はじめに
この記事はElastic stack AdventCalendar 14日目の記事になります。
技術的深い内容はございません。トリビアの泉で言うところの5へぇぐらいを目指します。
さて、ここから本題。
Elasticsearch, Kibana, Logstash, BeatsなどElastic stackに関わるコミュニティベースのフォーラムがあることをご存じでしょうか?
英語だからといって、尻込みすることはありません。
日本語しか無理!という(私のような)方でも、質問したり、回答したりすることができるのです。
「Elastic In Your Native Tongue」のところに「日本語による質問・議論はこちら」があります。
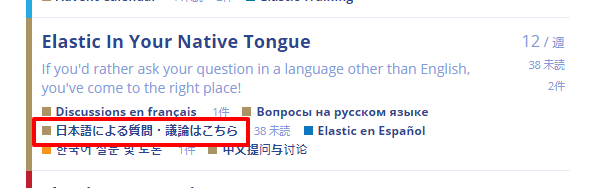
Elastic社や、サポートを生業としている会社からサポートを受ける、というのが一番確実で早いところでしょうが、
そうでない場合でも「何かできる場所」が設けられているのは心強いですね。
今回は、Elastic stackのフォーラムをElastic stackで可視化する、ということをやってみます。
前準備
気になることを整理する
- 以前は大谷さんばっかりが回答していた。今はどうなのか。
- Native Tongueには日本語以外もある。海外と日本では違うのか。
これらを確認してみることにします。
ここでやりたいことを整理しておかないと、どういう設定、どういうデータを取り込めばいいのかが決まりませんしね。
使用する環境
| プロダクト | バージョン | 動作環境 |
|---|---|---|
| Elasticsearch | 7.0.0-alpha1 | Docker |
| Kibana | 7.0.0-alpha1 | Docker |
Elasticsearchには、analysis-kuromojiプラグインをインストールします。
データについて
フォーラムはdiscourseという製品をお使いのようなので、こちらが提供するREST APIを利用してデータをとってくることにします。
https://www.discourse.org
API定義については、こちらにあります。
https://docs.discourse.org
ここのswagger.jsonをそのままswagger editorに読み込ませると、エラーだらけとなりクライアントの自動生成ができません。
仕方なく、自分でAPIを叩くことにしました。
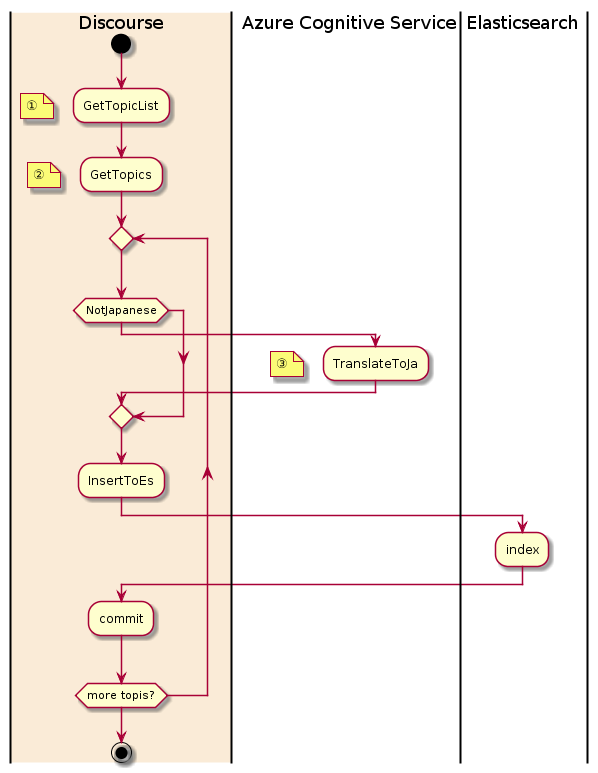
データ取得からIndexまでの流れ
| No | 処理 | 参考 |
|---|---|---|
| ① | フォーラムのカテゴリを指定してトピックのリストを取得します | 日本語トピックの場合 https://discuss.elastic.co/c/11/18.json |
| ② | ①で取得したトピックのIDを指定して投稿の詳細を取得します | トピック詳細のURL https://discuss.elastic.co/t/{id}.json |
| ③ | 日本語以外のトピックについては、読めるようにAzure Congnitive Serviceを呼び出して日本語に翻訳します |
カテゴリ11がNative Tongueで、その下のカテゴリIDが各言語になります。具体的には以下のIDとなっています。
| 言語 | カテゴリID |
|---|---|
| 日本語 | 18 |
| 韓国語 | 38 |
| 中国語 | 46 |
| フランス語 | 16 |
| ロシア語 | 15 |
| スペイン語 | 24 |
日本語に翻訳してるのは、タグクラウドで表示したときに、他言語だと全く分からないからです・・・。
あとBulkでElasticsearchにINSERTする方が良いのはもちろんなのですが、便宜上1件ずつ入れてます。(RESTのAPIもsleep入れながら取っているため、Esに1件ずつ入れてもあまり変わらないから)
Elasticsearch設定
今回は、日本語と海外では投稿に違いがあるのか、これをタグクラウドで見てみたいと思いましたので、タグクラウドに出したい言葉を名詞にしようと思い、不要な品詞をひたすら除外する設定を書きました。
今になってよく考えると、動詞はあった方が良かったかもしれません。
品詞一覧は、kuromoji-analysisのstoptags.txtを見ながら設定しました。
https://github.com/apache/lucene-solr/blob/master/lucene/analysis/kuromoji/src/resources/org/apache/lucene/analysis/ja/stoptags.txt
実際に設定した内容はこちら。
"analysis": {
"analyzer": {
"kuromoji_analyzer": {
"tokenizer": "kuromoji_tokenizer",
"filter": [
"remove_filter"
]
}
},
"filter": {
"remove_filter": {
"type": "kuromoji_part_of_speech",
"stoptags": [
"名詞-非自立",
"名詞-非自立-一般",
"名詞-非自立-副詞可能",
"名詞-非自立-助動詞語幹",
"名詞-非自立-形容動詞語幹",
"名詞-特殊",
"名詞-特殊-助動詞語幹",
"名詞-接尾",
"名詞-接尾-一般",
"名詞-接尾-人名",
"名詞-接尾-サ変接続",
"名詞-接尾-助動詞語幹",
"名詞-接尾-形容動詞語幹",
"名詞-接尾-副詞可能",
"名詞-接尾-助数詞",
"名詞-接尾-特殊",
"名詞-接続詞的",
"名詞-動詞非自立的",
"名詞-引用文字列",
"名詞-ナイ形容詞語幹",
"名詞-代名詞-一般",
"名詞-代名詞-縮約",
"名詞-数",
"接頭詞",
"接頭詞-名詞接続",
"接頭詞-動詞接続",
"接頭詞-形容詞接続",
"接頭詞-数接続",
"動詞",
"動詞-自立",
"動詞-非自立",
"動詞-接尾",
"形容詞",
"形容詞-自立",
"形容詞-非自立",
"形容詞-接尾",
"副詞",
"副詞-一般",
"副詞-助詞類接続",
"連体詞",
"接続詞",
"助詞",
"助詞-格助詞",
"助詞-格助詞-一般",
"助詞-格助詞-引用",
"助詞-格助詞-連語",
"助詞-接続助詞",
"助詞-係助詞",
"助詞-副助詞",
"助詞-間投助詞",
"助詞-並立助詞",
"助詞-終助詞",
"助詞-副助詞/並立助詞/終助詞",
"助詞-連体化",
"助詞-副詞化",
"助詞-特殊",
"助動詞",
"感動詞",
"記号",
"記号-一般",
"記号-読点",
"記号-句点",
"記号-空白",
"記号-括弧開",
"記号-括弧閉",
"記号-アルファベット",
"その他",
"その他-間投",
"フィラー",
"非言語音",
"語断片",
"未知語"
]
}
}(以下略)
いざ確認せん!
データをいれ、Visualizationを作っていきます。
大谷さんの回答率は!?
1つのトピックは、複数のポストが紐づいています。
実際に取得できるjsonはこんな感じです。
https://discuss.elastic.co/t/144014.json
post_stream.postの配列を1つずつElasticsearchに取り込んだdocumentを使用します。
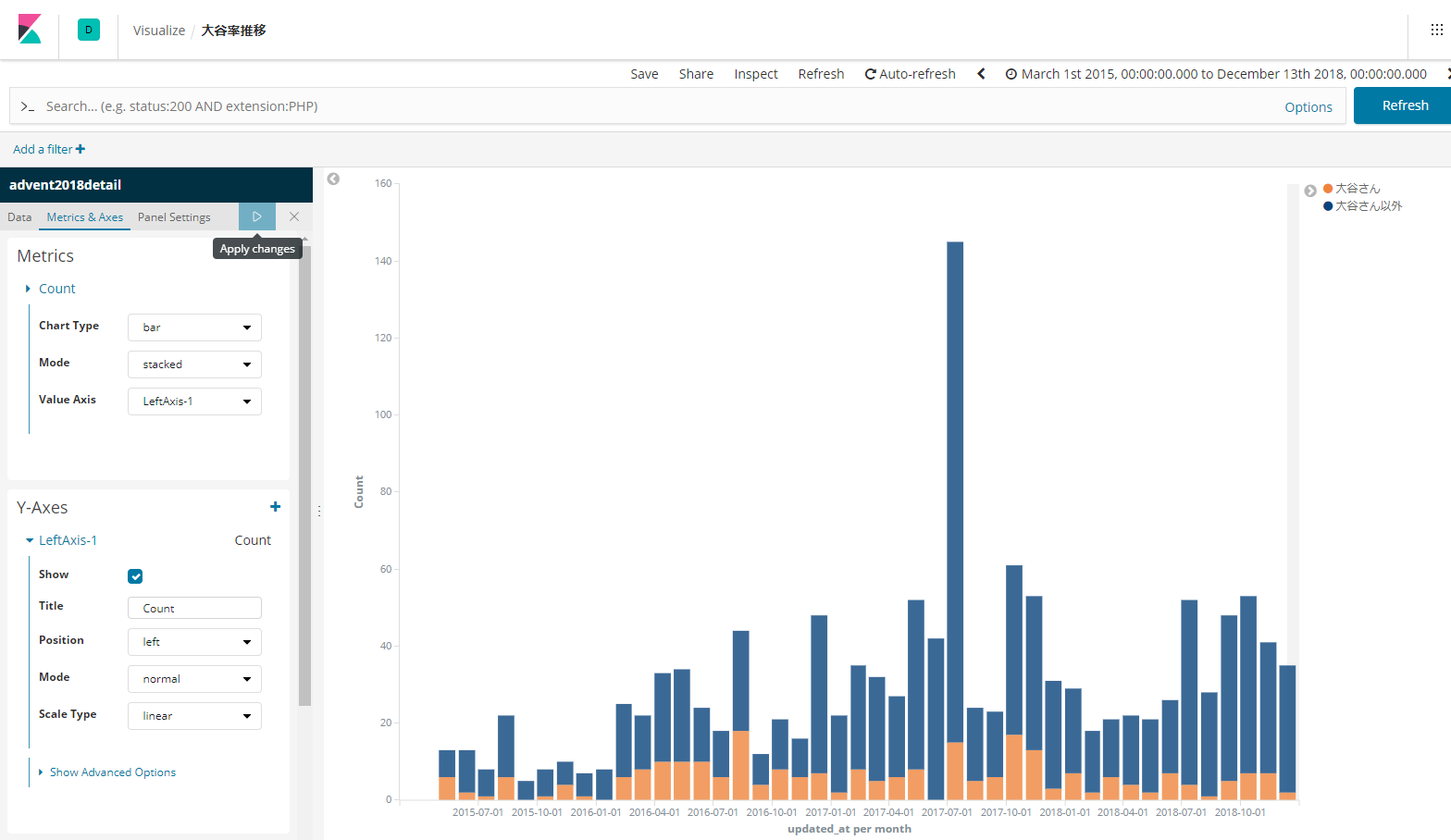
filterで大谷さんと大谷さん以外を出せるようにし、今回は割合を見たいので、percentageをMetrics&Axesタグから指定します。
すると、どうでしょう。
ちょっとずつ減っているような傾向が見えますね。
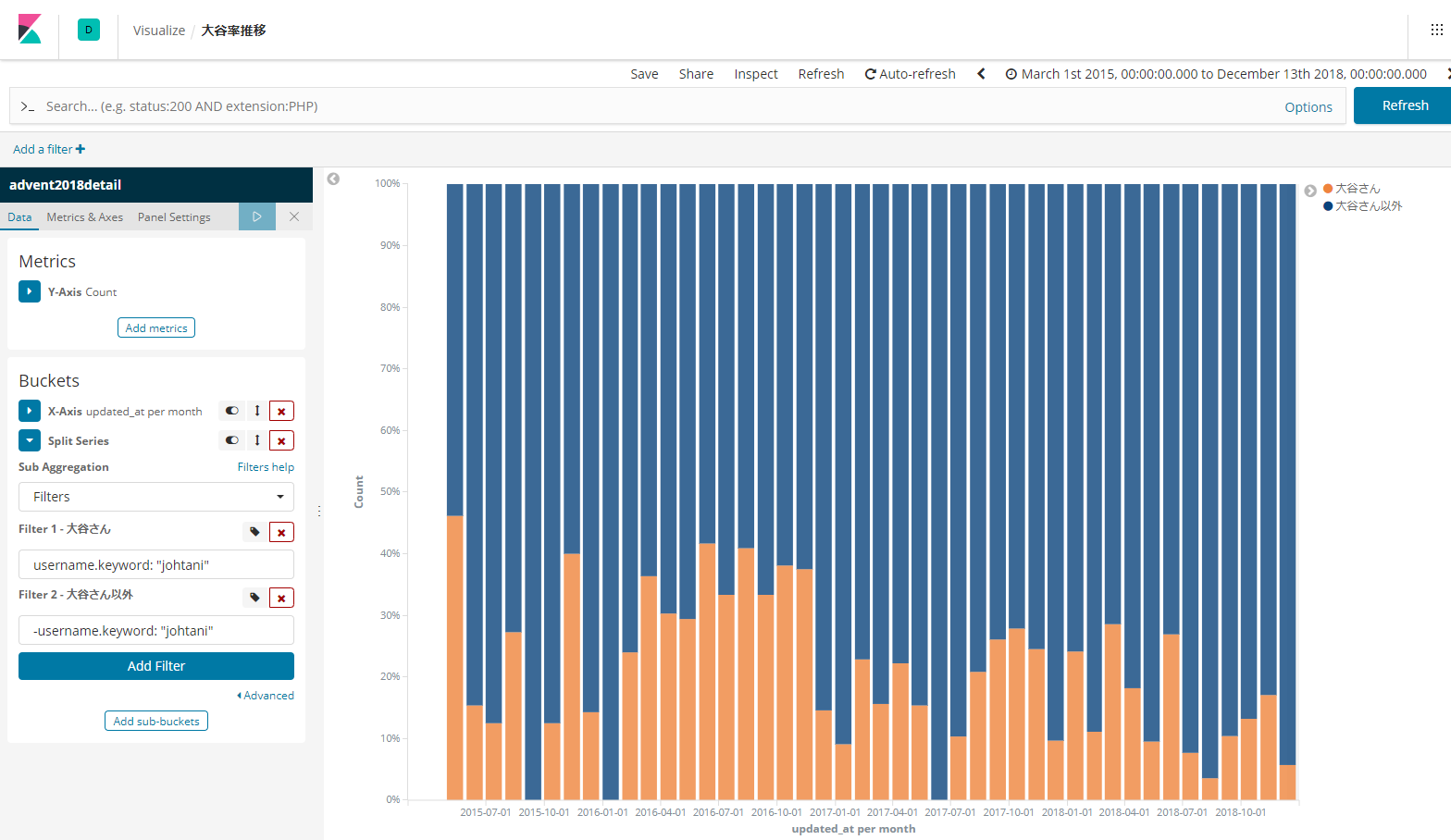
念のため、normalで表示すると、こうなります。
全体として投稿件数は微増しているので、大谷さん以外の方の投稿が増えた、と言えそうです。
年毎の回答者のトップ10を円グラフにしてみると、こうなります。
回答者というのは、トピックの最初の投稿者でない人をカウントしています。
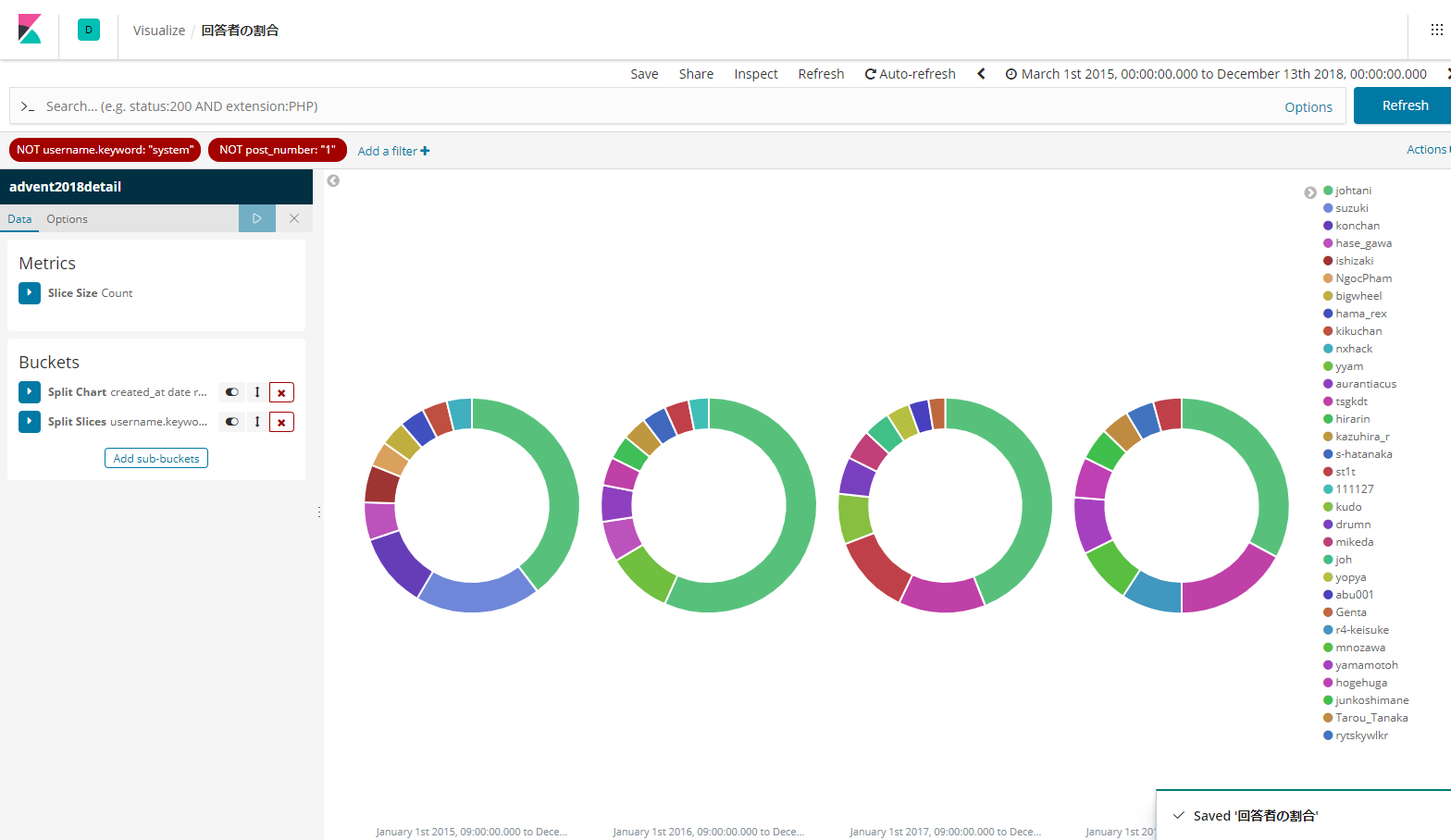
左から2015年、2016年、2017年、2018年となります。
2018年のを見ると、多くの人がそれなりの割合で参加されていることが分かりますね。
それでも大谷率は圧倒的です。
海外との差はある!?
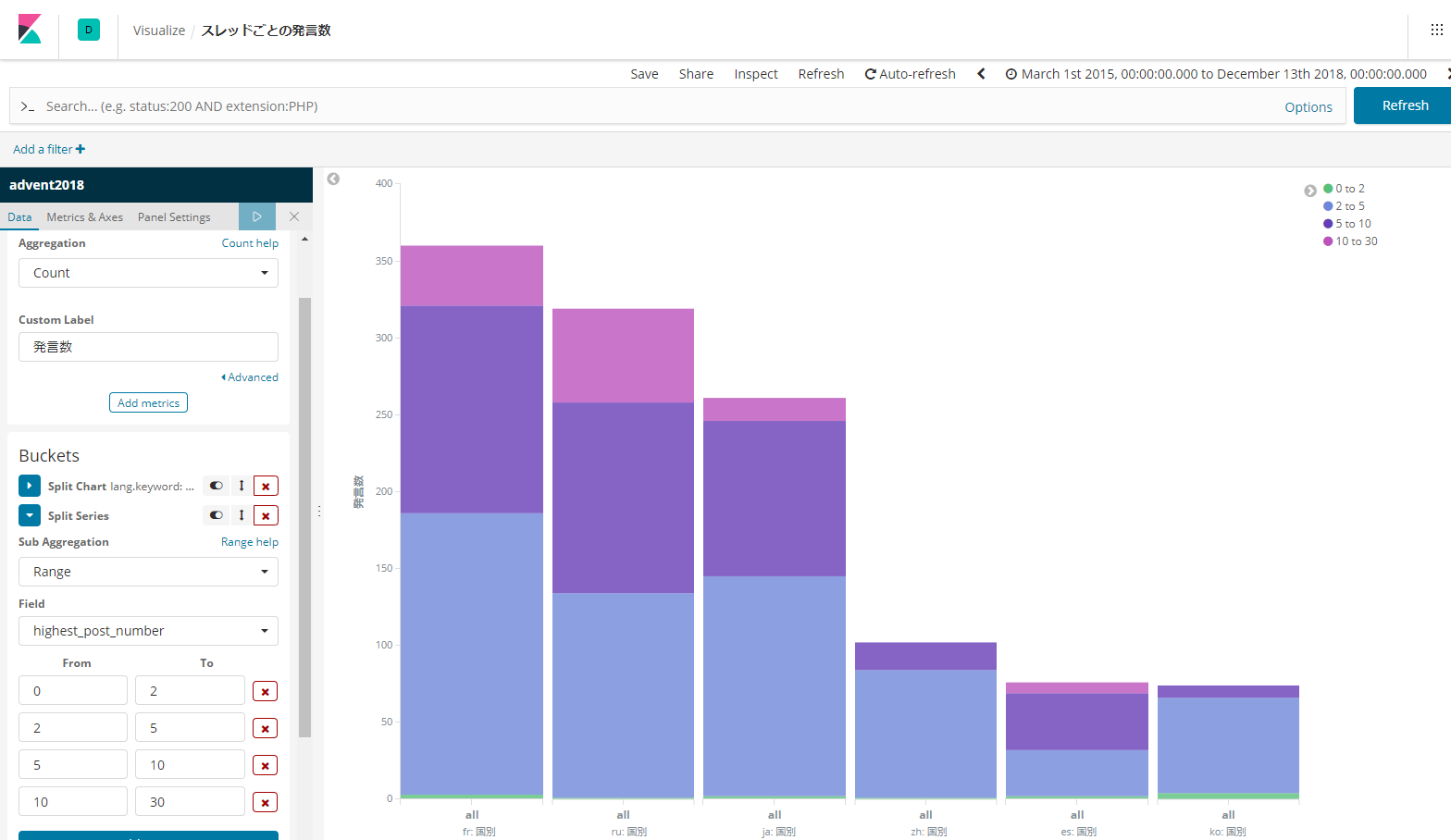
1つのトピックにつくポストの数
トピックに必ず回答がつくとは限らないのがツライところではありますが、頻繁にレスがつくのもあるようですが1トピックあたりの発言数を国ごとにカウントしてみます。
トピックのjsonのルートに、highest_post_numberという値があり、ここにポスト数が入っているので、これを数えます。
フランス、ロシアはトピックの全体数が多いのもありますが、10発言以上ついているトピックも多いですね。
そう思うと、スペインも10~30を示す色のところが多いです。
ヨーロッパの方は、気軽にコメント、極東の方は比較的慎重、そういう感じなのでしょうか。
初回のレスがつくまでの時間
トピックのポストの0番目と1番目の投稿時間の差から、どのぐらいで最初のレスがつくかを見てみます。
これはデータを入れるときにPythonのソースで計算しました。
1日以内、1日~10日以内、10~20日以内のレンジで平均初回レス取得までの時間を描画するようにします。
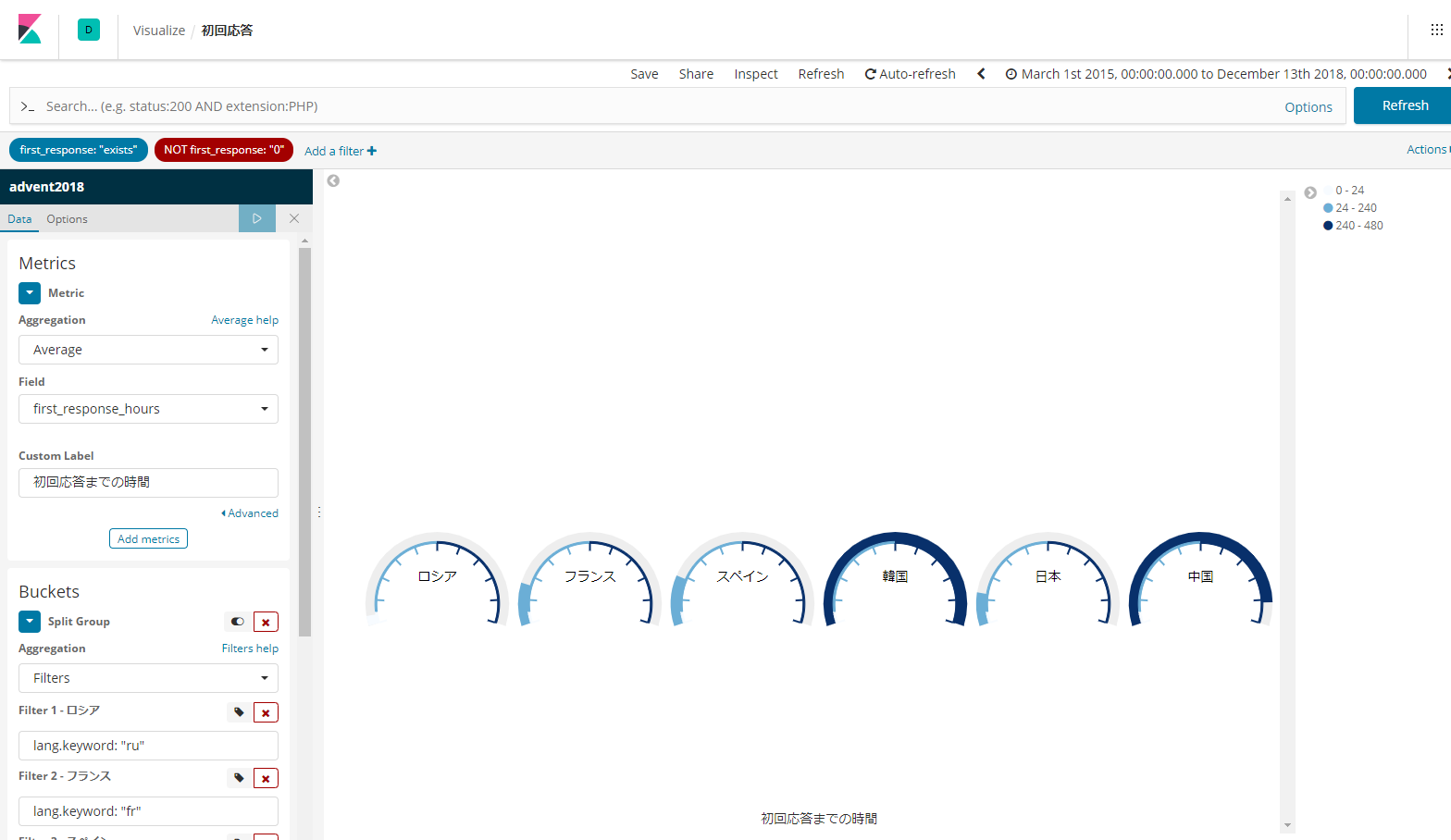
定量的にはテーブル形式に見たほうがイメージがつきやすいですかね。
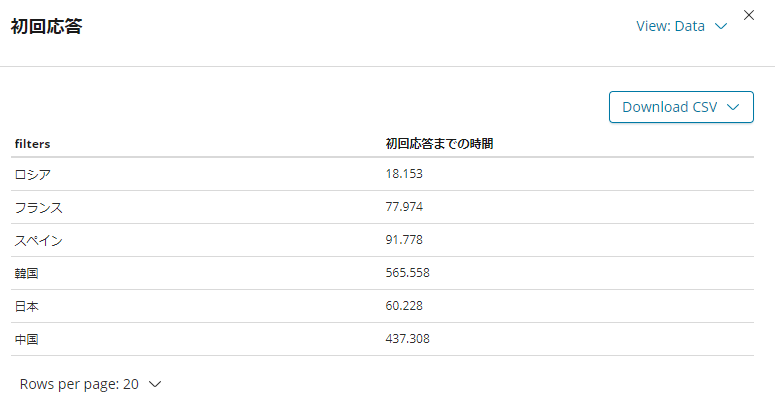
これを見ると、ロシアが最速です。
全くレスがつかずに自動クローズされたものがあったとしても、平均18時間台というのは驚異的です。
上の1トピックあたりのポスト数もロシアは多いため、もっと中身を詳しく見たくなりますね。
気軽に投稿している感じなのかどうかを確かめたくなるところです。
こうやって見ると、日本は結構がんばってますね。
もっと気軽に投稿してもいいんじゃないかと思います。
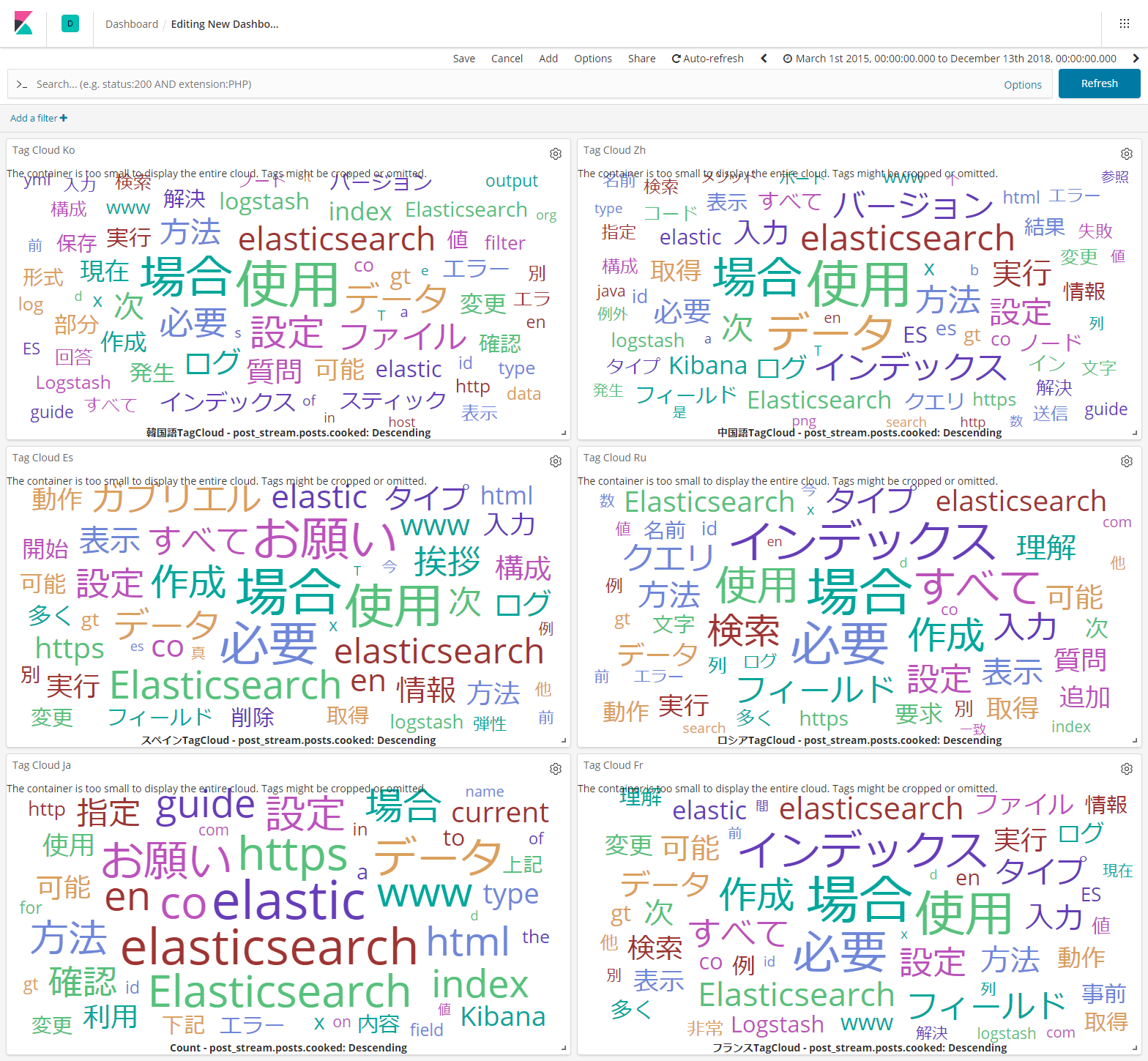
発言タグクラウド
どんな言葉を使ってんのかな?ということで、Azureの翻訳サービスに投稿内容を食わせて取得した日本語をTag Cloudで表示したものがこちら。
posts.coockedに投稿内容が入っているので、これを先に示したanalyzerで処理して表示させています。
もう少し違った感じになるのか?と予想していたのですが、思いのほか似たり寄ったり。これは期待外れです。
Elasticを弾性と訳してしまうあたり、AzureさんもAzure Searchで使っているのだから頑張って欲しいところです。
おわりに
Elastic stackのユースケースが多岐に渡り、いろんな使い方ができるからこそ、様々な質問が生まれてきます。
ズバリ回答とならなくても、ちょっとしたヒントで解決につながることもあると思います。
コードが書けなくても、英語ができなくても、本を執筆する熱量がなくても、Elastic社のサブスクリプションを買ってなくても、Elasticの認定エンジニアになってなくても、
フォーラムで困っている人の手助けをすることができます。
コミュニティが盛り上がるのは、良いことですね。
またいろんな人のユースケースを知り、自分の勉強にもなります。こういう場合ってどうすればよいんだっけ?というサポートSEの訓練にも最適!
(聞くところによると、認定試験の試験方法は、1人きりになれる部屋で、Webカメラで3時間ぐらい監視されながら用意されたVMを使って課題に取り組むという内容だとか。)
コミュニティといえば、先日、こんなイベントがあったそうです。

最後に、みなさま! 2019年5月30日はあけときましょう!!!
今半弁当が私を待っている!?
明日15日目のAdvent Calendarは、@j-yamaさんの「Reactivesearchで検索用WEB GUIを作る」です。
j-yamaさんは、Elastic stackの1週間の情報の収集と紹介をしているElasticloverの運営をされている方ですね。
ご期待ください。