私は、AIシステム開発で、おもにクラウドや機械学習の基盤の構築や保守を担当しています。
たま~~に分析もします。世間一般でいうところの「データエンジニア」とか「機械学習エンジニア」的な仕事をしています。
MLOpsって?
MLの開発運用においては、まずデータサイエンティストがデータを分析し、できた特徴量やモデルの成果を、本番システムに乗せ、オンライン予測やバッチ予測を稼働させる、というのが流れです。これには、データ分析以外にも、たとえば再現性の担保や、リリースされているモデルのバージョン管理、データのバージョン管理、データと学習/予測コードとモデルのバージョンの構成の管理、データドリフトの監視など、モデル成果を継続してカスタマーに届けるための取り組みが必要で、これをMLOpsと呼んでいます。従来のソフトウェアにおける「DevOps」という概念に、「データ」と「モデル」という存在が加わった感じです。
コードとリリース以外にバージョン管理するものがある
機械学習プロジェクトでバージョン管理するものは、「コード」だけではなく、前述した「データ」と「モデル」にもバージョンという概念があります。それぞれのバージョン管理が必要になる理由は、データは実験の再現性の担保やデータドリフトの検知、モデルは、学習コードやデータと関連付けて性能の比較を行ったり、KPIとの関係を追ったりするためだと思います。
そして、ここにデータリネージという概念も入ってきます。
- 「どのデータで」「どのバージョンのコードで」特徴量計算した結果が、「どのデータ」なのか
- 「どのデータで」「どのバージョンのコードで」学習を行った結果が「どのモデルなのか」
- 「どのデータで」「どのモデルで」予測した結果が「どのデータ」なのか
- 「いつから」「どのモデルが」リリースされているのか
こういったものをうまく紐づけるのが、難しいなと感じています。
dvcでコードベースなMLOps
開発初期はこういった課題はExcelやナレッジベースに、リリース更新などのたびに紐づけ関係を書いていくなどの運用でカバーする方法はできるのですが、成果物の複雑な依存関係は、なるべく機械にやらせたいというのが人間の性。
この課題にはdvc (Data Version Control)というオープンソースツールが、iterativeによって開発されており、GitHubで入力データやモデル出力物とコードの依存関係を、コードベースで管理できるようになっています。
dvcでできること
- データのバージョン管理
- データやモデルの中身が変わったら、ハッシュ変換値をファイルに記録して、実体は外部に保管
- パイプライン定義
- パイプラインのステージと、入力依存や出力物のコードベースな定義
- パイプライン実行
-
dvc reproコマンド一つで、gitのコミットと紐づいたパイプライン実行
-
- メトリクス追跡
たとえば、dvcのチュートリアルガイドにある下記のコードですが、
dvc run -n prepare \
-p prepare.seed,prepare.split \
-d src/prepare.py -d data/data.xml \
-o data/prepared \
python src/prepare.py data/data.xml
実行するコマンド本体は一番最後のpython src/prepare.py data/data.xmlですが、この処理が何に依存しているのかを上のオプションで定義しているイメージです。
- パイプラインのステージ名は
prepareである - このステージが依存するパラメータ(入力パラメータ)は
prepare.seedとprepare.split(params.yamlに定義してある) である - このステージが依存するデータ(入力データ)は
src/prepare.pyとdata/data.xmlである - このステージの出力は
data/preparedである
そして、これを実行すると、通常通りの処理が実行されると同時に、これらの依存関係がdvc.yamlというファイルに記録されます。
stages:
prepare:
cmd: python src/prepare.py data/data.xml
deps:
- src/prepare.py
- data/data.xml
params:
- prepare.seed
- prepare.split
outs:
- data/prepared
このようにステージの定義をつなげていって、一つのパイプラインを作っていくと、dvc.yamlにパイプライン内のステージの依存関係や、ステージ内のファイルやパラメータの依存関係が記録されていき、最終的にはdvc reproを実行すると、パイプラインを実行することができます。
このパイプラインの入出力であるデータやモデルですが、dvc add data/data.xml data/preparedと実行すると、dvcによるバージョン管理下に入ります。
具体的には、これを実行すると
- データファイル(data/data.xmlやdata/prepared)がgit管理下から外れる
-
.dvcというファイルに、データがmd5ハッシュ変換されて記録される - データは、リポジトリ外のストレージや指定した外部ストレージにバックアップされる
ので、データの代わりにこの.dvcファイルをgitでバージョン管理することで、データやモデル成果物のバージョンも管理できるということですね。
KubeflowでワークフローによるMLOps
さて、dvcでデータ、コード、モデルのバージョンは紐づけられそうです。
しかし、本番に乗せた場合は、ほかの外部のシステムと連携しながら動く場合がほとんどで、
- パイプラインを「どのパラメータで」「いつ」実行したのか
- 「いつ」「どのモデルが」リリースされているか
- その結果はどこに出力・転送されているか、保管されているか
- ジョブの成否履歴
を管理したくなってきます。「いつ」に関する管理はdvcだとちょっと弱い気がしています。
これに関しては、KubeflowやApache Airflowといったワークフローエンジンがソリューションの選択肢に入ってきます。
Google Cloud Platformユーザであれば、Vertex AIをつかうことでKubeflowをマネージド環境で利用することができます。
私としては、
- パイプラインをGUIで組む(コードベースでもできる)
- ダッシュボードUIで日々の実行の成否を追跡する
- Vertex AI Metadataを使って、そのそれぞれの実行がどのパラメータで動いたのかが記録として残される
これがなかなかイケてると思います。
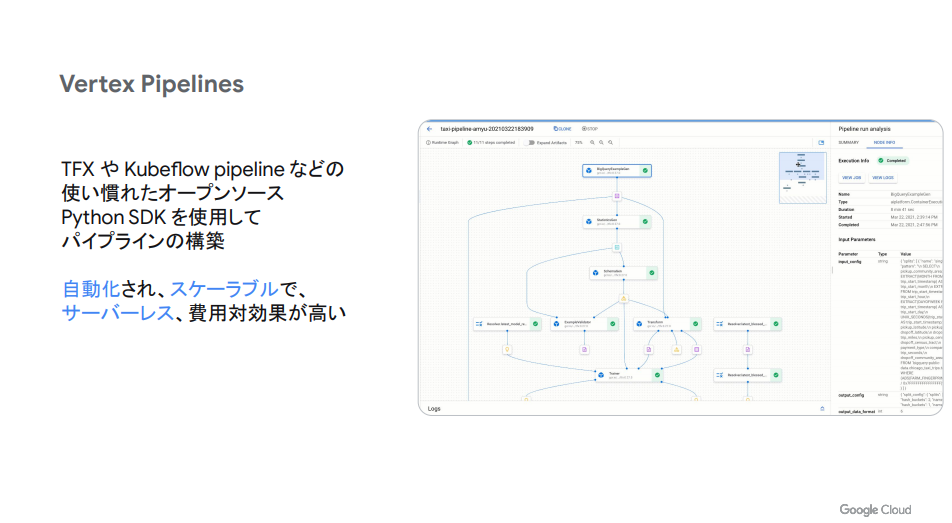
https://lp.cloudplatformonline.com/rs/808-GJW-314/images/Ask_the_Expert_Session3.pdf より引用
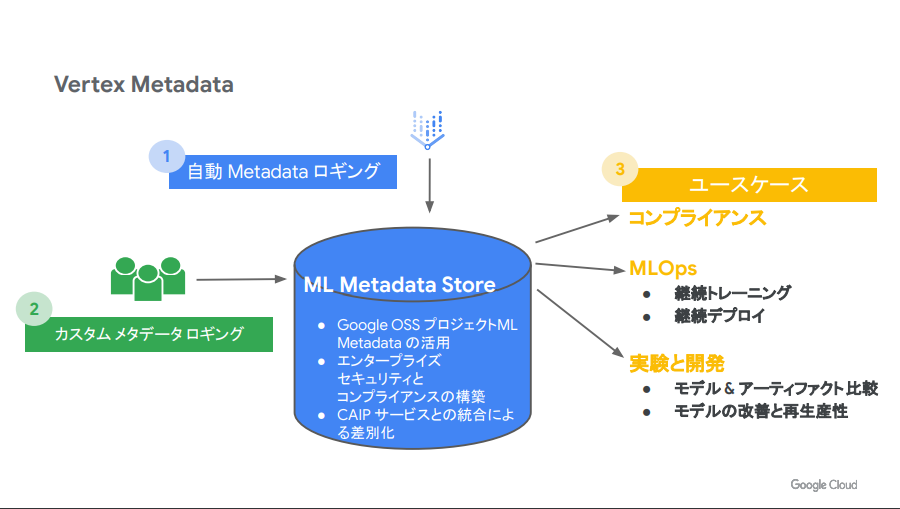
https://lp.cloudplatformonline.com/rs/808-GJW-314/images/Ask_the_Expert_Session3.pdf より引用
Vertex AIは割と新しいサービスで、GoogleCloudも開発にかなり力を入れているようです。
私はまだこのサービスに対する知識が乏しく、YouTubeに解説動画(英語)がたくさん上がっておりましたので、それを見て頑張って勉強しようと思います。
https://www.youtube.com/watch?v=gT4qqHMiEpA
まとめ
・・・と、なんかちょっと中途半端な感じで終わってしまいそうになりましたが、
機械学習エンジニアリング(MLSE)は比較的新しい領域であり、大変そうだな~と思うと同時に「ワクワクする」ような仕事だと思います。
これからも「イケてる」機械学習基盤の構築のため努力していく所存ですので、またいつかのアドベントカレンダーでお会いしましょう。