正規表現の先読み、後読み
正規表現の先読み、後読みを使用するタイミングがあったのですが、
よくわからない部分が多かったため整理しました
通常の正規表現と先読み、後読み
通常の正規表現と先読み、後読みの違いは次のようになります
- 通常の正規表現:正規表現と一致した文字列を取得します
- 先読み、後読み:正規表現と一致するか文字列を確認(取得はしない)し、位置を取得します
先読み、後読み
先読み、後読みの種類は4種類あります
- 肯定先読み:正規表現と一致した文字列の先頭の位置を取得します
- 否定先読み:正規表現と一致しない文字列の先頭の位置を取得します
- 肯定後読み:正規表現と一致した文字列の末尾の位置を取得します
- 否定後読み:正規表現と一致しない文字列の末尾の位置を取得します
取得例
実際に正規表現をチェックできるサイトを使用して確認してみます
使用サイト:https://rakko.tools/tools/57/
正規表現は先読み、後読みをした後に一文字を取得することで位置をわかりやすくしています
赤文字になっている部分が取得された文字となります
-
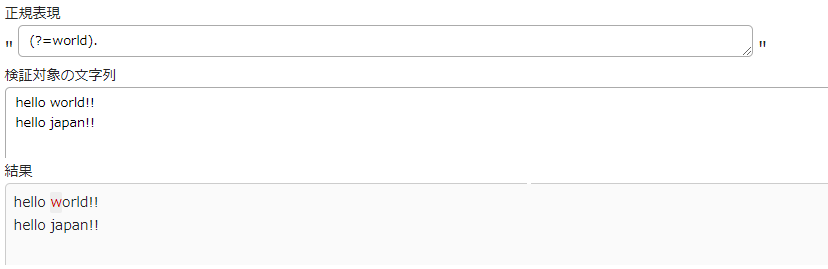
肯定先読み
記述方法は(?=正規表現)です
肯定先読みの場合、一致した文字列の先頭の位置なので、
画像の赤くなっているwの手前の位置が正規表現とマッチし取得されています
-
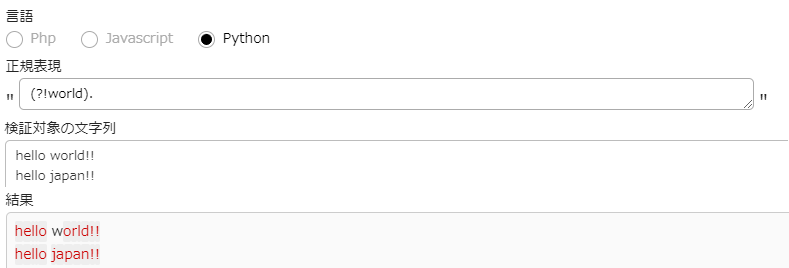
否定先読み
記述方法は(?!正規表現)です
否定先読みの場合、一致しない文字列の先頭の位置なので、
画像の黒くなっているw以外の位置が正規表現とマッチし取得されていますすることになります
-
肯定後読み
記述方法は(?<=正規表現)です
肯定後読みの場合、一致した文字列の末尾の位置なので、
画像の赤くなっている!の手前の位置が正規表現とマッチし取得されています

-
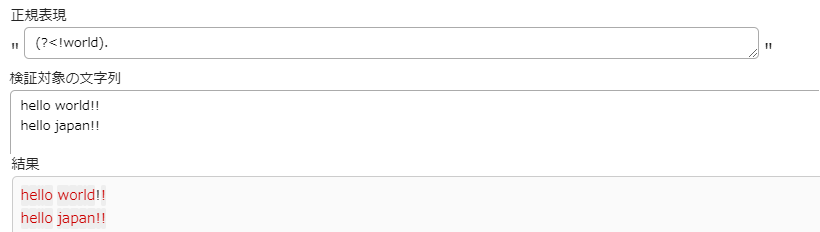
否定後読み
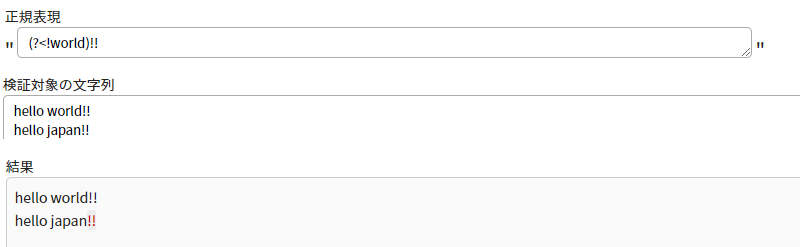
記述方法は(?<!正規表現)です
否定後読みの場合、一致しない文字列の末尾の位置なので、
画像の黒くなっている!以外の位置が正規表現とマッチし取得されています
何ができるのか
-
肯定先読み、肯定後読み
正規表現と一致する場合、該当位置から文字列を取得することができ、
先読みと後読みによって、正規表現で指定した文字列を含んで取得するか、含まずに取得するか分けることもできます
取得結果の違いについてまとめたのが次の画像になります

-
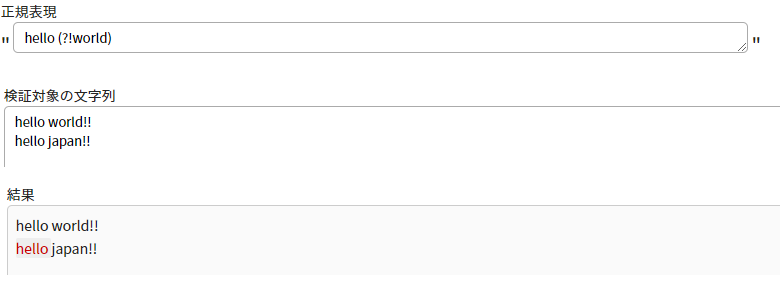
否定先読み
指定した文字列が続かない場合、文字列を取得する
-
否定後読み
指定した文字列から続かない場合、文字列を取得する
否定先読み、後読みは使いづらい?
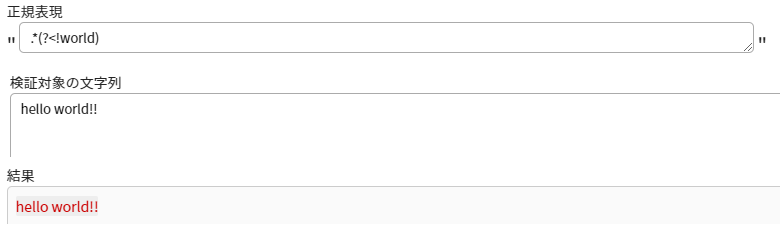
整理していく中で思ったことは、否定先読み、後読みは肯定先読み、後読みより使いづらい気がします
肯定先読み、後読みのように使用してしまうと、取得する位置が多いため、すべての文字列を取得してしまいます
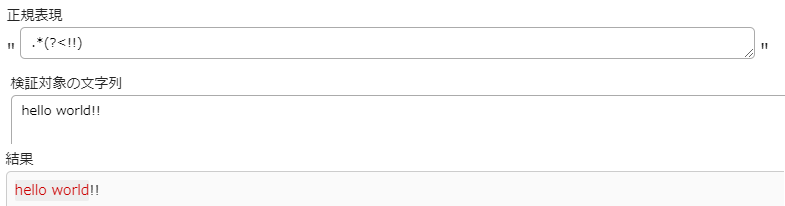
その代わり否定後読みは少し面白い使い方ができ、末尾の記号などを除いた文字列を取得したい場合などに使用できます
例えば、hello world!!の末尾!がいらない時などは、.*(?<!!)という風に記載することで!以外を取得することができます
終わり
よく理解できていなかった、正規表現の先読み、後読みを整理してみました
もし今回紹介した例以外にも面白い使い方などがあれば教えてください