概要
目的
summoのwebサイトの物件から、最新でお得な賃貸物件を抽出したい。
背景
不動産のサイトのみでは、条件に対する家賃が高いのか安いのか感覚でしか判断出来ないと、日々感じていました。そこで、様々な賃貸情報から家賃の相場を予測することで、数値的にその物件の価値を図ることが出来ると思いました。
内容
suumoのWebサイトから、住宅情報をスクレイピングして、DataFrameとしてデータを収集する。そのうえで、よりお得な物件を抽出すること。
今回は記事を3つに分けて、投稿します。
第1章:suumoのWebサイトから住宅情報をスクレイピング
第2章:GCPを用いた住宅情報をスクレイピングと、賃貸物件価格予測を自動化
第3章:Straemlitを用いた賃貸物件のWebアプリAPI作成
上記のような構成で考えています。
今回の第1章では、JupyterLabでのローカル環境で賃貸情報をスクレイピングしたいと思います。
実装の流れと内容
1. suumoのサイトからHTMLを把握する。
具体的な操作
- suumoのWebサイトで地区、駅などで条件を選択して、下記のページを開く
- 右クリックで、「ページのソースを開く」をクリック
●jupyterlabを開き下記のライブラリをインポート
from bs4 import BeautifulSoup
import urllib3
import re
import requests
import time
import pandas as pd
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
from sklearn import preprocessing
#探索的データ解析
import pandas_profiling as pdp
pd.set_option('display.max_columns',50)
pd.set_option('display.max_rows',100)
import warnings
warnings.simplefilter('ignore')
%matplotlib inline
import matplotlib.pyplot as plt
import japanize_matplotlib
import lightgbm as lgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
スクレイピングを実行する関数を作成
●建物名','最寄り駅','家賃','間取り','建築年','住所'などのリストを作る。
●BeautifulSoup()"メソッドを用いてHTMLドキュメントを解析して、特定の要素を抽出する。
●「本日の新着」「新着」タグを抽出して、リストとして保存する。テーブルに追加
実際にはひとつの関数で表現したので下記参照
私なりに細かく1行ずつにコードの説明を入れたので、読みやすくはなってると思います!
# スクレイピングの開始点のURL
## 今回は押上駅周辺の物件をスクレイピング
url = "https://suumo.jp/jj/chintai/ichiran/FR301FC005/?ar=030&bs=040&ra=013&rn=0045&ek=004506820&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&po2=99&pc=100"
# スクレイピングを実行する関数
def suumo_scraping():
name = []
station = []
price = []
sikikinreikin = []
room = []
age = []
address = []
count_new_list = []
urls=requests.get(url)
# 連続してアクセスするのを防ぐために3秒待つ
time.sleep(3)
#urls.encodingは、サイトの文字コードを表す文字列を返す。
#urls.apparent_encodingを使って、文字コードが正しく設定されていない場合に、自動的に正しい文字コードを設定するために使用
urls.encoding = urls.apparent_encoding
#、指定したURLから取得したHTMLドキュメントを解析し、特定の要素を抽出する
soup=BeautifulSoup()
#BeautifulSoupを使って、URLから取得したHTMLコンテンツを解析して、パース可能なオブジェクトを作成
#第一引数には、解析したいHTMLのコンテンツが含まれた文字列を渡し、第二引数には、使用する解析器を指定します。ここでは、"html.parser"
soup=BeautifulSoup(urls.content,"html.parser")
#soupオブジェクトから、"ol"タグでclass属性が"pagination-parts"である要素を抽出
get_url = soup.find("ol",class_="pagination-parts")
# 物件のページ数を取得
# 指定したHTMLドキュメントから"li"タグのテキストを抽出し、リストに格納
num_list =[]
for i in get_url.find_all("li"): #get_urlというオブジェクトから、"li"タグのすべての要素を検索
num_list.append(i.text) #append()メソッドは、リストの最後に指定された値を追加するために使用されます。
#ここでは、i.textをnum_listに追加しています。i.textは、i要素内に含まれるテキストを表している。
num = int(num_list[10]) + 1 #リストnum_listの11番目の要素を取得し、整数値に変換してから1を足している。これにより、取得したページ数に1を加えた値がnumに格納される。
# ページ数分だけスクレイピングを実行
for p in range(1,num):
page=str(p)
url_2="https://suumo.jp/jj/chintai/ichiran/FR301FC005/?ar=030&bs=040&ra=013&rn=0045&ek=004506820&cb=0.0&ct=9999999&mb=0&mt=9999999&et=9999999&cn=9999999&shkr1=03&shkr2=03&shkr3=03&shkr4=03&sngz=&po1=09&po2=99&pc=100" + "&page=" + page
urls=requests.get(url_2) #requests.get()関数を使用してHTMLデータを取得
# 連続してアクセスするのを防ぐために3秒待つ
time.sleep(3)
soup=BeautifulSoup(urls.content,"html.parser")
# 「本日の新着」「新着」のタグを検索
#soupのHTML内から「class="ellipse_pct ellipse_pct--red"」というクラスを持つ「<span>」タグを探し,
#この「<span>」タグには、「本日の新着」という文言が含まれており、それを表すために使われています。このコードが見つけたすべての「<span>」タグは、リストとして変数「house_info」に格納
house_info = soup.find_all("span",class_="ellipse_pct ellipse_pct--red")
# 「本日の新着」「新着」のタグの中で「本日の新着」の数をカウント
#各ページにおいて「本日の新着」の件数を数えて、リストとして保存
count_new = 0
for i in house_info: #前のコードで取得した「<span>」タグのリスト「house_info」をループ処理
if i.text == "本日の新着": #その中に含まれるテキストが「本日の新着」である場合に、変数「count_new」を1つ増やす。
count_new += 1
count_new_list.append(count_new) #各ページにおいて「本日の新着」が何件あるかをカウントし、「count_new_list」リストに追加
# ページ内の「本日の新着」の数が0でないならスクレイピングを実行
if count_new != 0:
#'<a>'タグの中から、classが"js-cassetLinkHref"であるものを所得
house_name = soup.find_all("a",class_="js-cassetLinkHref")
#最寄り駅の名前の取得
#<div>タグの中から、styleがfont-weight:boldであるものをすべて取得
station_name = soup.find_all("div",style="font-weight:bold")
#'urls'からテーブルをスクレイピング
table_data = pd.read_html(urls.content)
#スクレイピングした情報をリストに追加
#house_nameとstation_nameは、それぞれ物件名と最寄り駅名が含まれるタグを取得
for h in house_name:
name.append(h.text)
for s in station_name:
station.append(s.text)
#物件情報の取得
for i in range(0,count_new):
#table_dataには、物件の価格、間取り、築年数、住所、敷金・礼金などがテーブル形式で格納
table = table_data[i]
#最初のテーブルの最初の行の最初の列に格納された価格をpriceリストに追加
price.append(table.iloc[0,0])
room.append(table.iloc[0,2])
age.append(table.iloc[0,3])
address.append(table.iloc[0,4])
sikikinreikin.append(table.iloc[0,1])
# ページ内の「本日の新着」が0ならスクレイピングをやめる
else:
break
#スクレイピングした情報をリストにまとめて返す
return name, station, price, sikikinreikin, room, age, address, count_new_list
2.前処理を実行する関数
スクレイピングの際に余計な空白等がついてくるのでここで除去する
preprocessingの定義。suumo_scraping関数によって、取得したデータが格納されている
下記にコードの詳細
#preprocessingの定義。
def preprocessing(name, station, price, sikikinreikin, room, age, address, count_new_list):
station_line_list = []
time_move_list = []
#stationリストから「駅名」と「路線名と所要時間」を分離し、それぞれstation_line_listとtime_move_listに追加
for i in station:
#split()メソッドを用いて、各駅名を空白で分割し、その結果得られるリストの0番目を路線名
station_line_list.append(i.split(" ")[0])
#1番目を所要時間として、それぞれstation_line_listとtime_move_listに追加
time_move_list.append(i.split(" ")[1])
station_list = []
line_list = []
for i in station_line_list:
#station_line_listリストには、駅名と路線名が"/"でつながった文字列が格納されているため、まずはsplit()関数を使って"/"で分割し、駅名と路線名のリストを作成
#、駅名と路線名をそれぞれappend()関数でstation_listとline_listに格納
station_list.append(i.split("/")[1])
line_list.append(i.split("/")[0])
move_list =[]
time_list = []
for i in time_move_list:
#time_move_list の要素をループで取り出して、文字列中に "歩" が含まれる場合は move_list に徒歩を追加
if "歩" in i:
move_list.append("徒歩")
#移動時間に含まれる非数字の文字を除去するため、re.sub(r"\D", "", i) を使って、time_list に数値だけを追加
time_list.append(re.sub(r"\D", "", i))
#それ以外の場合は "バス" を追加
else:
move_list.append("バス")
time_list.append(re.sub(r"\D", "", i))
df=pd.DataFrame()
#それぞれのリストに各列を追加する。
df["station"] = pd.Series(station_list)
df["line"] = pd.Series(line_list)
df["move"] = pd.Series(move_list)
df["time_to_station_min"] = pd.Series(time_list).astype(float)
#家賃と管理費をそれぞれ抜き出し、価格リストと管理費リストを作成するための処理
price_list = []
admin_list = []
for i in price: #変数priceには、スクレイピングした不動産情報から取得した文字列型の価格情報がリストとして格納されている
#priceリストから各要素を取り出して、スペースで分割した後に家賃と管理費を抜き出して、price_listとadmin_listに追加
price_list.append(i.split(" ")[0].replace("万円",""))
admin_list.append(i.split(" ")[3].replace("円",""))
admin_fee_list = []
#物件の管理費用を管理費用のリストから取得
for i in admin_list: #admin_list リストの要素を一つずつ取り出し、i という名前で参照
#i が "-" であれば、管理費用が存在しないと判断し、admin_fee_list に "0" を追加
if i == "-":
admin_fee_list.append("0")
#i が "-" 以外であれば、管理費用が存在し、その値をadmin_fee_list に追加
else:
admin_fee_list.append(i)
df["price_10k"] = pd.Series(price_list).astype(float)
df["admin_fee"] = pd.Series(admin_fee_list).astype(float)
sikikin_pre = []
reikin_pre = []
deposit_pre = []
sikibiki_pre = []
#i.split(" ")[0]で敷金の金額を、i.split(" ")[2]で礼金の金額を、
#i.split(" ")[4]で敷引きの金額を、i.split(" ")[6]で敷引き以外の償却費の金額を取り出す
for i in sikikinreikin:
sikikin_pre.append(i.split(" ")[0])
reikin_pre.append(i.split(" ")[2])
deposit_pre.append(i.split(" ")[4])
sikibiki_pre.append(i.split(" ")[6])
sikikin_list = []
reikin_list = []
deposit_list = []
sikibiki_list = []
for i in sikikin_pre:
a = i.split("敷")[1]
#万円で表されている場合は、万円の部分を除いて数値のみを残し、万円で表されていない場合は、0として扱い
if "万円" in a:
sikikin_list.append(a.replace("万円",""))
else:
sikikin_list.append(0)
for i in reikin_pre:
a = i.split('礼')[1]
if "万円" in a:
reikin_list.append(a.replace("万円",""))
else:
reikin_list.append(0)
for i in deposit_pre: #保証金
a = i.split('\xa0')[1]
if "万円" in a:
deposit_list.append(a.replace("万円",""))
else:
deposit_list.append(0)
for i in sikibiki_pre: #敷引き
a = i.split("\xa0")[1]
if "万円" in a:
sikibiki_list.append(a.replace("万円",""))
elif "-" in a:
sikibiki_list.append(0)
else:
sikibiki_list.append("実費")
df["sikikin_10k"] = pd.Series(sikikin_list).astype(float)
df["reikin_10k"] = pd.Series(reikin_list).astype(float)
df["deposit_10k"] = pd.Series(deposit_list).astype(float)
df["sikibiki_10k"] = pd.Series(sikibiki_list)
room_list = []
area_pre = []
direction_pre = []
for i in room:
room_list.append(i.split(" ")[0])
area_pre.append(i.split(" ")[2])
direction_pre.append(i.split(" ")[4])
area_list = []
for i in area_pre:
area_list.append(i.replace("m2",""))
df["room"] = pd.Series(room_list)
df["area_m2"] = pd.Series(area_list)
df["direction"] = pd.Series(direction_pre)
type_list = []
age_pre = []
for i in age:
type_list.append(i.split(" ")[0])
age_pre.append(i.split(" ")[2])
age_list = []
for i in age_pre:
if i == "新築":
age_list.append(0)
else:
age_list.append(re.sub(r"\D", "", i))
df["type"] = pd.Series(type_list)
df["age_year"] = pd.Series(age_list).astype(float)
df["scraping_date"] = datetime.date.today()
df["name"] = pd.Series(name)
df["address"] = pd.Series(address)
id_range = 0
for i in count_new_list:
id_range = i + id_range
#現在の日付からID番号のリストを作成する
id_list = []
#datetime.date.today()を使って、現在の日付を取得
to_day = str(datetime.date.today())
#日付の文字列を作成するために、"-"を削除
to_day = to_day.replace("-","")
#id_range回繰り返しを行い、iを文字列に変換してID番号を生成
for i in range(0,id_range):
if i < 10:
i = str(i)
id_list.append(to_day + "000" + i)
elif i >= 10 and i < 100:
i = str(i)
id_list.append(to_day + "00" + i)
elif i >= 100 and i < 1000:
i = str(i)
id_list.append(to_day + "0" + i)
else:
i = str(i)
id_list.append(to_day + i)
df["scraping_id"] = pd.Series(id_list)
#dfを作成
df = df.reindex(columns=["scraping_id","scraping_date","name","price_10k","age_year","admin_fee","sikikin_10k","reikin_10k","deposit_10k","sikibiki_10k","line","station","move","time_to_station_min","room","area_m2","direction","type","address"])
# 最後のページのスクレイピングでは「本日の新着」以外のデータも混ざっている
# pd.read_html(urls.content)で取得した賃貸価格など
# それ以外で取得した物件名などは「本日の新着」分のデータしか取得していないのでNULLの部分が出てくる
# NULLが入っているデータは余分なデータなので削除する
df.dropna(inplace=True)
return df
上記の定義が完了したら、手動でデータフレームとしてデータ取得を試してみても良いかもしれない。
下記は例として残しておきます。
# タブ区切りのテキストファイルをDataFrameに変換する
df = pd.read_csv('suumo_data_test_20230411.txt',delimiter=',',names=['scraping_id','scraping_date','name','price_10k','age_year',
'admin_fee','sikikin_10k','reikin_10k','deposit_10k','sikibiki_10k',
'line','station','move','time_to_station_min','room',
'area_m2','direction','type','address'])
#0行目は必要ないので除去
df = df.drop(0)
# 提出ファイル
df.to_csv('suumo_sp_folder/suumo_sp01.csv',index=False)
上記のようにすると、実際に賃貸情報をスクレイピング出来ていると確認が出来る。
3.スクレイピングして得たデータから、お得な物件を抽出する
スクレイピングして作成したDFから、家賃を予測するモデルを作り、「家賃の相場」として新たに特徴量を作成する。
- 前処理はobject型のものをラベルエンコーディングをして、最低限の前処理を行った。
- 線形回帰を用いて、モデル簡単に構築。
- ( 「実際の家賃」-「家賃の相場」)をした求めることで相場よりも安い家賃、つまりはお得と思われる物件を抽出。
下記にコードを残します。
#カテゴリ変数のカラムを指定して、まとめて処理
for col in cols:
le = LabelEncoder()
df1[col] = pd.Series(le.fit_transform(df1[col]))
df1 = encode_categorical(df1,cols=["scraping_date","name","line","station","move","room","direction","type","address"])
X = df1.drop('price_10k', axis=1)
y = df1['price_10k']
#今回は簡単に回帰分析を行う。
model = LinearRegression()
model.fit(X, y)
df2 = df1.copy()
#'market_rent'を今回で言う、家賃の相場とする。
df2['market_rent'] = model.predict(X)
df2['price_10k'] = df2['price_10k'].astype(float)
df2['market_rent'] = df2['market_rent'].astype(float)
#実際の家賃から家賃の相場を引く。
df2['rent_difference'] = df2['price_10k'] - df2['market_rent']
df2_sorted = df2.sort_values('rent_difference', ascending=True)
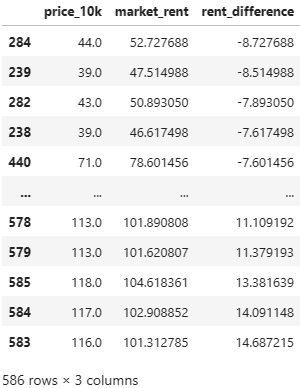
下記は得られたDFから実際の家賃と家賃の相場と、2つの差を抽出している。
df2_sorted[['price_10k','market_rent','rent_difference']]
'rent_difference'の値が小さいほど、実際の家賃は相場よりも安いとわかる。
4.全体を通して工夫した点
●スクレイピングの時点で、家賃や最寄りからの距離など数値のみを抽出するようにした。
(今回の目的はスクレイピングだったので、前処理を最低限にするため)
●コストパフォーマンスが高い家賃をどう定義するかを考えたときに、家賃予測で得た値を
家賃の相場として新たに特徴量として加えた点。
●前処理やモデル構築において、Nishikaのコンペで学んだ処理方法を応用できたので
効率良く処理ができた。
5.まとめ
スクレイピングはHTMLのソースコードを理解する必要があり、取っつきにくいイメージがあったが、順番に必要な特徴量をリストに入れていけば良いので、意外と複雑ではないと思いました。
次回の第2章では、「GCPを用いた住宅情報をスクレイピングと、賃貸物件価格予測を自動化」をまとめています。
また、追加処理として、家賃、物件名、最寄り駅、最寄駅からの距離、間取り、相場との差、等をobject型に戻してよりわかりやすくしたい。
今回はAPI作成まで実装することを目標にやってみる。