はじめに
この記事では美少女ゲーム「コイカツ」の話題を扱っています。
本文中に性的な表現などが含まれないよう気を付けておりますが、美少女ゲームに興味がない、あるいは好感を持てない方はブラウザバック推奨です。🙇
コイカツとは
コイカツは2018年にillusionから発売された恋愛シミュレーションゲームです。
ユーザーはゲーム中のキャラクターエディット画面を通じて理想のキャラクターを作り、そのキャラクターを学園パート内に出現させ仮想恋愛を楽しむことができます。
また、キャラクターに自由にポーズを取らせスクリーンショットを取ることのできる"スタジオ"機能も備えており、撮った作品は発売から3年経った今でもTwitterに続々投稿されています(私自身もその用途がメインになっております🙂)。
キャラクターエディットと公式アップローダー
そんなコイカツのキャラエディット機能はとても高機能になっていて、顔の輪郭や体型の細かな調整までできるようになっています。

このおかげで自分の好きなようにキャラを作成できる一方で、始めたばかりの人には、バランス良くキャラを作るためにはどのパラメータをいじればいいのか分からない、という学習コストの問題が存在します。幸いコイカツでは公式のキャラクターアップローダーが用意されており、他者の作ったキャラクターをゲーム中でダウンロードし参考にできる仕組みがあります。
しかしそのアップローダーは発売から3年たった今、約4.2万件のキャラクターがアップロードされていてなかなかカオスな状況になっています。一画面に表示できるのはキャラクター21人なので、すべてのキャラを見ていくためには2000回くらい画面を更新しないといけない計算です。そうなってくると1件1件のデータを自力で見ていくのではなく、コンピューターがデータを学習し、自動でいい感じのキャラを作ってくれればとても便利です。……つまり、†データサイエンス†の登場です。
そこで本記事では、この公式アップローダー内のキャラ1を機械学習モデルに学習させ、新たなキャラを生成することを目的とし、その過程でやってきたことをまとめます。
キャラクターをベクトルに変換する
さて、コイカツキャラのデータを機械学習モデルで学習するにあたって最初の問題となるのがそのデータ形式です。コイカツではpng画像の末尾にキャラクターのパラメータデータを付け、それを使ってゲーム中からキャラクターの読み込みを行っています。png画像のフォーマットでは明示的にファイルの終端を示す部分があるため、一般的なイメージビューアではpng画像部分のみで読み込みを終え、その後ろにあるキャラデータの部分は読み込まれません。このおかげでブラウザなどからはただのpng画像に見え、ゲーム中から読み出せばキャラクターデータとなる、という仕組みを実現しています。
既にgithubにはPythonからキャラデータを読み込むプログラムの実装があり、これを使えばキャラデータをJSON的な2リストとハッシュマップからなるデータ構造に変換することができます。試しにキャラカードを読み出すと、以下のようなデータ構造が得られます。
{
"custom": {
"face": {
"version": "0.0.1",
"shapeValueFace": [
...
],
"headId": 0,
"skinId": 0,
"detailId": 0,
"detailPower": 0.4490000009536743,
"cheekGlossPower": 0.0,
"eyebrowId": 1,
"eyebrowColor": [
...
],
"noseId": 0,
"pupil": [
{
"id": 69,
"baseColor": [
...
],
"subColor": [
...
],
"gradMaskId": 2,
"gradBlend": 0.5645166039466858,
"gradOffsetY": 0.5129030346870422,
"gradScale": 0.23225845396518707
},
...
このプログラムを使って学習データセットを用意したいのですが、読み込んだデータは単純なベクトルデータではないのでそのままニューラルネットの入力とすることはできません。そこで、含まれているデータをベクトルの要素として並べていく処理を実装しました。体型や顔の輪郭など、元から量的データとなっているものはそのままベクトルの要素に加え、髪型や瞳を選択する質的データはone-hotベクトルに変換した上で要素に加えます。
こうして出来上がったコイカツベクトルは1140の次元を持つベクトルとなりました。さらに、このベクトルのそれぞれの要素は元々のゲームの仕様から$[0,1]$の値域を持つため、ニューラルネットの出力層の活性化関数としてSigmoidを使えば扱いやすそうです。
キャラデータの学習
いよいよデータの前処理も終わり、学習することができるようになりました。そこで、どんな機械学習モデルを使うのかを考えます。機械学習の分野では、データの生成原理を推定し、それに近いデータを生成できるモデルのことを生成モデルと呼びます。生成モデルのカテゴリーに属する学習アルゴリズムはとてもたくさんありますが、学習・実装の容易さから、今回はVariational Autoencoderを使いました。Variational Autoencoderに関する詳しい解説はQiitaに記事がありますので、そこまで深く説明しないことにします。以下の記事がとてもわかり易いです。
また、Kerasでの実装にあたっては
を大いに参考にしました。
ざっくりと言うとVariational Autoencoderは、入力データを多次元ガウス分布に従う値に変換する機能(エンコーダー)と、変換された値から元の値に復元する機能(デコーダー)を持ちます。入力したデータから出力されたデータをうまく復元するようなニューラルネットのパラメータを得ることができれば、そのモデルは入力データとガウス分布を相互に変換できるようになります。ガウス分布に従う乱数の生成は簡単にできますので、ガウス分布の値→入力データの変換を使えば、乱数からデータを生成できるようになるわけです。
実際にデータを学習させ、層の数や素子数を変えた試行錯誤の結果、下ような構造のモデルが良い学習結果を示しました。
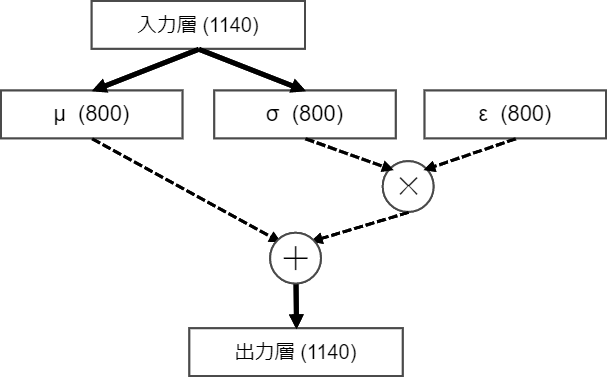 破線の矢印が要素ごとの演算を、太線が全結合層を表しています。全結合層が2つしかないモデルですが、あまり層数を増やしても学習結果と生成データに影響が無かったのでこうなっています。
破線の矢印が要素ごとの演算を、太線が全結合層を表しています。全結合層が2つしかないモデルですが、あまり層数を増やしても学習結果と生成データに影響が無かったのでこうなっています。
では、このモデルを使って生成されたキャラクターを見てみましょう。
生成されるキャラの例
学習回数が10, 20, 40, 60, 80, 100epochの時、それぞれキャラクターを10人ずつ生成しました。
-
10epoch

-
20epoch

-
40epoch

-
60epoch

-
80epoch

-
100epoch

観察できる特徴として、
- 10-40epochではまだ学習が足りず不安定なキャラが多い
- 100epochでは肌の色は良いものの髪の色がほとんど同じになってしまっている(上と合わせて過学習とのトレードオフといえる)
- 体型は全体的にほとんど同じになってしまっている(これはキャラメイクのデフォルトのキャラクターに近くなっていると考えられる)
が挙げられます。
まだまだヒロイン的風格をもったキャラクターは少ないですが、まずまずの結果が得られたのではないでしょうか😊
学習モデルをゲーム中から呼び出す
これでキャラクターの生成ができるようになったのですが、Pythonでキャラを生成しゲームを立ち上げて確かめる…という手間があり中々面倒臭いです。そこで、ゲーム中から学習モデルを呼び出すMODを作ってみました。
コイカツにはBepInEXというMOD読み込みのプラットフォームと、KKAPIというAPIを提供するMODが存在し、これを使えばMOD開発が容易にできるようになっています。今回はこれを使って開発しました。
さらに、KK_Pluginsというリポジトリには色々な機能を持ったMODがまとめて置いてあり、眺めてみるとコードを書く際の参考になります。特に今回は、実現したい機能に近いMODであるRandomCharacterGeneratorというMODを参考にしました3。
出来上がったものがこちらです。

行列演算をスクラッチで実装しているので生成まで少し時間がかかりますが、ボタン一つでキャラが生成できるようになりました。
今後の課題
最後に、今後取り組むべき問題についてまとめます。
初期キャラに引っ張られすぎる問題
コイカツではキャラエディット画面に初期表示されるキャラクターがおり、公式ロダにあるキャラの多くはこれを元に作られています。ですので、生成されるキャラクターはどうしてもこの初期キャラに引っ張られた体型や髪の色になっています。この対策として、初期キャラとのベクトルの負の誤差を誤差関数に加えるなどの対策が考えられます。
パラメータを固定した状態でサンプリングできない
例えば、髪の色を銀髪・肌の色を褐色に固定し、それを条件とした上でのサンプリングを行うことができません。これはボルツマンマシンなどの素子同士で相互関係を持ち合うモデルであれば実現可能だと考えられます。
まとめ
この記事では、コイカツのキャラクターデータを学習し生成を行うプログラムを実現させる上で得られた知見の数々をまとめました。
今後も学習モデルのチューニングを気ままにやっていきたいと思います。![]()
今回作ったプログラムは
に公開してあります。KoikatuGenが学習を行うプログラム、Koikatugen-PluginがMODです。