はじめに
この記事は、3-shake Advent Calendar 2024 シリーズ2の3日目の記事です。
ここ最近Kubernetesのオペレーターに触れる機会があったので、アウトプットとして本記事を書いています。
オペレーターとは
オペレーターとは、Kubernetesの持つ 制御ループ(Reconciliation Loop) という仕組みを用いたKubernetesの拡張機能になります。制御ループは、元々はロボット工学等の分野で使われていた用語で、現在の状態を目的の状態に近づけるように動作する仕組みのことです。オペレーターは、カスタムリソースとカスタムコントローラーを組み合わせることで作成します。
カスタムリソース(CRD) は、ユーザーが独自にカスタマイズできるKubernetesリソースで、アプリケーションの理想状態をspecフィールド内に記述します。
コントローラー は、カスタムリソースを監視し、そのspecフィールドで定義された目的の状態を実現するために必要な操作を行う制御ループを実装します。つまり、現在の状態を目的の状態に近づける責務を持ちます。
これらのカスタムリソース(CRD)とカスタムコントローラーを作成することで、Kubernetesの機能拡張を実現するものがオペレーターです。
オペレーターを開発するには
オペレーターを開発するためのフレームワークにはいくつかあり、そのうちの一つがkubebuilder です。他にも、Operator SDKなどがあるようです。今回は、kubebuilderを使ってPodの監視を行いたいと思います。
また、オペレーター自作に関して今回の記事を書く際参考にさせていただいた、大変有益なページがあるので紹介します。
Podを監視するオペレーターの作成
何を作るか
Kubebuilderを用いたオペレーター開発として、特定のラベルが付与されたPodに対し「理想状態のPod数」が定義できるようにし、実際のラベル付けされたPodの数が理想状態の数と異なっている場合、数が一致するよう調整するようなオペレーターを作っていきます。
つまり、理想状態の数よりも多くのPodが存在していればPodをスケールインさせ、逆に足りていなければPodをスケールアウトさせるような処理を自動で行うというオペレーターです。
以下に、簡単にですが全体の流れを示します。
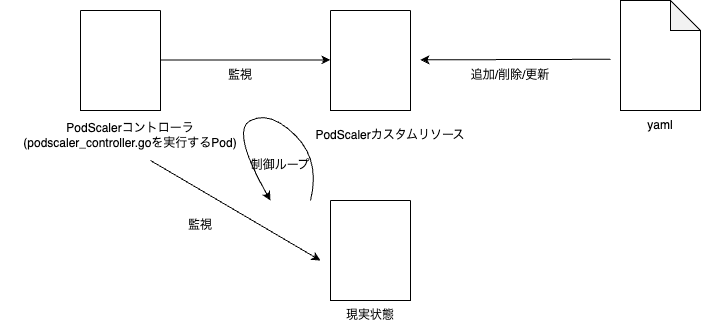
準備
kubebuilder initコマンドでプロジェクトの雛形を作成します。
kubebuilder init --domain example.com --repo example.com/pod-scaler
次に、kubebuilder create apiコマンドによりAPIの雛形を作成します。カスタムリソースとカスタムコントローラーが作成され、scalingグループに属するPodScalerというリソース名が生成されています。
kubebuilder create api --group scaling --version v1 --kind PodScaler
そして、make manifestsを実行しCRDのマニフェストを更新します。
kubebuilderにより以下のような、コントローラのDeployment(マニフェストの一部です)が作成されます。
apiVersion: v1
kind: Namespace
metadata:
labels:
control-plane: controller-manager
app.kubernetes.io/name: pod-scaler
app.kubernetes.io/managed-by: kustomize
name: system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: controller-manager
namespace: system
labels:
control-plane: controller-manager
app.kubernetes.io/name: pod-scaler
app.kubernetes.io/managed-by: kustomize
ここまでで、ディレクトリ構成は以下のようになります。
tree -L 2
.
├── Dockerfile
├── Makefile
├── PROJECT
├── README.md
├── api
│ └── v1
├── bin
│ ├── controller-gen
│ ├── controller-gen-v0.16.4
│ ├── kustomize
│ └── kustomize-v5.5.0
├── cmd
│ └── main.go
├── config
│ ├── crd
│ ├── default
│ ├── manager
│ ├── network-policy
│ ├── prometheus
│ ├── rbac
│ └── samples
├── go.mod
├── go.sum
├── hack
│ └── boilerplate.go.txt
├── internal
│ └── controller
└── test
├── e2e
└── utils
実際に作っていく
まず、api/v1/podscaler_types.go のPodScalerSpec構造体の中身を編集し、PodScalerリソースの定義を変更していきます。
type PodScalerSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// 強制的に保持するPodの数
Count int `json:"count"`
// Podのラベルセレクタ
Selector map[string]string `json:"selector"`
}
変更後、make manifestsおよびmake installにより反映します。
ここで、pod-scaler/config/crd/bases内のCRDを確認すると、PodScalerSpecの定義通りCRDが更新されていることがわかります。以下がその一部です。
spec:
description: PodScalerSpec defines the desired state of PodScaler.
properties:
count:
description: |-
Foo is an example field of PodScaler. Edit podscaler_types.go to remove/update
Foo string `json:"foo,omitempty"`
強制的に保持するPodの数
type: integer
selector:
additionalProperties:
type: string
description: Podのラベルセレクタ
type: object
required:
- count
- selector
type: object
上記のようにCountやSelectorを定義すると、以下のようにカスタムソースのspecフィールド内において定義した要素を追加することができるようになります。
spec.selectorで定義したラベルと同じラベルを持つPodを監視対象にし、spec.countで定義した数を理想状態とし現実状態のPodが理想状態と数が異なる場合には同じ数のPodが起動するようなオペレーターになります。
apiVersion: scaling.example.com/v1
kind: PodScaler
metadata:
name: example-podscaler
spec:
count: 4
selector:
app: nginx
次に、コントローラーの実装をしていきます。Reconcileの部分を実装していくことになりますが、この部分は先述した制御ループに当たる部分で、オペレーターの核となる部分になります。
PodScalerReconcilerの埋め込みフィールドとしてクライアントライブラリ(client.Client)が使用されます。Reconcile関数内でr.Getやr.Listなどを使い、クライアントを通じてリソースを取得していきます。
type PodScalerReconciler struct {
client.Client
Scheme *runtime.Scheme
Log logr.Logger
}
Reconcilerは以下のように実装しました。
引数であるreqにはカスタムリソースのNameとNamespaceが入っています。(reconcile.Request)
reqによりカスタムリソースであるPodScalerを取得した上で、該当するラベルのPodを列挙します。そして、カスタムリソースで定義したPodの数の理想状態と現実のラベルが一致するPodの数の比較を行います。
理想状態の数と比較してPodの数が足りていない場合は足りていない分のPodを新たに作成し、逆に現実状態のPod数が理想状態よりも多い場合は超過分の数のPodを削除しています。
func (r *PodScalerReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := log.FromContext(ctx)
var podScaler scalingv1.PodScaler
// 指定した名前空間と名前に基づいてPodScalerを取得
if err := r.Get(ctx, req.NamespacedName, &podScaler); err != nil {
log.Error(err, "unable to fetch PodScaler")
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// 対象のPodをリスト
var pods corev1.PodList
labelSelector := labels.SelectorFromSet(podScaler.Spec.Selector)
if err := r.List(ctx, &pods, &client.ListOptions{
Namespace: req.Namespace,
LabelSelector: labelSelector,
}); err != nil {
log.Error(err, "unable to list pods")
return ctrl.Result{}, err
}
// Podの数を調整
currentCount := len(pods.Items)
desiredCount := podScaler.Spec.Count
if currentCount < desiredCount {
for i := 0; i < (desiredCount - currentCount); i++ {
pod := &corev1.Pod{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "scaled-pod-",
Namespace: req.Namespace,
Labels: podScaler.Spec.Selector,
},
Spec: corev1.PodSpec{
Containers: []corev1.Container{
{
Name: "nginx",
Image: "nginx:latest",
},
},
},
}
if err := r.Create(ctx, pod); err != nil {
log.Error(err, "unable to create Pod")
return ctrl.Result{}, err
}
}
} else if currentCount > desiredCount {
// Podを削除
for i := 0; i < (currentCount - desiredCount); i++ {
pod := &pods.Items[i]
if err := r.Delete(ctx, pod); err != nil {
// 削除対象が存在しない場合はスキップ
if client.IgnoreNotFound(err) != nil {
logger.Error(err, "unable to delete Pod")
return ctrl.Result{}, err
}
}
}
}
log.Info("Reconciliation complete", "currentCount", currentCount, "desiredCount", desiredCount)
// 15秒ごとに再起動
return ctrl.Result{RequeueAfter: 15 * time.Second}, nil
}
また、SetupWithManager関数でReconcileをトリガーしたい条件を記述することができます。デフォルトではカスタムリソースが変更された時のみReconcileがトリガーされますが、今回はクラスタ内のPodの変更を検知したいので、Owns(&corev1.Pod{}).を追加することでPodを監視対象とします。
コントローラの実装が完了したら、以下コマンドを実行しクラスタに反映します。
make docker-build
make docker-push
make deploy
動作確認
初め、カスタムリソースで定義したnginxというラベルの付いたnginxのPodが一つある状態だとします。
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-86dcfdf4c6-7ltf4 1/1 Running 0 6m26s
ここで、カスタムリソースをkubectl apply -f config/samples/scaling_v1_podscaler.yamlによりapplyします。
すると、カスタムコントローラーが該当するラベルの付いた現在のPod数が理想状態の数と比較して少ないことを検知して追加していることがわかります!
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-86dcfdf4c6-7ltf4 1/1 Running 0 7m17s
scaled-pod-75cwf 1/1 Running 0 12s
scaled-pod-w8r87 1/1 Running 0 12s
scaled-pod-xr6k5 1/1 Running 0 12s
別の例として、nginxというラベルの付いたPodが4つある状態です。
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-86dcfdf4c6-tgslw 1/1 Running 0 4m11s
scaled-pod-h2n89 1/1 Running 0 4m11s
scaled-pod-hm2bl 1/1 Running 0 4m11s
scaled-pod-sbb79 1/1 Running 0 4m11s
ここで、nginx-86dcfdf4c6-tgslwのPodを手動で削除したとします。
そうすると、以下のようにコントローラが理想状態(4つ)と現実状態(3つ)の差分を検知して、新たにPodを作成していることがわかります。
kubectl get pods
NAME READY STATUS RESTARTS AGE
scaled-pod-h2n89 1/1 Running 0 4m40s
scaled-pod-hm2bl 1/1 Running 0 4m40s
scaled-pod-sbb79 1/1 Running 0 4m40s
scaled-pod-thzm5 1/1 Running 0 8s
さらに、この状態でreplicas=3のnginxのDeploymentをapplyするとします。
すると、一時的にPodは7つとなってしまいますが、
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-86dcfdf4c6-9dp2c 1/1 Running 0 6s
nginx-86dcfdf4c6-jsxf4 1/1 Running 0 6s
nginx-86dcfdf4c6-wmtld 1/1 Running 0 6s
scaled-pod-h2n89 1/1 Running 0 5m30s
scaled-pod-hm2bl 1/1 Running 0 5m30s
scaled-pod-sbb79 1/1 Running 0 5m30s
scaled-pod-thzm5 1/1 Running 0 58s
最終的には理想状態の4つになるようにオペレーターが調整してくれています!
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-86dcfdf4c6-72vdk 1/1 Running 0 14s
nginx-86dcfdf4c6-7krbg 1/1 Running 0 14s
nginx-86dcfdf4c6-td5fw 1/1 Running 0 15s
scaled-pod-ktc9f 1/1 Running 0 4s
このように、該当するラベルのPodについて数を監視して、理想状態と異なっている場合に数を増減させるようなオペレーターを作ることができました。
終わりに
Kubebuilderに慣れるという目的で、Podの理想状態の数を定義しその数に現実のPod数を合わせるというシンプルなオペレーターをKubebuilderを使って作ってみました。
まだ自分はKubebuilderに入門したばかりなので、これからもさらに知見を深められるよう頑張っていきたいです!
ここまで読んでいただき、ありがとうございました。
なお、この記事の続きとしてAdmission webhooksでkubebuilderを拡張するという記事も書いているので是非!
動作確認を行ったソースコードは以下になります。