概要
「【レポート】X-Pack新機能 : Machine Learning ワークショップに参加してきました」で紹介されているセミナーに出ておりました。
講師の方のデモは「ニューヨーク市のタクシー乗降データでMachine Lerningを体験する」に書いてある内容です。
容易に使用することができ、パワフルなMachine Learningを体験いただくには、みなさん自身のデータを使用されることが一番ですが、公開されているデータセットを用いても十分に実感できます。ニューヨーク市のタクシーの乗降データを用いて異常検知を行って見ましょう。リリース5.4を対象にします。
アノマリーと聞くと、Ingressが思い浮かびますが、それはさておき。
自身のデータだと数があまりないので、そうだ日経225はどうよ、ということでやってみた。
環境の準備
| products | version |
|---|---|
| Elasticsearch | 5.4.0 |
| Kibana | 5.4.0 |
version: '2'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:5.4.0
container_name: elasticsearch
ports:
- 9200:9200
- 9300:9300
kibana:
image: docker.elastic.co/kibana/kibana:5.4.0
container_name: kibana
links:
- elasticsearch:elasticsearch
ports:
- 5601:5601
docker-compospe up -dとでもやって起動しておきます。
なお、この環境の接続ユーザ、パスワードは初期値 elastic/changeme です。
データの準備
CSVの入手
日経225のデータは、「日経平均プロフィル-日経の指数公式サイト-」のダウンロードセンターからCSVを入手できます。
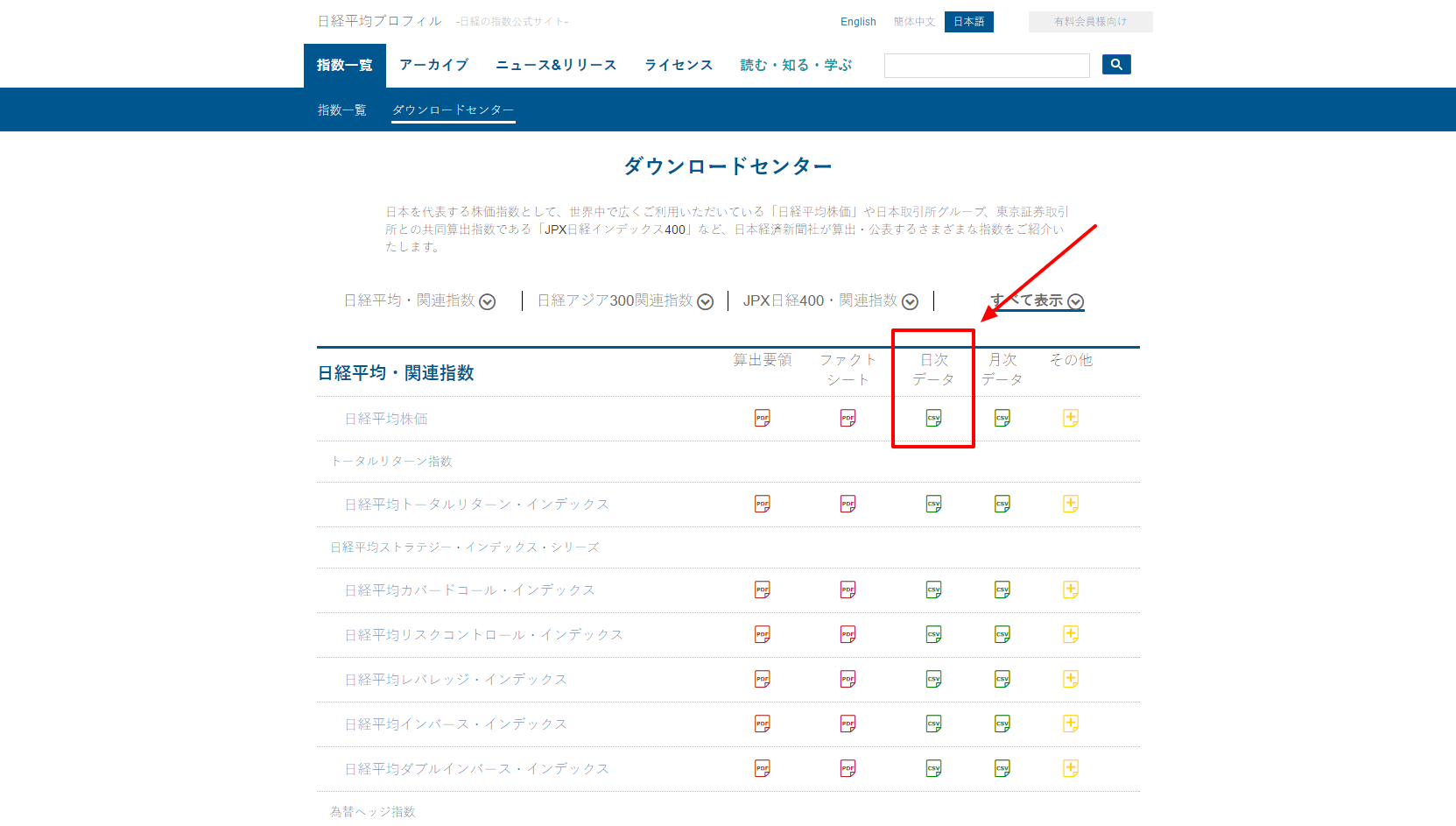
CSVには、始値、終値、安値、高値とデータの日付が含まれています。
Elasticsearchへの投入
データの投入はLogstashを使っても良いのですが、今回は手っ取り早くやりたかったのでPythonで書いてみました。
ダウンロードしたCSVはShift-JISなのが注意点です。
indexやtypeは以下のように想定します。
| 項目 | 値 |
|---|---|
| index | stock |
| type | nikkei225 |
# -*- coding: utf-8 -*-
from datetime import datetime as dt
import pandas as pd
from elasticsearch import Elasticsearch
df = pd.read_csv('nikkei_stock_average_daily_jp.csv', encoding='SHIFT-JIS')
es = Elasticsearch('http://elastic:changeme@xxx.xxx.xxx.xxx:9200')
def generate_doc(row):
doc = {
'start_value': row['始値'],
'end_value': row['終値'],
'low_value': row['安値'],
'high_value': row['高値'],
'timestamp': dt.strptime(row['データ日付'], '%Y/%m/%d')
}
return doc
for row in df.iterrows():
doc = generate_doc(row[1])
type = 'nikkei225'
res = es.index(index="stock", doc_type=type, id=str(row[0]), body=doc)
注:本当はBulk Insertすべきところですがデータ件数も少ないので適当にやってます
Single Metric Jobの作成
Create New Job
Machine Lerningのアイコンから、「Create a single metric job」を選択します。
New job from index pattern
さきほど作成したstockインデックスに対して、ジョブを作成しましょう。
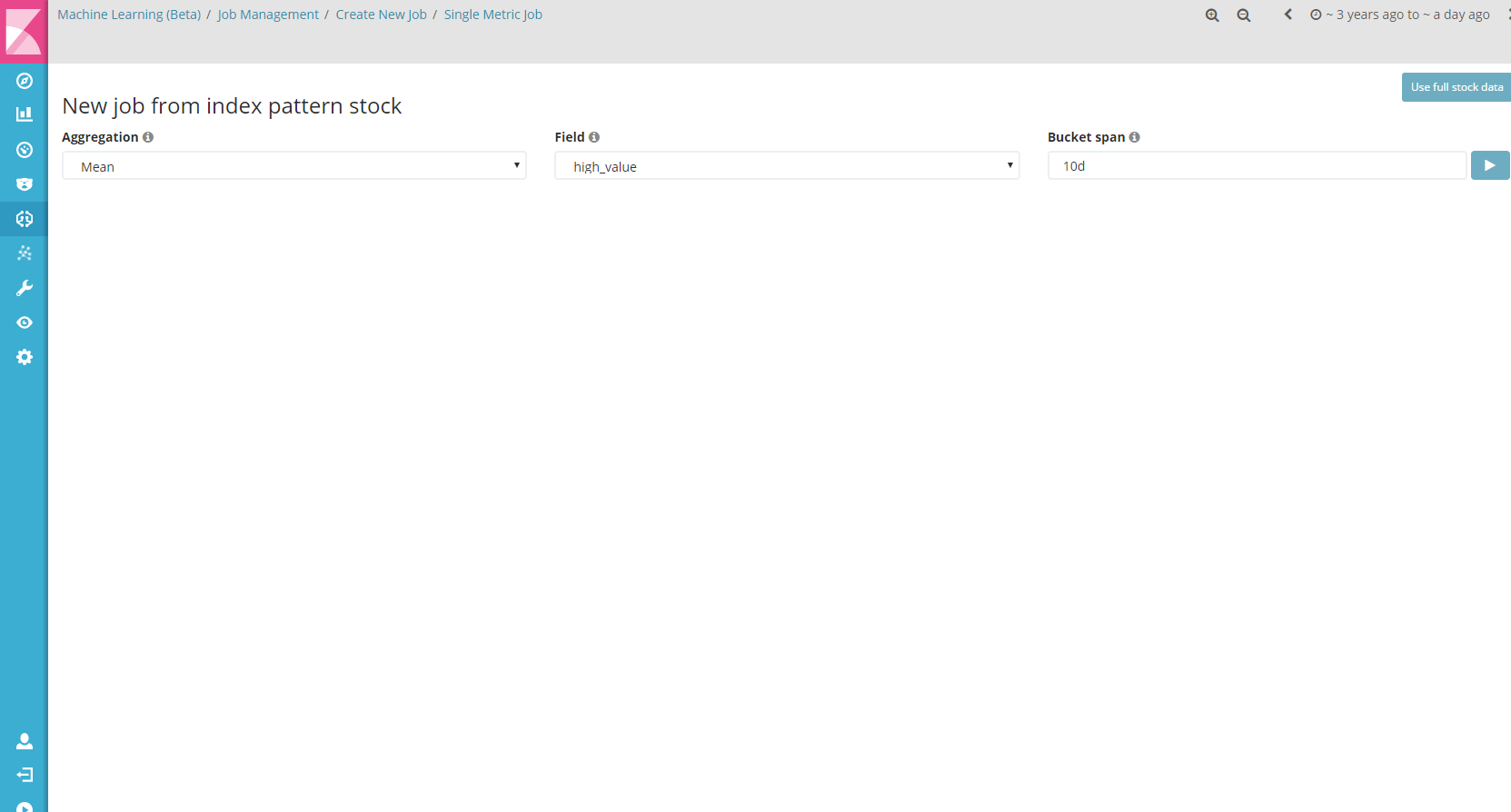
| 項目 | 値 |
|---|---|
| Aggregation | 集計方法を選択します。今回は平均を指定してみます |
| Field | high_value。今回は高値を指定してみます |
| Bucket span | どのぐらいのスパンでモデル化して異常を検知するかの大事な値。10日を表す10dとしました |
Bucket spanは講師の方がおっしゃっていましたが、小さすぎると結果が安定しないと。
今回は日時データですので、10日と仮に置きました。
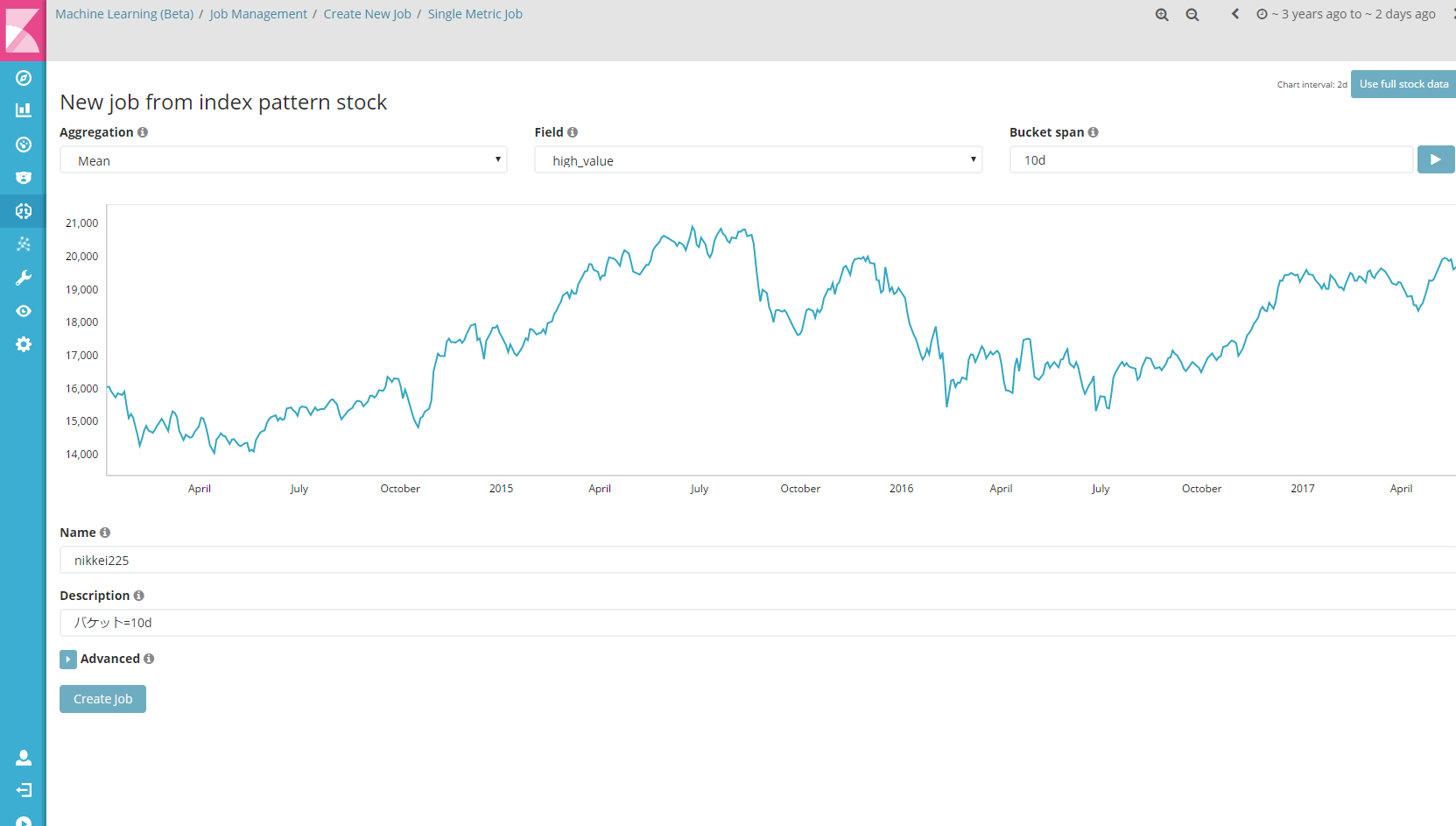
Bucket span横にある再生マークのようなアイコンを押すと、グラフが表示されます。
Name(日本語不可)とDescriptionを適当に埋めて、「Create job」ボタンを押下します。
Nameに「日経平均株価」などと入れると、エラーになるので注意。
すると、しばらくするとAnalyzeが終了し、こんな画面が表示されました。
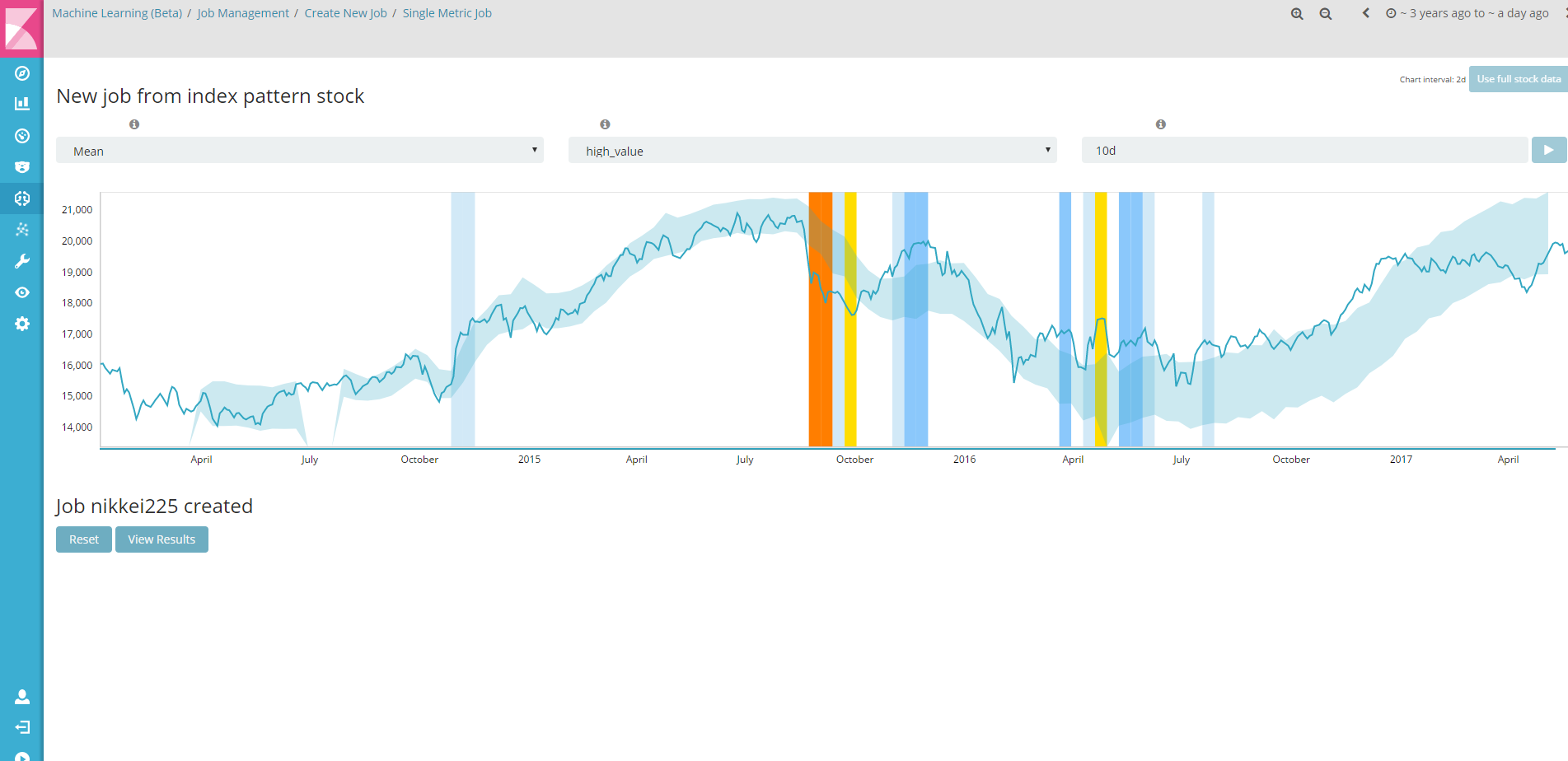
Single Metric Viewer
「View Results」ボタンを押すと、時系列の分析画面に遷移します。
オレンジ色があるところに枠を移動させて、詳しくみてみましょう。
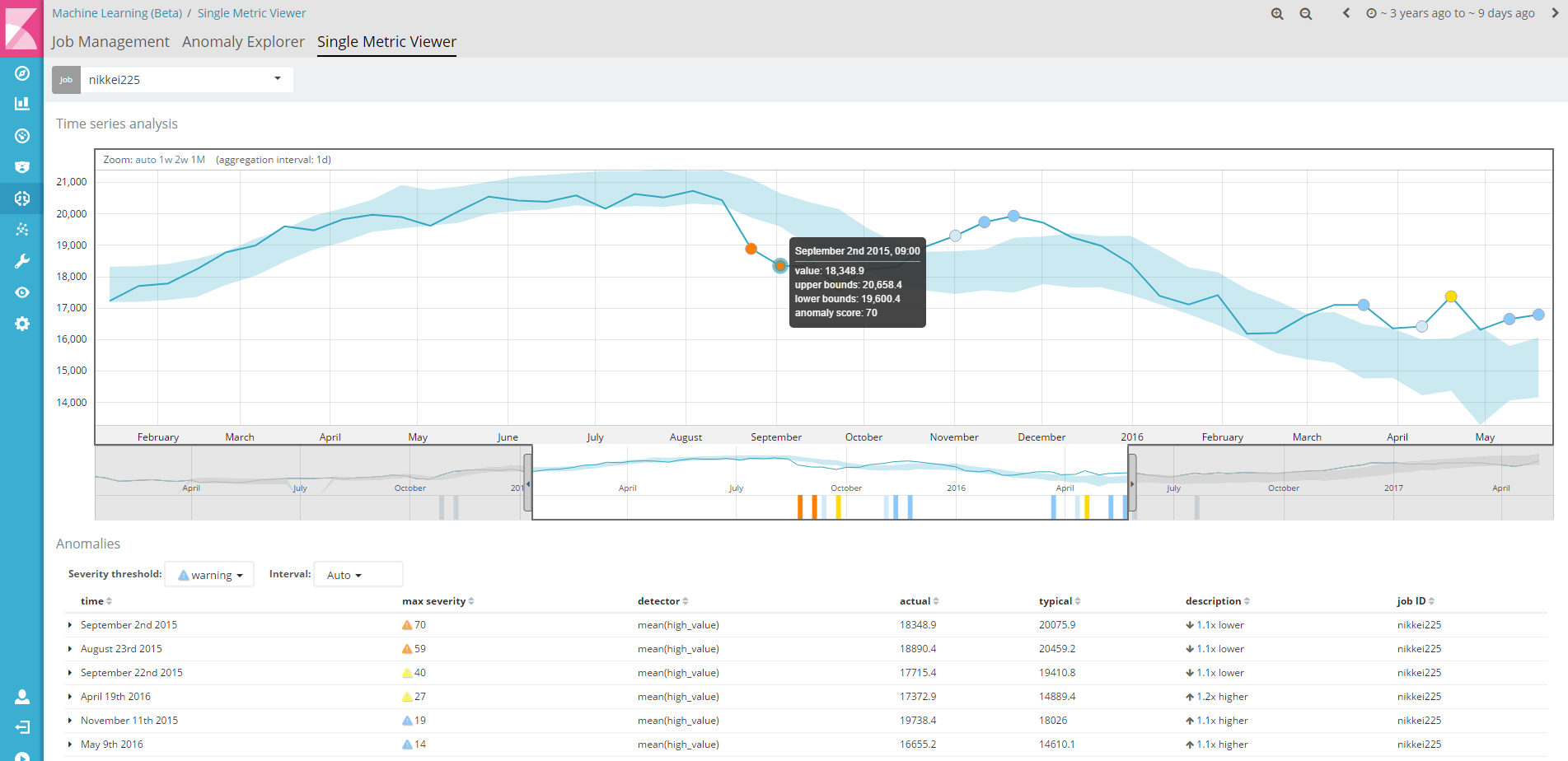
2015年8月23日~9月2日ぐらいのデータで、期待している値より(1.1倍ほど)低いとして異常が検知されました。
どうらやチャイナショックの時期だったようです。
なんとなく、それらしいアノマリーを検知してますね!
Anomaly Explorer
こちらの画面では、より異常だと検知された場所が分かりやすくなっています。
オレンジ色が濃いほど異常である確率が高いと。
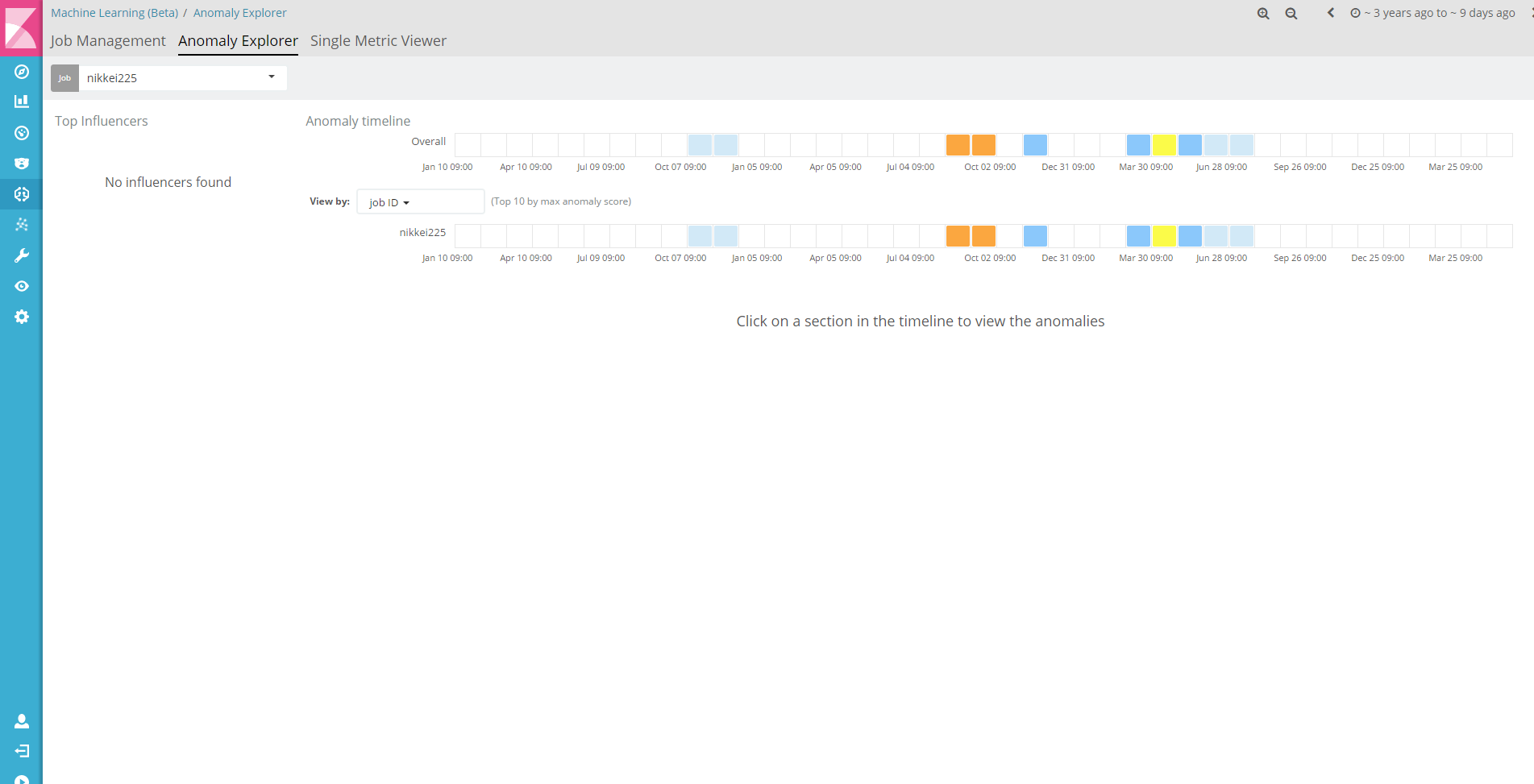
1つのデータだとまったく味気ないので、他にもjobを作って、複数のJobと重ね合わせてみたりすると良いと思います。
今度はTOPIXのデータをひっぱってきて、topixというindexにいれ、同じようにJobを作成して並べてみます。
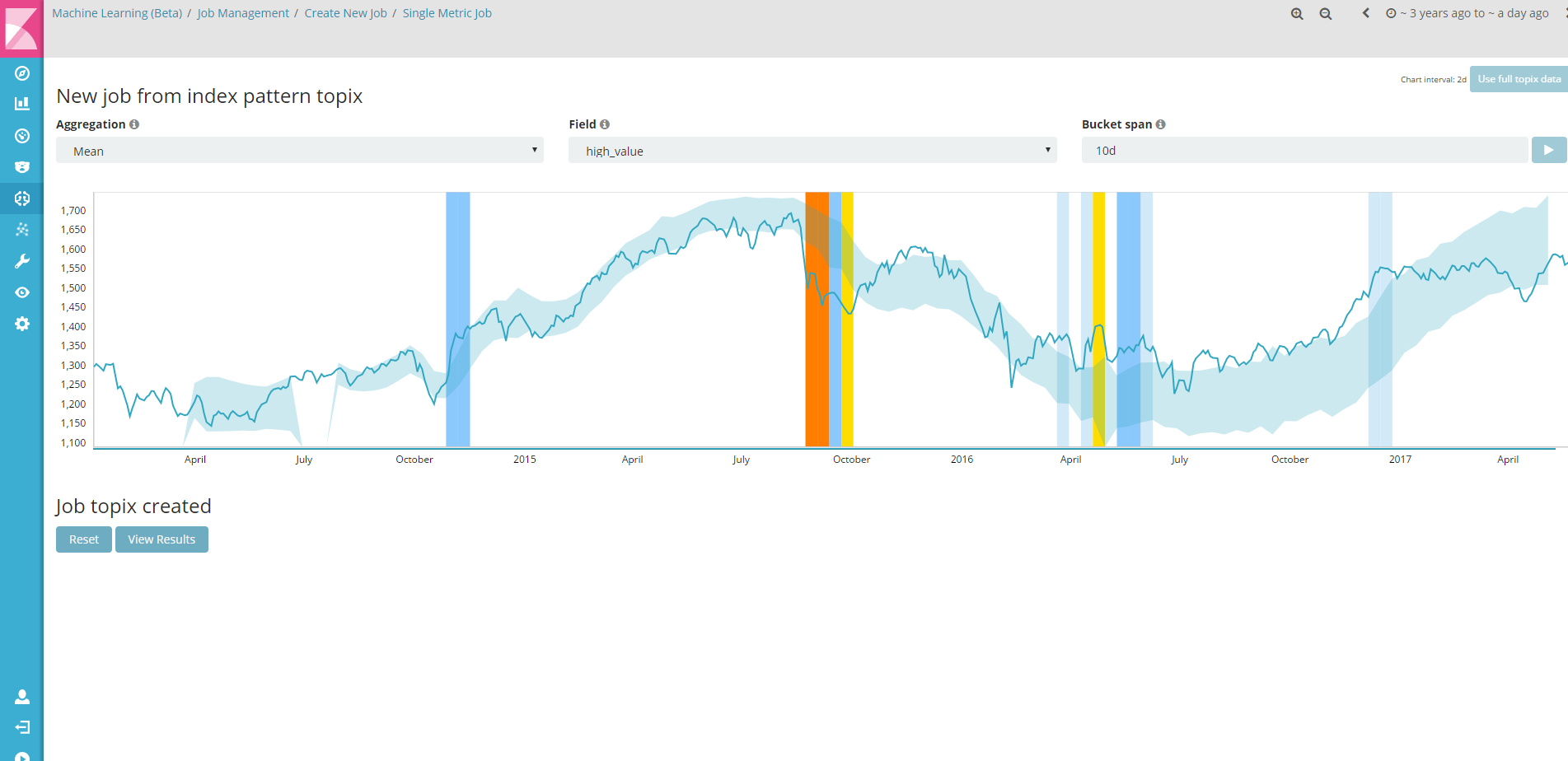
Anomaly Explorerの画面で、jobのプルダウンを選択すると、jobのチェックボックスが表示されます。
ここで先ほど作成したtopixを選択し、Applyボタンを押下します。
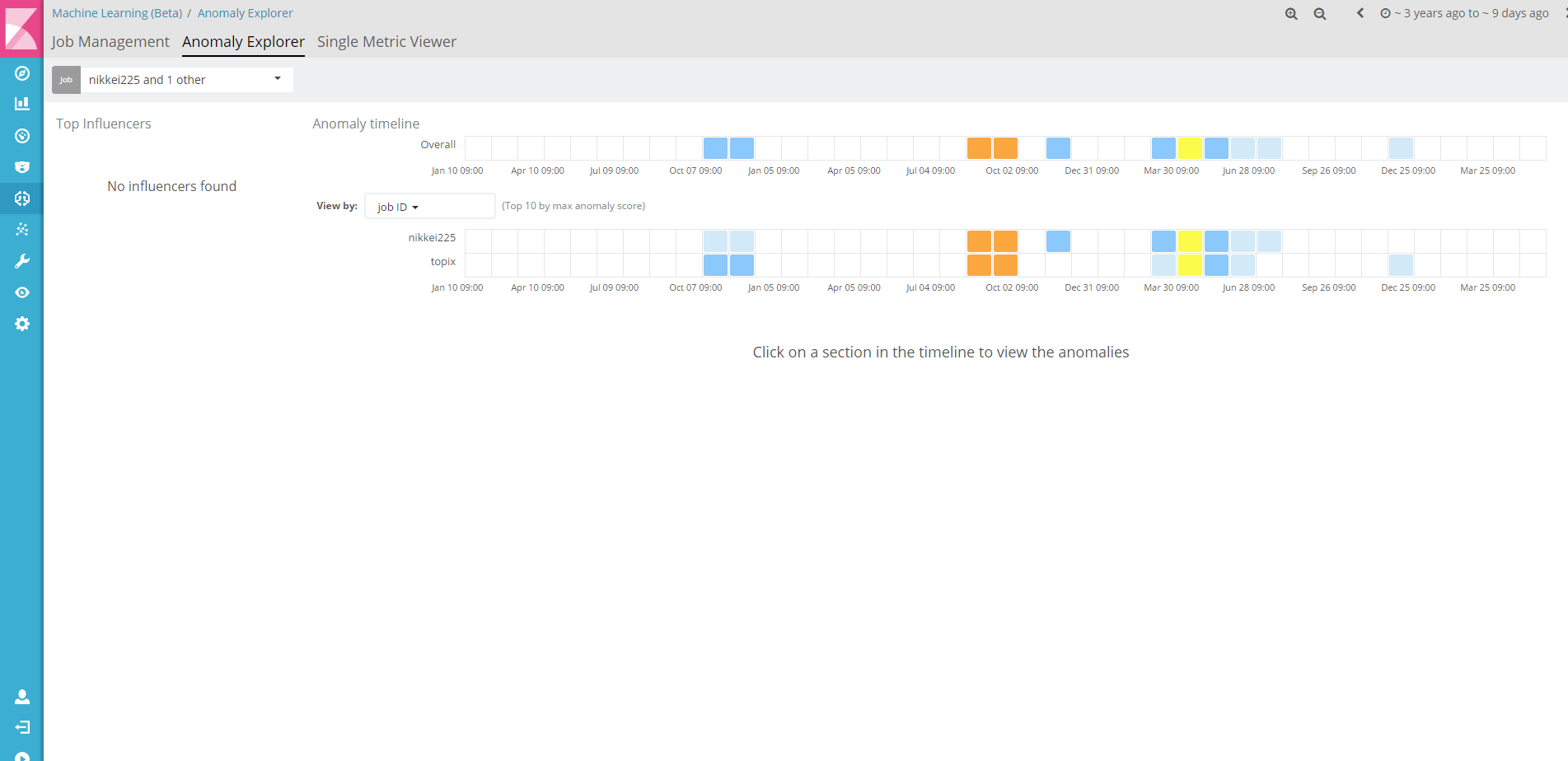
Anomalyだと判定されている部分が同じBucket10日でも、日経平均とTOPIXでは異なる個所があることが分かりますね。
ここに自社の株価なんかを合わせてみると、もっと面白いかもしれません。
(株式分割してたりすると面倒だけども)
おまけ
Bucket sizeを大きくしたり、小さくしたりするとどうなるの?ということで、3パターン用意してやってみた。
| job name | bucket size |
|---|---|
| nikkei225_5d | 5d |
| nikkei225 | 10d |
| nikkei225_20d | 20d |
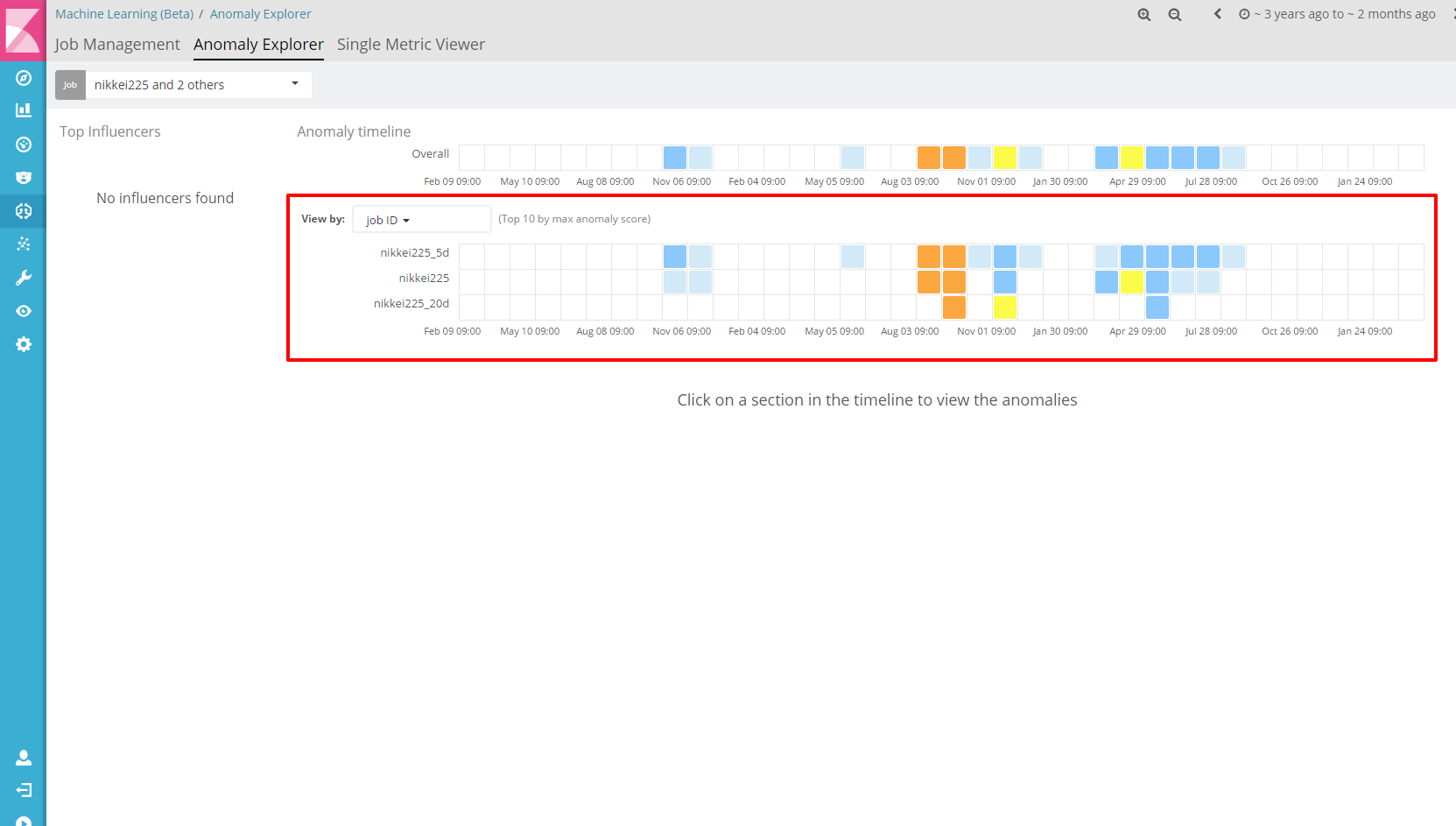
Bucket sizeが大きくなるごとに検出されている部分が減ってきていることがわかります。
本当に異常値だったところが抜けていないかどうか、Bucket sizeが適正なのかどうかは注意する必要がありますが、
小さすぎてもダメ、大きくすぎてもダメということは分かります。
20dでも検出されるチャイナショック。よっぽどだったのだろう。
雑感
ここまで、データをダウンロードしてこの画面を出すまで10分ぐらいです。
この記事用にキャプチャ撮ったりして書くのに40分ぐらいです。
実用するには、もっと細かな設定をする必要があるのだと思いますが、
まず試してみる、というレベルの人が簡単に試せる、そこに時間がかからない、というのは大変良いです。
特に難しい知識なしに、教師無しの異常検知がElasticsearchに入れるだけで使える(正確にはサブスクリプションを買うんですが・・・)のは素敵です。
そのうち勉強会などで、ぞくぞく事例が発表されることでしょう。期待しています。