データの取得・構造把握
今回使用するデータは、The UC Irvine Machine Learning Repository(以下UCI)にある映画データベースです。
UCIは、468のデータセットを公開されており、学術利用が可能です。
利用したデータベースは、2014、2015年のソーシャルメディア(Twitter,YouTube,IMDB)から取得された映画情報に関する232行14列のデータベースで、1行は映画の属性を表し、1列目に記載された映画を12のカラムで分類しています。
各変数の意味と取りうる値
Movie:映画のタイトル,character,長さ20
Year:年,実数,numeric
Ratings :評価,実数, numeric
Genre:ジャンル,1がアクション。カテゴリマスタが今回与えられていない。カテゴリカルデータ
Budget:予算,実数, numeric,単位ドル
Screens:上映された映画館の数,実数, numeric
Sequel;続編の有無。続編が何番目の作品か,実数, numeric
Views:映画を観た人数,実数, numeric
Likes:Youtubeでlikeした人数,実数, numeric
Dislikes:YoutubeでDislikeした人数,実数, numeric
Comments:コメントの数,実数, numeric
Aggregate Followers:フォロワーの数,実数, numeric
分析目的
映画の評価を決める要因を分析する。
2018年に「カメラをとめるな」という映画が注目された。
その理由は、作成予算が低いのに人気が高かったからである。
なぜ、「カメラをとめるな」は人気が出たのか気になり、今回映画の評価を決定する要因を分析することとした。
データ入力
映画データをdataステップで読み込む。
/* 映画データの読み込み */
data mylib.movie;
infile "&filepath\movie.csv" dsd dlm=',' firstobs=2;
input Movie :$20.
Year
Ratings
Genre
Gross
Budget
Screens
Sequel
Sentiment
Views
Likes
Dislikes
Comments
Aggregate_Followers;
run;
上記のコードを実行すると以下の写真のように読み込める.
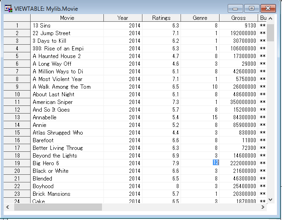
→綺麗に読み込めている.
使わない変数があるので、削除が必要である。
また、ところどころ欠損値がみられる。
クリーニングが必要である。
データクリーニング
Gross、sentiment、Movie year Aggregate_Follower,Genreの列を削除して、削除したデータをmovie_dropとして保存する。
→Gross、sentimentはデータとして理解ができなかったので削除した。
Movieは映画のタイトルであるが、今回の目的にはcharacter型であるため使えないと判断し削除した。
Aggregate_Followersは35行データが欠損しているので削除する。
そのため、残った10変数で分析を進める。
/* variableを削除する */
/* Dropステートメント */
data mylib.movie_drop;
drop Gross Sentiment Movie Aggregate_Followers Year;
set mylib.movie;
run;
上記のコードを実行すると次のようになる.
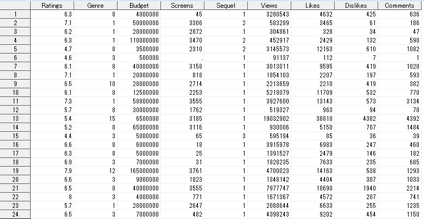
Ratain,Genru,Buget,Screenなど必要な変数のみのデータができた.
図1と比べ、Gross、sentiment、Movie 、year、 Aggregate_Followes,Genreが削除されている。
集計
1変量の集計
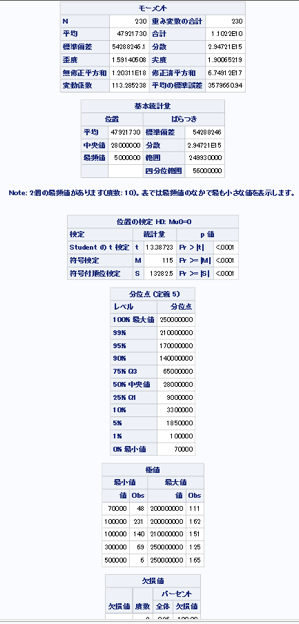
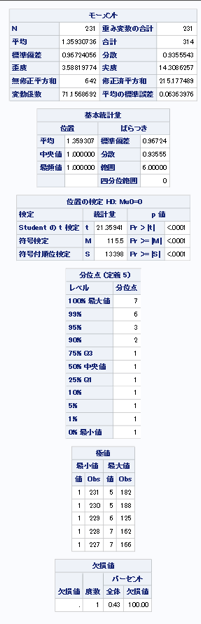
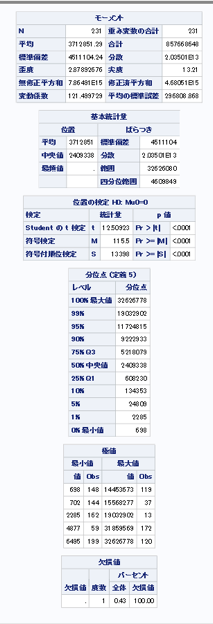
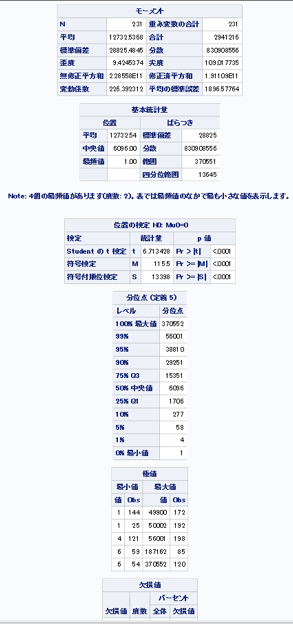
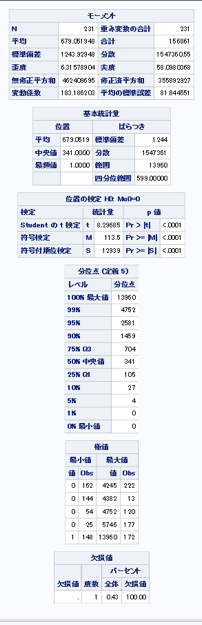
→各変数の基本統計量を「proc means」 と「proc univariat」を用いて調べる。
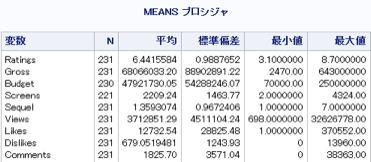
/*proc meansを用いた方法*/
proc means data = mylib.movie;
var Ratings Gross Budget Screens Sequel Views Likes Dislikes Comments ;
output out=mylib.movie_rating_syukei;
run;
/*proc univariateを用いた方法*/
proc univariate data = mylib.movie;
var Ratings;
run;
proc univariate data = mylib.movie;
var Budget;
run;
proc univariate data = mylib.movie;
var Sequel;
run;
proc univariate data = mylib.movie;
var Views;
run;
proc univariate data = mylib.movie;
var Likes;
run;
proc univariate data = mylib.movie;
var Dislikes;
run;
proc univariate data = mylib.movie;
var Comments;
run;
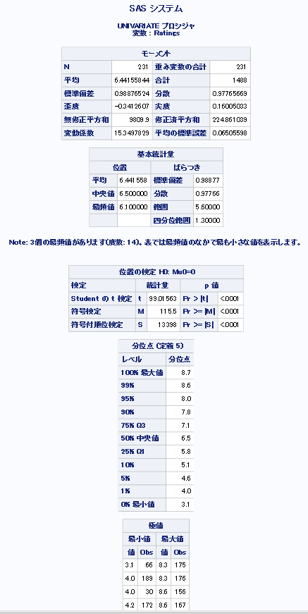
2変量の集計
/*2変量の基礎集計*/
/*映画の評価と予算の相関を確かめる*/
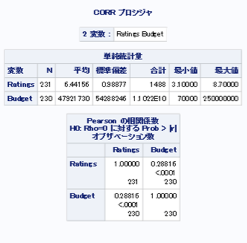
proc corr data = mylib.movie out = mylib.cor_Rating_Budget;
var Ratings Budget;
run;
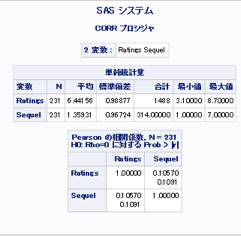
/*映画の評価と続編の相関を確かめる*/
proc corr data = mylib.movie out = mylib.cor_Rating_Sequel;
var Ratings Sequel;
run;
/*映画の評価と観客動員数の相関を確かめる*/
proc corr data = mylib.movie out = mylib.cor_Rating_Views;
var Ratings Views;
run;
/*映画の評価とyoutubeのlikeの数との相関を確かめる*/
proc corr data = mylib.movie out = mylib.cor_Rating_Likes;
var Ratings Likes;
run;
/*映画の評価とyoutubeのdislikeとの相関を確かめる*/
proc corr data = mylib.movie out = mylib.cor_Rating_Dislikes;
var Ratings Dislikes;
run;
/*映画の評価とコメント数の相関を確かめる*/
proc corr data = mylib.movie out = mylib.cor_Rating_Comments;
var Ratings Comments;
run;
評価と予算の相関
評価と続編の相関
→予算に1行欠損値がみられる。欠損している行を削除する必要がある。②に戻ってデータのクリーニングを行う必要がある。
→映画の評価の平均が6.44というのは高いのだろうか?低いのだろうか?ヒストグラムで分布をみる必要がある。
→予算の平均が4800万ドルというのは、つまり、48億円ということである。映画一本作るに莫大な金が必要なことがわかる。一番高い予算で作られた映画は「ホビット」、「アベンジャーズ」だった。自分でもわかる人気映画は高い予算で作成されている傾向がある。
→最も続編数が多いのは7つで、「ワイルドスピード」と「X-men」だった。人気映画は続編がでる傾向にあるのだろうか?次の視覚化で確認したい。
→youtuobeのlikeの数は「The Fault in Our Stars」が最も多かった。
→youtuobeのdislikeの数は「Fifty Shades of Grey」が最も多かった。
→2変量の集計で、評価と予算の相関を調べた。その結果、ピアソン相関係数が0.29と正の相関を得た。つまり、予算が増えると評価が高くなると解釈できる。または、評価が高い映画は予算がかかっている傾向にあるといえる。次に視覚化で散布図をプロットして分布を確認する必要がある。
→2変量の集計で、評価と続編の相関を調べた。その結果、ピアソン相関係数が0.105と正の相関を得た。つまり、続編が多いと評価が高くなると解釈できる。または、評価が高い映画は続編が多い傾向にあるといえる。次に視覚化で散布図をプロットして分布を確認する必要がある。
視覚化
評価と予算の散布図を描く。このとき、観客動員数で色分けする。
proc sgplot data = mylib.movie;
scatter x=Budget y=Ratings/
colorresponse=Views
colormodel=(blue red)
;
/* 必ず横軸縦軸のラベルやメモリ数値の大きさを指定すること */
xaxis valueattrs=(size=15) labelattrs=(size=20);
yaxis valueattrs=(size=15) labelattrs=(size=20);
run;
上記のコードを実行すると以下の結果を得る.
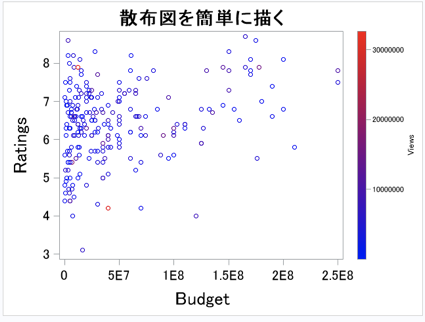
→評価と予算の散布図を描いた。観客動員数が多い映画は、赤色少ない映画は青色になっている。
この散布図から、予算が多い映画は評価が高い傾向にあると言えそうである。
多変量解析
/*************/
/* 重回帰分析 */
/*************/
ods graphics on;
proc reg data = mylib.movie
plots=(diagnostics residuals dffits dfbetas)
;
model Ratings = Budget Screens Sequel Views Likes Dislikes Comments /
influence tol vif collin;
run;
quit;
ods graphics off;
上記のコードの実行結果
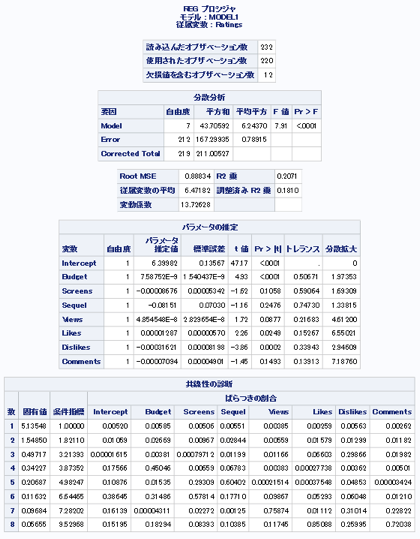
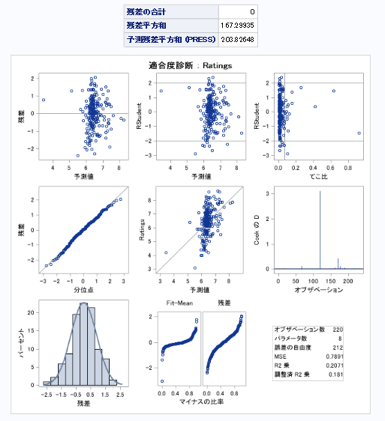
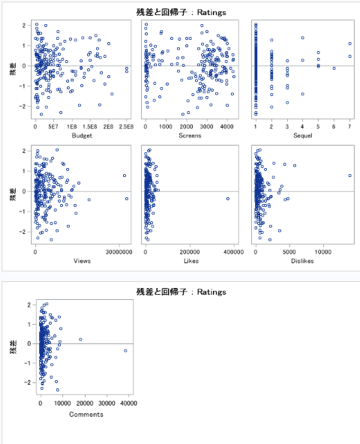
→予算、youtubeのLike・dislikeの数はP値が0.05以下で評価を予測するモデルにおいて有意であるといえる。
→今回の分析で、映画の評価の要因として、予算、youtubeのLike・dislikeの数であると言えそうだ。
→また,モデルの当てはまりも見れたら嬉しかった.