この記事は Elastic stack (Elasticsearch) Advent Calendar 2018 の8日目の記事です。
はじめに
こんにちは、tshoheと申します。
Elasticsearchはログやメトリクスの収集/可視化で利用する機会も多く、非常にお世話になっているソフトウェアの一つです。本記事では私が今年遭遇したElasticsearchのクラスタ停止障害について深掘りして調べてみたいと思います。
環境
- Elasticsearch6.1.1 + Filebeat6.1.1(PostgreSQL Module)
- 各ノードはmaster/data/ingestを兼任
今年の初めからPostgreSQL10を使い始めたのですが、当時はpg_stats_reporterも対応しておらず、監視をどうしようか考えていました。
そんなときにBeatsにPostgreSQL Moduleが追加されていたので、試してみようと思い使ってみてました。
FilebeatのPostgreSQL Module、当時はまだExperimentalではあったんですが、やっていることはFilebeatでログを転送してそれをIngestNodeのPipeline(Grok)で処理するというだけなので、まあそんなに変なことは起きないだろうと油断してました。(自己責任...)
※ 今はちゃんとExperimental取れているようです
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-postgresql.html
Visualization/Dashboardも付属してきていい感じに可視化できてええやんと思っていたある日、悲劇は起きました
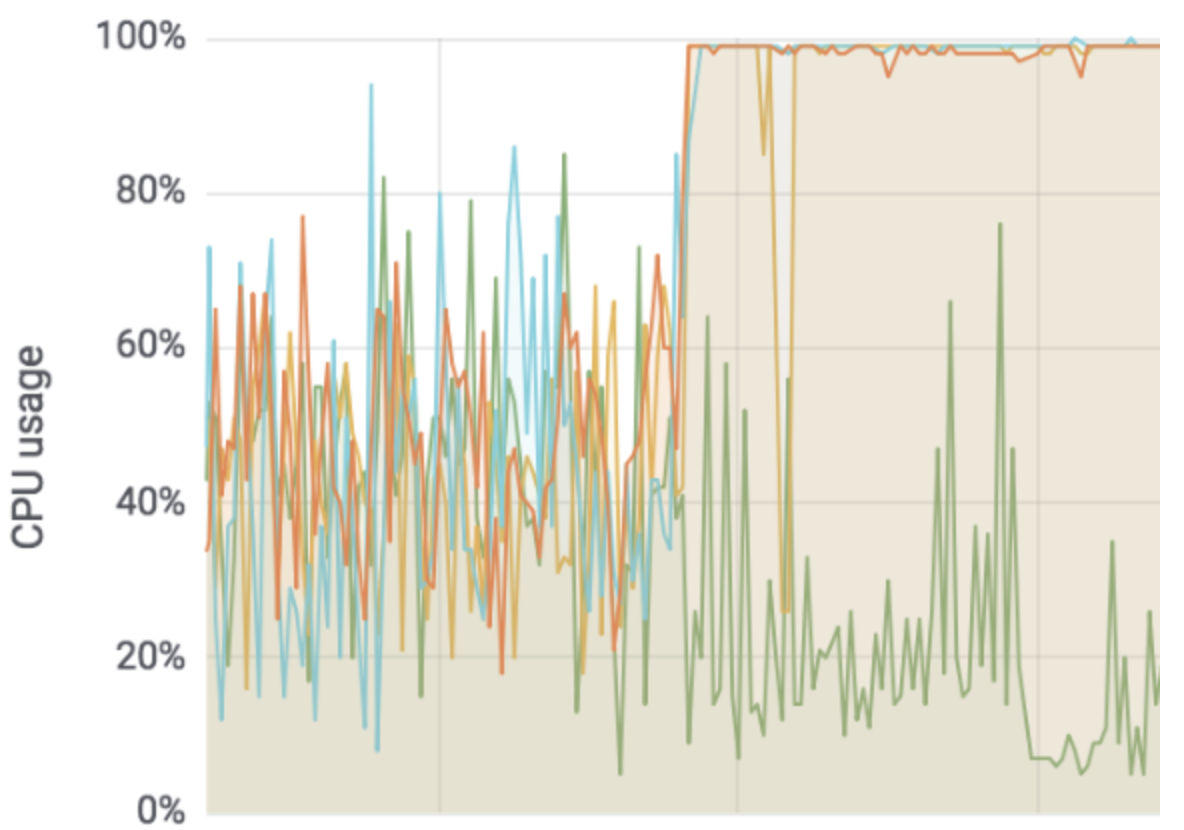
急に下のような事態に陥いってしまいました...!
- write処理が溜まってキューが枯渇
- リクエストがrejectされまくりDocumentが全く追加されない状態
- リクエストを受けるノードのCPU使用率(user)が100%に張り付き
こんな状態
ひえ〜
一体何が起きたのか
いろいろとログの転送を止めながら、原因がfilebeatで追加される「filebeat-6.1.1-postgresql-log-pipeline」というPipelineだとわかりました。
このPipelineのgrok processorが特定ログを処理するときに時間がかかって、キューが詰まってしまっていたようです。
原因となったGrok設定を見てみます。
filebeat-6.1.1-postgresql-log-pipeline
https://github.com/elastic/beats/blob/v6.1.1/filebeat/module/postgresql/log/ingest/pipeline.json#L18
"grok": {
"field": "message",
"ignore_missing": true,
"patterns": [
"%{LOCALDATETIME:postgresql.log.timestamp} %{WORD:postgresql.log.timezone} \\[%{NUMBER:postgresql.log.thread_id}\\] %{USERNAME:postgresql.log.user}@%{HOSTNAME:postgresql.log.database} %{WORD:postgresql.log.level}: duration: %{NUMBER:postgresql.log.duration} ms statement: %{MULTILINEQUERY:postgresql.log.query}",
"%{LOCALDATETIME:postgresql.log.timestamp} %{WORD:postgresql.log.timezone} \\[%{NUMBER:postgresql.log.thread_id}\\] \\[%{USERNAME:postgresql.log.user}\\]@\\[%{HOSTNAME:postgresql.log.database}\\] %{WORD:postgresql.log.level}: duration: %{NUMBER:postgresql.log.duration} ms statement: %{MULTILINEQUERY:postgresql.log.query}",
"%{LOCALDATETIME:postgresql.log.timestamp} %{WORD:postgresql.log.timezone} \\[%{NUMBER:postgresql.log.thread_id}\\] %{USERNAME:postgresql.log.user}@%{HOSTNAME:postgresql.log.database} %{WORD:postgresql.log.level}: ?%{GREEDYDATA:postgresql.log.message}",
"%{LOCALDATETIME:postgresql.log.timestamp} %{WORD:postgresql.log.timezone} \\[%{NUMBER:postgresql.log.thread_id}\\] \\[%{USERNAME:postgresql.log.user}\\]@\\[%{HOSTNAME:postgresql.log.database}\\] %{WORD:postgresql.log.level}: ?%{GREEDYDATA:postgresql.log.message}",
"%{LOCALDATETIME:postgresql.log.timestamp} %{WORD:postgresql.log.timezone} \\[%{NUMBER:postgresql.log.thread_id}\\] %{WORD:postgresql.log.level}: ?%{GREEDYDATA:postgresql.log.message}"
],
"pattern_definitions": {
"LOCALDATETIME": "[-0-9]+ %{TIME}",
"GREEDYDATA": ".*",
"MULTILINEQUERY" : "(.|\n|\t)*?;$"
}
}
MULTILINEQUERYにマッチしなければGREEDYDATAで処理するというもの
ちなみにこの正規表現はよろしくなくて既に下のように変更されています。
6.5.1
https://github.com/elastic/beats/blob/v6.5.1/filebeat/module/postgresql/log/ingest/pipeline.json
- "GREEDYDATA": ".*",
- "MULTILINEQUERY" : "(.|\n|\t)*?;$",
+ "GREEDYDATA": "(.|\n|\t)*",
MULTILINEQUERYとGREEDYDATAがまとめられて";"で終わっている必要がないような書き方になっています。
(.*)?;$ の何がやばいのか調べてみます。
org.joni.Regexではないので正確な動作は異なるかもしれませんが、簡単にステップを辿れるサイト (https://regex101.com) で確認してみます。
MULTILINEQUERYのところに入るクエリが↓のような感じだとすると...
select a.b,
a,
b,
c,
d
from t1
join t3
on a = a
and b = b
where aaaaaaaaa between '2018-12-07 00:00:00' and '2018-12-08 00:00:00'
union all
select a.b,
a,
b,
c,
d
from t2
join t4
on a = a
and b = b
where bbbbbbbb between '2018-12-07 00:00:00' and '2018-12-08 00:00:00';
1788step(187ms)くらいの処理
任意文字のあとに毎回";"が入るかチェックされているので普通のGREEDYDATAと比べるとstep数が多いようです。 
ただし本当にやばいのは後ろに想定外の文字列がついたときです。
今回問題になったログというのはPostgreSQLのlog_min_duration_statementの時間を超過した際に出力されるスローログなので、クエリがそのまま出力されます。よって下記のようにコメントが記載されている可能性もあるわけです。
...
where bbbbbbbb between '2018-12-07 00:00:00' and '2018-12-08 00:00:00'; -- hogehoge piyopiyo
一気にステップ数が跳ね上がって934154steps(1.06s)になります。
文字数によって爆発的にstep数が増えるので、SQL文がちゃんとインデントされていてスペースが多かったりするとえらいことに。(今回のPostgreSQLの例だとスロークエリなので非常に長い...)
- .*があることでバックトラックが発生(最大限マッチするパターンを探すため)
- ;で終わっていればよいが、終わっていないと1~n文字目の地点から開始した場合の文字列全てのパターンを確認するのでとんでもない計算量になる
まとめ
(.*)A$ みたいなgrokパターンが定義してあるところに hogehogepiyopiyoA hogehogepiyopiyo...... みたいなデータを投入するとクラスタに甚大な負荷をかけてクラスタを殺すことができる。
Elasticsearchというか正規表現の話でした。。。
教訓
- ログの乱れをある程度許容できるように書いておくべき
- 特定の文字列に特化してPipelineやGrokを設定すると予期せぬ値が入ったときの動作が不安
- テスト環境でいろんなパターンをチェックすべき
- IngestNodeはMasterNode/DataNodeと分離しておくべき
- 少なくとも検索はできていたはず
- ただそれだとFluentd/Logstashとかなくても処理挟めるという、IngestNodeの良さが消えてしまうんですが!