https://notebooklm.google.com/
こっちのがいい説あります笑 @2024/06/08
DIFYは、チャットボットを簡単に作成できるプラットフォームです。本記事では、DIFYを使って独自知識を持ったチャットボットを構築する方法を解説します。
- pdfからテキストを抽出する
- URLからテキストを抽出する
特定知識の応答
このアプリケーションの最大の特徴は、「KNOWLEDGE」という変数に注目すべき点です。ユーザーはここに、モデルが参照すべき知識ベースを記述することができます。これは、Retrieval Augmented Generation (RAG)のようにモデルの応答を特定の知識に根ざしたものにすることを示唆しています。
設定ファイル内の pre-prompt は、モデルに対して、提供された知識ベースを最大限に活用し、正確で関連性の高い回答を生成するよう指示しています。ユーザーが入力した質問に対して、モデルは知識ベースの中から関連する情報を抽出し、それを基に回答を生成します。
モデル
gemini-1.5-pro-latest
Variables
KNOWLEDGE
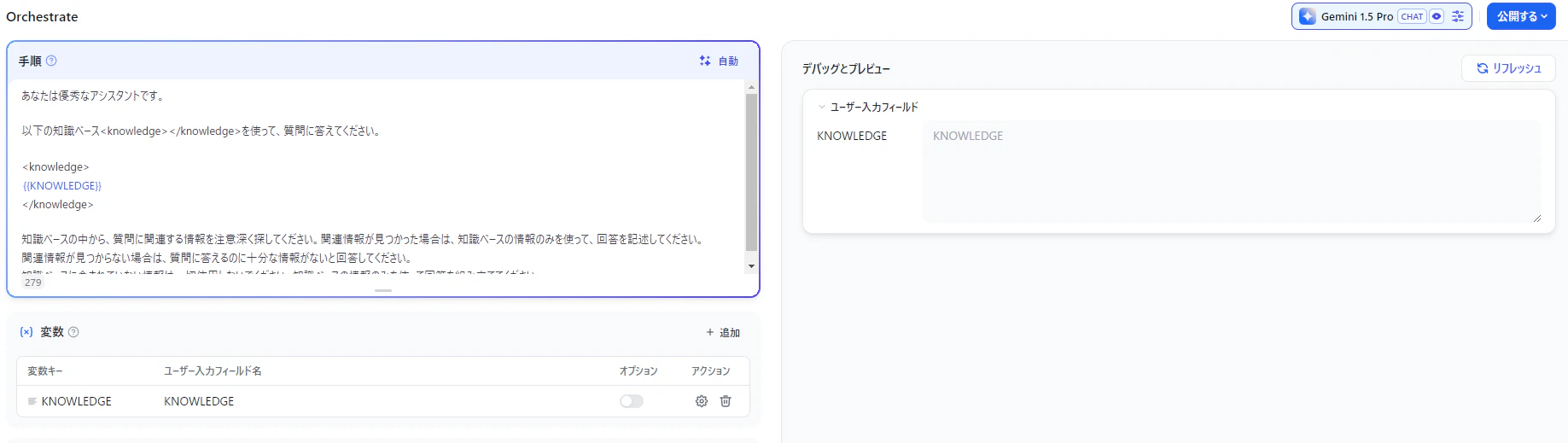
ユーザー入力フィールドに、ナレッジを平文でべた張りして下さい。
Instructions
あなたは優秀なアシスタントです。
以下の知識ベース<knowledge></knowledge>を使って、質問に答えてください。
<knowledge>
{{KNOWLEDGE}}
</knowledge>
知識ベースの中から、質問に関連する情報を注意深く探してください。関連情報が見つかった場合は、知識ベースの情報のみを使って、回答を記述してください。
関連情報が見つからない場合は、質問に答えるのに十分な情報がないと回答してください。
知識ベースに含まれていない情報は一切使用しないでください。知識ベースの情報のみを使って回答を組み立ててください。
おまけ:colab用
!pip install langchain
!pip install langchain_community
!pip install gradio
import gradio as gr
from langchain.document_loaders import UnstructuredPDFLoader, WebBaseLoader
def process_input(url, file):
"""
PDFファイルまたはURLを受け取り、その内容をテキストとして取得する関数。
Parameters:
- url: 入力されたURL
- file: アップロードされたPDFファイル
Returns:
- PDFファイルまたはURLのテキスト内容
Raises:
- gr.Error: PDFまたはURLの読み込みに失敗した場合のエラー
"""
try:
if url:
# URLが入力されている場合
loader = WebBaseLoader(url)
data = loader.load()
return data[0].page_content
elif file:
# PDFファイルがアップロードされている場合
loader = UnstructuredPDFLoader(file)
data = loader.load()
return data[0].page_content
else:
# 入力がない場合
return "URLまたはPDFファイルを入力してください。"
except Exception as e:
raise gr.Error(str(e))
def main():
# Gradioインターフェースの作成
iface = gr.Interface(
fn=process_input,
inputs=[
gr.Textbox(label="URL", placeholder="URLを入力してください"),
gr.File(label="PDFファイルをアップロード", file_types=[".pdf"])
],
outputs=gr.Textbox(label="ファイルの内容", show_copy_button=True),
title="tregu0458/pdf_2_text_converter",
description="PDFファイルまたはURLを入力すると、その内容がテキストとして表示されます。"
)
# インターフェースの起動
iface.launch()
if __name__ == "__main__":
main()
上記のテキストはクリエイティブ・コモンズ 表示-継承ライセンスのもとで利用できます。