概要
Oracle DatabaseのReal Application Testing(RAT)は、Oracle Databaseに対するテストを効率よく実施するためのOracle Databaseの機能です。
RATの主要機能であるDatabase Replay(DB REPLAY)を利用することで、Oracle Databaseサーバーに対する「システムテスト(負荷テスト)」を効率よく実施することができます。DB REPLAYは、実際にアプリケーションを動作させていたている環境(本番環境など)でデータベースへのリクエストのワークロードを記録し、テスト環境で再現します。システム変更(サーバーの変更など)の前後で、スループットやリソース使用量を比較できます。
本記事では、RATのDB REPLAYの評価をはじめる方(使ってみよう、という方)を対象に、評価を始めるためのスタートとなる手順(SQL,PL/SQLの実行環境でできるもの)を紹介します。**DB Replayのもっとも簡単な動作確認の手順を説明します。**本記事を参照いただく前に下記の記事などを参照して、RATのDB Replayがどのようなものか、どのように動作するのか、おおよそ理解いただいていると、本記事の内容・手順も理解しやすいと思います。
シンジ&アヤノの実践データベース性能テストの極意:Oracle Real Application Testingを使ってみよう
【12c対応】とにかく苦労しない「RAT」簡単攻略テクニック
RATのもう一つの主要機能であるSPAに関しては、下記の記事などが参考になります。
Oracle Real Application TestingのSQL Performance Analyzerの活用:データベースのアップグレード(バージョンアップ)でのSQLテスト
Oracle Real Application TestingのSQL Performance Analyzerの簡単な動作確認の手順:COMPARE_RESULTSETの動作確認
本記事で説明する内容は、DB REPLAYをコマンドラインで動作させるための一番簡単な手順です。本記事では、非常に少ない(簡単な)SQLの実行だけをキャプチャしてリプレイさせています。
DB REPLAYは上記の紹介記事などでも説明がありますが、データベースへの「本番相当のワークロード」をキャプチャして、リプレイしてテストする、というのがツールの目的です。
本記事で利用しているような「少ないSQLの実行」でのキャプチャとリプレイ時のワークロードの比較は、本来のツールの指向からするとあまり意味はないと考えた方がよい、と思います。つまり、実際のDB RREPLAYの適用シナリオは、数種類のSQLだけを数分流したものをキャプチャ、リプレイする、というものではないです。単体のSQLの実行時の性能比較、という観点ではRATのSPAの方が使いやすい、と思います。
(とても軽いワークロードの全体の実行時間がリプレイ時に少し悪化する、という観点の調査は、それだけではシステム全体では意味がないことが多いと考えられます。)
2020年3月ごろの情報・環境を元に本記事は記載しています。
1. 本記事の作業の前提
本記事で紹介しているシナリオでは、Oracle Database 19cの環境で、非常に簡単なSQLを実行をキャプチャして、それを同じデータベース上でリプレイします。当然、実際の利用時はキャプチャとリプレイの環境が異なることが想定されます。本記事は、DB Replayのもっとも簡単な動作確認の手順を説明すること、としていますので1つのデータベースに対して実施します。(正確には、本記事の例では1つのマルチテナント構成のデータベース上の、2つのPluggable Database=PDBを利用しています。)
本記事の作業を実行するには下記が必要です。
- RATがインストールされている19cの環境のOracle Databaseインスタンス
- SQLの実行環境
本記事の中では、SQLの実行環境としてデータベースサーバー上のSQL*Plusを利用します。データベースサーバー上にキャプチャしたファイルなどの出力がありますので、サーバーにログインして、それを確認しながら進めると動作の理解がしやすいと思います。
19cのデータベースは、マルチテナント構成で2つのPDB(PDB1とPDB2)を作成しています。記事の中では2つのPDBを利用していますが、1つのPDBあるいはマルチテナント構成でないデータベースでも、本記事の手順を少し変更することで同様に動作確認を実行できます。
2つのPDBそれぞれにTCUSERというユーザーを作成して、connectロール,resourceロールとUSERS表領域へオブジェクトを作成できるような権限を付与しています。
CREATE USER tcuser IDENTIFIED BY tcuser;
GRANT CONNECT,RESOURCE TO tcuser;
ALTER USER tcuser QUOTA UNLIMITED ON users;
利用したマルチテナント構成のCDB$ROOTとPDB1,PDB2には、それぞれ(接続文字列なしか)CDB,PDB1,PDB2という接続文字列で接続できるようにしています。記事の中では、どのデータベースのどのユーザーで接続して作業しているのか認識する際の助けになると思います。
$ sqlplus system/(パスワード) <- これでCDB$ROOTに接続できるように設定しています。
(略)
SQL> show con_name
CON_NAME
------------------------------
CDB$ROOT
$ sqlplus tcuser/tcuser@pdb1 <- これでPDB1に接続できるように設定しています。
(略)
SQL> show con_name
CON_NAME
------------------------------
PDB1
$ sqlplus tcuser/tcuser@pdb2 <- これでPDB2に接続できるように設定しています。
(略)
SQL> show con_name
CON_NAME
------------------------------
PDB2
2. 本記事の作業の流れ
本記事で紹介しているDB Replayの動作確認の手順の流れを図で説明します。流れをおおよそ頭に入れておくと、実際の作業の理解がしやすいと思います。まずは、DB Replayの最初のステップであるキャプチャの前の準備です。
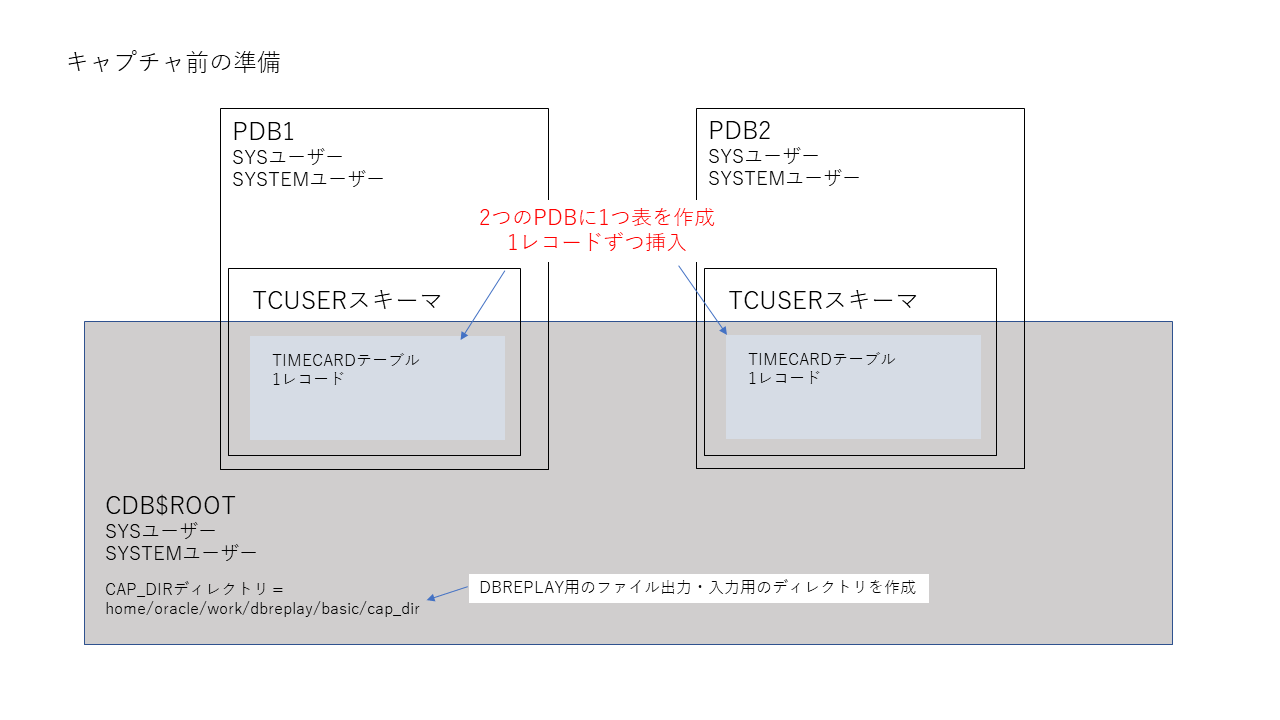
キャプチャ対象は非常に小さなトランザクションにします。その対象とするスキーマに表(TIMECARD)を作成し、キャプチャ前の状態として1レコード入力しておきます。これは2つのPDBで同じように実行しておきます。
DB Replayのキャプチャでは、キャプチャしたファイルをデータベースサーバーのファイルシステム上に出力します。ファイルの出力先となるディレクトリオブジェクト(CAP_DIR)を作成します。
続いてDB Replayのキャプチャを実施します。
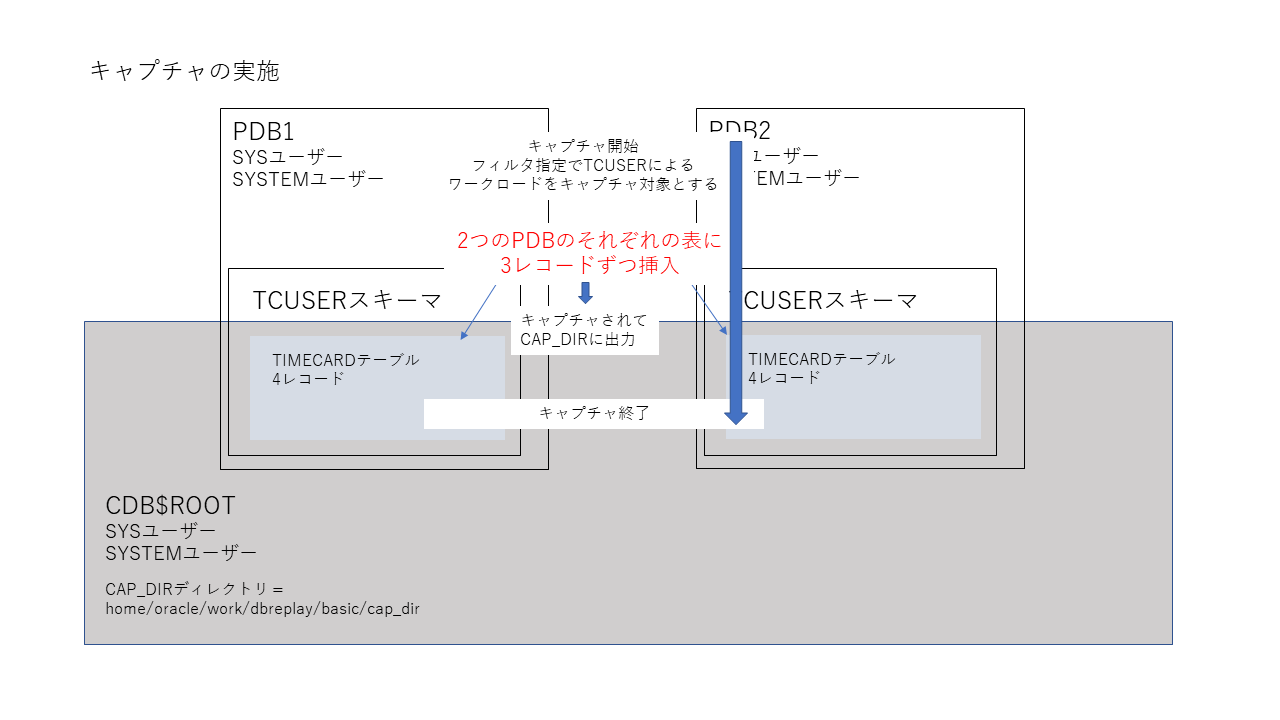
DB Replayのキャプチャを開始するときに、特定のユーザー(この記事の例ではTCUSERからのリクエストのみキャプチャする)ことを指定します。キャプチャ開始後に、3レコードのINSERTを実行します。これがキャプチャされます。その後キャプチャを終了します。次はリプレイ前の準備です。
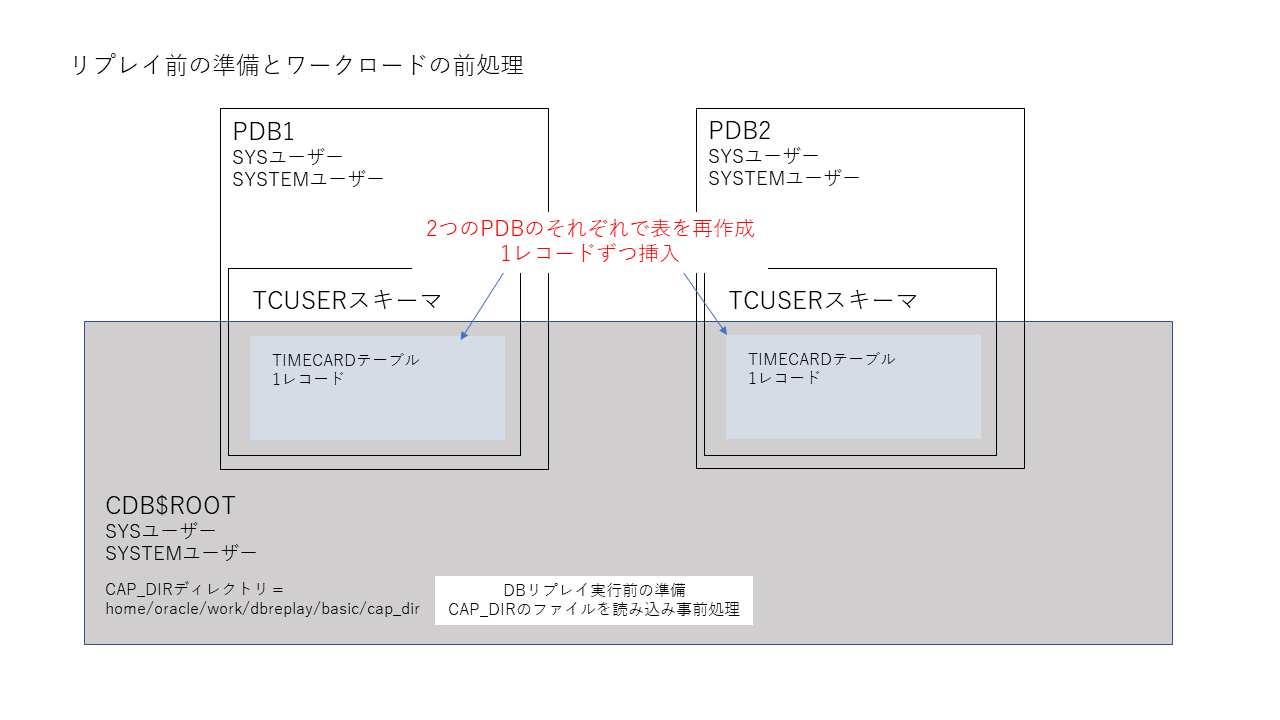
通常リプレイは、キャプチャとは別環境になるわけですが、この記事では同じ環境で実行します。リプレイ前に、キャプチャ開始時点と同じような表の状態(1レコードだけが入力された状態)にします。
実システムでDB Replayを実行するときは、このリプレイ前にキャプチャ開始時点のデータベースの状態をどのように作るか、というのはポイントになります。これはRATの機能ではありません。datapumpを利用したり、rmanのバックアップを利用したり、といったことが考えられます。
またDB REPLAYでは、実際のリプレイを実行する前に、キャプチャしたファイルを読み込んで事前処理を実行する必要があります(プロセスとかプリプロセスとか呼びます)。準備が完了したらリプレイを実行します。
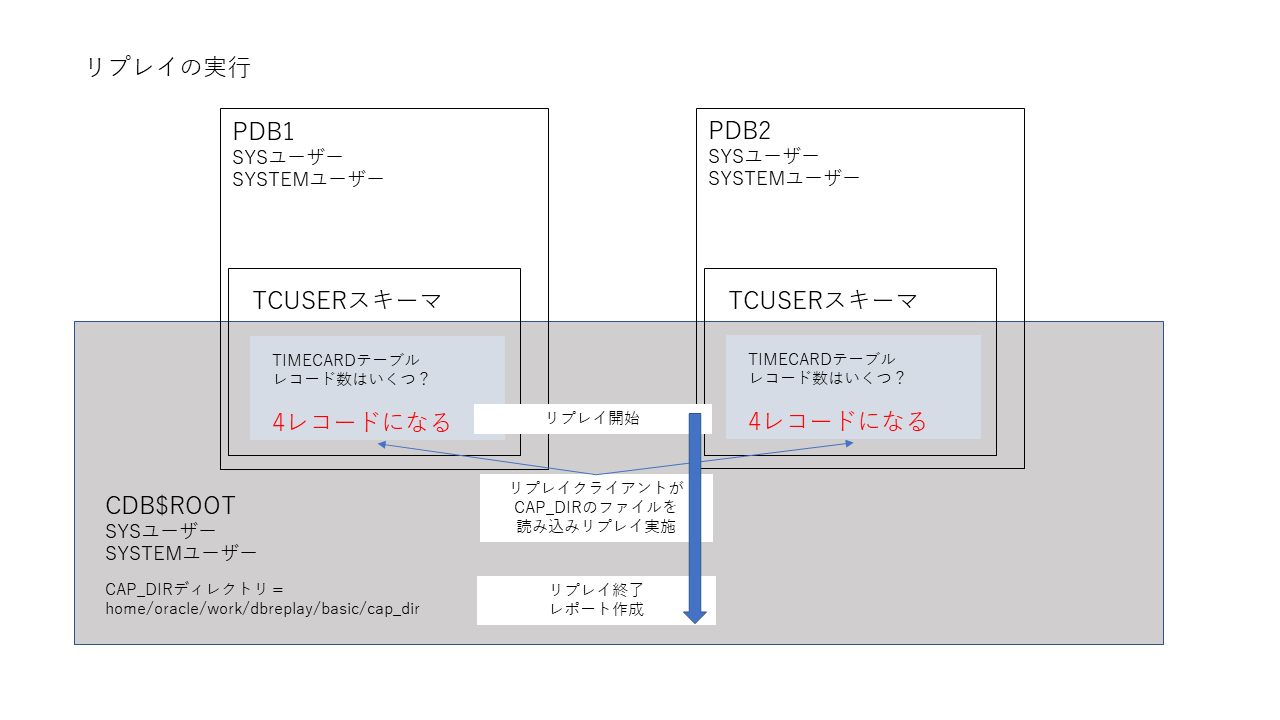
リプレイを実行すると、キャプチャした内容(本記事の例では2つのPDB上の1つの表、それぞれに対する3レコードの入力だけです)が実行されたことを確認します。またDB Replayのレポートを出力させます。本記事での、リプレイされたことの動作確認はレコードが入力されたことで実施しています。
実際にDB Replayを活用する場合は、DB Replayが作成するレポートや、キャプチャとリプレイのときに取得できるAWRレポート、リプレイ時のOSの負荷状況などを確認することになります。本記事は、DB Replayの動作手順の確認を目的にしているので、DB Replayが作成するレポートの読み方に関する詳しい説明はしていません。これに関しては下記のマニュアルが参考になります。
Oracle Database Testingガイド 19c - 13.1.3 ワークロードの取得レポートの確認
3. キャプチャ前の準備
ここから実際に実行した手順(SQL*PlusからのSQL,PL/SQの実行と一部サーバー上のシェルからのコマンド実行)を紹介しながら、DB Replayの動作確認をしていきます。
まず2つのPDBにそれぞれ作成済みのユーザー(tcuser)で接続して、本記事のテスト用の表(timecard)を作成し1行入力しておきます。
SQL> conn tcuser/tcuser@pdb1 <- PDB1に接続します。
Connected.
SQL> CREATE TABLE "TCUSER"."TIMECARD" ( "EMPNO" NUMBER, "WORKDATE" DATE, "DURATION" NUMBER);
Table created.
SQL> insert into timecard values ( 1, to_date('2014/11/1', 'YYYY/MM/DD'), 8);
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
SQL> conn tcuser/tcuser@pdb2 <- PDB2に接続します。
Connected.
SQL> CREATE TABLE "TCUSER"."TIMECARD" ( "EMPNO" NUMBER, "WORKDATE" DATE, "DURATION" NUMBER);
Table created.
SQL> insert into timecard values ( 1, to_date('2014/11/1', 'YYYY/MM/DD'), 8);
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
テスト用のスキーマtcuserに表timecardを作成して1レコード入力しています。続けてキャプチャファイルを出力するディレクトリに対してディレクトリオブジェクトを作成します。
SQL> conn / as sysdba <- CDB$ROOTにSYSで接続します。
Connected.
SQL> create or replace directory cap_dir as '/home/oracle/work/dbreplay/basic/cap_dir';
Directory created.
cap_dirという名前のディレクトリオブジェクトを作成しています。後続のDB REPLAYの実行の際、このディレクトリオブジェクトを指定します。ディレクトリオブジェクトは、サーバーの /home/oracle/work/dbreplay/basic/cap_dir というディレクトリを指してします。**ここで指定するディレクトリはOS上であらかじめ作成しておいてください。OSのoracleユーザーがファイルを出力できる権限があるディレクトリでなければなりません。**キャプチャの際、このディレクトリにたくさんのファイルが出力されます。
4. キャプチャの実施
キャプチャを実施します。
マニュアルでは、キャプチャを開始する前に、データベースの再起動することを薦めています。下記の記載を参照ください。
Oracle Database Testingガイド 19c - 10.3.1 データベースの再起動
このステップは必須ではありませんが、ワークロードの取得の開始前に進行中のトランザクションおよび依存トランザクションを確実に完了またはロールバックするために、その取得前にデータベースを再起動することをお薦めします。取得の開始前にデータベースを再起動しないと、進行中のトランザクションまたはコミット前のトランザクションは、ワークロードに完全に取得されません。
本記事のように、DB REPLAYの簡単な動作確認であればデータベースを再起動する必要はありません。
SQL> conn / as sysdba
Connected.
SQL> --define filter
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.ADD_FILTER (
3 fname => 'user_tcuser',
4 fattribute => 'USER',
5 fvalue => 'TCUSER');
6 END;
7 /
PL/SQL procedure successfully completed.
SQL> --start capture
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.START_CAPTURE (
3 name => 'BASIC_CAPTURE1',
4 dir => 'CAP_DIR',
5 default_action => 'EXCLUDE',
6 capture_sts => TRUE,
7 sts_cap_interval => 10);
8 END;
9 /
PL/SQL procedure successfully completed.
ここの例では、CDB$ROOTにsysで接続して実行していることに注意ください。Oracle Database 19c以降であれば、PDBに接続して実行することが可能になっています。
最初のDBMS_WORKLOAD_CAPTURE.ADD_FILTERでキャプチャを実施する際のフィルターの設定をしています。SQLをリクエストするユーザーとしてtcuserであることをフィルターとして指定しています。このパラメータに関しては下記のマニュアルの記載が参考になります。
Oracle Database PL/SQLパッケージおよびタイプ・リファレンス 19c - 183.3.1 ADD_FILTERプロシージャ
DBMS_WORKLOAD_CAPTURE.START_CAPTUREでキャプチャを開始します。キャプチャに名前をつけ、キャプチャしたファイルを出力するディレクトリとして、先に作成したcap_dirを指定しています。default_actionのパラメータでは、先に指定したフィルタをEXCLUDEで適用することを指定しています。先に指定した「リクエストしたユーザーがtcuserであるSQL」というフィルタをEXCLUDEで適用すると、tcuserによるSQLだけがキャプチャされます。
DB Replayのキャプチャの実行中にSTSを取得することができます。STS自体はDB Replayの動作には不要ですが、なんらかの調査・解析作業のためにSTSが有効になることもありえるので取得しておくこともできるようになっています。capture_stsをTRUEに設定している場合、STSを取得します。パラメータsts_cap_intervalは、このSTSをカーソルキャプチャから取得するインターバルを指定しています。
これらのパラメータの詳細に関しては、下記のマニュアルが参考になります。なおマニュアルに記載がありますが、**Oracle RAC環境でSTS取得はサポートされていないません。**RAC環境でこのcapture_stsをtrueにしている場合、キャプチャが正常にできないケースが報告されているのでfalseにします。
Oracle Database PL/SQLパッケージおよびタイプ・リファレンス 19c - 183.3.1 ADD_FILTERプロシージャ
キャプチャを開始した時点で、ディレクトリオブジェクトで指定したディレクトリを確認すると、下記のような「cap」「capfiles」というディレクトリと「wcr_xxx」というファイルが作成されていることがわかります。
$ ls
cap capfiles wcr_cap_0000000000072.start
このあとに実行されたデータベースに対するリクエストがキャプチャされることになります。
本記事では、キャプチャするためのSQLをPDB1,PDB2それぞれに対して実行します。
SQL> conn tcuser/tcuser@pdb1
Connected.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
1197 20-02-21 09:57:08 10
4186 20-02-21 09:57:08 9
9978 20-02-21 09:57:08 9
SQL> conn tcuser/tcuser@pdb2
Connected.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> insert
2 into timecard
3 values (
4 TRUNC(DBMS_RANDOM.VALUE(1000,9999),0),
5 sysdate,
6 TRUNC(DBMS_RANDOM.VALUE(1,14),0)
7 );
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
2465 20-02-21 09:57:08 10
3888 20-02-21 09:57:08 2
6349 20-02-21 09:57:08 10
それぞれのPDBの表timecardに対して3レコード追加しました。入力したデータには実行時点での日時と乱数を利用しているので、実際に入力されるデータは上記の例と同じにはなりません。
続けて、キャプチャを停止します。
SQL> conn / as sysdba
Connected.
SQL> --finish capture
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.FINISH_CAPTURE ();
3 END;
4 /
PL/SQL procedure successfully completed.
キャプチャが終了しました。キャプチャしたファイルが出力されているディレクトリを確認すると、作成されていた「wcr_xxx」というファイルがなくなっています。
$ ls
cap capfiles
リプレイを別環境のデータベースサーバーで実行する場合は、このディレクトリ以下のすべてを対象のデータベースサーバーへコピーします。
5. (オプション)キャプチャ後の作業
ここでは、キャプチャ後のオプションの作業としてキャプチャ中のAWRレポートを出力させる手順を紹介します。DB Replayのキャプチャを実行する際には、開始時と終了時にAWRのスナップショットが作成されています。これを使って、通常のOracle Databaseの性能解析でよく利用するAWRレポートを出力させます。DB Replayのリプレイのときも同じようにAWRレポートを出力させることができます。
AWRレポートを出力させなくてもDB Replayを動作させることは可能ですが、後の調査解析のためにキャプチャ時、リプレイ時のAWRレポートを出力させることをお薦めします。
ここではAWRレポートを出力させるためのスナップショットIDの確認方法を紹介します。スナップショットからAWRレポートを出力させる方法は通常の方法と同じです。
SQL> conn / as sysdba
Connected.
SQL> col name for a30
SQL> col status for a10
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM
6 (
7 SELECT id ,
8 name ,
9 start_time,
10 status ,
11 rank() over ( order by start_time DESC) rank
12 FROM dba_workload_captures
13 )
14 WHERE rank=1
15 /
ID NAME START_TIM STATUS
---------- ------------------------------ --------- ----------
226 BASIC_CAPTURE1 21-FEB-20 COMPLETED
SQL> select id,AWR_BEGIN_SNAP,AWR_END_SNAP from dba_workload_captures;
ID AWR_BEGIN_SNAP AWR_END_SNAP
---------- -------------- ------------
226 224 225
まず、もっとも最近実施したDB ReplayのキャプチャのIDを確認しています。ここの例では226です。続けて226のキャプチャに関するスナップショットのIDを確認しています。ここの例では224と225です。この記事の出力では、キャプチャに関する記録が1件しかない状態で出力させていますが、複数の記録があれば複数行の出力があります。
この2つのスナップショットIDを元に、$ORACLE_HOME/rdbms/admin/awrrpt.sql をCDB$ROOTにsysユーザーで接続した状態で実行すると、AWRレポートが作成されます。AWRレポートの作成に関しては、下記の記事が参考になります。
基本からわかる!高性能×高可用性データベースシステムの作り方 第13回 AWRレポート作成とAWRスナップショット取得(CDB全体)
6. リプレイ前の準備
DB Replayのリプレイの前に、対象のデータベースをキャプチャ開始時点と同じ状態にします。本記事の例では、キャプチャしたSQLの対象にした2つのPDBの1つの表を再作成して1レコードだけ入力しておきます。
SQL> conn tcuser/tcuser@pdb1
Connected.
SQL> drop table timecard;
Table dropped.
SQL> CREATE TABLE "TCUSER"."TIMECARD" ( "EMPNO" NUMBER, "WORKDATE" DATE, "DURATION" NUMBER);
Table created.
SQL> insert into timecard values ( 1, to_date('2014/11/1', 'YYYY/MM/DD'), 8);
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
SQL> conn tcuser/tcuser@pdb2
Connected.
SQL> drop table timecard;
Table dropped.
SQL> CREATE TABLE "TCUSER"."TIMECARD" ( "EMPNO" NUMBER, "WORKDATE" DATE, "DURATION" NUMBER);
Table created.
SQL> insert into timecard values ( 1, to_date('2014/11/1', 'YYYY/MM/DD'), 8);
1 row created.
SQL> commit;
Commit complete.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
これでキャプチャの対象にした2つのPDBの表が、キャプチャ開始時点の状態に戻りました。
7. ワークロードの前処理
DB Replayのリプレイを実行するには、キャプチャしたファイルを前処理(プロセスとかプリプロセスとか言います)する必要があります。これは、キャプチャした内容によっては結構時間がかかる作業となります。ワークロードの前処理は次のように実行します。
SQL> conn / as sysdba
Connected.
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE(capture_dir => 'CAP_DIR');
3 END;
4 /
PL/SQL procedure successfully completed.
DBMS_WORKLOAD_REPLAY.PROCESS_CAPTUREのパラメータとしてキャプチャしたファイル群が含まれるディレクトリを指定します。本記事ではキャプチャとリプレイを同じデータベースで実行しているので、ディレクトリオブジェクトも使いまわしています。ここにはキャプチャしたファイル群として cap capfiles という2つのディレクトリがありました。
この処理を実行後にキャプチャファイルが含まれるディレクトリを確認すると、下記のようにppではじまるディレクトリが新たに作成されています。
$ ls
cap capfiles pp19.5.0.0.0
8. (オプション)ワークロードの前処理後の作業
DB Replayのリプレイは、リプレイクライアントを起動してそこからリプレイの処理をリクエストしていきます。このリプレイクライアントをいくつ起動すればいいのか、ということを見積もるための情報を入手する方法が提供されています。そのためには、リプレイクライアントを mode=calibrate という引数を指定して起動します。この作業を実施しなくてもリプレイは実施できますが、ここではリプレイクライアントを mode=calibrate で起動する方法を紹介しておきます。
$ wrc mode=calibrate replaydir=/home/oracle/work/dbreplay/basic/cap_dir
Workload Replay Client: Release 19.5.0.0.0 - Production on Fri Feb 21 10:16:37 2020
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Report for Workload in: /home/oracle/work/dbreplay/basic/cap_dir
-----------------------
Recommendation:
Consider using at least 1 clients divided among 1 CPU(s)
You will need at least 3 MB of memory per client process.
If your machine(s) cannot match that number, consider using more clients.
Workload Characteristics:
- max concurrency: 1 sessions
- total number of sessions: 2
Assumptions:
- 1 client process per 100 concurrent sessions
- 4 client processes per CPU
- 256 KB of memory cache per concurrent session
- think time scale = 100
- connect time scale = 100
- synchronization = TRUE
wrcはリプレイクライアントのモジュールです。$ORACLE_HOME/binにあります。
リプレイクライアントを mode=calibrate で起動する場合 repladirというパラメータで、キャプチャし前処理を実行したファイル群が格納されているディレクトリを指定します。リプレイクライアントをデータベースサーバーとは別のマシンで実行する場合、それらのファイル群をコピーする必要があります。
mode=calibrate でのリプレイクライアントを動作させる場合に関しては、下記のマニュアルが参考になります。
Oracle Database Testingガイド 19c - 12.1.8.1 リプレイ・クライアントの較正
9. リプレイの実行
DB Replayのリプレイを実行していきます。
SQL> conn / as sysdba
Connected.
SQL> --initialize replay
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.INITIALIZE_REPLAY (replay_name => 'BASIC_REPLAY1', replay_dir => 'CAP_DIR');
3 END;
4 /
PL/SQL procedure successfully completed.
まずリプレイのために、キャプチャしたファイルと事前処理したファイル群が格納されているディレクトリを指定します。
次にリプレイクライアントからの接続に関する設定(接続のリマップといったり再マッピングといったりします)を実施します。
ワークロードの取得時に接続に使用された接続文字列が取得されています。リプレイには、この接続文字列をリプレイ対象のデータベースに再マッピングする必要があります。これによって、リプレイクライアントは再マッピングされた接続を使用してリプレイ対象のデータベースに接続できます。
接続の再マッピングは下記のように実行します。
SQL> conn / as sysdba
Connected.
SQL> select * from dba_workload_connection_map;
REPLAY_ID CONN_ID SCHEDULE_CAP_ID
---------- ---------- ---------------
CAPTURE_CONN
--------------------------------------------------------------------------------------------------------------------------------------------
REPLAY_CONN
--------------------------------------------------------------------------------------------------------------------------------------------
80 1
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.0.0.17)(PORT=1521)(HOSTNAME=tsugahar19cb.sub10280956260.tsugaharvcn01.oraclevcn.com))(CONNECT_D
ATA=(SERVICE_NAME=pdb2.sub10280956260.tsugaharvcn01.oraclevcn.com)(CID=(PROGRAM=sqlplus)(HOST=tsugahar19cb)(USER=oracle))))
80 2
(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=10.0.0.17)(PORT=1521)(HOSTNAME=tsugahar19cb.sub10280956260.tsugaharvcn01.oraclevcn.com))(CONNECT_D
ATA=(SERVICE_NAME=pdb1.sub10280956260.tsugaharvcn01.oraclevcn.com)(CID=(PROGRAM=sqlplus)(HOST=tsugahar19cb)(USER=oracle))))
SQL> --remap connections
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION(connection_id => 1,
3 replay_connection => 'pdb1' );
4 END;
5 /
PL/SQL procedure successfully completed.
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION(connection_id => 2,
3 replay_connection => 'pdb2' );
4 END;
5 /
PL/SQL procedure successfully completed.
dba_workload_connection_mapを検索して、取得しているワークロードに関する接続の情報を確認します。少し見ずらいかもしれませんが、CONN_IDが1のものがpdb2へ、CONN_IDが2のものがpdb1への接続となっています。(SERVICE_NAMEの出力をよく確認してください)
続けてDBMS_WORKLOAD_REPLAY.REMAP_CONNECTIONで、CONN_IDが1のものに関しては接続文字列pdb1、CONN_IDが1のものに関しては接続文字列pdb2を利用するように設定しています。ここでは、動作を確認する意味でも、あえて「pdb1に対する処理をキャプチャしたものをpdb2に対して」、「pdb2に対する処理をキャプチャしたものをpdb1に対して」リプレイするよう設定にしています。
この接続文字列に関する設定は、リプレイクライアントを同じデータベースサーバー上で動作させるので、(データベースサーバー上と)同じ接続文字列の指定になっています。接続の再マッピングに関しては、下記のマニュアルが参考になります。
Oracle Database Testingガイド 19c - 12.6.2 接続の再マッピング
本記事ではリプレイクライアントをデータベースサーバー上で動作させていますが、リプレイクライアント自体の負荷のデータベースサーバーへの影響を避けるために、リプレイクライアントをサーバーとは別のマシンで実行することもできます。その場合、リプレイクライアントを動作させるマシンにはOracle Clientをインストールします。リプレイクライアントにはOracleのライセンスは不要です。
続けて、リプレイ実行時のパラメータを設定します。
SQL> conn / as sysdba
Connected.
SQL> --set replay options
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.PREPARE_REPLAY (synchronization => TRUE,
3 connect_time_scale => 100,
4 think_time_scale => 100,
5 think_time_auto_correct => TRUE,
6 capture_sts => FALSE);
7 END;
8 /
PL/SQL procedure successfully completed.
DBMS_WORKLOAD_REPLAY.PREPARE_REPLAYでリプレイのパラメータを設定します。これらのパラメータに関しては、下記が参考になります。
Oracle Database Testingガイド 19c - 12.6.4 ワークロードのリプレイ・オプションの設定
続けてリプレイクラアントを起動します。リプレイクライアントの起動は、対象のマシン(本記事ではデータベースサーバー上で実行します)でシェルから$ORACLE_HOME/wrcを実行します。SQL*Plusを実行しているターミナルとは別に、新たにターミナルを起動してサーバーに接続してシェルから実行します。次のような感じになります。
$ wrc system/Manager1 mode=replay replaydir=/home/oracle/work/dbreplay/basic/cap_dir
Workload Replay Client: Release 19.5.0.0.0 - Production on Fri Feb 21 10:22:12 2020
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
Wait for the replay to start (10:22:12)
リプレイクライアントでパラメータを指定して起動すると、上記のように出力され「リプレイスタートの合図」が送られるのを待ちます。この間に、複数のリプレイクライアントを起動するのであれば、同じようにパラメータを指定して起動します。本記事の例においては、リプレイクライアントは1つで十分です。SQL*Plusを実行しているターミナルに戻って、下記のように実行します。
SQL> conn / as sysdba
Connected.
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.START_REPLAY;
3 END;
4 /
PL/SQL procedure successfully completed.
このように実行すると、リプレイクライアント側で下記のように出力され、リプレイが開始されます。
Wait for the replay to start (10:22:12)
Replay client 1 started (10:22:33)
ここでリプレイクライアントの実行は、プロンプトは戻ってきません。リプレイが進行していることは、下記のように検索して確認できます。
SQL> conn / as sysdba
Connected.
SQL> col name for a25
SQL> col status for a15
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM dba_workload_replays
6 /
ID NAME START_TIME STATUS
---------- ------------------------- ----------------- ---------------
80 BASIC_REPLAY1 20-02-21 10:22:33 IN PROGRESS
SQL> /
ID NAME START_TIME STATUS
---------- ------------------------- ----------------- ---------------
80 BASIC_REPLAY1 20-02-21 10:22:33 COMPLETED
dba_workload_replaysを検索して、最初はIN PROGRESSと表示されていますが、しばらくして同じ検索を実行するとCOMPLETEDになりリプレイが終了したことがわかります。
dba_workload_replays の user_callsの値から、リプレイの途中でもリプレイ済みのユーザーコールの数を確認できます。キャプチャされているユーザーコールの数は dba_workload_captures の user_calls で確認できます。この2つの値からおおよそのリプレイの進捗状況を確認できます。
なお、COMPLETEDになってもリプレイクライアントのプロンプトがすぐ戻ってくるわけではありません。キャプチャした時の時間にも応じて、リプレイ処理が完了してもリプレイクライアントが戻ってくるまで、しばらく時間がかかります。リプレイクライアントは、次のように出力してプロンプトを戻します。
Replay client 1 started (10:22:33)
Replay client 1 finished (10:26:20)
実際にリプレイが実行されたか、対象の表を検索して確認してみます。
SQL> conn tcuser/tcuser@pdb1
Connected.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
2465 20-02-21 09:57:08 10
3888 20-02-21 09:57:08 2
6349 20-02-21 09:57:08 10
SQL> conn tcuser/tcuser@pdb2
Connected.
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> select * from timecard order by empno;
EMPNO WORKDATE DURATION
---------- ----------------- ----------
1 14-11-01 00:00:00 8
1197 20-02-21 09:57:08 10
4186 20-02-21 09:57:08 9
9978 20-02-21 09:57:08 9
PDB1,PDB2ともに、リプレイが実行され3レコードが追加されていることが確認できます。またリプレイのときに接続するデータベースをPDB1,PDB2入れ替えて設定したので(接続の再マッピングでそのように指定しました)、PDB1に対して実行した処理をPDB2に、PDB2に対する処理をPDB2にリプレイで処理していることが確認できます。
リプレイのレポートの作成は次のように実行します。
SQL> conn / as sysdba
Connected.
SQL> set echo on
SQL> set pagesize 10000
SQL> set linesize 140
SQL> set long 10000000
SQL> set trimspool off
SQL> col report for a140
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM
6 (
7 SELECT id ,
8 name ,
9 start_time,
10 status ,
11 rank() over ( order by start_time DESC) rank
12 FROM dba_workload_replays
13 )
14 WHERE rank=1
15 /
ID NAME START_TIM STATUS
---------- ------------------------- --------- ---------------
80 BASIC_REPLAY1 21-FEB-20 COMPLETED
<- このような出力結果から、直近のリプレイのIDの番号を確認し次に入力する。
SQL> spool /tmp/dbreplay_basic.html
SQL> select dbms_workload_replay.report( &replayID, 'HTML') report from dual;
Enter value for replayid: 80 <- 上記の検索結果で確認したリプレイIDを入力
(以下略)
DBMS_WORKLOAD_REPLAY.REPORTを実行してするとレポートが出力されるので、それをspoolコマンドでファイルに出力させます。ここの例では、/tmp/dbreplay_basic.html に出力させています。
出力されたレポートの中身に関しては、次のマニュアルが参考になります。
Oracle Database Testingガイド 19c - 13.1.3 ワークロードの取得レポートの確認
10. (オプション)リプレイ後の作業
リプレイ後のオプションの作業としてリプレイ中のAWRレポートを出力させる手順を紹介します。キャプチャのときもAWRレポートを出力させることができましたが、同じようにリプレイのときも出力させることができます。AWRレポートを出力させなくてもDB Replayを動作させることは可能ですが、後の調査解析のためにキャプチャ時、リプレイ時のAWRレポートを出力させることをお薦めします。
DB Replayのリプレイを実行する際には、開始時と終了時にAWRのスナップショットが作成されています。これを使って、通常のOracle Databaseの性能解析でよく利用するAWRレポートを出力させます。ここではAWRレポートを出力させるためのスナップショットIDの確認方法を紹介します。
SQL> conn / as sysdba
Connected.
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM
6 (
7 SELECT id ,
8 name ,
9 start_time,
10 status ,
11 rank() over ( order by start_time DESC) rank
12 FROM dba_workload_replays
13 )
14 WHERE rank=1
15 /
ID NAME START_TIM STATUS
---------- ------------------------- --------- ---------------
80 BASIC_REPLAY1 21-FEB-20 COMPLETED
SQL> select id,AWR_BEGIN_SNAP,AWR_END_SNAP from dba_workload_replays;
ID AWR_BEGIN_SNAP AWR_END_SNAP
---------- -------------- ------------
80 226 227
キャプチャのときにスナップショットIDを確認した方法と、アクセスする表が違うだけでほぼ同じ方法です。まず、もっとも最近実施したDB ReplayのリプレイのIDを確認しています。ここの例では80です。続けて80のキャプチャに関するスナップショットのIDを確認しています。ここの例では226と227です。
スナップショットからAWRレポートを出力させる方法は通常の方法と同じです。この2つのスナップショットIDを元に、$ORACLE_HOME/rdbms/admin/awrrpt.sql をCDB$ROOTにsysユーザーで接続した状態で実行すると、AWRレポートが作成されます。
**以上でDB Replayのキャプチャからリプレイまでの、一番簡単な動作確認の手順は終了です。**この手順を繰り返し実行するための作業に関して続けて説明します。
11. 繰り返し実行する場合の準備
リプレイまで完了させた後に、同じような手順でキャプチャからリプレイまでを繰り返し実行することを想定して、リプレイ後の実施する手順を説明します。
まずキャプチャファイルを出力させたディレクトリを空にします。次のように実行します。
(もちろん空にするディレクトリは利用されている環境にあわせてください。)
[oracle@tsugahar19cb]$ rm -rf /home/oracle/work/dbreplay/basic/cap_dir/*
これだけでも、本記事のDB Replayの手順を繰り替えすることは可能です。
ただ、データベースに対しては実行したキャプチャとリプレイの情報が蓄積していきます。これを削除するには、次のように実行します。
SQL> conn / as sysdba
SQL> col name for a30
SQL> col status for a10
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM
6 (
7 SELECT id ,
8 name ,
9 start_time,
10 status ,
11 rank() over ( order by start_time DESC) rank
12 FROM dba_workload_captures
13 )
14 WHERE rank=1
15 /
ID NAME START_TIME STATUS
---------- ------------------------------ ----------------- ----------
225 BASIC_CAPTURE1 20-02-21 09:03:59 COMPLETED ★
<- もっとも最近実行したキャプチャのIDが225です。
SQL> BEGIN
2 DBMS_WORKLOAD_CAPTURE.DELETE_CAPTURE_INFO( &captureID );
3 END;
4 /
Enter value for captureid: 225 <- 確認したIDを入力します。
old 2: DBMS_WORKLOAD_CAPTURE.DELETE_CAPTURE_INFO( &captureID );
new 2: DBMS_WORKLOAD_CAPTURE.DELETE_CAPTURE_INFO( 225 );
PL/SQL procedure successfully completed.
SQL> conn / as sysdba
Connected.
SQL> col name for a30
SQL> col status for a10
SQL> alter session set nls_date_format='YY-MM-DD HH24:MI:SS';
Session altered.
SQL>
SQL> SELECT id ,
2 name ,
3 start_time,
4 status
5 FROM
6 (
7 SELECT id ,
8 name ,
9 start_time,
10 status ,
11 rank() over ( order by start_time DESC) rank
12 FROM dba_workload_replays
13 )
14 WHERE rank=1
15 /
ID NAME START_TIME STATUS
---------- ------------------------------ ----------------- ----------
11 BASIC_REPLAY1 20-03-12 10:14:18 COMPLETED
<- もっとも最近実行したリプレイのIDが11です。
SQL> BEGIN
2 DBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFO( &replayID );
3 END;
4 /
Enter value for replayid: 11 <- 確認したIDを入力します。
old 2: DBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFO( &replayID );
new 2: DBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFO( 11 );
PL/SQL procedure successfully completed.
DBMS_WORKLOAD_CAPTURE.DELETE_CAPTURE_INFOとDBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFOでそれぞれキャプチャの情報とリプレイの情報を削除できます。1回の実施では1回分しか削除できないので、必要に応じて複数回実行します。
12. 参考
RATのDB Replayに関して参考になるドキュメントを紹介します。
本記事と同じように手順を紹介しています。Part 1の下の方にPart 2へのリンクがあります。
[Oracle Real Application Testing - Demo Part 1]
(http://orabliss.blogspot.com/2016/02/oracle-rat-demo-part-1.html)
Oracleのマニュアルは、本記事の内容を一通り理解した上で参照すると詳細に理解できるようになると思います。
Oracle Database Testingガイド 19c - 第II部 データベース・リプレイ
Database Linkを利用する処理をDB Replayでキャプチャ、リプレイする場合に関する、かなり詳しい解説(英語)があります。ピンポイントの情報ですが、該当するケースでは有用です。
Database Replay and database links