TensorFlowで画像認識「〇〇判別機」を作る
TensorFlowとは
Googleの機械学習オープンソースソフトウェアライブラリです。
公式ページ
目的の再定義
TensorFlowを使用して、画像認識 「オリジナル画像判別機」を作ります。
必要なもの
・Macbook Air
macOS Sierra 10.12.6
メモリ 大きいほど望ましい
・テキストエディタ
推奨:Atom
作成の流れ
- 必要なものを準備する
- 仮想環境に入る
- TensorFlowを入れる
- 教師データを用意する
- 学習させて、モデルを作る
- モデルを使って判別させる
Tensorflowを使って簡単な「〇〇判別機」を作ってみます。
なお、環境としてPython3系を前提としています。Pythonのバージョンは
python --version
で確認してください。
1. Tensorflowを使う環境を作る
TensorFlowの公式ページでご確認ください。
今回TensorFlowはversion1.4で実行していきます。
今回TensorFlowはversion1.8で実行していきます。(アップデートしました)
2. Tensorflowの再学習チュートリアルを使う
公式ページ:TensorFlowインストールする
を参考にしながらインストールします。
公式ページ:TensorFlowで画像認識(チュートリアル)
を参考にしながら画像認識のチュートリアルを行います。
これでTensorFlowのチュートリアルは完了しました。
次は画像を自分で集めて「自分専用の〇〇判別機」を作る作業です。
3. どんなものを作るかを決める
判別させたいものを決めましょう。
イメージとしては、例えば犬を「犬」と認識するのではなく、トイプードルなのか、柴犬なのかを判別できるものを作っていきます。
「何」判別機を作るかを決めましょう。私はうどん好きなので、かけ・釜揚げ・しょうゆ・ざるの4種類のうどんを判別できる「うどん判別機」を作ろうと思います。
自分が好きなもので、4種類くらいに分けられるものを自由に選んでみましょう。違いが大きいほど正確に判別できます。
また、最後にテストをする際に使う画像として、ご自身で撮影された写真があるとより良いです。
(例)
犬…柴犬、トイプードル、ブルドッグ、ラブラドールレトリーバー
クワガタ…コクワガタ、ノコギリクワガタ、オオクワガタ、ミヤマクワガタ
スパゲッティ…ボンゴレビアンコ、ボロネーゼ、アラビアータ、カルボナーラ
などなど。お腹がすいてきましたね!
4. Pythonに画像を集めてもらう
判別機を作るには、学習用の画像データが必要です。Google画像検索から一つずつダウンロードしていくと大変なので、Pythonを使って「スクレイピング」(画像を集めてもらう)をしてみましょう。
※このあたりからターミナルで色々打つようになります。うまくいかない場合はpythonのバージョンが違っていたり、必要なモジュールが入っていないことが多いです。エラーでno module named 〇〇のように出てしまったら、「Mac Python3 〇〇インストール」などでググると出てきたりします。
1.google_images_downloadをインストール
pip install google_images_downloadでインストールする
2.画像をダウンロードする
googleimagesdownload -k 検索したいワードで画像を集めに行きます。
実行した階層からダウンロードが実行されます。
downloads/検索ワードディレクトリ(自動生成)/1.xxxxxx.jpg(画像)
というように、downloadsというディレクトリと、検索ワードディレクトリが自動生成されます。
その中にデフォルトで100枚の画像がダウンロードされていきます。
複数のキーワードで集めたい場合は、googleimagesdownload -k 検索したいワード -sk 二つ目のワードとしてください。
その他参考情報は http://co.bsnws.net/article/295 こちらにどうぞ。
3.データの選別をする
残念ながら集めてきてくれたものの中にはあまりふさわしくないデータや壊れているデータも存在します。
例えば、以下の画像かけうどんというより肉の塊です。
こういったものや、違うものが大きく写り込んでいるもの、複数の何かがごちゃごちゃ写っているものなどは除いておきましょう。この一手間で画像認識の精度が大きく変わります。
また、各フォルダの中から、
最後に認識させる画像を1枚ずつ選び、デスクトップに移動させておきましょう。
#4'. Pythonに画像を集めてもらう(bs4.ver 改良中)
判別機を作るには、学習用の画像データが必要です。Google画像検索から一つずつダウンロードしていくと大変なので、Pythonを使って「スクレイピング」(画像を集めてもらう)をしてみましょう。
※このあたりからターミナルで色々打つようになります。うまくいかない場合はpythonのバージョンが違っていたり、必要なモジュールが入っていないことが多いです。エラーでno module named 〇〇のように出てしまったら、「Mac Python3 〇〇インストール」などでググると出てきたりします。
- beautifulsoup4をインストール
pip install beautifulsoup4でインストールする。
- スクレイピングプログラムをつくる
Atomを開き、以下のコードをコピー&ペーストしてください。
# coding: utf-8
import os
import sys
import traceback
from mimetypes import guess_extension
from time import time, sleep
from urllib.request import urlopen, Request
from urllib.parse import quote
from bs4 import BeautifulSoup
MY_EMAIL_ADDR = ''
class Fetcher:
def __init__(self, ua=''):
self.ua = ua
def fetch(self, url):
req = Request(url, headers={'User-Agent': self.ua})
try:
with urlopen(req, timeout=3) as p:
b_content = p.read()
mime = p.getheader('Content-Type')
except:
sys.stderr.write('Error in fetching {}\n'.format(url))
sys.stderr.write(traceback.format_exc())
return None, None
return b_content, mime
fetcher = Fetcher(MY_EMAIL_ADDR)
def fetch_and_save_img(word):
data_dir = 'data/'
if not os.path.exists(data_dir):
os.makedirs(data_dir)
for i, img_url in enumerate(img_url_list(word)):
sleep(0.1)
img, mime = fetcher.fetch(img_url)
if not mime or not img:
continue
ext = guess_extension(mime.split(';')[0])
if ext in ('.jpe', '.jpeg'):
ext = '.jpg'
if not ext:
continue
result_file = os.path.join(data_dir, str(i) + ext)
with open(result_file, mode='wb') as f:
f.write(img)
print('fetched', img_url)
def img_url_list(word):
"""
using yahoo (this script can't use at google)
"""
url = 'http://image.search.yahoo.co.jp/search?n=60&p={}&search.x=1'.format(quote(word))
byte_content, _ = fetcher.fetch(url)
structured_page = BeautifulSoup(byte_content.decode('UTF-8'), 'html.parser')
img_link_elems = structured_page.find_all('a', attrs={'target': 'imagewin'})
img_urls = [e.get('href') for e in img_link_elems if e.get('href').startswith('http')]
img_urls = list(set(img_urls))
return img_urls
if __name__ == '__main__':
word = sys.argv[1]
fetch_and_save_img(word)
os.rename('data/', str(word) + '/')
get_images.pyという名前をつけて保存しましょう。保存場所はどこでもいいですが、今回はデスクトップにフォルダgakusyu_dataを作り、そこに保存しましょう。
3. 画像をダウンロードする
ターミナルでget_images.pyを実行してみましょう。
python get_images.py 検索したいワード```
get_images.pyの入っているフォルダに、検索したワードと同じ名前のフォルダが生成され、60枚の画像がダウンロードされているはずです。
以上の作業を何回か繰り返し、必要なデータを集めます。
最終的にはこのようになるでしょう。
<img width="452" alt="32a936cd42a64c5d98e85e53db46b141.png" src="https://qiita-image-store.s3.amazonaws.com/0/206583/f525dc52-0131-7a96-5f5f-41a38c4f6ad5.png">
4. データの選別をする
残念ながらget_images.pyが集めてきてくれたものの中にはあまりふさわしくないデータも含まれています。
例えば、以下の画像かけうどんというより肉の塊です。
<img width="803" alt="91a39fd1383da65b20dc2bceb8e57db5.jpg" src="https://qiita-image-store.s3.amazonaws.com/0/206583/95024f98-f1d1-c0bf-a2b5-3f62c5e681ce.jpeg">
こういったものや、違うものが大きく写り込んでいるもの、複数の何かがごちゃごちゃ写っているものなどは除いておきましょう。この一手間で画像認識の精度が大きく変わります。
また、各フォルダの中から、
最後に認識させる画像を1枚ずつ選び、デスクトップに移動させておきましょう。
</div></details>
# 5. 集めたデータを学習させる
それではいよいよ集めたデータでモデルを作っていきます。
https://github.com/tensorflow/models
こちらから、modelをダウンロードしておきます。
まずはFinderから /models-master/tutorials/image/imagenet に移動します。
そこにgakusyu_dataフォルダをコピペします。
<img width="207" alt="スクリーンショット 2018-11-29 14.58.52.png" src="https://qiita-image-store.s3.amazonaws.com/0/320853/b8321662-2ab4-b0c8-1400-0bc45de7403b.png">
また、フォルダ名が日本語だとうまくいかないので下のように英語にしておきましょう。
<img width="436" alt="8b2098ffb23a1ca815aab818322d7e48-2.png" src="https://qiita-image-store.s3.amazonaws.com/0/206583/ebcfc54c-e9d8-cd09-8470-20af16875a91.png">
次にターミナルを開き、再学習に必要なプログラムをダウンロードします。
`curl -LO https://github.com/tensorflow/hub/raw/master/examples/image_retraining/retrain.py`
続いて、必要なモジュールをインストールします。
`pip install tensorflow_hub`
そして、以下のコマンドを1回で、全てコピー&ペーストします。
python retrain.py
--bottleneck_dir=bottlenecks
--how_many_training_steps=100
--model_dir=inception
--summaries_dir=training_summaries/basic
--output_graph=retrained_graph.pb
--output_labels=retrained_labels.txt
--image_dir=gakusyu_data
しばらくすれば学習は終了です。これで判別機が完成しました!
# 6 実際に判別機を使ってみる
いよいよ完成した判別機を使ってみましょう。
/models-master/tutorials/image/imagenet に、判別させたい画像を移動します。
(#4でデスクトップによけておいた画像を移動します。)
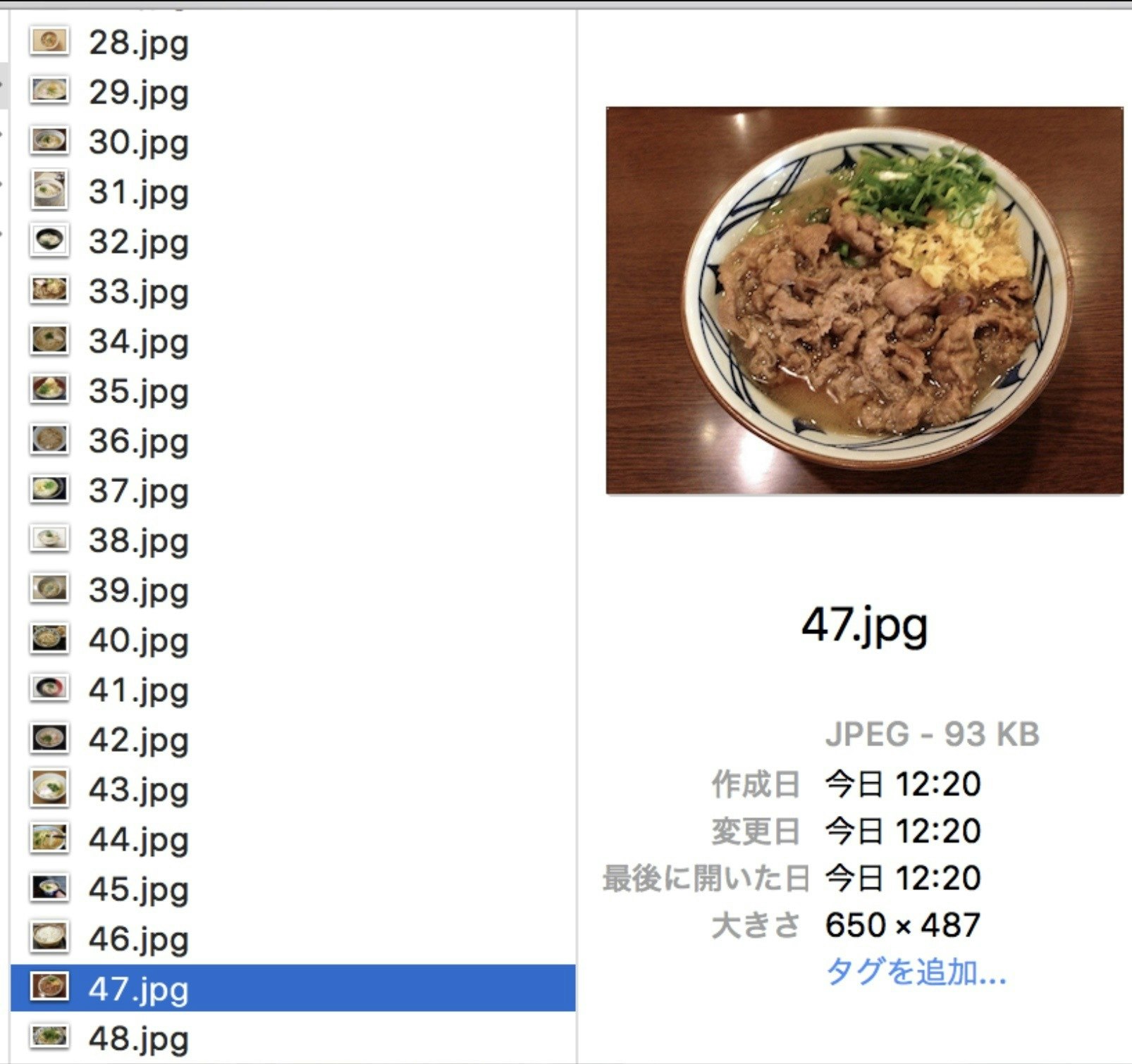
ここでは01.jpgという名前にしておきます。画像の拡張子はpngなどでも大丈夫です。
<img width="487" alt="a534699fb16dc0f2847c5c2bf82930a7.png" src="https://qiita-image-store.s3.amazonaws.com/0/206583/6ffaf83b-fe45-fd4f-5c1b-18264df6b51b.png">
(ちなみにこれは新宿にある「慎」という筆者オススメのうどん屋さんの醤油うどんです)
判定に必要なプログラムをダウンロードします。
`curl -LO https://github.com/tensorflow/tensorflow/raw/master/tensorflow/examples/label_image/label_image.py`
それでは実行してみましょう。
python label_image.py
--graph=retrained_graph.pb
--labels=retrained_labels.txt
--input_layer=Placeholder
--output_layer=final_result
--image=01.jpg
すると、どの種類にどれくらい近いのかをscore(パーセント)で表してくれます。
<img width="190" alt="8cba14ef68b31fc8b9286604ba926b1d.png" src="https://qiita-image-store.s3.amazonaws.com/0/206583/b2d79fbc-9dca-7634-4918-3e6d492f77c3.png">
みごと、醤油うどんだとわかってもらえました!
※上のコマンドでKeyErrorが出るという方は、label_image.pyの78,79行目を
```input_layer = "Mul"
output_layer = "final_result"
に変更してみましょう。
参考: https://github.com/tensorflow/tensorflow/issues/12736
これで判別機の作成は終了です。お疲れ様でした!
7. さらに+α
ここまできてさらに余裕があるという方は、以下にチャレンジしてみましょう。
・より多くの種類を判別できるようにする
・判別の精度をさらに上げる
・もっと多くのデータを集めてみる
などなど
このチュートリアルだけでなく、インターネットで色々調べることでいい方法を見つけられるかもしれません。