相席ラウンジ
女性は無料、男性は有料で有名な相席居酒屋の高級版みたいなお店です。仕組みは相席居酒屋とほぼ同じで、「お店が高級なので相席居酒屋よりも良い女性が多い。」という点が相席居酒屋と比較したメリットのようです。料金は、おおよそ6000円/時の定額課金+女性が食べた料理分の支払いとなるようです。
お店側の美辞麗句はさておき、いち見込み客として気になるのは、**本当に女性が多いのか?****どの時間帯に行くのが一番お得なのか?**という点に尽きます。街コン、相席居酒屋ともに、「もう流行は終わった。」と言われて久しい中、相席ラウンジには本当に女性が多いのか、Webスクレイピングを使って調査してみました。
方法
相席ラウンジでは、お店にいる男性と女性の数をリアルタイムにWeb上に公開しています。

今回は、このWebページを毎分スクレイピングすることで、曜日、時間帯ごとの男性と女性の人数の推移を把握し、男性にとってどの曜日、時間帯がもっとも狙い目なのかを明らかにします。
※ 女性は常に無料なので、女性にとってはどの曜日、時間帯でもお得だと思われます。
TL;DR
元データもあります。
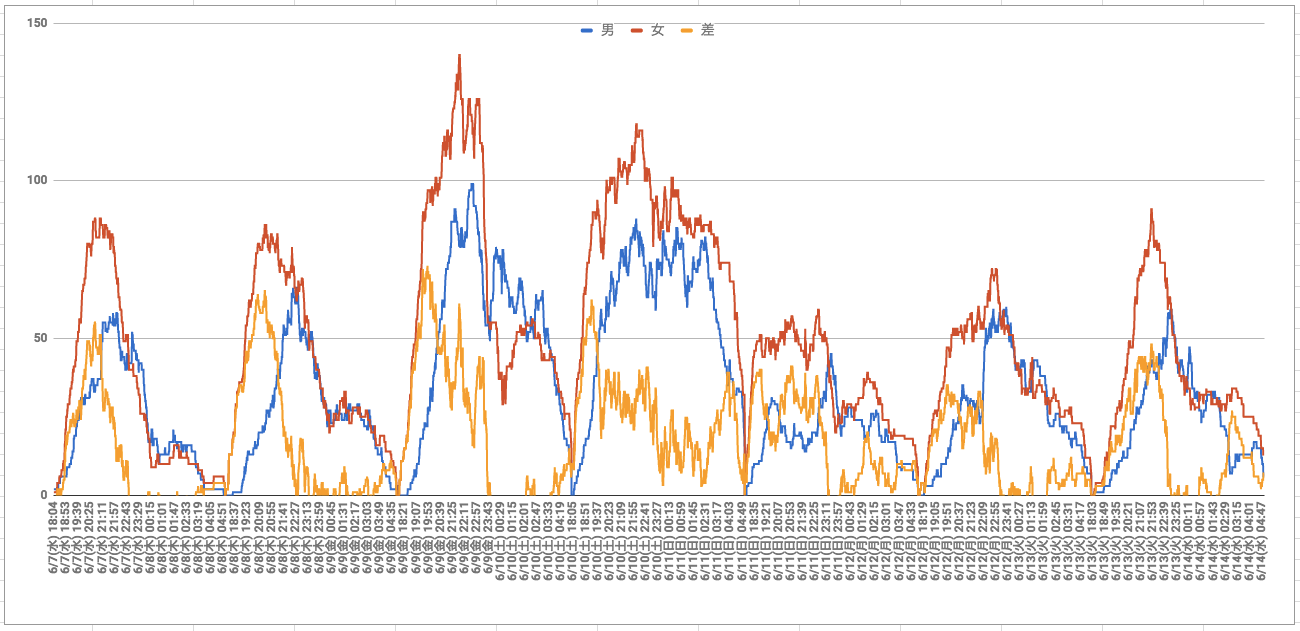
- おすすめの曜日は、金曜と土曜
- おすすめの時間帯は、19:40〜20:40
- どんなに遅くとも、22〜23時頃には切り上げること(二次会も含め)
- ただし土曜のみ、時間を気にしない女性が多い可能性あり
気付いた点
ほぼすべての曜日、時間帯で女性の方が男性よりも多い
店員さんがちゃんとお客さんをさばいてさえいれば、どの時間帯に行っても女性とマッチングできるようです。想定しうる最悪の事態である、「行ってはみたものの女性とまったく会話できず。」という状況はひとまず避けられそうです。
金曜と土曜の夜は、他の曜日と比べて1.5〜2倍ほど女性の数が多い
女性と男性の両方とも増加していますが、女性の増加の方が大きいため、トータルで考えても金土はお得な曜日と言えそうです。さらに、瞬間最大人数(金曜 21:54 女性140人)的に、金曜が一番お得と言えそうです。
日曜と月曜の夜は、他の曜日と比べて女性の数が半分ほどしかいない
とは言え、男性も少なくなっていることもあり、常に30〜40人ほど女性の方が多いようなので、そこまで不利な曜日でもなさそうです。
19:40〜20:40に女性の数が一気に増加する
金曜と土曜は19:40頃、それ以外の曜日は20:40頃に女性の数が一気に増加します。なので、この時間の5分まえくらいにお店に到着するように待ち合わせすると、費用対効果良くお店を利用できそうです。
また、男性のピークは女性のピークよりも2〜3時間ほど遅れてやってきます。ライバルの多い時間帯は避けるという意味で、「仕事が長引いたから遅れて行こう。」や、「一次会はみんなで飲んで二次会は相席ラウンジに行こう。」はやめた方がよさそうです。
22時頃から女性の数が一気に減少する
おそらく、電車で帰宅し始めるのがこの時間帯なのだと思われます。金曜と土曜以外は、男性も女性もほぼ同じ時間に急激に減少します。一方で、金曜と土曜は他の曜日と異なる動きを見せています。
金曜の女性は帰宅する意思が強い
金曜は、女性の数が一番多くなる曜日であるものの、時間が遅くなるとその数は急激に減少し、24時過ぎにはこの曜日のみ男性の方が女性よりも多くなってしまいます。この結果はおそらく、女性は、「今日は仕事で疲れてるし、帰ろうっと。」と考えるのに対し、男性は、「明日は仕事がないし、粘るぞー!」と考えるという悲しい行き違いの結果だろうと思われます。
土曜の女性は始発帰宅もOK
逆に土曜は、男性も女性も3時前までそれぞれ80人ほどがお店に残っており、さらに、男性は3時過ぎから帰り始めるのに対し、女性は4時頃までずっとお店に残っています。つまり、「終電に間に合わなくても、始発で帰れればいっか。」と思っている女性はこの曜日に一番多く、二軒目に誘うにはベストな曜日だと言えそうです。
注意点
- 今回は新宿店のみ(6/7〜6/13)を対象としています
- 梅雨の時期に調査したため、天候の影響もありそうです
- 女性の属性は考慮していません(深夜はプロの女性が多い?)
まとめ
相席ラウンジの滞在人数を分析した結果、金曜か土曜の19:40〜20:40がもっとも行くのに適した時間であり、二軒目に誘うなら土曜がベストということが判明しました。これから行くことを考えている方のご参考になれば幸いです。
元データには、新宿だけでなく全店舗のデータを記載しています。私が記載している点以外にも気付いたことがありましたら、Qiitaのコメントにてご指摘いただけますとありがたいです。
参考リンク
Rubyコード
Gemfile
source "https://rubygems.org"
gem 'anemone'
crawl.rb
# !/usr/bin/ruby
require 'anemone'
require 'fileutils'
require 'optparse'
module Crawl
class Place
NAMES = %w(
sapporo
sendai
shinjuku
shibuya
machida
nagoya
kyoto
shinsaibashi
kobe
hiroshima
fukuoka
kumamoto
kagoshima
okinawa
)
attr_reader :name, :men, :lady
def initialize(name, men, lady)
@name, @men, @lady = name, men, lady
end
def to_s
"#{name} #{men} #{lady}"
end
end
class Cache
class << self
def time2key(time)
time.is_a?(String) ? time : time.strftime("%Y%m%d%H%M") # yyyymmddhhmm
end
def dir
"#{Dir.pwd}/.cache"
end
def file(time)
"#{dir}/#{time2key(time)}"
end
def exists?(time)
FileTest.exist?(file(time))
end
def read(time)
File.read(file(time))
end
def write(time, html)
FileUtils.mkdir_p(dir) unless FileTest.exist?(dir)
File.write(file(time), html)
end
def fetch(time)
if block_given?
if exists?(time)
read(time)
else
result = yield
write(time, result)
result
end
else
read(time)
end
end
end
end
class Scraper
URL = 'http://oriental-lounge.com/'
class << self
def scrape(time)
html = Cache.fetch(time) { fetch(URL).to_html }
doc = Nokogiri::HTML(html)
Place::NAMES.map do |name|
str = parse(doc, "//a[@id='box_#{name}']")
men, lady = extract(str)
Place.new(name, men, lady)
end
end
def fetch(url)
Anemone.crawl(url, depth_limit: 0) do |anemone|
anemone.on_every_page do |page|
return page.doc
end
end
end
def parse(doc, xpath)
doc.xpath(xpath).each do |tag|
return tag.text
end
end
def extract(str)
str.strip.match(/(\d+)[^\d]+(\d+)/).to_a.slice(1, 2)
end
end
end
end
if $0 == __FILE__
places = Crawl::Scraper.scrape(Time.now)
print Time.now.to_s + ' '
puts places.map(&:to_s).join(', ')
end
crontab
* 9-19 * * * /bin/bash -l -c "cd /home/username/lounge && bundle exec ruby bin/crawl.rb >>log/cron.log 2>&1"