遅くなりましてすみません。22日め担当の @tsubasaogawa です。普段は顧客・課金系のシステムをいじっています。
さてクリスマスが目前と迫った今日この頃、諸兄はいかがお過ごしでしょうか。
仕事に追われる毎日、疲れ果てて家に返っても一人、でも強がって「ただいま」なんて言ってみたりしたものの、流れる静寂が余計に疲れを誘う、そんな方に朗報です。
おかえり彼女
このわざとらしい流れでもうお分かりかもしれませんが、今回ご紹介するのは『「ただいま」に彼女っぽい声で「おかえり」と返してくれるプログラム』です。
また、不慮の事故1 2を未然に防ぐため話者認識も行い、見知らぬ人への「おかえり」の暴発を止めます。
システム概要
開発環境
- Windows 10
- MinGW32 4.2.0 + MSYS 1.0
- Julius 4.4.1
- Chainer 1.16.0
- ほか cuDNN, CUDA, Anaconda など必要に応じて
構成
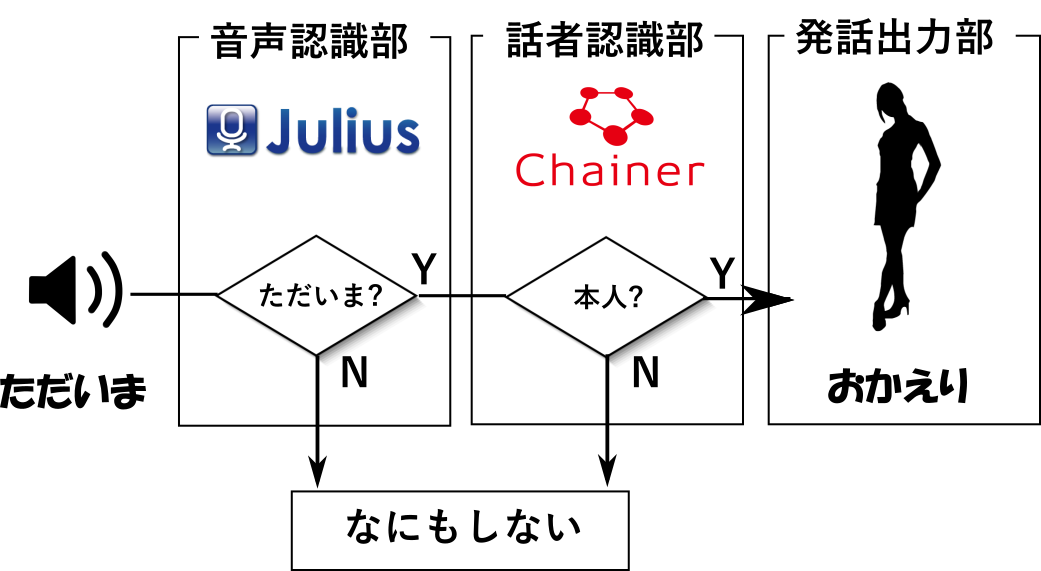
入力された音声は、OSS の音声認識ソフト Julius に渡され、音声認識されます。
認識結果が期待された文字列 (= ただいま) であった場合、後続処理として話者認識が行われます。
話者も本人だろうと認識されてはじめて、「おかえり」と再生してくれる仕組みです。
使う
ソースは GitHub に上げてあります。
別途以下準備が必要です。
- Julius 最新版のコンパイル + インストール
- ディクテーションキットも
- Chainer のインストール
- 「おかえり」の音声ファイル
実行については、okaeri ディレクトリにて
[Julius のバイナリ] -C [ディクテーションキットのディレクトリ]/main.jconf -C [ディク(ry]/am-gmm.jconf -nolog -quiet -plugindir .
と打ち込んでください。あとはマイクに話せば動くはず。
ポイント
音声認識部
Julius ライブラリとして動かす
Julius を自作アプリケーションで利用する場合、主に2通りの方法があります。
- モジュールモードで Julius を動かし、自作アプリと通信させる
- 自作アプリを Julius のライブラリとして動かす
前者の「モジュールモード」は、Julius が指定ポートで音声入力の通信を待ち、認識結果をクライアントへ返すモードです。
いわゆるサーバ-クライアント型のアプリケーションを容易に構築できる点がメリットです。
逆にデメリットとしては、後述のライブラリで動かす場合よりも認識結果として得られる情報が少ないという点です。
一方、後者の「ライブラリ」です。
自作アプリを jpi ファイルにコンパイルし、Julius 起動時に -plugindir オプションでライブラリのディレクトリを指定することで読み込まれます。
基本的にC言語で書かれているためコーディングがめんどいという点がネックですが、その分音声認識に必要な特徴量や認識結果などの情報を細かく得ることができます。これらは Recog というJulius の構造体にアクセスすることで得られます。参考: http://www.sp.nitech.ac.jp/~ri/julius-dev/doxygen/julius/4.1.2/ja/struct____Recog____.html
今回はC言語が書きたかった音声認識で用いる特徴量を話者認識にも流用したかっため、ライブラリ化を選択しました。
話者認識部
MFCC (Mel Frequency Cepstrum Coefficients)
モデルは一般的な3層の畳み込みニューラルネットワークです。入力は 25 次元で、MFCC (とその微分) 24次元 + パワーを用いています。
MFCC は、噛み砕いて言うと「ヒトの耳に最適化された音声の特徴集合」です。人間がどこを重視して音声を聞き分けているのか、というコツを予め伝授されたパラメータのようなイメージです。(わかりづらい)
MFCC について詳しく知りたい方は http://speechresearch.fiw-web.net/66.html をご覧ください。
この MFCC をイチから算出するのは骨が折れるので、Julius が予め音声認識で利用したものを流用することで計算量の削減を図っています。
また、真面目に話者認識をしようとするともはや学術研究レベルなので、精度を求めるのであれば MFCC に甘えるだけでなく様々な工夫が必要です。
一方で MFCC の持つポテンシャルは大きく、単独での利用でもそれなりの判別ができるという報告もあります: https://www.ieice.org/iss/jpn/Publications/issposter_2015/data/pdf/ISS-P-35.pdf 。
学習データ
本タスクは「自分の声」と「他人の声」を識別させたいため、学習データとして「自分のただいまデータ」と「他人のただいまデータ」が必要になります。
まずは「自分のただいまデータ」ですが、一人でマイクに向かって「ただいま」を100回録音しました。50回目ほどで時の流れが急激に遅くなり、心身的苦痛も生じ始めましたがなんとか完遂です。
問題は「他人のただいまデータ」です。当初は「このご時世、ネットで検索すればたくさん見つかるだろう」と思っていたけど甘かった。自分の検索が足りないだけかもしれませんが現時点ではチャン・グンソクの「ただいま」しか見つけられませんでした。しかも謎の効果音が入ってて地味に使いづらい…!
仕方ないので「ただいま」以外の音声でも良いことにします。あたりを見回した際に使えそうだと思ったのが「グループ魂」の名盤: 嫁とロックに収録のコミックソング2曲です。楽器の音はなく、メンバーによるコントが収録されています。このシュールな音声をひたすら Julius (と自作プラグイン) に聞かせるという作業を行いました。
結果、200 サンプルほどの「他人」の音声データを得られました。
発話部
音声認識による判定、話者認識による判定をそれぞれかいくぐることができればいよいよ「おかえり」の音声が聴けます。
ここで、汎用的なシステムにしたい、つまり「おかえり」以外も将来的に喋らせたい場合は音声合成で「おかえり」を合成すると良いでしょう。
しかし、今回は手を抜きたい「おかえり」に特化したモノを作りたい、音声合成の無機的な「おかえり」はイヤだ、ということで「声優さんによる wav ファイルを再生する」という手法を選択しました。
ダウンロード元は http://materializer.co/maya/2838/ です。幾つかバージョンがあったので「優しいお姉さん Ver.」を選択しました。
※あとあと気づいたけど、上記サイトで落とせる音声も実は音声合成のモノだった…!!
実行結果例
$ ../julius -C ../dictation-kit-v4.4/main.jconf -C ../dictation-kit-v4.4/am-gmm.jconf -plugindir . -nolog -quiet
STAT: include config: ../dictation-kit-v4.4/main.jconf
STAT: include config: ../dictation-kit-v4.4/am-gmm.jconf
STAT: loading plugins at ".":
STAT: file: okaeri_kanojo.jpi #0 [Okaeri Kanojo]
STAT: 1 files loaded
sentence1: たとえば 。
pass1_best: たとえば 。
okaeri_kanojo: tadaima recognized
# test-file: test/test_20161223_094920.csv
okaeri_kanojo: classification: label= 0 predict= 0
okaeri_kanojo: classification: okaeried
pass1_best: たぶん 。
sentence1: ただいま 。
pass1_best: など に も 。
sentence1: ただ M 。
okaeri_kanojo: tadaima recognized
# test-file: test/test_20161223_094926.csv
okaeri_kanojo: classification: label= 0 predict= 0
okaeri_kanojo: classification: okaeried
pass1_best: ただいま 。
sentence1: ただいま 。
okaeri_kanojo: tadaima recognized
# test-file: test/test_20161223_094943.csv
okaeri_kanojo: classification: label= 0 predict= 1
pass1_best: うん 。
sentence1: ただいま 。
Julius にて「ただいま」が認識されると tadaima recognized と出力されます。
その後話者認識が走って、分類に成功する (label = predict = 0) と okaeried となります。
何回か「ただいま」と喋って試したところ、だいたい5割ほどの戦績かなあ…という印象です。
そもそもの音声認識間違いがあったり(ただMってなんだ)、一番下の「ただいま」では話者認識に失敗してたりしてます。
なお、pass1_best は、pass1 = 速度重視で導き出した認識結果なのでここでは無視してください。(Julius 本体のコードに手を出さないとおそらく消せないはず。。 )
課題
精度
- 音声認識間違いについては、専用の言語モデル/記述文法等を用意すれば改善できるはずです。
- 話者認識の間違いは、以下あたりが課題なのかなと感じています。
- 学習データのボリューム不足
- 学習データの正規化が必要
- MFCC だけでは足りない?
- より話者識別に有用な特徴量 (ピッチなど) の追加
処理速度
私のマシンでは「ただいま」と喋ってから「おかえり」と返答してくれるまで2秒ほどのラグが生じました。
話者認識部分で主に時間がかかっているようです。
特にラズパイなどの非力なマシンで実装する場合、実現は厳しいです。
小型デバイスに対するさらなる性能アップへ期待します。
明日は @ysaotome さんです。お楽しみに!!