent の最小推奨値
○ db.t3.small: 30
○ db.t3.medium またはそれ以上: 20
検証結果
設定を変えて試したところ、エラーが増えてしまいました。。。(変更前の2~3倍)
新Aurora(ライターインスタンス)のコネクション数を確認したらmax connections(3000)に達していなく、プロキシ2の接続数が頭打ちに。。。
ボトルネックがAuroraからプロキシに遷移しただけでした。
設定を戻そう。
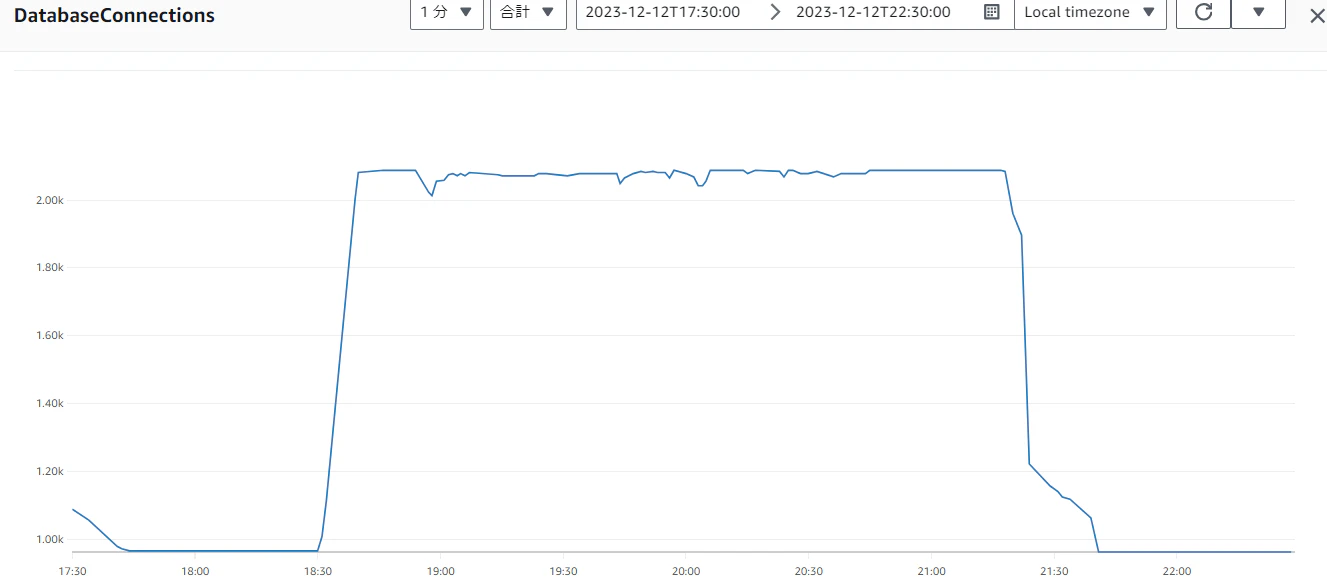
【ライターインスタンスのコネクション数(MAX:2148)】
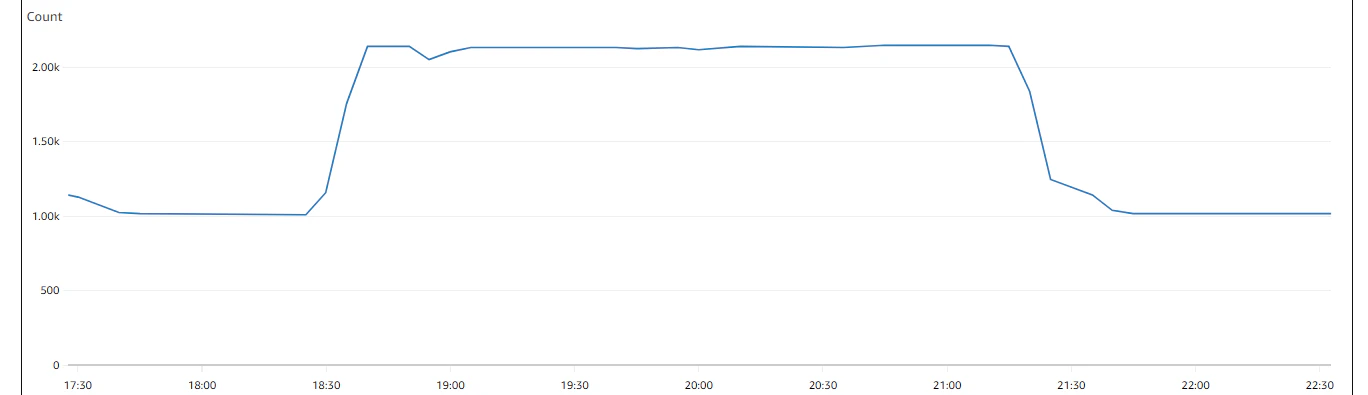
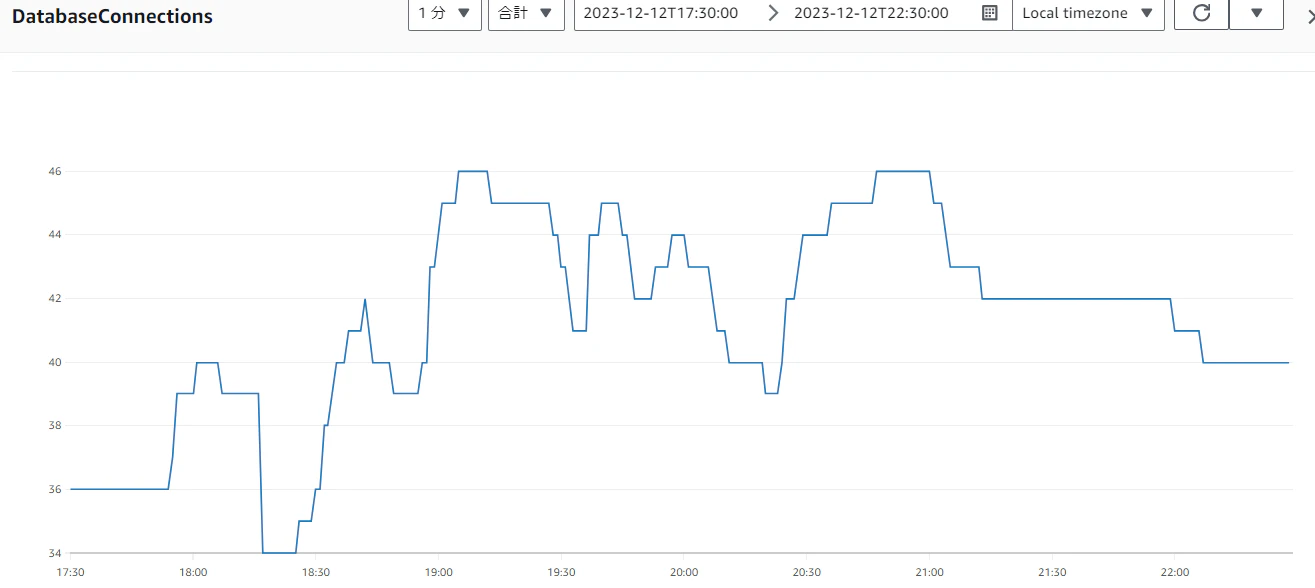
【プロキシ1のコネクション(MAX:46)】
【プロキシ2のコネクション(MAX:2088)】
設定を変更して検証2
コネクション数に関しては一旦保留とし、そもそも 新Aurora にアクセスしてる Lambda のプロセス数が多すぎるんじゃないか疑惑が浮かんできたため、矛先を Lambda へ向け、まずは容疑者の同時実行数を確認してみる。
【Lambdaの同時実行数】
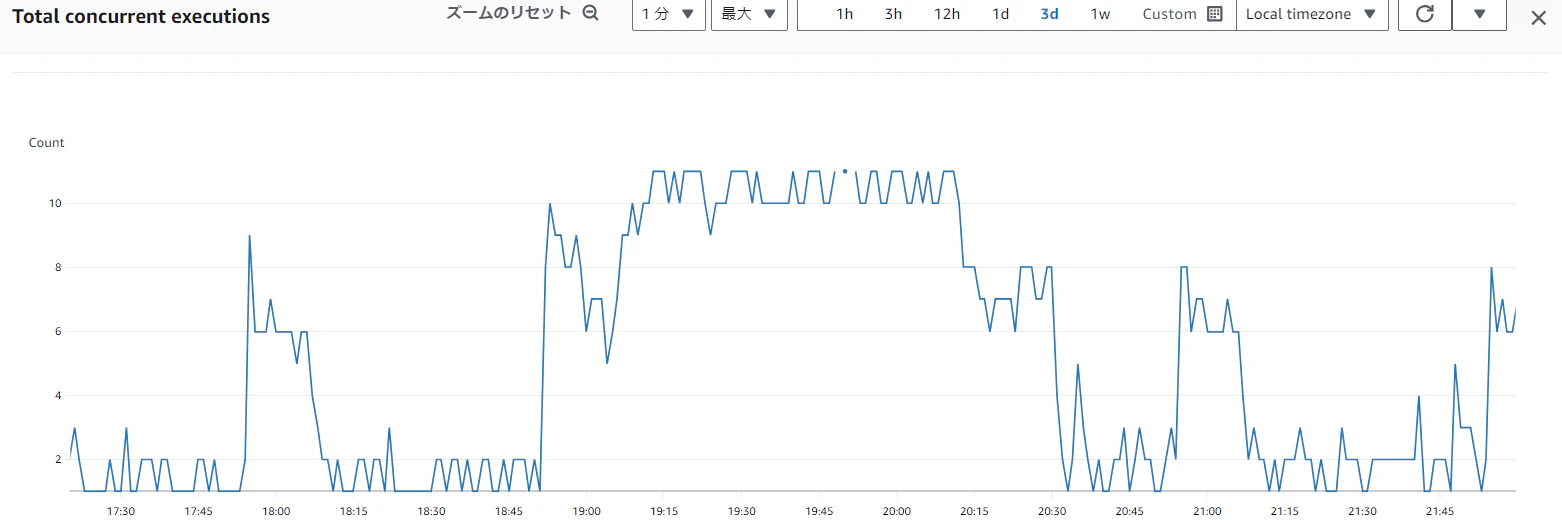
同時実行数11だと!!
。。。
多いのか少ないのか適切なのか分からないけど、8 ぐらいにしてみよう(←謎設定誕生の瞬間)

検証2結果
【Lambdaの同時実行数】

エラーが減りましたー!!
新Auroraのコネクション数を確認した所、max connections(3000) に達してはいましたが、達するまでの時間が伸びていたため、タイムアウト発生までの処理数が増えたためかと思います。
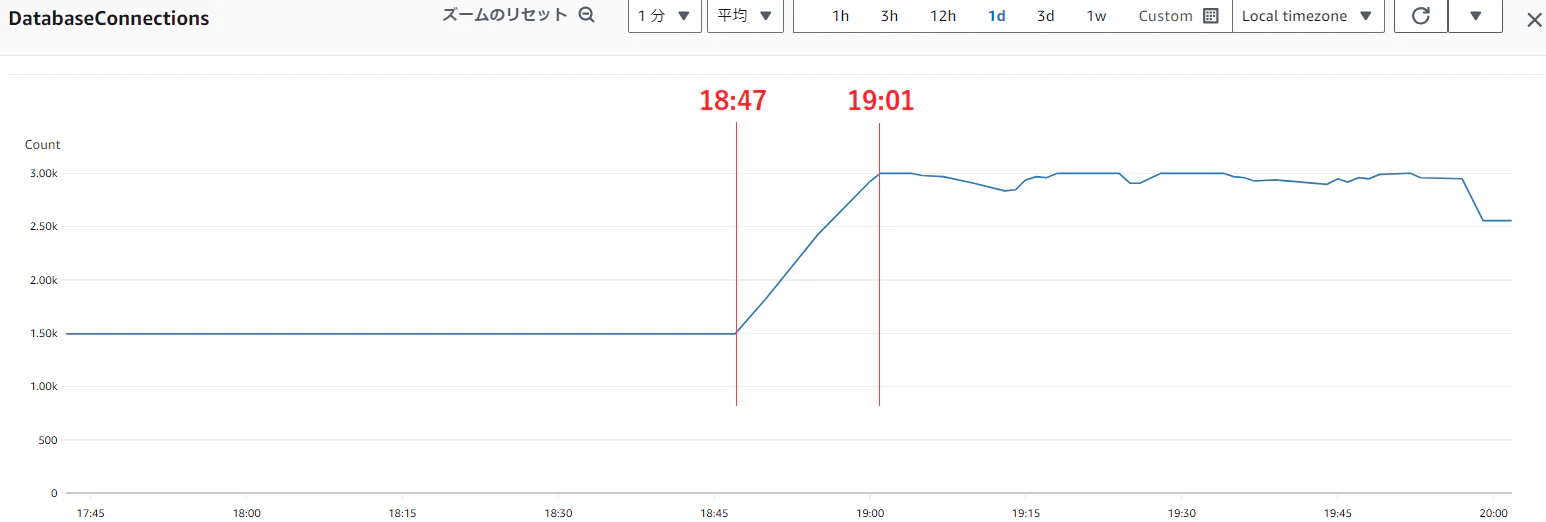
■コネクション数が1500→3000までの時間で比較
【Lambdaの同時実行数が MAX 11 の時:7分】
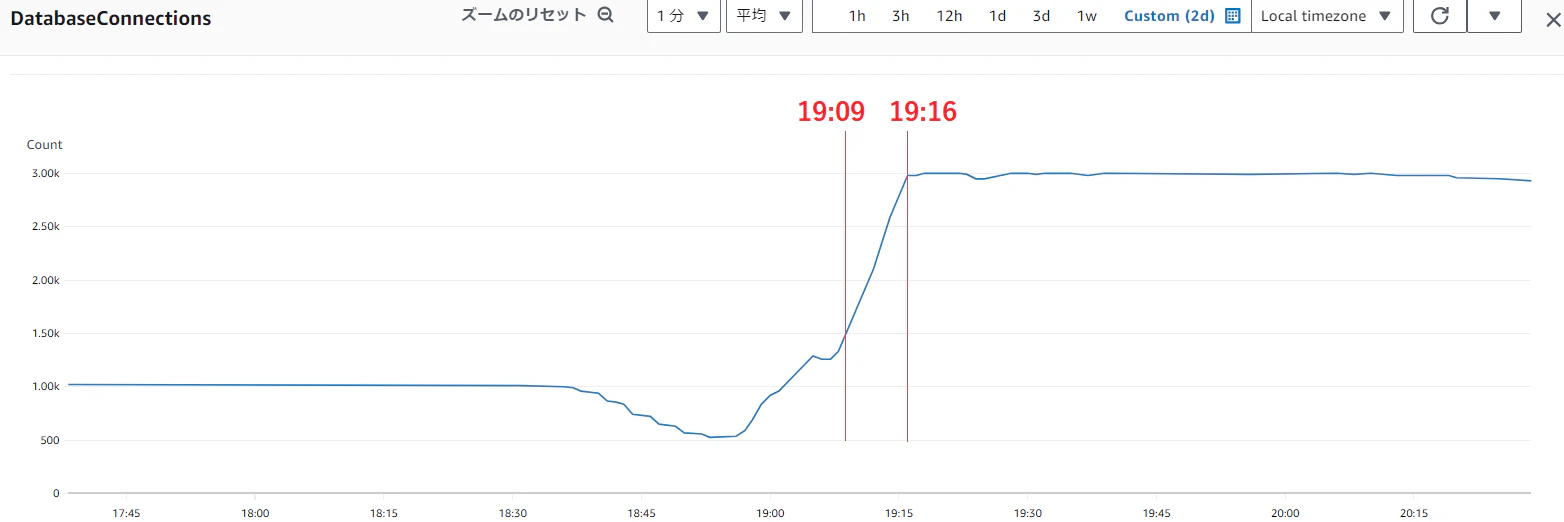
【Lambdaの同時実行数が MAX 8 の時:14分】
よしいいぞ、そうとなればもう少しLambdaの同時実行数を下げてみよう。
次は 6 だっ!!
設定を変更して検証3

検証3結果
Auroraのエラーは少し減った気がするのですが、今度は Lambda の方でタイムアウトが発生している様子。。。
(前に多発していて、Lambda のタイムアウト値を伸ばして消えたはずのエラーが再発しました)
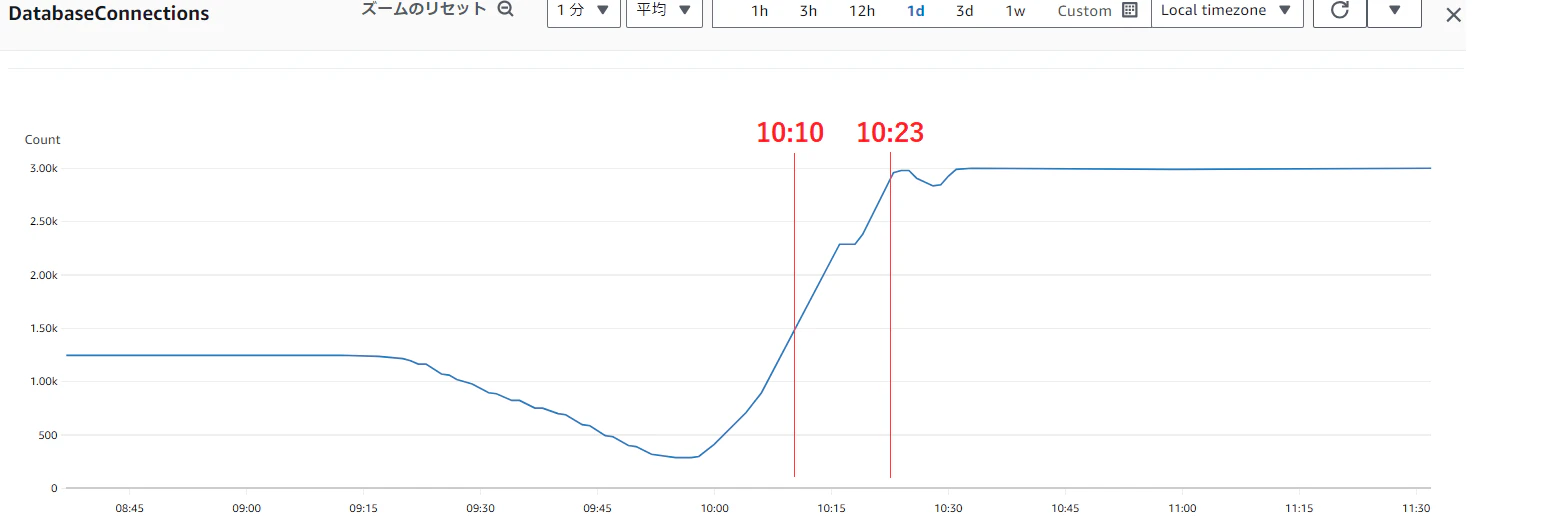
Aurora側の max connection に達するまでの時間も確認しましたが、Lambda同時実行数を 8 とした時と変わらず、同時実行数は 8 で飽和してそうでした。
調子に乗ってごめんなさい。
【Lambdaの同時実行数が MAX 6 の時:13分】
今回の考察
- Lambdaからのアクセスに対してAurora側が追い付けていない
- AuroraのCPU使用率は1ケタ台のため、単純にコネクション数が多い
- Lambdaの同時起動数を下げたことで暫定的にエラー数は減ったが根本解決ではない
- Lambdaの同時起動数を下げると、今度はLambdaの方でジョブが溜まってしまう
- 引き続き根本解決に向けて下記の確認を進める
- Lambdaのコード確認(Read/Write、ReadOnlyの制御が正しくされているか)
- ReadOnlyっぽい命名のプロキシ2をリーダーインスタンスに接続したい
- Lambdaの同時実行数 8 が丁度良いというエビデンスを探る(謎設定を後世に残さないため)
最後に
今回は問題解決までに至らなかったですが、スッキリとした気持ちのよい年越しを迎えるため、さらなる改善をしていきたいと思います。
しかし気持ち的には正月休み。心ここにあらずの状態でどこまで行けるかは神のみぞ知る
それでは皆様、少し早いですがメリークリスマス&良いお年を!!