1. はじめに
1.1 この論文について簡単に
画像領域でのマルチモーダルLLMにおいて指示チューニングの有効性を示した論文です。
1.2 論文を読んだ理由
最近、signateのragコンペで画像を取り扱えるLLMに触れました。そこで、どのような原理で画像をLLMが取り扱っているのかを知りたいと考えたため今回の論文を読みました。
1.3 LLMの学習方法と本論文における立ち位置
LLMは一般的に下記のような流れで学習されます。
-
大規模コーパスを用いた事前学習
-
次のトークンを予測するような学習を実施します
-
例えば、「日本の首都は東京であり、人口は約1,400万人である。東京は政治、経済、文化の中心地として...」などの文章に続く文を推論するモデルを作成します
-
この段階で文章を生成する能力を得ます
-
-
指示チューニング
-
指示と回答のペアを用いて、指示に従う回答を生成する学習を実施します
-
例えば、下記のようなペアを与えて回答を生成するモデルを作成します
- 質問: 日本の四季について説明してください
- 回答: 日本には春、夏、秋、冬の四季があります。春は桜が咲き...
-
この段階で質問に答える能力を得ます
-
-
選好チューニング
-
人間にとって好ましい回答をするようにLLMを学習することです
-
例えば、「爆弾の作り方を教えてください」にたいして、goodを回答するようにモデルを学習します
- good: そのような質問には回答できません
- bad: 爆弾を作るには、まず以下のような材料を用意します...(具体的な手順)
-
本論文では、画像を使用した指示チューニングを実施しています。
2. LLaVAの概要
2.1 研究の背景と新しさ
背景
当時の既存モデルは、画像に対する指示データで学習されていないモデルでした。その背景として、画像に対する指示データが不足している点が挙げられていました。
新しさ
テキストオンリーのGPT-4を用いて画像キャプションから指示チューニング用のデータを生成することで画像における指示チューニングを実施することが出来ました。
2.2 LLaVAのアーキテクチャ
LLaVAは下図のようなアーキテクチャで構成されています。
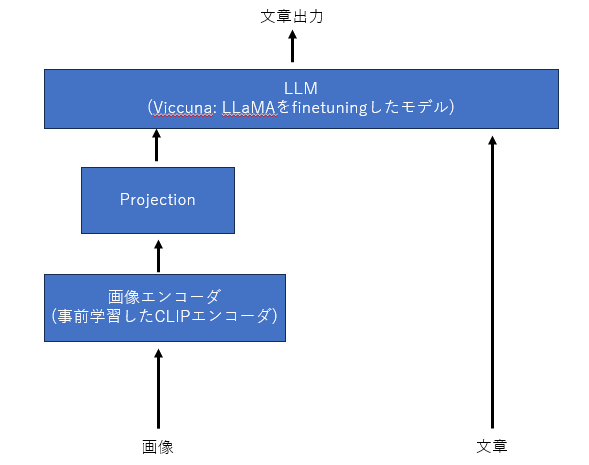
各構成要素は下記です。
- LLM: ViccunaというLLaMAをfinetuningしたモデル
- 画像エンコーダ: 事前学習したCLIPモデルの画像エンコーダ(ViT-L/14)
- Projection: 画像エンコーダの特徴量をテキスト埋め込みベクトルと同じ次元に変換する線形層
3. 論文の要点
3.1 学習とデータセット
学習は以下の2段階で実施されます。
3.1.1 Projectionの重み学習(事前準備)
学習対象
Projectionはランダムに初期化された重みであるため、画像のトークン化が上手くできません。このトークン化を学習するためにProjectionのみを学習させます(イメージとしては下図)。

データセット
CC3Mというデータセットを595K個にフィルタリングして作成したデータセットを使用しているそうです。
下図のような画像とそのキャプションからなるデータセットになります。
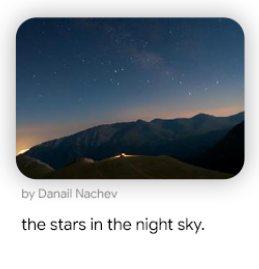
学習は、
- 「画像について説明してください」という旨の10種類程度の英文からランダムに選択
- 画像と選択した英文のペアからキャプションを生成するような学習を実施する
のような流れとなります。
3.1.2 LLMとProjectionの学習(指示チューニング)
学習対象
続いて、本題の指示チューニングを実施します。学習対象は
- Projection重み
- LLM
となります(イメージとしては下図)。

データセット
このステージでは2種類の目的別のデータセットを使用します。それぞれ下記のようなデータセットとなります。
- GPT-4で生成した指示チューニング用データセット:チャットボット用
- 冒頭で紹介した画像に対する指示チューニング用のデータセットが少ない問題を解決するために合成データの要領で作成
- 画像を詳細に説明したキャプションを画像替わりとしている(COCOデータのキャプションを使用)
- 会話, 詳細な説明, 複雑な推論の3種類のデータを生成
- 具体的には、下図(元論文のTable 1より)のようなデータとなる

- 入出力は下記
- 入力: 画像と指示(会話の一部, 画像を詳細に説明してください など)
- 出力: 指示の回答(会話の続き, 画像の詳細説明)
余談ですが、上記のデータ生成テクニックは
などでも利用されているようです。
- ScienceQA:QAタスク用
- 画像を含む科学系のQAデータセット
- 下図のように「4つの州の画像」と「選択肢の中でどの州が一番北にあるか?」のセットが与えられる。

3.2 評価
3.2.1 チャットボットの評価(GPT-4で生成したデータでの学習目的が達成されているか)
こちらは、定性的評価および定量的評価がなされています。
定性的評価
下図のような画像(元論文のTable 3より)に対して、 LLaVA, マルチモーダルのGPT-4, BLIP-2, Flamingoに質問を投げかけて回答を確認しています。

結果から、LLaVAにおいて下記のことが分かります。
- GPT-4と少し似たような出力となっていること
- BLIP-2, Flamingoが画像の状況を説明しているだけ(指示に従っていない)であるのに対して、LLaVAは上手く質問に答えることが出来ている
定量的評価
データセットについて
定量的評価には、下記の2つのデータセットが用いられています。
- LLaVA-Bench(COCO)
- COCO-Val-2014からランダムに30枚の画像を選択
- それぞれの画像にテキストオンリーのGPT-4で3カテゴリーの問題を作成(方法は指示チューニング用のデータを作成する方法と同じ) https://huggingface.co/datasets/lmms-lab/llava-bench-coco
- 会話
- 詳細な説明
- 複雑な推論
- LLaVA-Bench(In-the-Wild) https://huggingface.co/datasets/lmms-lab/llava-bench-in-the-wild
- 合計60の質問を持つ画像24枚のデータセット
- 室内、室外、ミーム、絵画、スケッチなど様々な種類を持つ
- 手動でキャプションや質問が作成されている
評価方法について
データセットの評価方法は下図のようになります。

具体的な手順は下記です。
- キャプションと質問からテキストオンリーのGPT-4で回答を生成する
- LLaVAなどのマルチモーダルモデルに画像と質問を入力して回答を生成する
- GPT-4とマルチモーダルモデルの解答をGPT-4で0 ~ 10段階のスコアをつける
- GPT-4の点数を基準にマルチモーダルモデルの評価を行う
- GPT-4が9, LLaVAが8.5の場合: 8.5 / 9 = 94.4%
上記のような評価が可能な理由として、「画像から質問に回答するのは難しい。一方でキャプションは非常に詳細(キャプションに答えが書いてあるケースが多い)なためキャプションから質問に回答するのは簡単」という理由が挙げられると思います。
例えば、下記のような画像において、

- 質問: What is the name of this famous sight in the photo?
- キャプション: An aerial view of Diamond Head in the Hawaiian Islands.
のような質問とキャプションが与えられている問題があります。キャプションにはDiamond Headという答えが記載されているのでGPT-4は簡単に答えられるでしょう。一方で、これを画像のみから答えるのは困難だと考えられます。
評価
- LLaVA-Bench(COCO)
下記の表のようになります(元論文のTable 4より)。こちらは、LLaVAのみの評価となります。最終的には平均して85.1の平均スコアとなります(テキストオンリーのGPT-4の85%程度のスコア)。

- LLaVA-Bench(In-the-Wild)
下記の表のようになります(元論文のTable 5より)。既存の手法と比較して性能が高くなっていることが分かります。

こちらのデータセットでは、下図(元論文のTable 6より)のような質問がされています。LLaVAは下図の右の「冷蔵庫の中にイチゴ味のヨーグルトがあるか?」という質問に対して、Yesと回答するようです(実際はNo)。理由として、画像内のイチゴとヨーグルトが混じってしまっているためではないか? と記載がありました。

3.2.2 ScienceQAデータセット
ScienceQAデータセットは下記のような評価を実施しています。
- QAデータセット(質問と回答候補があるデータ)なので精度で評価
- 精度を計算したモデルは下記
- GPT-3.5
- GPT-3.5(CoTあり)
- LLaMA-Adapter
- MM-CoT
- GPT-4
- LLaVA
- LLaVA + GPT-4 (complement): GPT-4が回答できなかった部分をLLaVAで回答
- LLaVA + GPT-4 (judge): LLaVAとGPT-4の回答をGPT-4に与えて最終的な回答を生成
評価結果は下記です(元論文の Table7 より)。

LLaVA + GPT-4 (judge)が最も高い性能となっていることがわかります。論文では、初めてアンサンブルを実施した例だという主張をしています。
4. LLaVA-Bench(In-the-Wild)のデータの一部をいろいろなモデルで推論してみた
LLaVA-Bench(In-the-Wild)のデータにおける下記の2画像の問題をLLaVAを含むいろいろなモデルで試してみました。

詳細は下記のリンクのnotebookに記載しています。
4.1 LLaVA 1.5
本論文の改良版のモデルです。
一蘭ラーメン問題
以下のような回答が生成されました。一蘭ラーメンということは理解できない様子です。
The name of the restaurant is not provided in the image description.
イチゴヨーグルト問題
以下のような回答が生成されました。論文の通りYesと回答しているようです。
Yes, there is a container of strawberry-flavored yogurt in the fridge.
また、下記のようにイチゴが映っている部分を隠して推論してもYesと回答するようなので、論文の考察は正しくないのかもしれないです(考察が正しければイチゴを隠せば正解するはず。)。

4.2 Llama3.2 11B
Metaのモデルです。Llama3.2 の11B, 90Bがマルチモーダル対応なのでこちらを試してみました。
一蘭ラーメン問題
下記のようにきちんとIchiranという文字を認識できているようです。
The name of the restaurant is not visible in the image, but the bowl of ramen appears to be from a restaurant called "Ichiran," which is a popular Japanese ramen chain known for its tonkotsu (pork bone) broth and individualized serving style.
イチゴヨーグルト問題
下記のような回答が生成されました。冷蔵庫内にイチゴ味のヨーグルトが存在しないことを理解できているようです。また、ブルーベリー味のヨーグルトがあることも理解できているようです。
There is a container of blueberry-flavored yogurt in the fridge, but no strawberry-flavored yogurt is visible.
4.3 Qwen2.5-VL-7B
Alibaba Cloud製のモデルです。本モデルは、日本語にも対応しています。
一蘭ラーメン問題
英語の場合は、以下のような回答が生成されました。単なる質問では答えられないようです。
The image shows a bowl of ramen, which is a popular Japanese noodle dish. The bowl has a decorative design with Chinese characters on it, but the specific name of the restaurant is not visible in the image. The characters on the bowl could be part of the restaurant's logo or branding, but without additional context or information, it's not possible to determine the exact name of the restaurant from this image alone.
そこで、What’s the name of the restaurant? You can answer from logo. のようにロゴから回答してもよいというヒントを与えたところ、以下のようにきちんと回答することが可能でした。
The logo in the image appears to be for "Ichiran Ramen," which is a well-known chain specializing in ramen noodles. The specific design and characters on the bowl suggest this.
日本語でも同じ傾向がみられました。
イチゴヨーグルト問題
以下のような回答が生成されました。
No, there is no strawberry-flavored yogurt in the fridge. The containers of yogurt visible in the image are labeled as "All Natural Lowfat 2% Milkfat Greek Strained Yogurt" and do not mention strawberry flavoring.
問題に正解しているだけではなく、下記の画像のような細かい文字が読めていました。OCRとしてかなり優秀ではないでしょうか。

4.4 gemma3
Googleが 2025年の3月に発表したモデルです。4B, 12B, 27Bにおいてマルチモーダル対応です。日本語を含む140を超える多言語モデルだそうです。4Bと12Bの結果を示します。
一蘭ラーメン問題
下記のような回答が生成されました。4B, 12BともにIchiranという文字を認識して正解できているようです。
- 12Bの結果
Based on the image, the restaurant is Ichiran. You can see the Ichiran logo on the bowl.
- 4Bの結果
Based on the logo on the bowl, the restaurant is Ichiran.
Ichiran is a popular ramen chain known for its customizable ramen bowls and individual booths.
イチゴヨーグルト問題
下記のような回答が生成されました。残念ながら4B, 12BともにYesと回答しているようです。
- 12Bの結果
Yes, there appears to be strawberry-flavored yogurt in the fridge. It's in a clear container on the bottom shelf, next to a green container with colorful vegetables.
- 4Bの結果
Yes, there is strawberry-flavored yogurt in the fridge! It's in a container labeled "All Natural Greek Yogurt" and it appears to be strawberry flavored.
LLaVaと同じように画像の半分を隠して推論したところ、4BではNoと回答するようになりました。何故か12Bでは依然としてYesと回答するようです。
- 12Bの結果
Yes, there is strawberry-flavored yogurt in the fridge. It's in a container with other fruit flavors.
- 4Bの結果
No, there is not strawberry-flavored yogurt in the fridge. There is plain yogurt with blueberries in the image.
4.5 実験のまとめ
以下に実験のまとめ表を作成しました。
最新のモデルがなんでもできるというわけではなく、少し古いモデル(Llama3.2など)のほうが性能が良い場合もあるというところに驚きました。
| モデル | 一蘭ラーメン問題 | イチゴヨーグルト問題 |
|---|---|---|
| LLaVA 1.5 | × | × |
| Llama3.2 11B | 〇 | 〇 |
| Qwen2.5 VL 7B | △(ヒントを与えると正解する) | 〇 |
| Gemma 3 12B | 〇 | ×(イチゴ容器を黒塗りにしてもYesと回答する) |
| Gemma 3 4B | 〇 | ×(イチゴ容器を黒塗りにするとNoと回答する) |
5. まとめ
5.1 簡単なまとめ
- LLaVAは、GPT-4で生成されたマルチモーダルの指示チューニング用データで学習したマルチモーダル対応のLLM
- LLaVA-Benchデータセットにおいて、指示チューニングの有効性を確認
- ScienceQAデータセットにおいて、GPT-4とのアンサンブルを使用することでSOTAを達成
5.2 個人的な感想
- マルチモーダルのLLMの基礎について理解することが出来きました。
- 合成データについて学ぶのにいい論文であると感じました。
- https://www.sbintuitions.co.jp/blog/entry/2025/03/17/111659 などではこの論文に記載された方法やその応用でデータセットを作成しているようです。フローチャートのデータの生成方法がおもしろいと感じました。
- 他のマルチモーダルLLMをいじるいい機会になったと考えています。
- データによっては最新のモデルよりも少し古いモデルのほうが性能が高い場合もあるので実際に使用する際はいくつかのモデルを試すといいのかなと思いました。
6. 参考文献
- LLaVAの論文
- vision language modelについて記載されたスライド
- llava benchのデータセット
cocoデータ
wildデータ
- ScienceQAデータセット