はじめに
この記事では、機械学習パイプラインをWatson Studio Pipelinesで構築する手順を紹介します。
記事の内容:
- Watson Studio Pipelineの仕組み
- パイプラインの構築
- パイプラインのジョブ登録
パイプライン化の対象
下の図にある機械学習モデルの運用の中の3つの処理をパイプライン化の対象としています。
- パイプライン1:モデリング
- パイプライン2:モニタリング構成
- パイプライン3:モデル・リフレッシュ

Pipeline Editor
Watson Studio Pipelinesはパイプラインフロー作成のためのGUIツールを提供しています。
このツールを使ったパイプラインフローの作成は以下のようなイメージです。

上記画像の参照元:Automating the AI Lifecycle with IBM Watson Studio Pipelines
https://medium.com/ibm-data-ai/automating-the-ai-lifecycle-with-ibm-watson-studio-orchestration-flow-4450f1d725d6
作成したパイプラインフローのイメージ
今回、Watson Studio Pipelinesで作成したパイプラインフローは以下のようなイメージです。

Watson Studio Pipelinesの仕組み
Kubeflow Pipelines
Watson Studio Pipelinesは、バックエンドのランタイムとしてKubeflow Pipelinesを使用しています。Watson Studio Pipelinesでのパイプラインの各ノードの処理は、コンテナーで実行されます。
Watson Studio Pipelines is built off of Kubeflow Pipelines on the Tekton runtime and is fully integrated into the Watson Studio platform, allowing users to combine tools including:
・Notebooks
・Data refinery flows
・AutoAI experiments
・Web service / online deployments
・Batch deployments
・Import and export of project and space assets
引用元:Kubeflow Pipelines on Tekton hits 1.0, and Watson Studio Pipelines goes open beta
https://developer.ibm.com/blogs/kubeflow-pipelines-and-tekton-advances-data-workloads/
環境(コンテナー)
プロジェクトの「環境」タブの中にパイプラインの実行で使用できるコンテナーを確認できます。
予め準備されている環境を利用することも可能ですが、設定をカスタマイズした環境(コンテナー)を作ることも出来ます。
以下の画面キャプチャーは、環境の一覧を表示している画面になります。
今回のパイプラインの実行では、Watson Studio pipelinesとOpenScaleのSDKを導入したカスタマイズした環境を使用します。画面キャプチャーの一番上の環境(pipeline)

環境のカスタマイズの方法の詳細は以下の記事をご参照ください。
ストレージ
Watson Studio Pipelinesのフローの各ノードはコンテナーとして実行されます。コンテナーのディスクは永続化されないため、処理した結果を永続化して他のノードでも利用するには、外部のストレージへの保存する必要があります。
今回はデプロイメントスペースとCOSを外部ストレージとして利用して、各ノードからデータを参照できるようにフローを作成します。
全体の処理の流れは以下の図のようになります。
作成したデータやモデルはデプロイメントスペースを経由してアクセスするようにしています。
デプロイメントスペースにデータファイルを配置することも可能ですが、データファイルをCOSのバージョン管理機能を使用して履歴として保持するようにしたいため、COSに保存したファイルをデプロイメントスペースに登録する処理(処理1と7)の流れになっています。

データファイルのバージョン管理
COSのバージョン管理機能を有効にしておくことで過去のファイルの状態を保存できます。
パイプラインの出力に作成したファイルのバージョンIDを書き出すようにしておくことで、パイプライン実行履歴とその実行で作成されたCOS上のファイルを紐付けることができます。

デプロイメントスペースを通したCOSアクセス
デプロイメントスペースを通してCOSアクセスするためには、デプロイメントスペース上にCOSの接続情報を持つ「接続」を作成する必要があります。
「接続」を使用することで、NotebookからはCOSの接続情報を直接指定することなくCOS上のファイルへアクセスすることができます。

詳細は以下の記事を参照してください。
パイプラインの構築
パイプラインフローの作成
パイプラインのフローはPipeline Editorから作成します。
画面の左側にあるパレットからノードをドラッグアンドドロップしてキャンバスに配置します。
キャンバス上のノードをつなげることでフローを作成することが出来ます。
以下の画面キャプチャーでは、作成するパイプラインで使用しているノードを示します。
パイプライン1:モデリング
「Create data file」「Run notebook」「Create web service」の3種類のノードを使用します。

パイプライン2:モニタリング構成
「Run notebook」ノードを使用します。

パイプライン3:モデル・リフレッシュ
「Create data file」「Run notebook」「Update web service」の3種類のノードを使用します。

ノードの入出力を設定
ノードの入力と出力の設定を行うために設定画面を開きます。
キャンバスに配置されたノードをクリックして、「オープン」を選択すると設定画面が開きます。

入力と出力
「入力」タブで入力値、「出力」タブで出力値の設定を実施します。
設定方法は後述します。

環境(Environment)の設定
Environmentの設定項目では実行する環境(コンテナー)を選択します。
Watson Studioで準備された環境以外を利用する場合には、事前にプロジェクトの環境定義に環境を設定します。
今回は、事前に準備したWatson Studio Pipeline SDKとOpenScale SDKが導入された環境(以下の図のpipeline)を使用します。
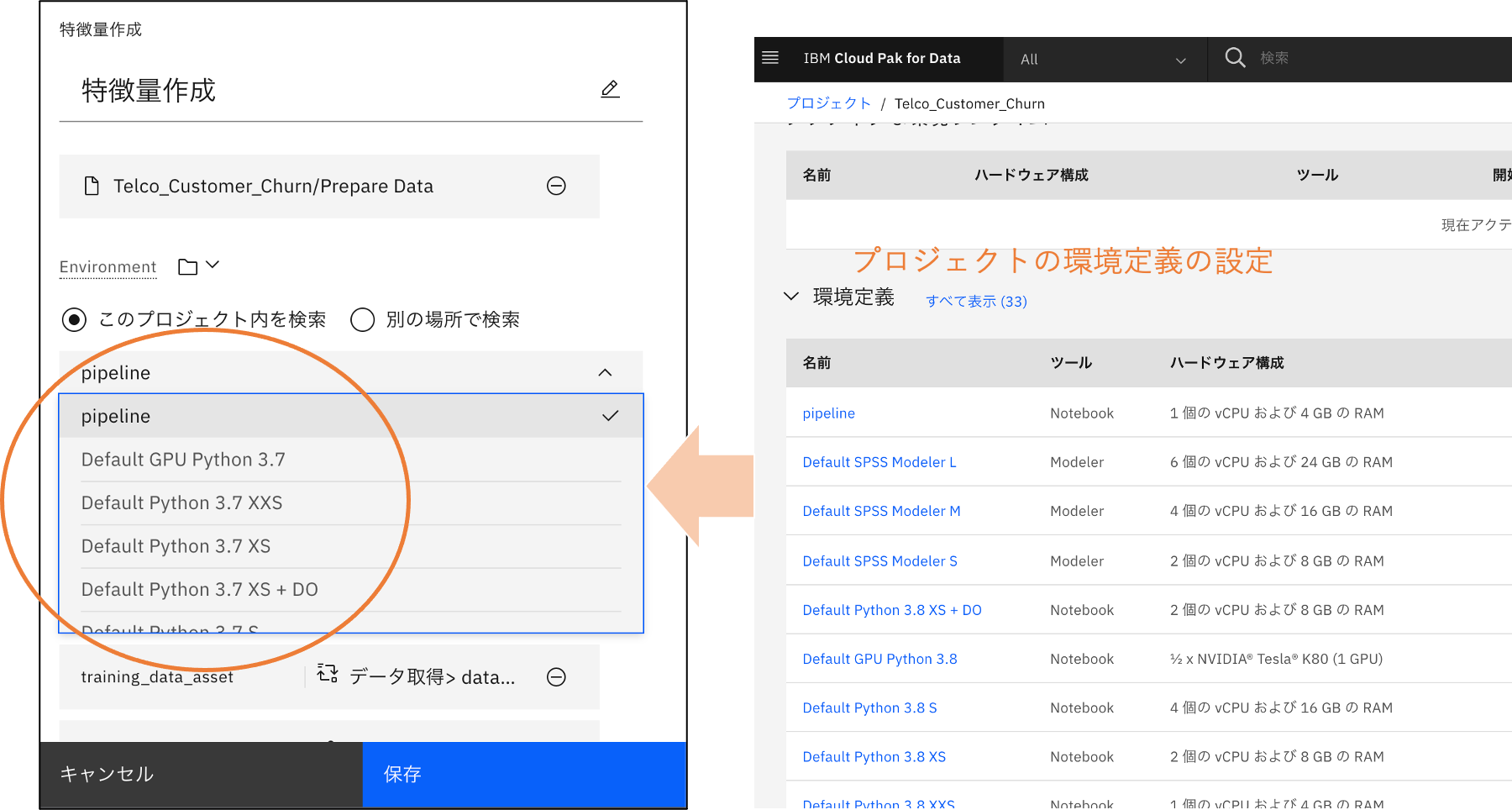
設定値の種類
設定値の種類は、以下の4種類あります。
- 「リソースの選択」:プロジェクト、スペース内からから選択する
- 「パイプライン・パラメーターの割り当て」:パイプライン・パラメーターを参照する(詳細は後述)
- 「別のノードからの選択」:別ノードの出力値を参照する(詳細は後述)
- 「値の入力」:定数を直接設定する
以下は、「モデリング」パイプラインの「データ取得」ノードの設定画面になります。
各設定項目の右側にあるアイコンをクリックすると設定値の種類を変更できます。

パイプラインパラメーター
パイプラインパラメーターの設定
Watson Studio Pipelinesでは、パイプラインを実行する時にパラメーターを与えることが出来ます。これをパイプラインパラメーターと呼びます。
パイプラインの実行ごとに異なる設定で実行が必要な場合に利用します。
例えば、デプロイ先のデプロイメントスペースやデプロイメント名など環境に依存する設定をパイプラインパラメーターとして、パイプライン実行時に外部から与えられるようにしておくことで、1つのパイプライン定義で複数の環境へのデプロイが可能になります。
以下の画面で丸をつけたアイコンをクリックするとパイプラインパラメーターの設定画面が開きます。

以下はパイプラインパラメーターの設定画面です。このキャプチャーはパイプライン1(モデリング)の設定内容になります。
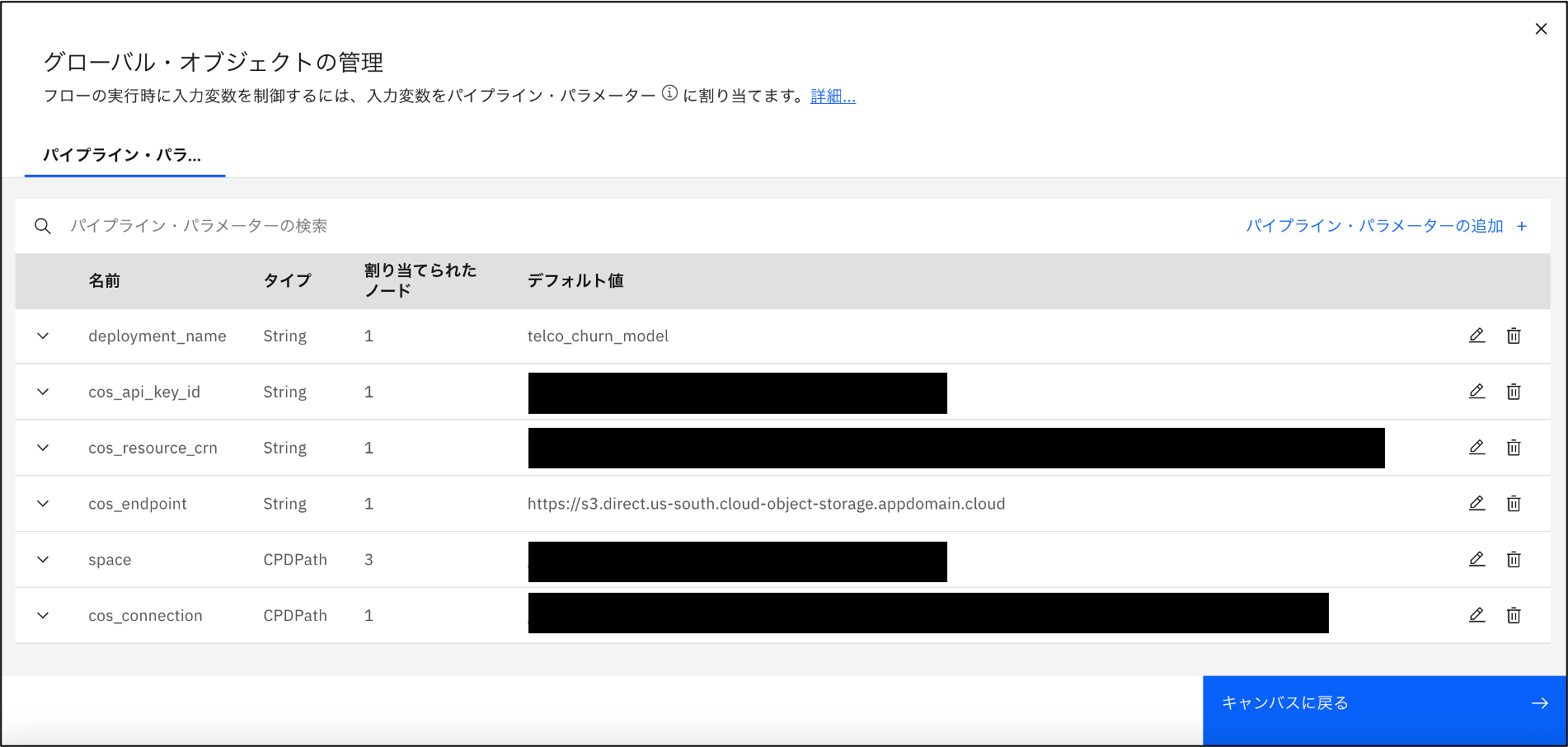
CPDPathについての参考情報:
Specifying the Cloud Pak for Data scope
When you specify an asset in the pipeline, you must provide the scope for finding the asset. The scope is the project, catalog, or space containing the asset. From the user interface, you can browse for the scope. In a notebook, specify the scope as part of the path to an asset, as follows:
[cpd://]/(projects|spaces|catalogs)/<scope-id>/<resource-type>/<resource-ID>
パイプラインパラメーターをノードから参照する
パイプラインパラメーターをノードから参照するにはノードの設定画面で以下の画面キャプチャーのように操作を行います。
設定項目の横にあるアイコンをクリックして、メニューを開き、「パイプライン・パラメーターの割り当て」を選択します。
「パイプライン・パラメーターの割り当て」を選択後、事前にパイプライン・パラメーターに設定してあるパラメータがリストされます。

別ノードの出力をノードの入力として使用する
パイプラインの処理を作る時に、あるノードが処理した結果を別のノードで使用したい場合が出てくるはずです。
別のノードが出力した結果を入力値として使用する設定が可能です。この設定を行うには設定項目の横にあるアイコンをクリックして、「別のノードからの選択」を選びます。そうすると参照するノードの選択とそのノードの出力項目をリストから選択できるようになります。
候補としてリストされるノードはフローの中で上流にあるノードのみです。理由は処理されていないノードの出力を利用することは出来ないためです。

ノードの設定内容
ここでは、各ノードの設定内容の中から主なものを説明します。
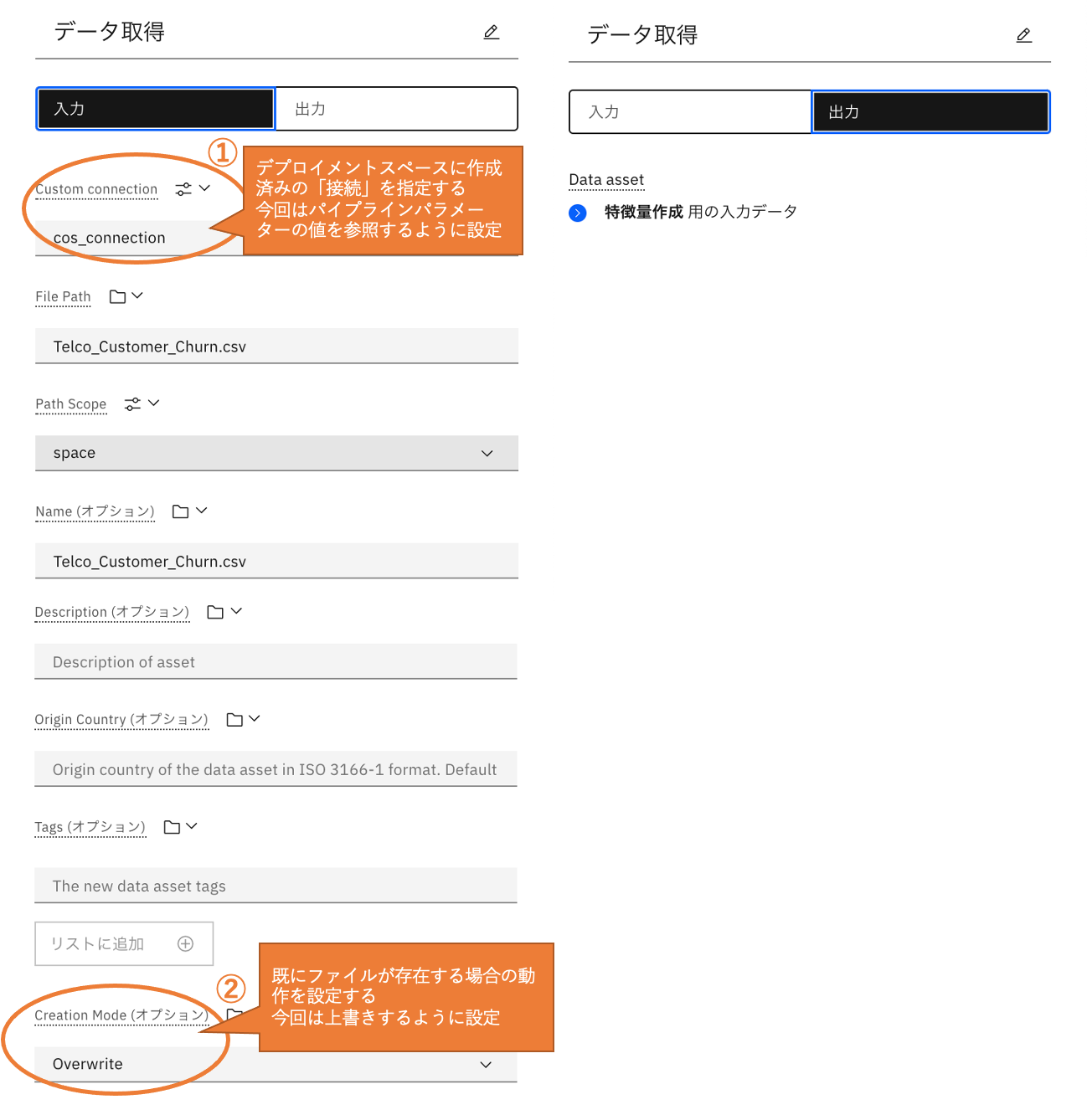
データ取得「Create data file」
「Create data file」ノードを使用します。「Create data file」ノードは、Object Storageに配置されたファイルをデプロイメントスペースにコピーすることが出来ます。
「モデリング」と「モデル・リフレッシュ」のパイプラインで使用しています。
① 設定項目:Custom connection
「Create data file」ノードを使う際の前提としてコピー先のデプロイメントスペースにファイルが格納されたCOSバケットへの「接続」が作成されている必要があります。
事前にデプロイメントスペースに作成された「接続」を設定します。今回この設定は、パイプラインパラメーターから渡すように設定しています。
② 設定項目:Creation Mode
デプロイメントスペースに既に同じ名前のファイルが存在している場合の動作を設定します。
今回は上書きする設定を行っています。
特徴量作成「Run notebook」
「Run notebook」ノードを使用します。「Run notebook」ノードは、Notebookを実行できます。
「モデリング」と「モデル・リフレッシュ」のパイプラインで使用しています。
① 設定項目:Notebook
実行するNotebookを設定します。
② 設定項目:Environment
Notebookを実行する際に使用する環境を設定します。
Watson Machine LearningとOpenScaleのSDKを導入したカスタムの環境「pipeline」を選択します。
③ 設定項目:Environment Variables
Environment Variablesには、Notebookで使用するデータを設定します。
「データ取得」ノードで取得したデータをNotebookから使用できるように、「データ取得」ノードの出力を設定します。環境変数の名前はtraining_data_assetとして登録します。
④ 設定項目:Output Variables
Notebookで処理した結果をパイプラインに戻し、他のノードで利用できるようにOutput variablesを設定します。
ここでは特徴量のデータファイルを2つ(学習とテスト)設定しています。

モデルを作成「Run notebook」
「Run notebook」ノードを使用します。
「モデリング」と「モデル・リフレッシュ」のパイプラインで使用しています。
① 設定項目:Environment Variables
「特徴量生成」ノードの出力を設定します。
② 設定項目:Output Variables
「モデルを公開」ノードで使用できるように、モデルのパスをOutput variablesに設定します。

モデルを公開「Create web service」
「Create web service」ノードを使用します。「Create web service」ノードは、モデルをWeb Service(API)として公開出来ます。
「モデリング」のパイプラインで使用しています。
① 設定項目:ML asset
公開するモデルを設定します。今回は「モデルを作成」ノードで作成したモデルへのパスを設定しています。
② 設定項目:Create Mode
同じ名前のデプロイメントが既に存在した場合の動作を設定します。
今回は失敗するように設定しています。

モニタリング構成「Run notebook」
「Run notebook」ノードを使用します。
「モニタリング構成」のパイプラインで使用しています。
① 設定項目:Notebook
OpenScale SDKを使ってOpenScaleを構成するNotebookを指定します。
② 設定項目:Environment Variables
OpenScaleの構成に必要な値を設定します。
デプロイメントスペースやデプロイメント名をパイプラインパラメーターから渡すように設定しています。
③ 設定項目:Output Variables
後続のノードで利用するデータはないため、出力設定は行っていません。

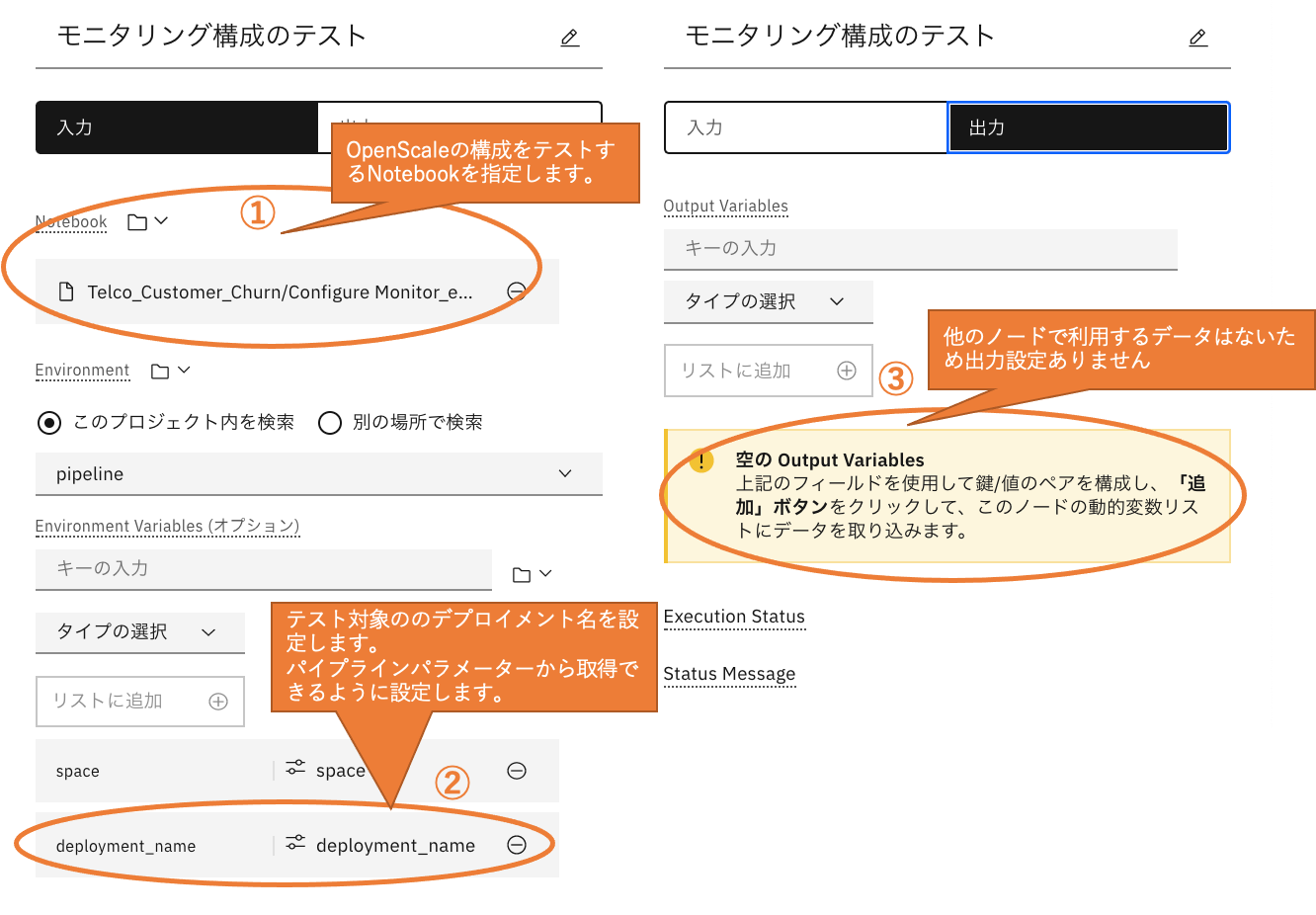
モニタリング構成のテスト「Run notebook」
「Run notebook」ノードを使用します。
「モニタリング構成」のパイプラインで使用しています。
① 設定項目:Notebook
OpenScale SDKを使ってOpenScaleの構成をテストするNotebookを指定します。
② 設定項目:Environment Variables
デプロイメントスペースやデプロイメント名をパイプラインパラメーターから渡すように設定しています。
③ 設定項目:Output Variables
後続のノードはないため、出力設定は行っていません。
モデルを公開(Update)「Update web service」
「Update web service」ノードを使用します。「Update web service」ノードは既存のWeb Service(API)を更新します。
「モデル・リフレッシュ」のパイプラインで使用しています。
① 設定項目:Deployment
更新対象のデプロイメントがあるデプロイメントスペースを設定します。
パイプラインパラメーターから渡すように設定しています。
② 設定項目:デプロイメントの名前
更新対象のデプロイメントの名前を設定します。
パイプラインパラメーターから渡すように設定しています。

パイプラインとNotebook間のデータの受け渡し方法
NotebookでWatson Studio Pipelinesのルールに従ったコーディングが必要になります。
入力値の処理方法
ノードの入力設定でEnvironment Variablesに設定した値が、Notebookの環境変数として設定されます。

Notebookでは以下のように環境変数を取得します。
# 環境変数
SPACE = os.getenv('space')
TRAINING_DATA_ASSET_CPD_PATH = os.getenv('training_data_asset')
COS_API_KEY_ID = os.getenv('cos_api_key_id')
COS_RESOURCE_CRN = os.getenv('cos_resource_crn')
COS_ENDPOINT = os.getenv('cos_endpoint')
出力値の処理方法
ノードの出力設定のOutput Variablesに、Notebookから受け取る出力変数名を設定します。

Notebookからパイプラインの出力変数に値を渡すには以下のようにします。
# Watson Studio Pipelines SDKの読み込み
from ibm_watson_studio_pipelines import WSPipelines
# WSP Client作成
wsp_client = WSPipelines() # 環境変数APIKEYから資格情報を読み取る
# 出力用(パイプラインに返すデータ)の値を作成
results = {
"train_data": "cpd:///spaces/{}/assets/{}".format(SPACE_ID, asset_uid_train),
"test_data": "cpd:///spaces/{}/assets/{}".format(SPACE_ID, asset_uid_test),
"data_info": {
## 省略 ##
}
}
# パイプラインから実行された場合に、パイプラインの出力に書き出す
if 'OF_CPD_SCOPE' in os.environ:
res = wsp_client.store_results(results)
print('DONE')
パイプラインとNotebook間のデータの渡し方については以下の記事も参考になります。
Notebookに関する参考情報
以下はパイプラインで実行するNotebookを作成する際に参考になる情報です。
パイプラインのジョブ登録
作成したパイプラインは、ジョブとして登録出来ます。
登録されたジョブは、スケジュールでの呼び出しまたはAPIでの呼び出しが可能になります。
ジョブ登録
Pipeline Editorの「実行」→「ジョブ作成」からパイプラインをジョブとして登録できます。
登録されたジョブは、プロジェクトの「ジョブ」タブから確認できます。

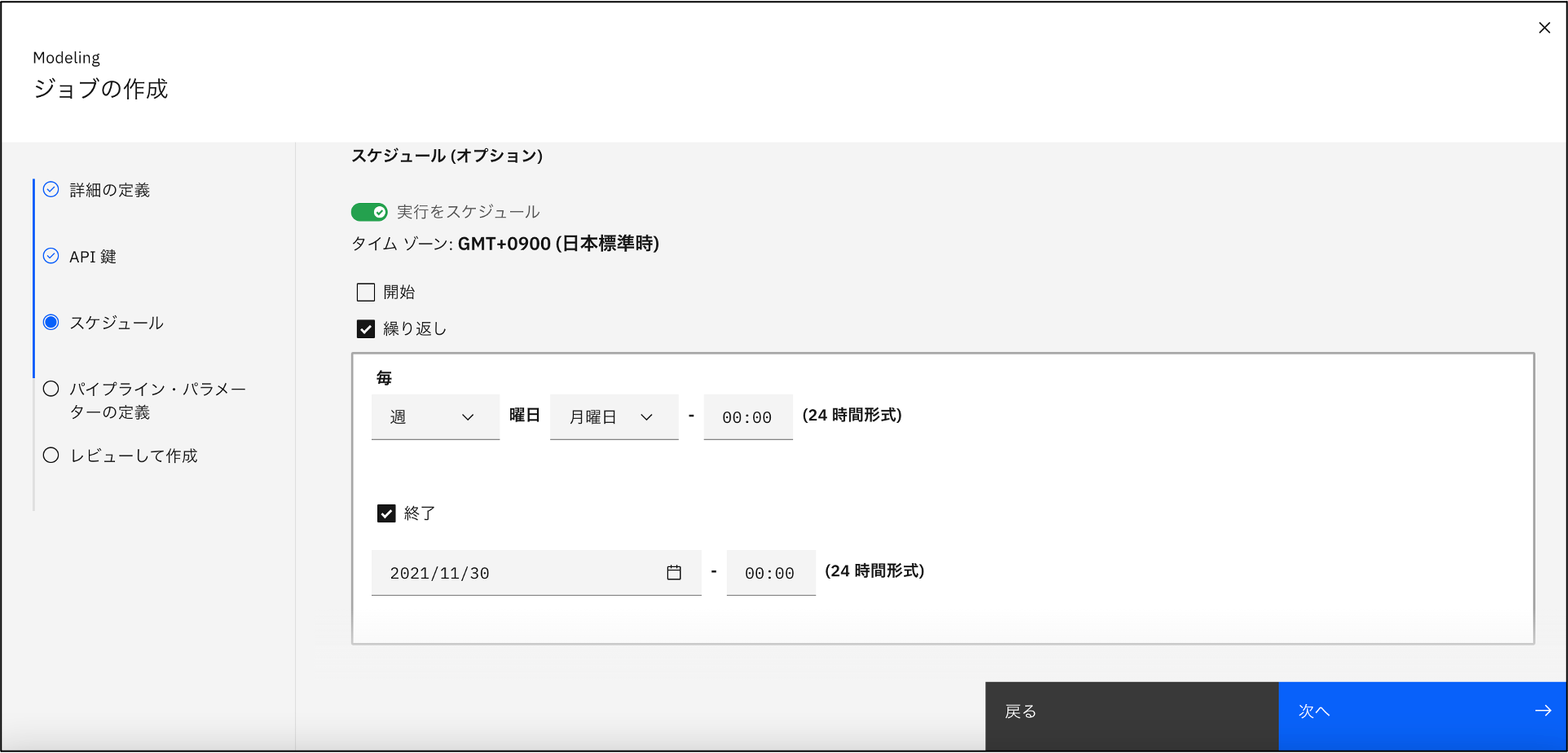
ジョブのスケジュール実行
ジョブ作成の設定画面ではジョブを実行するスケジュールの設定が可能です。
スケジュールベースでの実行をしない設定も可能です。
APIを使ったジョブ実行
あるイベントをトリガーにした実行や別のスケジューラーとの連携などのように任意のタイミングでジョブを起動できるようにAPIでの呼び出しが可能です。
ジョブを起動するAPIは以下になります。
https://cloud.ibm.com/apidocs/watson-data-api#job-runs-create
以下は、APIを使ったジョブの実行例になります。
import requests
# トークン取得
def get_token(apikey):
url = "https://iam.ng.bluemix.net/identity/token"
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
data = "apikey=" + apikey + "&grant_type=urn:ibm:params:oauth:grant-type:apikey"
token = requests.post(url, headers=headers, data=data).json()['access_token']
return token
# ジョブ実行
def execute_pipeline_job(job_id, job_param={}):
url = 'https://api.dataplatform.cloud.ibm.com'
headers = {
'Authorization': 'Bearer ' + get_token(apikey),
'Content-Type': 'application/json'
}
response = requests.post(url+"/v2/jobs/"+job_id+"/runs?project_id="+project_id, headers=headers, json=job_param, verify=False).json()
return response
execute_pipeline_job(job_id='xxxxxxx')
パイプラインのジョブ登録については以下の記事に詳しい内容があります。