問題点として
Google Spreadsheet を Python スクリプトで作成と読込、更新、削除 (CRUD) を行いたい場合、手段が下記のように複数あり、またそれぞれバージョンによる差異もあることから分かりづらいです。
解決する手段として
2018年5月現在で最新となる Sheets API V4 を Google 公式の Google client libraries を用いて操作します。
この記事では次の手順で実現していきます。
- 準備
- Google Drive にアクセスするための認証情報を得る。
- Python から API にアクセスするためのモジュールをインストールする。
- 実行
- スプレッドシートを作成する。
- テーブルに情報を加える。
- テーブルの情報を更新する。
- テーブルを削除(クリア)する。
準備
スプレッドシートを Python で操作するために、結果として次の認証情報が得られていれば OK です。
- クライアント ID
- クライアントシークレット
- リフレッシュトークン
既にそのための有用な記事がいつくかあります。こちらを参照してください。
- [Google API OAuth2.0のアクセストークン&リフレッシュトークン取得手順メモ]
(https://qiita.com/kossacks/items/8d279bcc1acc2c2153ab) - Google API OAuth2.0のトークン取得手順
Google client libraries (Python) のインストール
API を Python から操作するためのモジュールをインストールします。
$ pip install --upgrade google-api-python-client
API とクライアントライブラリについて
Google Sheets API
Google Sheets API は Google スプレッドシートを操作するための API です。
スプレッドシートを読み書きするための主な API を下記に記します。
- v4.spreadsheets
- create
- v4.spreadsheets.developerMetaData
- v4.spreadsheets.sheets
- v4.spreadsheets.values
- append
- clear
- get
- update
Google client libraries (Python)
Google client libraries は Google Sheets API 等を Python で使用するためのライブラリです。
下記は v4.spreadsheets の create にアクセスする Python スクリプトの例です。
service = discovery.build('sheets', 'v4', credentials=credentials)
request = service.spreadsheets().create(body=spreadsheet_body)
response = request.execute()
- 1行目の
discovery.build()では、Sheets API を使用するための認証済みインスタンスを取得します。 - 2行目の
service.spreadsheets().create()にはv4.spreadsheetsのcreateが対応しています。 - 3行目の
responseには API から得た情報が入ります。
操作対象とする Google スプレッドシートの構造について
- スプレッドシートには単一もしくは複数のシートが入っています。
- シートには単一もしくは複数のテーブルが入っています。
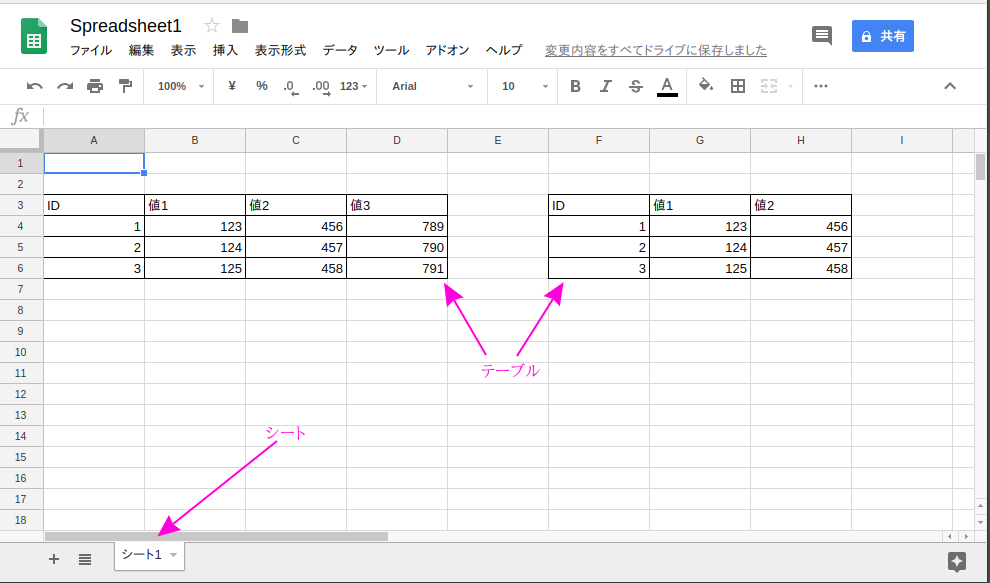
図1 スプレッドシートの構造
実行
サンプルプログラム 作成しましたので参照ください。
クラス MySpreadsheet は以下のメソッドを持っています。
- create
- read
- update
- append
- clear
これらを用い、シートの作成、読込、更新、削除 (CRUD) および 追記 を行います。
ファイル自体の削除は Drive API になるため、ここでは代わりにシートのクリアを行います。
なお、認証情報は使用する環境のものに置き換えてください。
以下に実際にスプレッドシートを操作している箇所を抜粋し、要点を示します。
create()
service = discovery.build('sheets', 'v4', credentials=self.credentials)
body = {"properties": {"title": title}}
request = service.spreadsheets().create(body=body)
response = request.execute()
- 空のスプレッドシートを新規作成します。
- title にはスプレッドシートのファイル名を指定します。
- self.credentials には
OAuth2Credentialsのインスタンスが入ります。 - 生成されたファイルはドライブのホームフォルダに保存されます。
read()
_range = f"{sheet_name}!{sheet_range}"
request = service.spreadsheets().values().get(spreadsheetId=spreadsheet_id,
range=_range,
valueRenderOption="UNFORMATTED_VALUE")
response = request.execute()
values = response["values"]
if header:
columns = values[0]
values = values[1:]
else:
columns = None
return pd.DataFrame(values, columns=columns)
- 指定された位置にあるテーブルを読み込みます。
- sheet_name には シート名が入ります。
- _range にはテーブルの範囲を指定します。 例) "A2:D10" または "A2:D"
- response["values"] からテーブルの情報を読み取り、以降で pandas DataFrame にしています。
ValueRenderOption について
得られる値の形式を設定します。
ここでは全て文字列とする UNFORMATTED_VALUE を設定しています。
- FORMATTED_VALUE
- セルの値は計算され、書式設定(円、ドルなど)が適用されます。
- 数値は数値、文字列は文字列として取得されます。
- UNFORMATTED_VALUE
- セルの値は計算されますが、書式設定は適用されません。
- セルの値は文字列として取得されます。
- FORMULA
- セルは計算されません。'=A1' のようなセルはそのまま文字列として取得されます。
注意点
- テーブルに欠損値がある場合、別途補間する処理が必要になります。ここでは欠損値は考慮していません。
- FORMATTED_VALUE を指定した場合、セルが意図しない値に計算されてしまう場合があります (日付時刻など)。
update()
_range = f"{sheet_name}!{sheet_range}"
value_input_option = "USER_ENTERED"
if header:
dat = [df.columns.tolist()] + df.values.tolist()
else:
dat = df.values.tolist()
body = {"values": dat}
request = service.spreadsheets().values().update(spreadsheetId=spreadsheet_id,
valueInputOption=value_input_option,
range=_range,
body=body)
response = request.execute()
- 指定された位置のテーブルを新しい DataFrame で更新します。
clear()
_range = f"{sheet_name}!{sheet_range}"
body = {}
service = discovery.build('sheets', 'v4', credentials=self.credentials)
request = service.spreadsheets().values().clear(spreadsheetId=spreadsheet_id,
range=_range,
body=body)
response = request.execute()
- 指定された位置のテーブルをクリアします。
append()
_range = f"{sheet_name}!{sheet_range}"
value_input_option = "USER_ENTERED"
if header:
dat = [df.columns.tolist()] + df.values.tolist()
else:
dat = df.values.tolist()
body = {"values": dat}
request = service.spreadsheets().values().append(spreadsheetId=spreadsheet_id,
valueInputOption=value_input_option,
range=_range,
body=body)
response = request.execute()
- 指定された位置のテーブルに DataFrame を追加します。
- パラメータは update と同じです。
- テーブルの下に情報が追記されます。
セルの範囲について
- 基本的には "B2:E5" のように範囲を指定します。
- API によりテーブルの終端を入力しなくても良い場合があります。
表1 テーブルの例
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | ID | VAL1 | VAL2 | VAL3 | ||
| 3 | 1 | 101 | 201 | 301 | ||
| 4 | 2 | 102 | 202 | 302 | ||
| 5 | 3 | 103 | 203 | 303 | ||
| 6 | ||||||
| 7 | ||||||
| 8 |
表2 APIごとの範囲指定
| API | 範囲指定 |
|---|---|
| read | "B2:E" のような指定もできます。テーブルの終端はAPI 側で判定してくれます。 |
| append | テーブルが特定できれば良いので、テーブルの任意のセルを指定すれば追記してくれます。 例) "B2" |
| update | 更新する部分の左上のセルで指定できます。 例) "B2" |
| clear | "B:E" のような指定ができます。 この場合B列からE列は全てクリアされます。 |
結果として
Google スプレッドシートを Python の pandas DataFrame を使用して読み書きができるようになりました。
参考
- [Google API OAuth2.0のアクセストークン&リフレッシュトークン取得手順メモ]
(https://qiita.com/kossacks/items/8d279bcc1acc2c2153ab) - Google API OAuth2.0のトークン取得手順
- Sheets API V4
- Google client libraries