概要
The Future of Attachments for Elasticsearch and .NETで紹介されているingest-attachmentプラグインを使って、PDFやOfficeファイルをElasticSearchに登録してみます。
ingest-attachment入りの環境の構築
こういうのは面倒なので、Dockerでやります。
FROM elasticsearch:5.0.1
RUN /usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-attachment && \
chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/plugins
ビルドと起動
docker build -t estest:5.0.1 .
docker run --name estest -d -p 9200:9200 -p 9300:9300 estest:5.0.1
ちょこちょこ設定やIndexを確認するのにkibanaがあると便利なので、ついでにkibanaも立てておくとよろし。
docker run --name kibana -d -p 5601:5601 --link estest:elasticsearch kibana:5.0.1
ここで、kibanaにアクセスし、dev toolsより** GET _cat/plugins** を実行すると、ingest-attachmentが入っていることが確認できます。
XKHPlqb ingest-attachment 5.0.1
データ投入側の用意
使ったプログラムはこちらにあります。参照してください。
POCOの準備
Javaで言うところのPOJO、入れ物を用意します。
using Nest;
using System;
using System.Collections.Generic;
using System.Text;
namespace FutureOfAttachments
{
public class Document
{
public int Id { get; set; }
public string Path { get; set; }
public string Content { get; set; }
public Attachment Attachment { get; set; }
}
}
Attachmentクラスでは、AuthorやContent、ContentLengthといったメタデータを保持できるようになっています。
Mappingとパイプラインの準備
マッピングの作成
var indexResponse = _client.CreateIndex(DocumentsIndex, c => c
.Settings(s => s
.Analysis(a => a
.Analyzers(ad => ad
.Custom("windows_path_hierarchy_analyzer", ca => ca
.Tokenizer("windows_path_hierarchy_tokenizer")
)
)
.Tokenizers(t => t
.PathHierarchy("windows_path_hierarchy_tokenizer", ph => ph.Delimiter('\\'))
)
)
)
.Mappings(m => m
.Map<Document>(mp => mp
.AllField(all => all
.Enabled(false)
)
.Properties(ps => ps
.Number(n => n
.Name(nn => nn.Id)
)
.Text(s => s
.Name(n => n.Path)
.Analyzer("windows_path_hierarchy_analyzer")
)
.Object<Attachment>(a => a
.Name(n => n.Attachment)
.Properties(p => p
.Text(t => t.Name(n => n.Name))
.Text(t => t.Name(n => n.Content))
.Text(t => t.Name(n => n.ContentType))
.Number(n => n.Name(nn => nn.ContentLength))
.Date(d => d.Name(n => n.Date))
.Text(t => t.Name(n => n.Author))
.Text(t => t.Name(n => n.Title))
.Text(t => t.Name(n => n.Keywords))
)
)
)
)
)
);
こうして登録したマッピングは、kibanaのdev toolsで取得してみると、こうなっています。
GET documents/_mapping

パイプラインの設定
_client.PutPipeline("attachments", p => p
.Description("Document attachment pipeline")
.Processors(pr => pr
.Attachment<Document>(a => a
.Field(f => f.Content)
.TargetField(f => f.Attachment)
.IndexedCharacters(-1)
)
.Remove<Document>(r => r
.Field(f => f.Content)
)
)
);
ファイルの登録
登録時に先に登録したattachmentsパイプラインを指定することで、ingest-attachmentによりContentに設定したBaseにエンコードされたファイルの中身からテキストやメタデータの抽出が行われ、Attachmentとして格納される、ということになるようです。
//contentはbyte[]
var base64File = Convert.ToBase64String(content);
var res = _client.Index(new Document
{
Id = 1,
Path = "あいうえお/かきくけこ/さしすせそ.docx",
Content = base64File
}, i => i.Pipeline("attachments"));
Console.WriteLine(res.DebugInformation);
登録の結果確認
3つのファイルを登録してみました。
- WIkiLeaksのPDF CIA report into shoring up Afghan war support in
Western Europe - 東京都教育委員会発行のPDF 児童・生徒質問紙調査、学校質問紙調査の結果から
- 文部科学省が出しているExcel 「諸外国の教育統計」平成26(2014)年版
Program.csでAddAttachmentとしている部分が該当します。
sample.CreateMapping()
.PutPipeline()
.AddAttachment(1, new Uri(@"https://file.wikileaks.org/file/cia-afghanistan.pdf"))
.AddAttachment(2, new Uri(@"http://www.kyoiku.metro.tokyo.jp/press/2016/pr161110b/besshi2.pdf"))
.AddAttachment(3, new Uri(@"http://www.mext.go.jp/b_menu/toukei/data/syogaikoku/__icsFiles/afieldfile/2015/07/17/1352615_01_1.xlsx"))
;
Program.csを実行してインデックスの作成からデータの登録までを行います。
WikiLeaksのPDFの確認
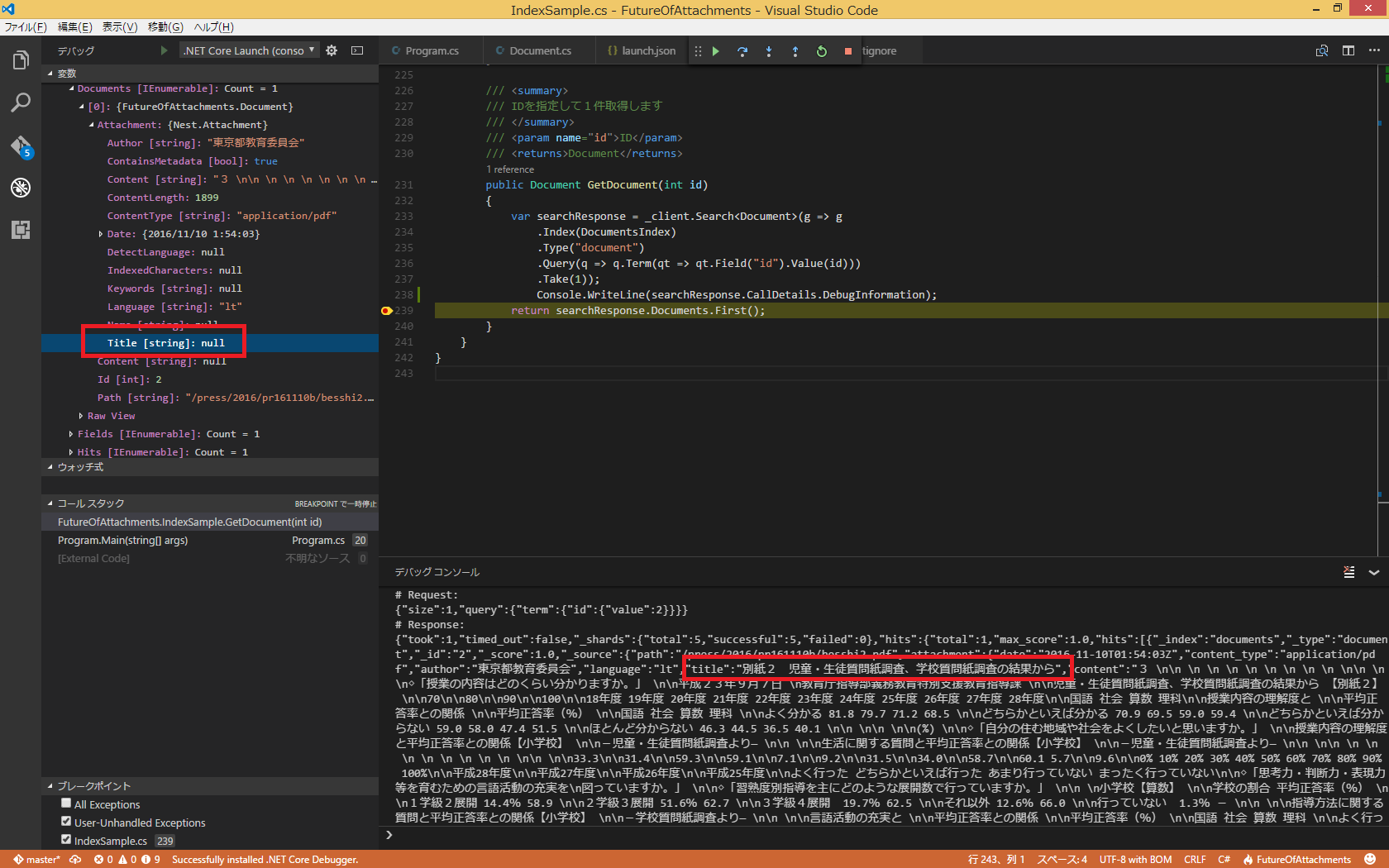
GET documents/document/1
PDFからauthor, language, content(本文), titleが抽出され格納されていることが確認できます。
東京都教育委員会発行のPDF
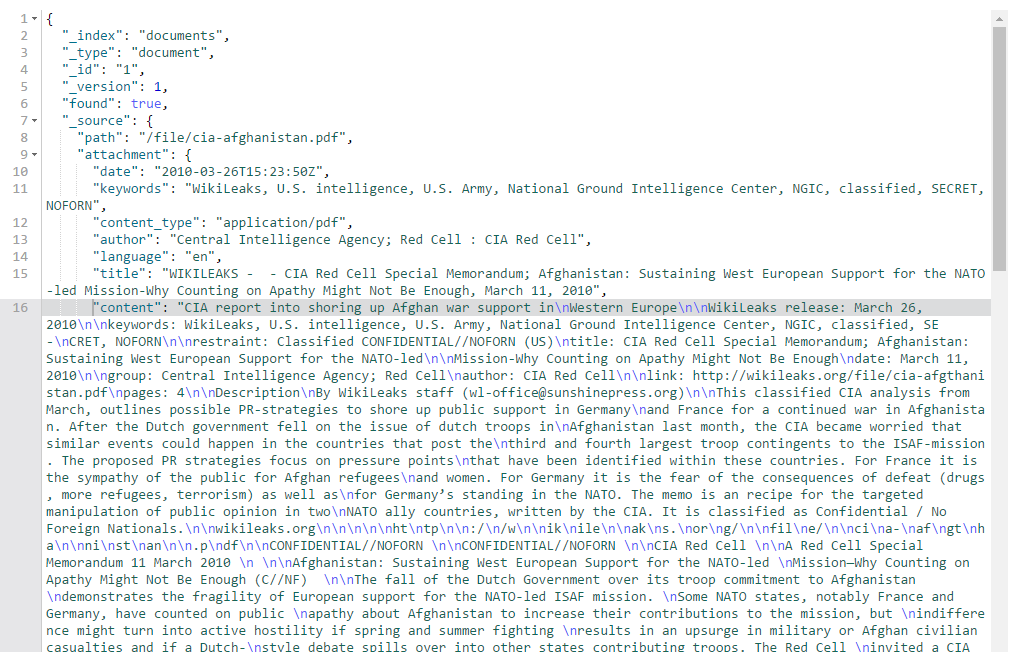
GET documents/document/2
先ほどと同様にtitleやauthorは正しそうに見えますが、languageがltになっています。リトアニア語になっています。
文部科学省が出しているExcel
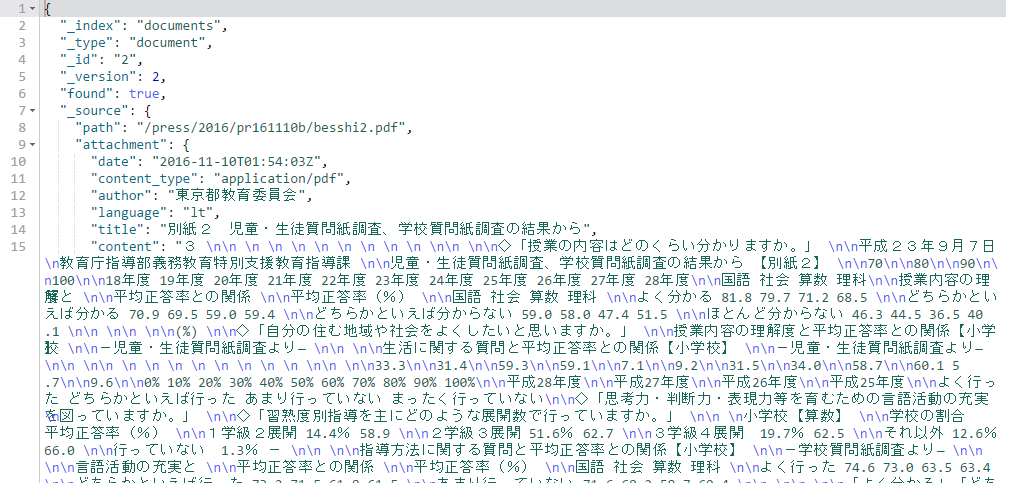
GET documents/document/3
今度こそリトアニア語ではなく、jaと判定されることを望むも・・・ダメっ!
中身の言語判定は、languageではなく、DetectLanguageを見るのが良いようです。
ただし、Nestのコメントを見る限り、デフォルトではdisableとなっているため、null値となるようです。
/// Detect the language of the attachment. Language detection is
/// disabled by default.
POCOへのマッピングの確認
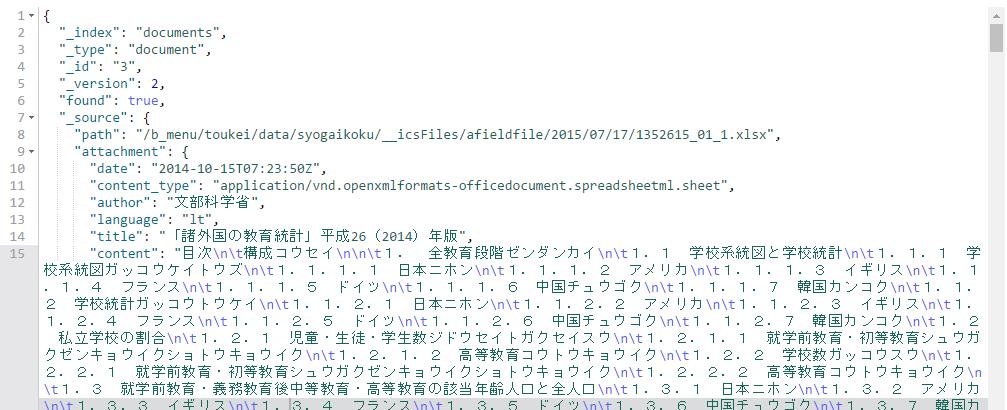
検索結果がDocumentに入ることを確認します。
//Documentの取得
var result = sample.GetDocument(2);
//ファイルの情報を表示してみる
Console.WriteLine($"Author = {result.Attachment.Author} / Content = {result.Attachment.Content}");
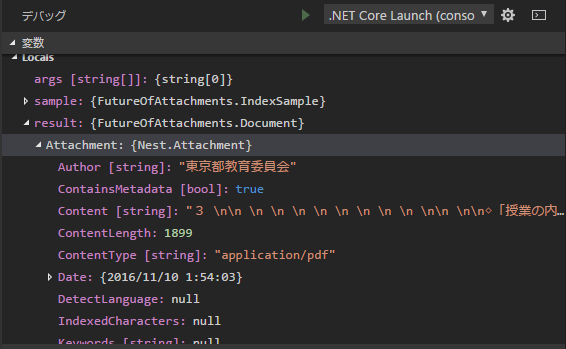
Debug実行して、適当にとめてやると、Documentの下でAttachmentに値が格納されていることが確認できます。
まとめ
ingest-attachmentを使うと、ファイルの中身を送り付けるだけでテキスト抽出、メタデータの抽出ができることがわかりました。
自分だけのオリジナルの属性や処理の追加も、pipelineの仕組みやNestを使うことで出来そうな予感です。
疑問点
Nestで検索したをDocumentに格納してくれるはずなのだけども、Titleフィールドの値が抜けてしまっている。
AuthorやContent、languageといった値はしっかり入っているのに。
投げたリクエストとレスポンスを出力していて、返されたjsonにTitleが含まれていることは確認できるのに、Document.Attachment.Titleの値はNull。