背景
機械学習で学習・推論を行うに当たり、AWS SageMakerを利用しています。
今回は独自モデルを利用して バッチ推論を実施する際 にハマったお話で、扱っているデータは画像です。
※本来、学習→推論の流れになりますが、学習を割愛しているため若干記事として読みにくいかもしれません。
推論とは
作成したモデルを利用して、元となるデータから予測される結果を出力することを「推論」と記載しています。
AWS SageMakerでの推論方法は主に下記の2パターンあります。
- リアルタイム推論
- バッチ推論
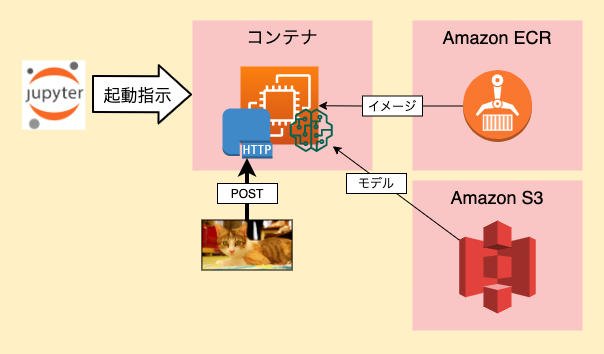
リアルタイム推論
リアルタイム推論はイメージしやすいです。
リアルタイム推論の流れ
- Estimatorインスタンスを生成し、deployメソッドを呼び出す
- 指定したモデルを包含したHTTPエンドポイントが起動される
-
docker run image serveでコンテナ起動 - モデルはEstimatorインスタンス生成時の引数で指定
- ECRに登録済みのコンテナを起動し、HTTPエンドポイントを設定
- /invocationsと/pingを定義しておく
- /pingは200を返せば良いが、監視としても利用できる
-
- /invocationsに推論元データをPOSTして推論結果を出力させる
- 推論結果はHTTPレスポンスとして返却
- 停止指示しない限り、エンドポイントは起動したまま
推論時のイメージ
参考URL
バッチ推論
本題です。
自分が元々想像していたのは、以下のような流れでした。
- 指定したモデルを包含したバッチジョブ(スクリプト)を定義
- S3上の推論元データが逐次スクリプトに渡され、指定出力先にアウトプット
- 推論元のデータを全て処理し終わったら完了
そもそも「バッチジョブ(スクリプト)を定義」の時点で違いました。
やっていることはほとんどリアルタイム推論(上の「推論時のイメージ」)と同様で、違いとしては 「推論実施までの流れ」 と 「コンテナの挙動」 です。
バッチ推論の流れ
- boto3のSageMakerインスタンスを生成し、create_transform_job()で呼び出し
- create_transform_job()は非同期で実行される
- (内部的に)指定したモデルを包含したHTTPエンドポイントが起動される
-
docker run image serveでコンテナ起動 - モデルはcreate_transform_job()に渡すjson引数に定義
- S3上のINPUT/OUTPUTもこの引数内で指定する
- (どういう風に渡されるのかドキュメントから読み取れない...)
- ECRに登録済みのコンテナを起動し、HTTPエンドポイントを設定
- /invocationsと/pingを定義しておく
- /pingは200を返せば良いが、監視としても利用できる
-
- /invocationsにINPUTとして指定したS3パスのファイル群が、一つずつPOSTされる
- 推論結果はHTTPレスポンスとして返却
- 返却内容は、OUTPUTに指定したS3に「INPUTに与えられたファイル名.out」としてupされる
- S3のファイル群を処理し終わったらコンテナ停止
参考URL
所感
個人的にSageMakerのバッチ推論は 「理解し辛いのでは」 、、というのが所感です。
- 「バッチ」という名前と挙動に大きな剥離がある
- 自分が勝手に想像していたイメージではあるものの...
- 学習時の作業ともかなり異なる
- 学習時はS3のパスとコンテナ内のパスを紐付けながらの作業
- 推論時もS3のデータをコンテナ内にコピーできそうだが、できない
また、下記の「まだ分かっていないところ」も含めて、利用シーンが想定できていません。
まだ分かっていないところ
- 通常運用だとjupyter notebookを介して呼び出せない
- リアルタイム推論はエンドポイントが起動したままなので扱いやすい
- バッチ推論はどう呼び出すのが適切?
- 何度か試している限りコンテナの起動に4分くらいかかる
- 毎回4分かかっていたらさすがに使い勝手が良くない
- 高速化する方法はないものか
最後に
もちろん、以下の利点もあります!
- リアルタイム推論とバッチ推論で共通のIFにできる
- バッチ推論は処理が終わったらコンテナも停止される
- 無駄なコストを節約できる
その他、自分の理解が追いついてないところも多々あるかもしれません。
調べていく内に、もっと良い利用方法が見つかったら改めて記事にしたいなと思います。