雑まとめ
GCPのVision APIとFirebaseを使ってinshi.orgというウマ娘の因子を検索できるサイトを作りました。プレイしてる人は使ってみてね!
「2日で作った」とタイトルにある通り、この記事は「既存のAPIを説明の通りに使ったらその通りのものができた」的なやつです。いやー便利な世の中ですね。
ウマ娘について
ウマ娘って簡単に言うと育成シミュレーションゲームなんですが、元ネタが競走馬ということで、「因子」といういわゆる血統システムが組み込まれています。
例えば下の画面で言うと真ん中から下の「賢さ」とか「芝」とか書いてあるのが因子です。この子を親に選ぶと該当するステータスが伸びるというわけですね。
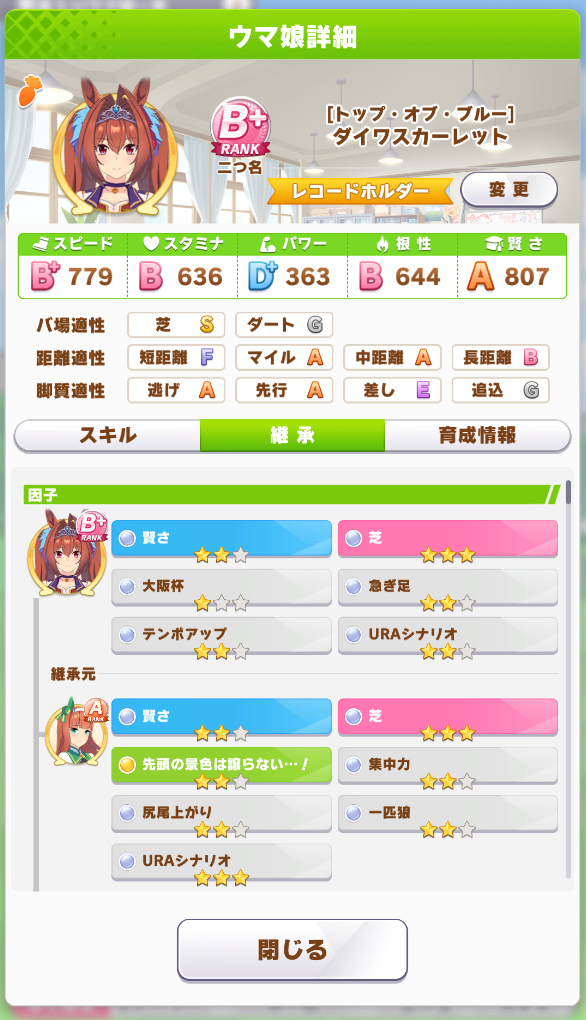
キャラクターの育成を始める時には親を2人選び、この因子を引き継がせて強いウマ娘を育てていくわけなんですが、この親のうち1人をフレンドから借りることができます。
キャラクターを育て切ったときにどんな因子が出るのかは運なんですが、試行回数の問題で基本的に他人の因子の方が強くなるわけで、つまり強いウマ娘を育てるにはいかに強い親を借りてこれるかが大切です。
逆に、自分のウマ娘を親として使ってもらうとボーナスポイントがもらえるので、強い因子が出た時はできるだけ他人に使ってもらいたいんですが、ツイッターに書くにしろ攻略サイトに投稿するにしろ、検索してもらうためには因子を自分で手打ちしていかないといけません。
因子の数も多いのに全部手打ちというのはあまりにも面倒ということで、何とかならないかやってみることにしました。
画像認識
あんまり長々と開発したくはなかったので、楽に使えるライブラリ的なのが無いかな~と思って「画像認識 文字 API」で検索するとGCPのCloud Vision APIが一番上にヒット。
上のページを参考にこんな感じのテストコードを書きました。
const fs = require("fs");
const vision = require('@google-cloud/vision');
// Creates a client
const client = new vision.ImageAnnotatorClient();
(async () => {
let buffer = fs.readFileSync("test.png");
const [result] = await client.textDetection(buffer);
const detections = result.textAnnotations;
console.log(detections);
})()
そして実行。
export GOOGLE_APPLICATION_CREDENTIALS="inshi-search-1c46c7d5ac77.json" && node test.js > log.txt
で、出てきたのがこれ。最初の要素は全文入りでした。
[
{
locations: [],
properties: [],
mid: '',
locale: '',
description: 'ウマ娘詳細\n' + ...,
score: 0,
confidence: 0,
topicality: 0,
boundingPoly: { vertices: [Array], normalizedVertices: [] }
},
{
locations: [],
properties: [],
mid: '',
locale: '',
description: 'ウマ',
score: 0,
confidence: 0,
topicality: 0,
boundingPoly: { vertices: [Array], normalizedVertices: [] }
},
{
locations: [],
properties: [],
mid: '',
locale: '',
description: '娘',
score: 0,
confidence: 0,
topicality: 0,
boundingPoly: { vertices: [Array], normalizedVertices: [] }
},
...
]
boundingPolyのverticesに要素の位置が記録されていて、これとdescription以外はいらなさそうだったのでカット。すると下のようになりました。
[
{
description: 'ウマ娘詳細\n' + ...,
vertices: [
{ x: 27, y: 25 },
{ x: 548, y: 25 },
{ x: 548, y: 960 },
{ x: 27, y: 960 }
]
},
{
description: 'ウマ',
vertices: [
{ x: 230, y: 25 },
{ x: 277, y: 25 },
{ x: 277, y: 47 },
{ x: 230, y: 47 }
]
},
...
]
これだけあれば十分ですね。一番上は単語と単語の切れ目が微妙なので消して、手動で近くの単語を合体させてから必要な因子の部分だけを切り取ると下のように。
[
{ text: '○賢さ', vertices: [ [Object], [Object], [Object], [Object] ] },
{ text: '○芝', vertices: [ [Object], [Object], [Object], [Object] ] },
{
text: '○大阪杯',
vertices: [ [Object], [Object], [Object], [Object] ]
},
{
text: '○急ぎ足',
vertices: [ [Object], [Object], [Object], [Object] ]
},
...
]
先頭のマークを○だと解釈しちゃってますが、概ね問題なさそうです。
あとは★の数をどうやって判断するかですが、因子の位置から下に灰色のピクセルを探して、そのまま横に黄色のピクセルを探しに行くようにしました。
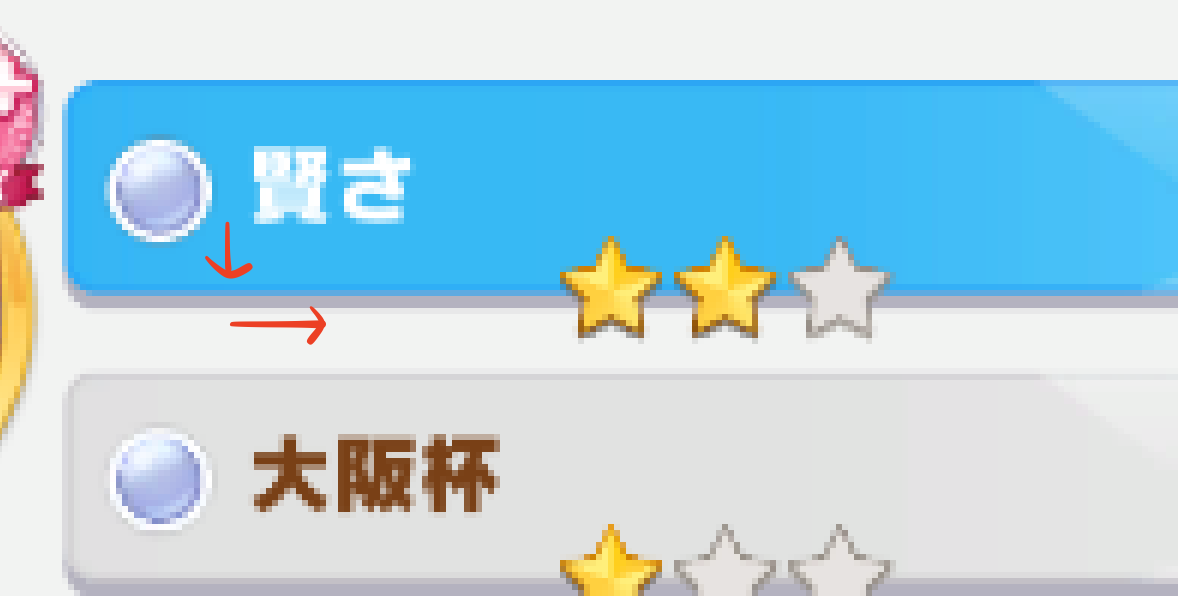
この辺りはNode.jsでCanvas(ImageData)を使った簡単な画像処理を参考にさせていただきました。画像の形式を考えなくていいのがめちゃ楽でした。
こんな感じで画像認識は完了。
[
{ text: '賢さ', star: 2 },
{ text: '芝', star: 3 },
{ text: '大阪杯', star: 1 },
{ text: '急ぎ足', star: 2 },
{ text: 'テンポアップ', star: 2 },
{ text: 'URAシナリオ', star: 2 },
...
]
Firestoreの設定
上で作ったコードをfunctionsに設置して、出てきたデータをFirestoreに投入するように設定。functionsの引数は分析用の画像2枚とウマ娘のユーザーIDです。
画像1枚だと因子が全部収まらないので、画像2枚から因子をマージするようにしました。画像データはbase64で転送するのでstringになっています。
...
export const postImage = functions.region("asia-northeast1")
.https.onCall(async (data: {
buffer1: string,
buffer2: string,
userId: number,
}, context): Promise<{
inshi: {
[x: string]: number
},
horseName: string,
success: boolean,
}> => {
...
await app.firestore().collection("uma").doc(data.userId.toString()).set({...});
});
で、Firestoreでどう検索を設定するかについてなのですが、因子の中でも重要性が高いと言われている青因子や赤因子の星数で絞り込みたい場合、単純に考えると下記のようなクエリになります。
firebase.firestore().collection("uma")
.where("blue", ">", foo)
.where("red", ">", bar);
ところがFirestoreでは大小比較の含まれるwhere句は同時に1つまでしか使えないという制限があり、このままでは使えません。
仕方ないのでFirestoreに保存するときに検索用のフィールドも追加して保存することにしました。
ついでに因子の種類を絞り込むためのフィールドも用意します。
{
...
speed: true // スピード因子持ちならtrue
stamina: false // 同スタミナ
...
blue7: true // 青因子が7個以上あればtrueにして保存
blue8: true // 8個以上
...
}
これでwhere句が大小比較ではなく==になり、たくさん連結できるようになりました。
絞り込んだデータを投稿日時順に並べたいので、timestampとそれぞれのプロパティとの複合インデックスを登録しておきます。
Firestoreにはインデックスマージという機能があるため、プロパティ間での複合インデックスは不要とのこと。
インデックスマージについては今回初めて知ったんですが、Firestoreさん意外と検索に強い作りにできるんですね。
フロントエンド作成
普段使っているReactを利用するという方針で、特にカスタマイズも不要なのでcreate-react-appを使いました。
フロントエンドに関しては特に特筆する部分もなく、単純にトグルボタンを大量に追加してその状態に応じてFirestoreのクエリを生成するというシンプルな作りです。
終わりに
雑にコードを一通り書き上げてからの調整に意外と時間を使わされました。
特に時間を取られたのがOCRの精度問題で、「汝」「錨」「顕」などの難しい漢字が全然違う文字になったり、濁点が落ちたり、「.」みたいな妙なごみを拾ってきたりして困りました。
いまいちエレガントな解決方法を思いつかなかったので、よく間違う部分を下のコードみたいな感じで修正しています。
return text.replace(/紅.ギア\/?LP1211-M/, "紅焔ギア/LP1211-M")
.replace(/不沈艦、抜.[ォオ]ッ!/, "不沈艦、抜錨ォッ!")
.replace(/G[0O]{2} ?1st\.F.*;/, "G00 1st.F∞;")
.replace(/貴.の使命を果たすべく/, "貴顕の使命を果たすべく")
.replace(/.、皇帝の神威を見よ/, "汝、皇帝の神威を見よ")
...
この辺は手動なので、多分まだまだ認識をミスる因子が残っていると思います。
宣伝のためにTwitterアカウントを作って因子を投稿している人にかたっぱしからリプライ送ってみたんですけど、今のTwitterはこういうスパムを弾くようになってるんですね。
そういえばここ何年もスパム見てないなと今さら思いましたw
(僕の送ったリプライが消えている図)