ニューラル言語処理向けのトークナイザSentencePieceを文書分類に適用してみました。
きっかけ
先日、自然言語処理における単語分割の選択肢としてSentencePieceを知りました。
機械翻訳で従来の単語分割手法を超えるスコアを達成したようで、単純に興味があったのと、現在自分が取り組んでいる文書分類ではどうなるかと思い、試してみました。
SentencePiece(GitHub)
作者のtaku910さんの記事(Qiita)
データ
KNB解析済みブログコーパスを使いました。
こちらは「京都観光」「携帯電話」「スポーツ」「グルメ」の4つのカテゴリに分けられた全4,186文の解析済みブログコーパスで、形態素や格なども含まれています。
今回はカテゴリと文章のみ使って、各文章がどのカテゴリに属するかの分類問題を解きます。
全データの1割をテストデータとして分割し、残りの9割でSentencePiece、ニューラルネットワークの学習を行いました。
実装
Bash on Windows上でPython3.6.1で実行しました。
Pythonモジュールの詳しいバージョンはrequirement.txtをご参照ください。
コードはGitHubにまとめています。
まだまだ未熟なので間違いの指摘やアドバイスいただけるとありがたいです。
separator.py
基本的にSentencePieceはコマンドラインから使うようですが、私はPythonから使いたかった&mecabと簡単に使い分けたかったので、あまり賢いやり方とは言えませんがsubprocessから呼ぶようにしました。
def train_sentencepiece(self, vocab_size):
cmd = "spm_train --input=" + self.native_text + \
" --model_prefix=" + self.model_path + \
" --vocab_size=" + str(vocab_size)
p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout_data, stderr_data = p.communicate()
学習したモデルを使って分ち書きをする際、1行ずつでは処理に時間がかかりすぎるので、一旦テキストファイルに書き出して、まとめて行うようにしましています。
今回は使用していませんが、characterレベルでの学習を行う際のために1文字ずつの分割機能も付けました。
今回比較するのはSentencePieceとmecab+neologdです
net.py
ネットワークにはLSTMを使いたかったのですが、学習に非常に時間がかかってしまうため、今回はCNNにしました。
実装したのは3、4、5単語の3種類のフィルタを持ったネットワークになります。
class CNN(Chain):
def __init__(self, n_vocab, n_units, n_out, filter_size=(3, 4, 5), stride=1, use_dropout=0.5, ignore_label=-1):
super(CNN, self).__init__()
initializer = initializers.HeNormal()
with self.init_scope():
self.word_embed=L.EmbedID(n_vocab, n_units, ignore_label=-1)
self.conv1 = L.Convolution2D(None, n_units, (filter_size[0], n_units), stride, pad=(filter_size[0], 0), initialW=initializer)
self.conv2 = L.Convolution2D(None, n_units, (filter_size[1], n_units), stride, pad=(filter_size[1], 0), initialW=initializer)
self.conv3 = L.Convolution2D(None, n_units, (filter_size[2], n_units), stride, pad=(filter_size[2], 0), initialW=initializer)
self.norm1 = L.BatchNormalization(n_units)
self.norm2 = L.BatchNormalization(n_units)
self.norm3 = L.BatchNormalization(n_units)
self.l1 = L.Linear(None, n_units)
self.l2 = L.Linear(None, n_out)
self.use_dropout = use_dropout
self.filter_size = filter_size
def forward(self, x, train):
with using_config('train', train):
x = Variable(x)
x = self.word_embed(x)
x = F.dropout(x, ratio=self.use_dropout)
x = F.expand_dims(x, axis=1)
x1 = F.relu(self.norm1(self.conv1(x)))
x1 = F.max_pooling_2d(x1, self.filter_size[0])
x2 = F.relu(self.norm2(self.conv2(x)))
x2 = F.max_pooling_2d(x2, self.filter_size[1])
x3 = F.relu(self.norm3(self.conv3(x)))
x3 = F.max_pooling_2d(x3, self.filter_size[2])
x = F.concat((x1, x2, x3), axis=2)
x = F.dropout(F.relu(self.l1(x)), ratio=self.use_dropout)
x = self.l2(x)
return x
その他のパラメータは以下のように設定しました。
|ユニット数|ミニバッチサイズ|max epoch|WeightDecay|GradientClipping|Optimizer|
|:---:|:-------:|:-------------:|:-----------:|:---------:|:--------------:|:-------:|
|256|32|30|0.001|5.0|Adam|
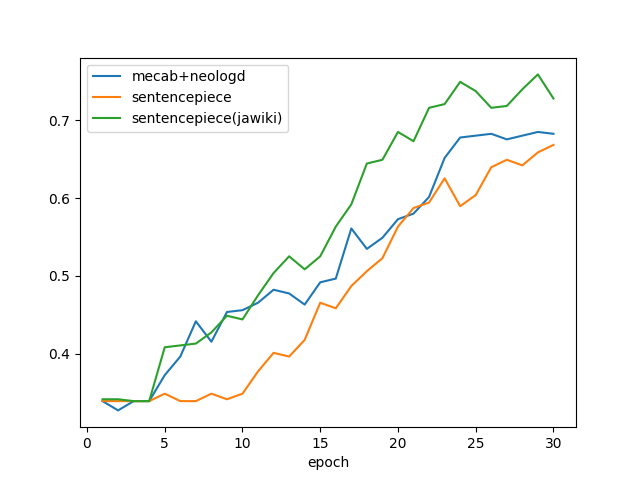
結果
| トークナイザ | mecab+neologd | SentencePiece |
|---|---|---|
| Best精度 | 0.68496418 | 0.668257773 |
う~ん、、、あまり良くないですね
SentencePieceの学習に使ったのがtrain用のテキストデータだけなので、文章量が少なすぎたのでしょうか?
試しにSentencePieceのモデルの学習をjawiki(2017/05/01最新版)でやってみました。
| トークナイザ | mecab+neologd | SentencePiece | SentencePiece(jawikiで学習) |
|---|---|---|---|
| Best精度 | 0.68496418 | 0.668257773 | 0.758949876 |
今度は良さそうです。
epoch毎の精度は以下のようになります。
分ち書き
実際に分ち書きされた文章をいくつかサンプリングしてみてみました
【SentencePiece】
小さすぎ/て/ボタンを押/し/辛い/のである/。
どの/くらい/やり/取り/が/続/く/のかな/あ/♪
あともう/一/頑/張/り/、/しようか/と思う/。
【SentencePiece(jawikiで学習)】
小/さ/すぎ/て/ボタン/を/押し/辛/い/の/である/。
ど/の/く/らい/や/り/取り/が/続く/の/かな/あ/♪
あ/と/もう/一/頑/張/り/、/し/よう/か/と/思/う/。
【mecab + neologd】
小さ/すぎ/て/ボタン/を/押し/辛い/の/で/ある/。
どの/くらい/やり取り/が/続く/の/か/なあ/♪
あ/ともう/一/頑張り/、/しよう/か/と/思う/。
同じSentencePieceでもjawikiで学習したほうが細かく分かれている感じがします。
感覚的に人間に近いのはmecab+neologdですが、それがそのままニューラルネットワークの学習でもいい結果になるわけではないというのは面白いです。
今後
今回はユニット数などのパラメーター調整は全て決め打ちだったので、ちゃんと調整してそれぞれのベストで比較する必要があるかなと思います。
またセパレーターの項でも少し触れましたが、characterレベルの学習との比較も試してみたいです。
あとはSentencePieceの学習をtrainデータとは別の文章、今回はjawikiを使いましたが、ほかの文章だと精度にどんな影響があるのかも確認してみたいです。
メモ
始めはCentOS上(docker)で試したのですが、SentencePieceが上手くインストールできませんでした。
私はあきらめたのですが、GitHubの手順に加えて、下記のものを入れておけばCentOSでもインストールできるみたいです。
$ yum install protobuf-devel boost-devel gflags-devel lmdb-devel