LLMによる記事の要約
このQiitaの記事では、Amazon Bedrockを使用して伝説のジャズミュージシャン、チャーリー・パーカー風の音楽を作成するプロセスについて説明しています。2023年のre:Inventで紹介された新機能「Continued Pre-training」と「Fine-tuning」について、それぞれの違いと使用シナリオを解説しています。ABC記法を用いた音楽生成の方法と、チャーリー・パーカーのスタイルを模倣する試みのプロセスと成果についても述べています。
はじめに
今年も始まりました、アドベントカレンダー!今回はAmazon Bedrockについて書いてみたいと思います。
12/18分を担当しているのですが、すでに画像生成やprompt、LangChainなどなど非常にバリエーションに富んだ記事がありますね!
何を書こうか迷ったのですが私の方ではre:Invent 2023でアナウンスされたAmazon Bedrockの新機能であるContinued pre-trainingとFine-tuningを使って遊んだ記事を書きたいと重います。
— おばけ👻 (@triwave33) December 15, 2023
音楽も作れるよ。そうAmazon Bedrockならね。
Amazon BedrockのFine-tuningとContinued pre-training

(AWS re:Invent 2023 - CEO Keynote with Adam Selipsky on YouTube)
11月28日のre:Invent2023で、Amazon BedrockがFine-tuningおよびContinued pre-trainingに対応することが発表されました。Fine-tuningは一般利用開始、Continued pre-trainingはPreviewです(いずれもバージニアとオレゴンリージョンにて提供)
Amazon Bedrockでは多彩なモデルを用意していますが、これでさらにユーザの要望に応じてモデルを簡単にカスタマイズできるようになりました!
カスタマイズ対応のモデルは、
- Fine-tuning
Meta Llama 2, Cohere Command Light, and Amazon Titan Text
- Continued pre-training
Titan Text
となります。
まずはこの二つのモデルカスタム機能、Fine-tuningとContinued pre-trainingの使い分けについて説明します。
Fine-tuningとContinued pre-traiingの使い分け
大規模言語モデルをカスタマイズする目的について説明します。
Fine-tuning
汎用的なLLMを特定のタスクに特化させたい場合、Fine-tuningが有効です。例えばコールセンターで、顧客との会話内容から最終的に{A,B,C}の提案の中から一つを選ぶ業務がある場合、会話の内容から提案を指示するモデルを作成できればシンプルな意思決定と自動化が期待できます。(クラス識別タスクへの特化)

他には、チャットの応答を特定のスタイルで返すケースもFine-tuningが有効です。丁寧な敬語が求められたり、特許や法律のように特徴的な文章を生成することが求められるケースです。特定のキャラクタの語調をまねる、なんてのもありますね(スタイルの特化)
上の2例はLLM自体が獲得している知識には手を加えず、モデルの出力を特定の形に特化させていると考えることができます。このような場合に用いるのがFine-tuning、とここでは考えて下さい。
Continued Pre-training
一方で、汎用的な大規模言語モデルが持ち合わせていない知識、例えば特定の業界での用語や慣習、常識などを新しい知識として覚え込ませたい場合があります。
いきなり化学の話をしますが、 「硫酸を希釈するときは、水に硫酸を加えるか? それとも硫酸に水を加えるか?」 覚えていますか?

答えは 「水に硫酸を加える」 です。
単純に化学のテストで満点を取りたいのであれば、問題と答えだけをモデルに教え込ませればよいでしょう。しかし、現実にこの問題を取り扱うことを考えてください。硫酸の希釈の仕方を知らなかった人にやり方だけ教えて「じゃあよろしく」と任せられますか?(私には恐ろしくて無理です。)
きっと人間であればこの状況の背景を想像するでしょう。そもそも何で希釈したいの?濃度は?保護メガネつけてる?廃液タンクはどれかわかる?など。与えられた状況下から、その後起こりうる現象に対応するための質問やアドバイスをするはずです。それは、決して希釈の方法をピンポイントで暗記しただけではできないことでしょう。その場合、硫酸と水の物性および化学的性質、溶解・水和・解離といった物理化学現象、実験器具・分析手法といった化学的知識が集積されており、それが「硫酸の希釈」というキーワードに伴って総動員されるものです。観念的ではりますが、このような学習を行うのがContinued Pre-trainingと、この記事では説明します。
もちろん、全てのパターンがこの二つのどちらかに当てはまるわけではなく、完全に二者択一の別物とはならないことにも注意してください。特にFine-tuningの技術は多岐にわたるため、この説明に違和感を感じる方もいらっしゃると思いますし、「Fine-tuningが知識を獲得するのか?」については技術的な発展と検証が必要でしょう(もっとも、知識を定義する必要がありそうです)。
とにかく、ここでは概念として、そしてAmazon Bedrockの機能としてFine-tuningとContinued Pre-trainingの二つがある、と覚えていただければOKです。
Amazon Bedrockでは
- Finetuning
- 少量のラベル付きデータを使って特定のタスクの精度を最大限に高めるもの、
- Contunued pre-training
- 大量のラベルなしデータを使ってモデルにドメイン知識を与えるもの
と説明しています。
次に、Amazon BedrockのFine-tuningとContinued pre-trainingの技術的な側面を説明します。
データのフォーマット
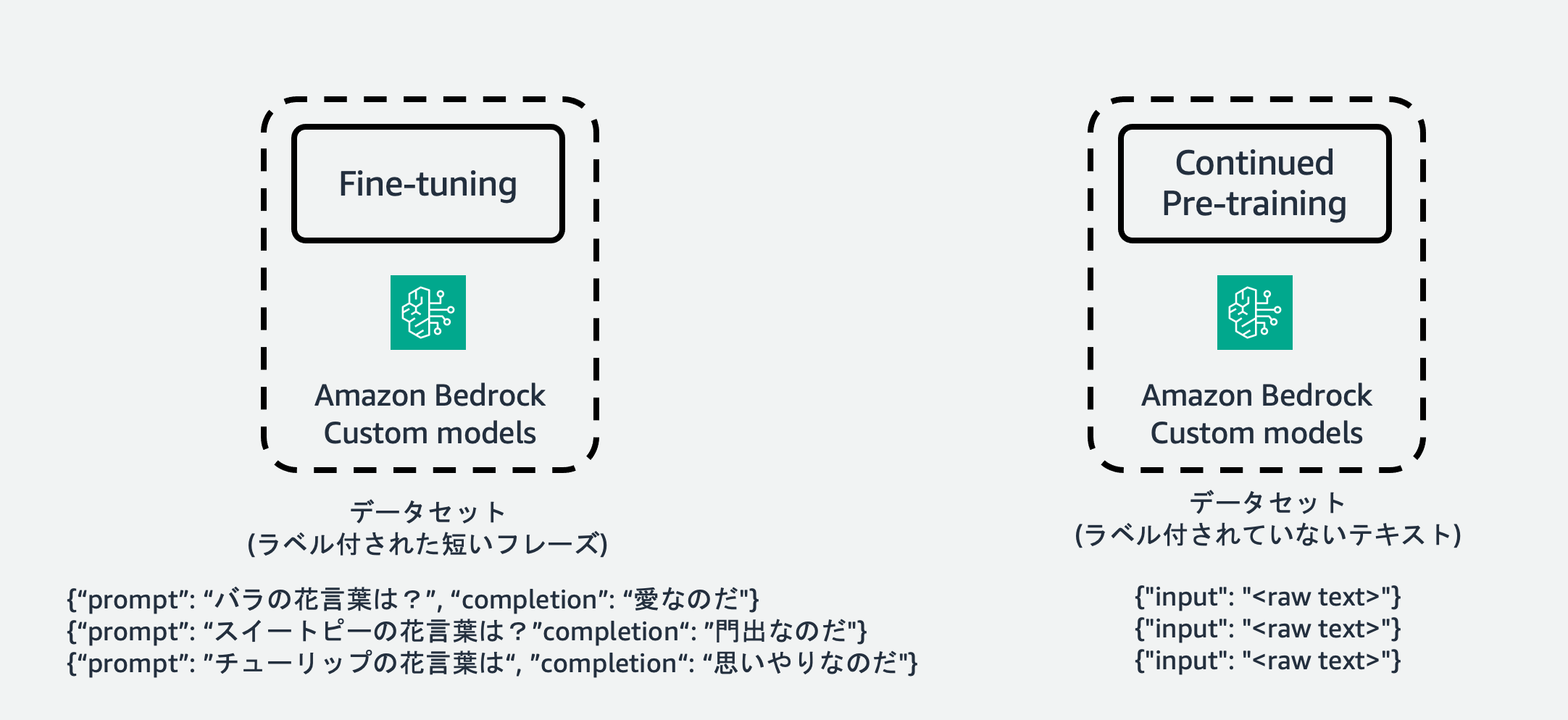
Fine-tuning
Amazon bedrockでFine-tuningを行う場合、必ずデータを<入力, 出力>の対で準備します。LLMに投げるリクエスト(入力)に対して答えてほしい出力を準備しておく必要があります。これは機械学習の文脈で言う教師あり学習に他ならず、"sft" (supervised fine tuning)と呼ばれることもあります。Amazon Bedrockでは入力のキー名に"prompt"、出力のキー名に"completion"を使ったjsonフォーマットで各サンプルデータを表し、各行にjson文字列が入力されたjsonl (json line)フォーマットで全体のデータを準備します。
この図では、「バラの花言葉は?」などのユーザ入力プロンプトに対して、「〜なのだ」という特定の(某キャラクターの)語尾のスタイルを獲得するようなタスクを想定しています。もちろんバラの花言葉(Question)に対して愛(Answer)を答えるといったようなQuestion & Answerのタスクを解いていると考えることもできます。
Continueed Pre-training
一方、Continued Pre-trainingを行う場合はラベル付けされたデータセットは必要とせず、シンプルにテキストをinputとして与えます(キー名も"input")。これは「次の単語(正確にはトークン)を予測する」という言語モデルの特性に関連しており、大規模言語モデルを事前学習する(Pre-training)ときも大量のラベルなしテキストをデータとして与え、次のトークンを予測するように自己教師あり学習をおこないます。Continued Pre-trainingは文字通り、継続した事前学習ですので、データセットもPre-training同様ラベル付けを行う必要がありません。
データフォーマットの詳細はこちらのドキュメントを参照してください
Amzon Bedrock User Guide: Custom models - Prepare the datasets
Amazon BedrockでFine-tune, Continued Pre-trainingを実行する方法
ここではコンソール画面からFine-tune,Continue Pre-trainingを行う方法について説明します。どちらの同じような操作感で非常にシンプルにモデルのカスタマイズを実行できます。Amazon SageMakerや他のAIサービスのコンソール操作に慣れている人であれば、数分で実行操作を完了できます。
ドキュメントはこちらです。
Amzon Bedrock User Guide: Custom models - Using the console
ブログの分量が非常に長くなったため、具体的な操作方法と画面は以下に折りたたんで表示してあります。
具体的な操作方法を知りたい方は下記をクリックして内容を確認してください。
とりあえずブログを読み進めたいかたはそのまま次の章へ進んでください。
(※※詳細はクリックしてください!)コンソールからのモデルカスタムジョブの実行と推論方法
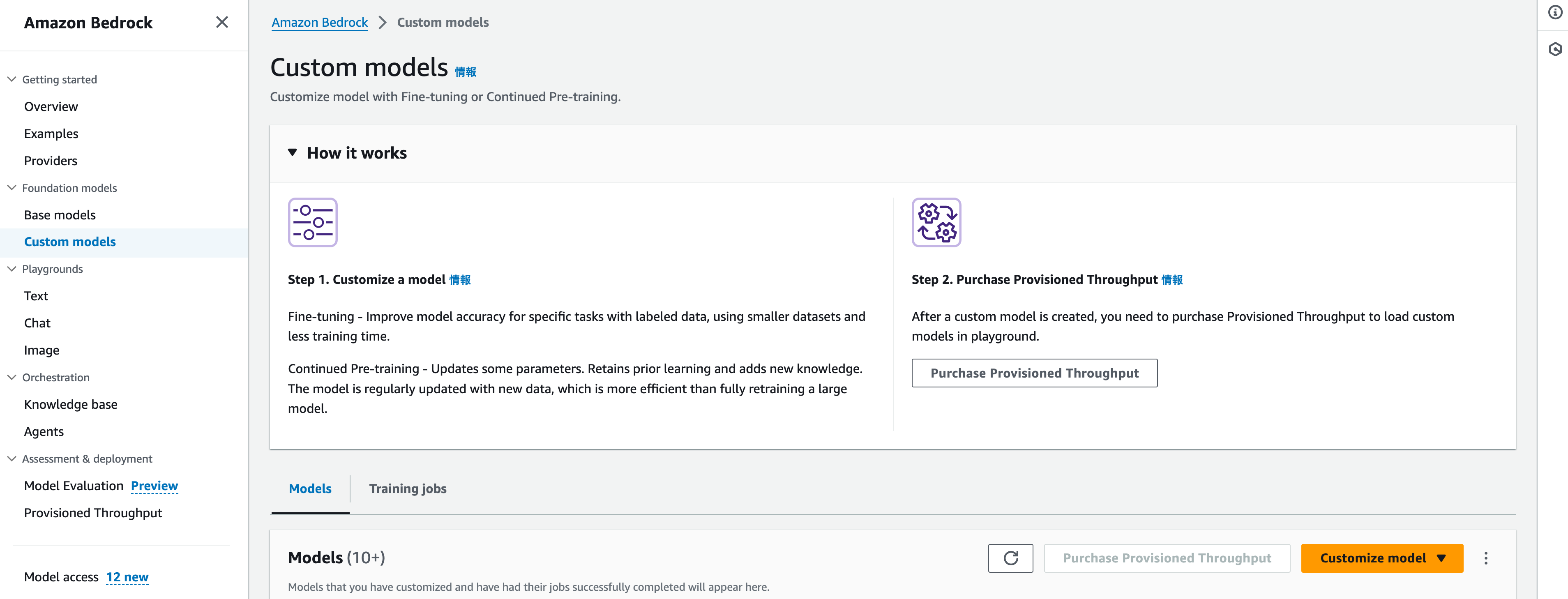
モデルのカスタマイズ
Fine-tuningジョブの実行
| スクリーンショット | 動作 | |
|---|---|---|
| 1 | |
Amazon Bedrockのコンソールの左メニューから Cusom models を選択して、右下のCustomize modelのオレンジボタンをクリックします。 |
| 2 | 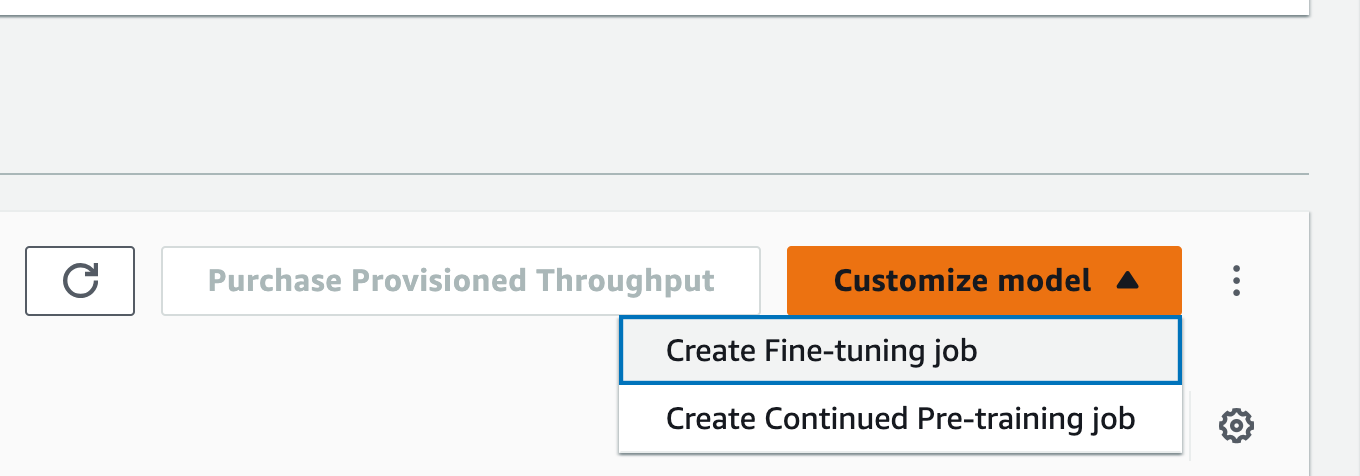 |
今回はFine-tuningを行うのでCreate Fine-tuning jobをクリック |
| 3 | 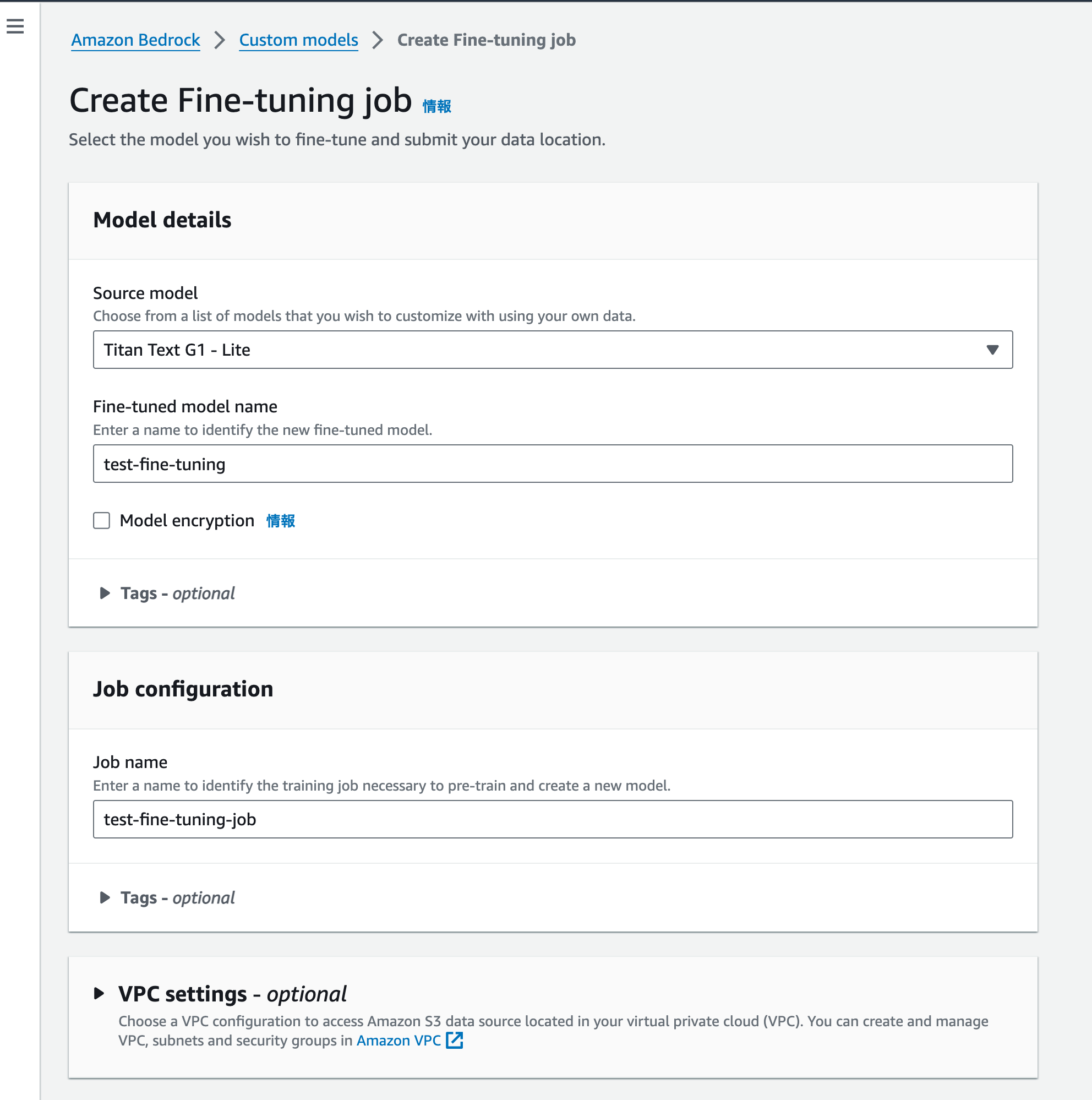 |
Fine-tuning jobの設定画面に飛びますので、設定をしていきます。 |
| 4 | 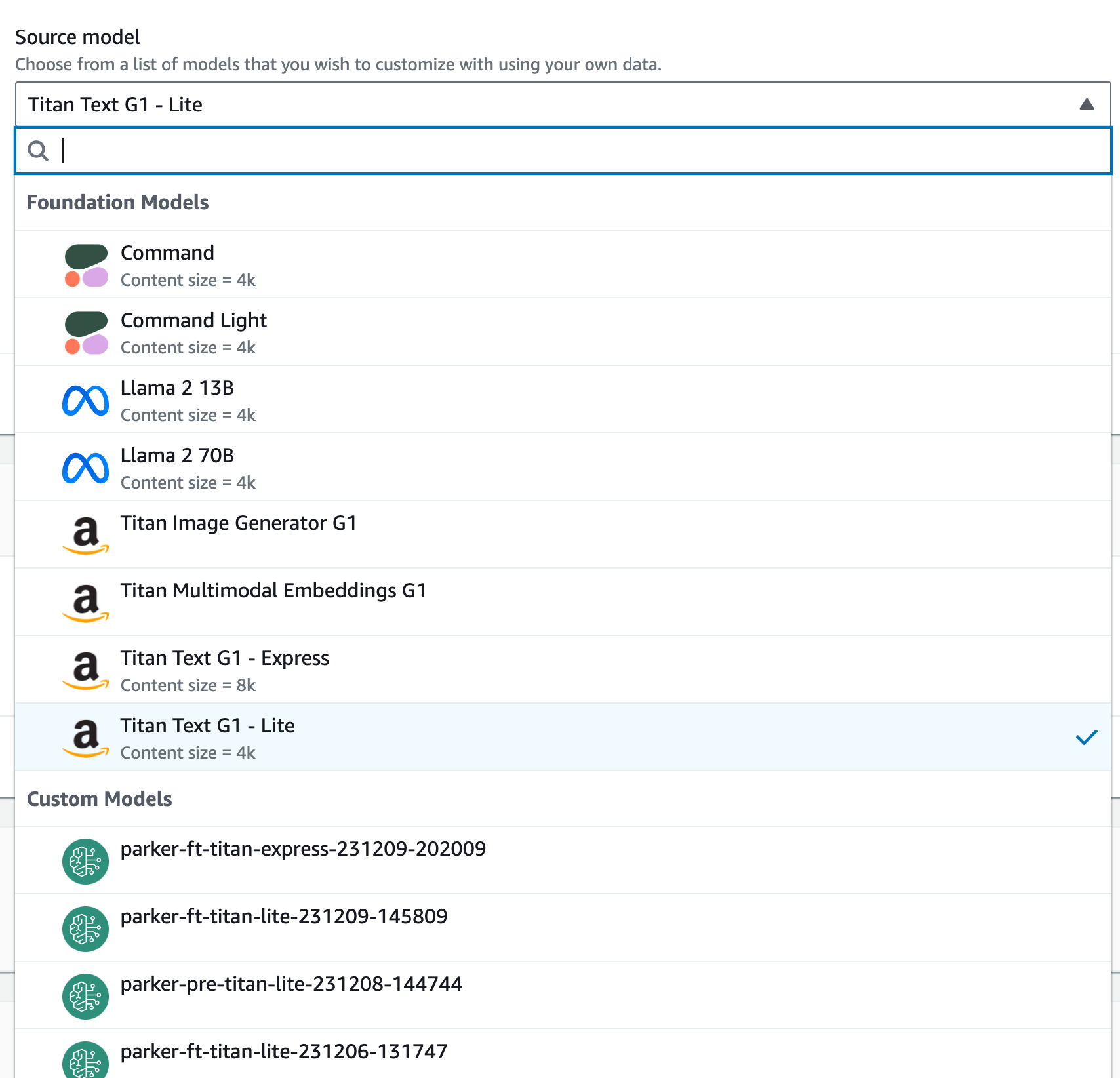 |
ベース(学習の出発点となる)モデルを選択します。一度Fine-tuningしたモデルを選ぶ(学習を引き継ぐ)こともできそうです。 |
| 5 | 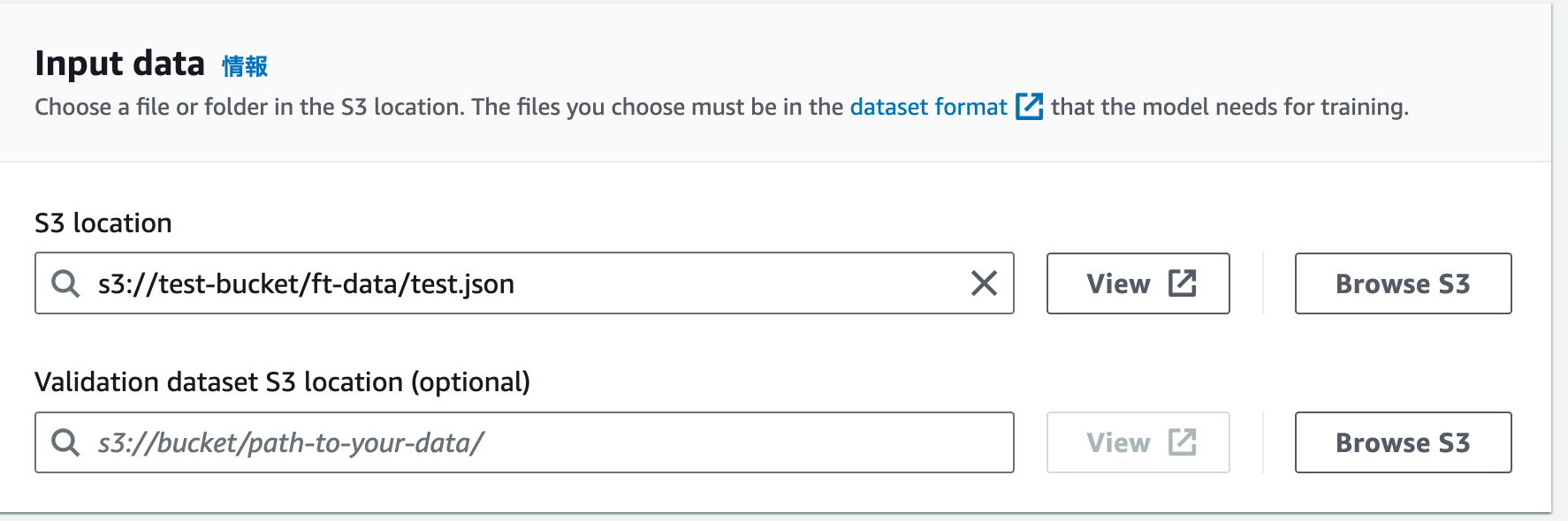 |
学習に必要なデータはInput dataの項目で設定します。S3に必要なデータを配置し、その場所(S3 URI)を指定します。trainingデータとvalidationデータを別に設定することもできます。 |
| 6 | 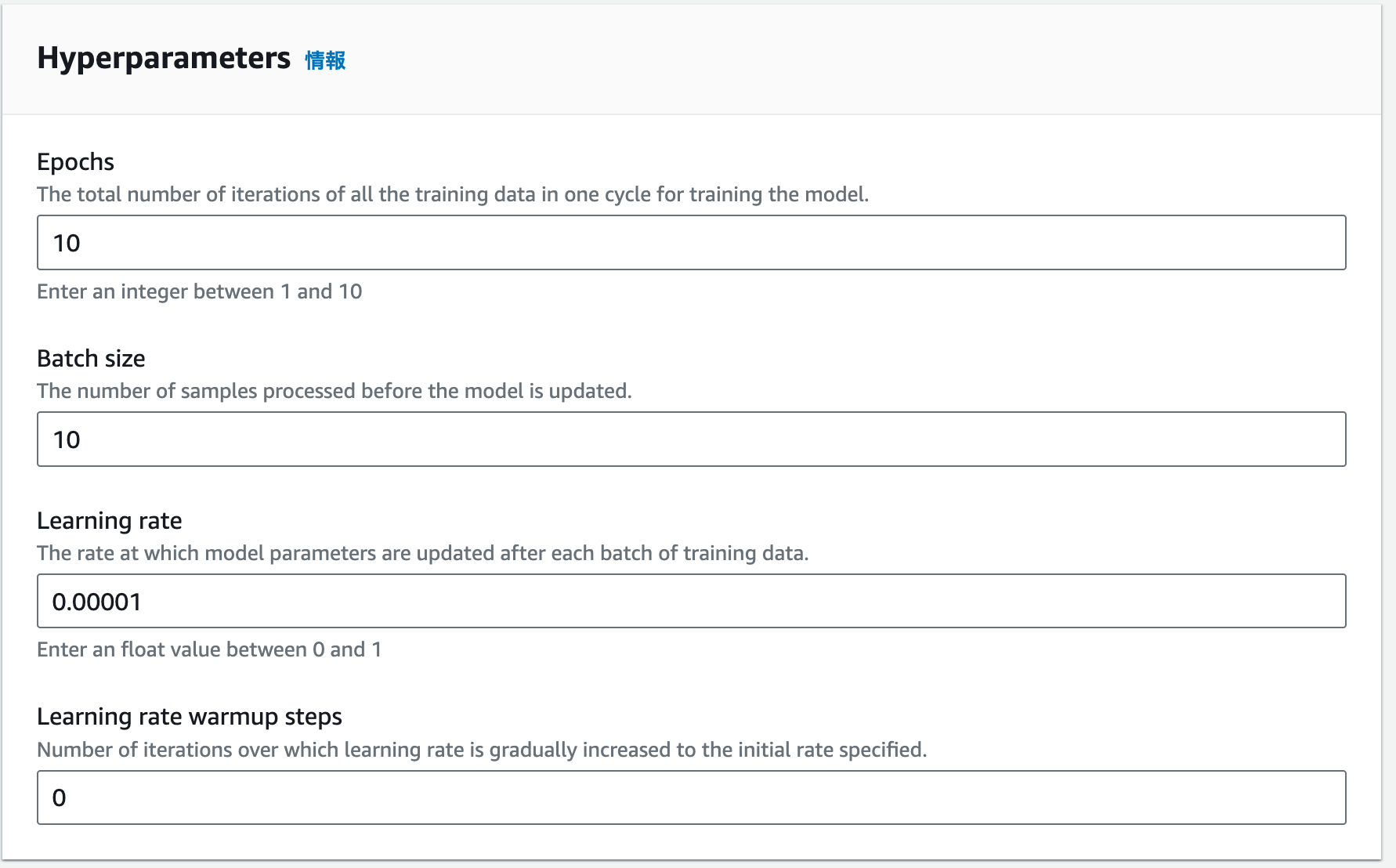 |
ハイパーパラメータの設定。非常にシンプルです。Learning rate warmup stepsは指定したLearning rateでいきなり学習を始めるのではなく、徐々にその学習率まで増加させるためのパラメータのようです。 |
| 7 | 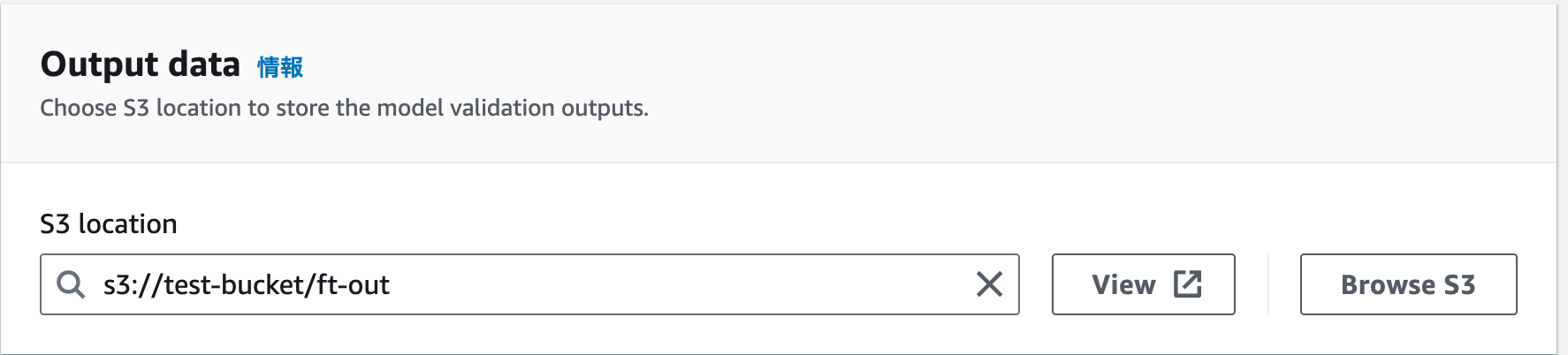 |
学習のログ(lossの推移)などを出力するS3パスを指定します。 |
| 8 | 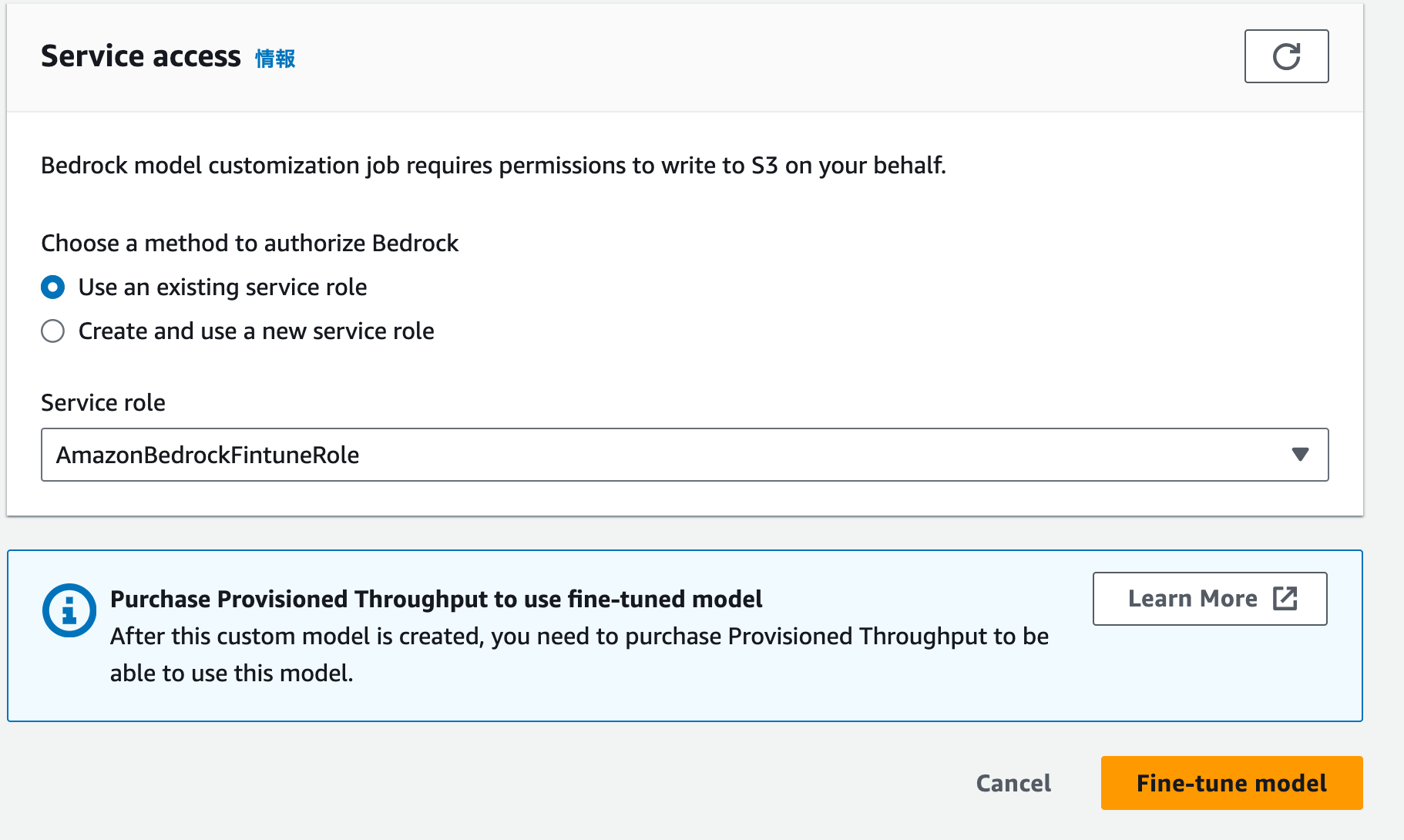 |
IAMロールを指定してFine-tune modelを押せばFine-tuningが開始されます。とっても簡単! |
Continued Pre-trainingジョブの実行
Fine-tuningジョブと全く同じように実行できます。現在、Amazon Titan Text G1 Lite, ExpressがContinued Pre-trainingの対象です。
| スクリーンショット | 動作 | |
|---|---|---|
| 1 | 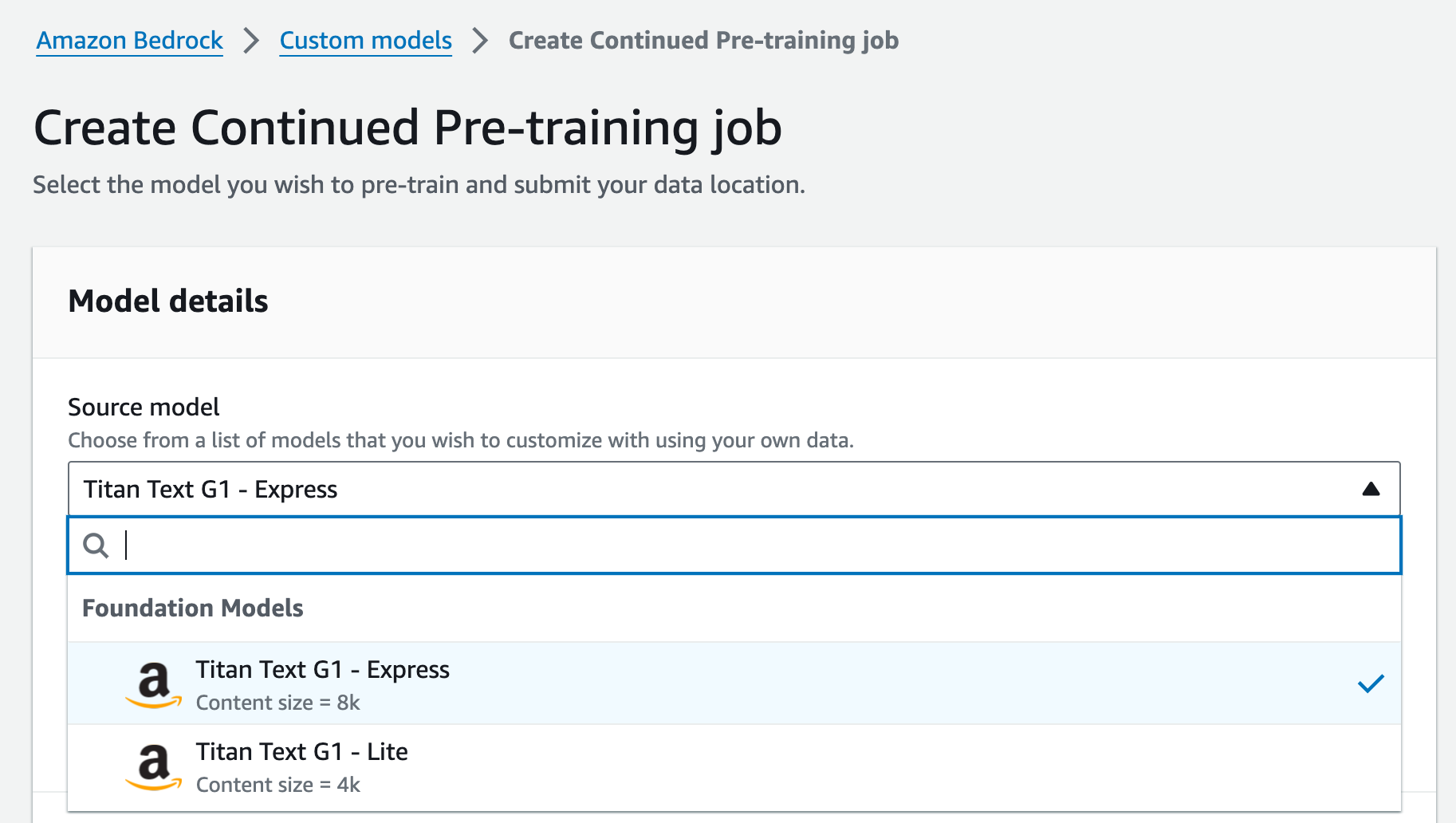 |
Titanモデルのいずれかを選択。以下はFine tuningと同様 |
カスタムモデルの使用
カスタムモデルはモデルの扱い方やコスト体系が従来の汎用モデル(カスタマイズされていないモデル)とは異なります。
モデルの使い方が、従来のリクエスト量(正確には入出力トークン長)に応じたオンデマンドでの課金方式から、時間あたりの課金方式になります。これは汎用モデルを複数ユーザで使い回す従来の方式と違い、カスタマイズしたモデルをユーザだけが使えるように専用の環境をセットアップする必要があるためです。
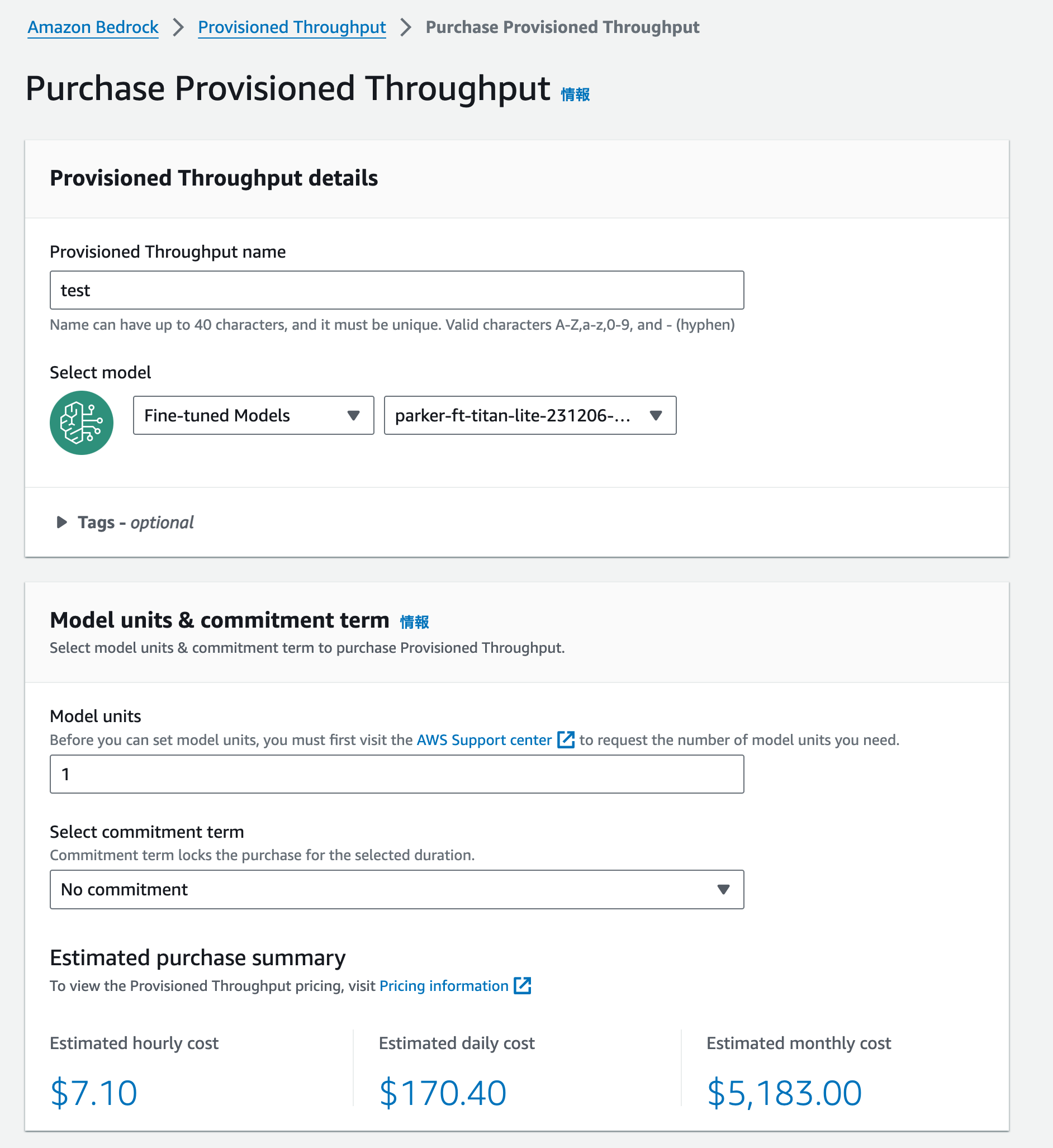
(Provisioned Throughputの購入画面。Titan liteで7.10 USD/hourの料金。1時間あたりの料金体系の他に1ヶ月、6ヶ月分をまとめてコミットするプランもある)
使いたいモデルごとにProvisioned Throughputとよばれるユニットを購入し、モデルを利用可能な状態にセットアップします。まそセットアップ自体は自動で行ってくれます。Amazon SageMakerのエンドポイントの考え方に似ています。(ちなみにカスタマイズしない汎用のモデルにもProvisioned Throughputの機能はあります)
そのため、カスタマイズモデルを用いる時はリクエストが来なくても課金が発生することになります。 使わない時にはProvisioned Throughputを削除しないと高額の課金が請求されるおそれがあるため、くれぐれも削除し忘れにはご注意ください。
またカスタマイズしたモデルはPlaygroundでは使えないのでAPIを使用して実行します。
Provisioned Throughputの詳細と料金についてはこちらをご参照ください
Amzon Bedrock User Guide: Custom models - Provisioned Throughput
Amazon Bedrock の料金表 – AWS
実際にFine-tuning, Continued Pre-trainを試してみる
それでは実際にモデルカスタマイズ試してみましょう。残念ながら現在(2023年12月14日時点)でAmazon BedrockのModel Customizationは日本語に対応していません。英語のデータセットを使う必要があります。
英語のデータセットで検証しても良いのですが、いかんせん面白くないのでここは思い切って別の問題設定に取り組んでみましょう。そう音楽生成です。
音楽データのフォーマットと表記方法
以前の記事で、ニューラルネットワークを使った音楽生成の記事を書きました。
この記事ではバッハの音楽データから楽曲を生成したのですが、各パートの楽譜データを配列として持たせていました。例えば4声の教会音楽であれば、4小節を16部音符でクォンタイズして、それぞれの音の高さに区切ったone-hotベクトルをクォンタイズ幅分用意する、それを4パート分用意する。といった形です
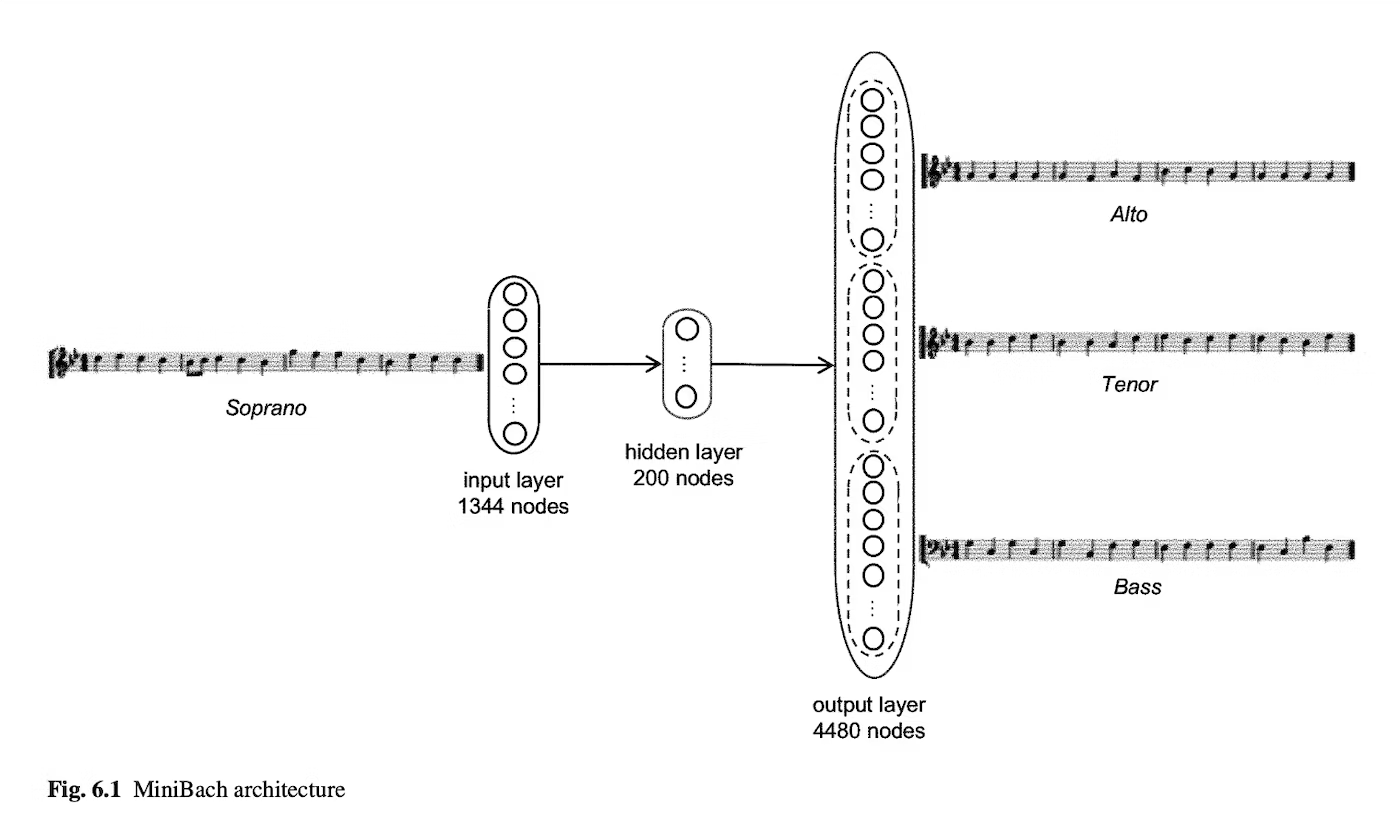
今回は、もっとシンプルな方式として言語モデルを使って音楽を生成します。
ABC記譜法
音楽(楽譜データ)の表し方にはさまざまなフォーマットがあります。今回はABC記譜法 (ABC notation)というものに着目してみました。詳細は詳しい書籍などに任せるのですがWikipediaでは以下のようにABC記法を紹介しています。
ABC記譜法(エービーシーきふほう、ABC music notation あるいは ABC notation)は、パソコン等で使われる音楽記述言語の一つで、イギリスの Chris Walshaw によって考案された。単に「ABC」とも、また小文字で「abc」とも言う。音高を表すアルファベットと、音長を表す数字、その他の若干の記号を組み合わせて表記する。
ABC記譜方を使うことで以下の楽譜(フレーズ)は

次のような文字列で表されます
| "D7" z4 z2 z D |"G" GABc dBcd |"G" BG z2 z2 z D |"Gm" GA_Bc d e2 f |
zは休符、A-B (もしくはa-b)は音階を示しています。"D7"などのコードネームも表記されていますね。このように音楽を文字列で表すことができます。だったら言語モデルで扱えるんじゃね!? というのが今回の記事のモチベーションです。
使用データ
今回は、チャーリー・パーカーというサックス奏者のデータを使います。パーカーはジャズ史における偉大なレジェンド、金字塔、革命家、ビバップの開拓者。呼び名にはキリがないですが、ともかく今日のジャズの即興演奏スタイルの基礎を築いた偉大なミュージシャンです。

(Photo of Charlie Parker from Wikipedia)
チャーリーパーカーの奏法・フレージングの特徴をAmazon BedrockでClaude 2.1(これも今回のre:Inventで発表されましたね)に聞いてみましょう。

うーん、なんとなくそれらしいことは言っている気がします。シャープな音、は意味不明ですが。臨時記号を多用してフレーズに緊張感を与えるってことでしょうか。

自分なりに上のフレーズで説明すると
- 上昇・下降を含めたジェットコースターのような息の長いフレーズ
- トリル(上がって戻る)による引っ掛けるようなアプローチ(1小節目1拍目)
- 8分、16分、3連符を絡めた自在な緩急
- 分散和音によるコード感の表現(1小節目4拍目)
- クロマチック(半音)アプローチによるコードトーンへの解決(3小節目4拍目から次の小節のF)
なんかが個人的にパーカーらしいフレーズと感じます。これを彼の演奏データから生成させることを試みてみます。
データセットはCharlie Parker's Omnibook MusicXML dataを用います。これはパーカーの過去の演奏50曲を採譜しMusicXMLと言われるフォーマットのデータセットにしたものです。曲のメロディ(テーマ)部分だけでなくアドリブ(即興演奏)部分も記譜されています。
Charlie Parker's Omnibook MusicXML data
citationはこちら
Ken Deguernel, Emmanuel Vincent, and Gerard Assayag.
"Using Multidimensional Sequences for Improvisation in the OMax Paradigm",
in Proceedings of the 13th Sound and Music Computing Conference, 2016.
このデータセットはCreative Commons Attribution NonCommertial-ShareAlike license, version 2.0で非商用利用に限って使用が許可されています。もちろんこのブログも、商売っ気一切なしの非商用の記事です。
このXMLデータをABCフォーマットに変換して用いました。変換にはxml2abcというツールを用いました。
今回は特にConfirmationという曲にフォーカスして生成フレーズを紹介したいと思います。
パーカーが作った曲で、約80年経ったいまもジャズのスタンダードとして君臨しています。急速なコードチェンジを繰り返すパーカーの魅力がこれでもかと詰まった曲で、この曲で即興演奏するのは非常に高難度です。しかし、パーカーの演奏はテクニックを押し付けるのではなく、歌うようなフレーズでこの曲に色々な感情、個人的にはハッピーなようなそれでいて少し切ないような気持ち、を加えながらのびのびと吹いています。
この曲を聴いてパーカーのフレーズの流麗さを頭に入れてから、続きを読んでもらえればうれしいです(100回くらい聴いてくれ)
データセットの作成
Continued Pre-training
前述の通り、Continued Pre-trainingはラベルなしの教師データを用意すればよいので、文字列となった演奏データを基本的にそのままつっこみます。
こういった演奏、つまりサックスのフレーズの羅列(中略)に対して

下のようなABC記譜法の文字列をひたすら曲の分だけ作成していきます。コードネームが含まれているバージョン、含まれていないバージョンと2パターン用意しました。(下記はコードありバージョン)
{"input": "'F'Ac2A_BA(3EF^F|'Em7b5'Gd_BG'A7'A^C2G|'Dm'zFz2'G7'z2zA|'Cm'G_BAG'F7'zF2B|'Bb7'B_B_AFB(AA2)|'Am'zc_BG'D7'^FAD(=B|'G7'B2)eAz2z_e/d/|'Gm'_dFGE'C7'zc3|'F'A2zF(3_BA_AG=A|'Em7b5'F/G/_Ez2'A7'z^C2G-|'Dm'GF2z'G7'z2zA|'Cm'G_BAG'F7'F_DFF-|'Bb7'F_A_BFABz2|'Am'z_EG_B'D7'A^Fz2|... (中略)...(3G/A/G/F_DBC_B(3CEG|(3F2C2_B2A4|"}
このデータセットを使ってContinued Pre-trainingではひたすら次の文字(すなわち音符)を予測する自己教師あり学習を繰り返していきます。このモデルを使うことで、入力データ(フレーズ)を与えればチャーリーパーカーの次のフレーズを延々と生成することができます。今回のカスタムモデルでできた生成モデルを勝手にGen Parkerと呼ぶことにしましょう。
Fine-tuning
もう一つ、Fine-tuningのデータセットも作ってみましょう。
先ほどのContinued Pre-trainingのタスクは、時系列に従って次のフレーズを出力していくようにできています。これは一見、実際の演奏の過程と同じように思えます。しかし、それは違います 。実は、演奏者は未来を知りながら演奏しています。
まず、第1にジャズは曲単位の楽譜にしたがって演奏されることが多いです。即興演奏の際もコード進行と呼ばれる和音の構成が示されているので、プレイヤーは未来(例えば2小節先)のコードを見据えて今のフレーズを演奏しています。
第2に、西洋音楽には一定のフォーマット・お作法があります。その曲のコード進行を知らなくても、Dm7 (レファラド) → G7 (ソシレファ) と耳で聞いたら、次はほぼ間違いなくCmaj7 (ドミソシ)に解決します。演奏しながらある程度の先読みができます。
第3に、即興演奏はコード進行に厳密に沿わなくてもかまいません。別のコードに勝手に変えて(解釈して)演奏することは日常茶飯事です。つまり理想の未来を勝手に決めてフレーズを演奏しています。ちなみに、パーカーはそういった演奏の名手でもあります。
このように、様々なレベルで演奏家は未来を想定して演奏しています。これを学習に取り入れるために、未来の先の情報を使って今のフレーズを予測(生成)する教師ありデータセットを作ります。

2小節目を現在と考えて、1.過去のコードとフレーズ、2.現在のコード、3.未来のコードとフレーズ、すなわち3つの赤枠の情報が与えられたときに、現在のフレーズ(青枠)を予測するタスクを設定します。
これを以下のようなフォーマットで表現しました。
{"prompt": "|F|Cm|,|(3G/A/G/FDBC_BA/C/_E/G/|,|F7|,|G_EC_BA_G/F/E=E|", "completion": "|dcdcz2z(3d/c/_B/|"}
"prompt"の中身の表現方法は完全に任意性があります。今回は私が勝手に
|1小節目のコード|2小節目のコード|,|1小節目のフレーズ|,|3小節目のコード|,|3小節目のフレーズ|
という構成にしていますが、この表現形式が最良である保証はありません。
completionは2小節目のフレーズの正解フレーズ(教師データ)になります。音楽に正解はない、つまり2小節目に絶対にこれを演奏しなければならない理由は(音楽の自由さにおいて)ないのですが、その前後の小節のコード進行やフレーズを勘案する限り、このフレーズが演奏される確率はランダムな音列より当然高いと考えられます。これを教師あり学習を学習する妥当性としています。
♬ 実際に演奏を聞いてみよう ♬
さて、学習や推論でも紆余曲折あり書きたいことは山ほどあるのですが、すでにこの記事がク○長い状態になってしまっているのでさっさと実際の生成フレーズを聞いてみましょう。
Continued Pre-training
入力プロンプトで与えられたフレーズから延々と新しいフレーズを生成していきます。原曲ではチャーリーパーカーがサックスでアドリブを吹いてからピアノにソロを回すタイミングなのですが、そこを(ピアノに回さずに)延々と拭き続けたらどうなる?という問題設定にしました。こんな感じになりました。
自分の番が終わったのに延々と吹き続ける(AI)チャーリーパーカーくん pic.twitter.com/cJ3M5l1aR5
— おばけ👻 (@triwave33) December 5, 2023
上の動画では98小節目、時間では12秒目からGen Parkerの生成フレーズが始まります。コードの指示もないので完全にフリースタイルでのプレイだと思ってください。演奏の開始から即興演奏の開始までのフレーズはプロンプトで全て与えてあります。それを受けてのフリースタイルプレイです。
同じフレーズの繰り返し(98 & 100小節)がありますね。また入力プロンプトで与えられた過去のフレーズの再利用(106)もあります。大丈夫か?とおもっていたら113小節目からは完全に無我の境地に入ってしまっています。その後持ち直した?と思ったら、再び意識を宇宙に運んでのプレーが続きます。
個人的には非常におもしろいのですが、高尚すぎるというか、大衆音楽の枠にはめ込める気がしないです。これは音列の続きを生成するだけで周辺のコードや前後とのフレーズの関係性を学習しきれてないのが原因かもしれません。。もっとも、単純に学習を追い込めきれていないのもあると思います。謎のフレーズではあるにしろ、緩急やフレーズの繋がりを感じる箇所はいくつもあり、改善に期待が持てます。もう少しデータとパラメータを詰めれば変わるかもしれません。
Continued Pre-trainingはこれくらいにして、特定のタスク(真ん中の小節のフレーズを作る)に特化した場合はどうでしょうか。Fine-tuningの生成例に進みましょう。
Fine-tuning
前述の通りこちらは3小節単位でのデータとなります。1,3小節目が与えられた時の2小節目のフレーズを生成しています。真ん中の小節の仕上がりと前後のつながりを評価してください。
ではまず生成事例を。
— おばけ👻 (@triwave33) December 14, 2023
1小節目はconfirmationのテーマの出だしを吹き、2小節目からは好きなフレーズを弾く。ジャズでいう"フェイク"の形になっています。後ろの3小節目のフレーズとのつながりは悪いですが、2小節目のコードの構成音にそったE♭やA#といった音列を使っており、曲の展開にあったメロディになってますね。
念のため繰り返しになりますが、2小節目だけを生成(予測)していることに注意してください。
では次
— おばけ👻 (@triwave33) December 14, 2023
ジェットコースターに沿って音列で埋めるようなパッセージです。Gmの構成音(ソ シ♭ レ)に沿ったフレーズが続きます。C7らしい音使いとは言えないですが、次の解決のFに向かって吹き切る、という意思が感じられます。ジグザグに下降するのもパーカーがよく使いますね。C7で小節の最後まで吹き切って、半拍(息継ぎに)置いて次のフレーズに入る。理論どうこうよりも聴感上気持ちいいです。じゃあ次
— おばけ👻 (@triwave33) December 14, 2023
これは大好きですね。3小節でギア上げるぞ、ってのが事前にわかってるので2小節目の冒頭はタメて、最後の一拍でアクセル踏み込んで次の小節に繋げています。3小節目頭のF(ファ)をターゲットとして頭にいれつつ、そこに向けて半音ずつ下げてFに着地させてます。これもパーカーらしいですね。
ちなみに、この生成音源が打ち込みで機械的すぎて本物に遠く及ばない、という正論ご意見はなしでお願いします。そもそも演奏のニュアンスを離散化された情報(楽譜)に落とし込むのが不可能なので。。これをパーカーが実際に演奏したらどうなるのか?それっぽいか?という想像を膨らませて聞いてください。
もちろんうまくいった例ばかりではありません。失敗例もいくつか。
— おばけ👻 (@triwave33) December 14, 2023
前のフレーズをそのまま繰り返しています。同じフレーズを意志を持って繰り返すことは悪いことではないとは思うのですが、この場合はあんまり面白味がないですね。コードに沿って音形は同じなのに音程を変えてくれる、とか一工夫があったら面白かったですね。
失敗例をお見せしたお詫びに、同じフレーズを偏執的に繰り返す名演のリンクを貼っておきます。ご査収ください。 (1, 2)
では最後
— おばけ👻 (@triwave33) December 14, 2023
なんか遥か昔のファミコン(ファミリーコンピューター)の音源みたいな感じですねぇ。同時発音数が制限されていたので高速にアルペジオ(分散和音)を繰り返してコードを弾いてた時代。多分3小節目に6連符が出てきたから力入っちゃったんでしょうねぇ笑。かわいいぞGen Parkerくん。ただし途中でB♭からB♮に変えたのはG7の構成音に追随していて評価できます。速すぎて聴いてもわかんねぇけど。
考察
Amazon Bedrockではモデルや学習に関わる詳細、例えばtokenizerについては公開されていません。また、カスタマイズすることもできません。今回は音楽データをむりやり英語の学習の枠組みに当てはめましたが、それがBedrockの学習に適していたのかは残念ながらはっきりとはしません。自前での学習結果と比較する必要があります。
今回のような特定の(特に言語と関係ない)ドメインの場合、そもそも"Continued" Pre-trainingを使う必要はあるのでしょうかか?つまり「よろずの文章を事前知識として学習させておく意味があるのか?」「音楽データだけで0から始めれば良いのではないか?」ということです。私の見解はYesでもありNoでもあります。
Yesと答えた理由ですが、一人のミュージシャンの音楽フレーズを理解し、生成するのに膨大なパラメータと大量の(音楽に関係のない)テキストデータは不要かもしれません。特に音楽の即興演奏で求められるような即時性、インタラクティブ性を追求すると、もっと軽量なモデルをエッジで推論させるべきかもしれません。例えばTinyLlamaを使ったエッジ推論は今後追求したいですが、今回のアドベントカレンダーの趣旨とは反するので、記事中には言及しませんでした。
その一方で音楽生成に関しても、汎用的な言語モデルから出発してContinued pre-training/Fine-tuningすることは有効と感じました。理由はプロンプトエンジニアリングの観点です。今回詳しく説明しませんでしたが、プロンプト(Instruction)が生成されるフレーズのクオリティに大きく影響しました。具体的にはFew shotでのexampleの提示、ABC記法の説明、期待する出力の注文(与えられたフレーズを単純に模倣しない、音楽に関係ない出力はしない、4/4拍子を厳密に守る、など)です。学習だけで所望の出力が完璧に得られることは個人的にはあり得ないと個人的に感じるので、モデルの学習後に出力を自然言語で調整する余地は必要であると思いました。
おわりに
Amazon Bedrockでモデルのカスタマイズをおこないました。Continued Pre-training、Fine-tuningいずれも、Amazon Bedrockではデータを所定のフォーマットに用意できれば、マウスだけで簡単に学習ジョブ実行することができます。みなさまも思いついたアイデアをぜひAmazon Bedrockで形にしてみてください!