0. 論文
A Survey on Multi-output Learning
2019
1. どんなもの?
近年の多出力学習の研究のサーベイ
2. 先行研究と比べてどこがすごい?
課題がまとめられている.
3. 技術や手法のキモはどこ?
論文による.
4. どうやって有効だと検証した?
データ:
対戦相手:
評価指標:
5. 議論はある?
課題F出力分布の変更:出力分布は時間とともに変化し,概念のドリフトも発生する可能性がある.雨雲の変動を予測する時,出力する分布は夏と冬では異なる.使えるのではないか.
これを共変量シフト適合を用いて解決できないか?
応用の例
https://ieeexplore.ieee.org/abstract/document/5995586
https://www.kaggle.com/c/pkdd-15-predict-taxi-service-trajectory-i
http://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014
https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Nam_Learning_Multi-Domain_Convolutional_CVPR_2016_paper.html
6. 次に読むべき論文は?
ランダム射影や正準相関分析(CCA)ベースの射影[197][198],[199],[200]などの一般的な方法
ノイズの多いラベルを処理する既存の多出力学習方法は,主に2つのグループに分類される.
1つ目:ロバストな損失関数[258]〜[260]を構築します.これらは,損失関数のラベルを変更してノイズ効果を軽減します.
2つ目:潜在ラベルをモデル化し,潜在ラベルからノイズの多いラベルへの遷移を学習します[261] – [263].
出力分布が変化する課題に対処した論文
-
https://www.kaggle.com/c/pkdd-15-predict-taxi-service-trajectory-i
-
http://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014
-
F出力分布の変化とEノイズの多いラベルの組み合わせ[279]・・・欠損値を伴うオンライン時系列予測
画像の出力の論文
-
“Super-resolution image reconstruction: a technical overview[33]・・・低解像度の画像を与えて,高解像度の画像を構築する.
-
Generative Adversarial Text to Image Synthesis[44]・・・自然言語記述から画像を生成する
-
Conditional generative adversarial nets for convolutional face generation[45]・・・顔生成
-
単一ラベル分類器の数が指数関数的に増えるという問題に対してRandom k- Labelsets [210]という拡張
-
Classifier Chains (CC)[206][207]→チェーンの順序が異なると結果が異なるという問題にECC[206],PCC[211] ,CCMC[94]へ拡張
7. メモ
abstract
多出力学習は,入力を与えられた複数の出力を同時に予測することを目的としています.
研究は増加しているが,様々なタイプの課題と課題を克服するために提案された手法に関する包括的な概要が不足しています.
この論文ではこの分野の包括的なレビューを提供している.
1. Instroduction
従来の教師あり学習の目標は,入力インスタンス空間から出力空間にマッピングする関数を学習すること.
出力は,単一ラベル(予測タスクの場合)または単一値(回帰タスクの場合)です.
しかし,多くの問いには複雑な回答が必要であり,複数の決定で構成される場合があります.
例えば,コンピュータビジョンでは複数のラベルで画像に注釈を付ける必要がある[1].
このような意思決定と複雑な予測問題は,通常,multi-output learning(マルチ出力学習)によって処理できます.
マルチ出力学習は,入力が与えられると複数の出力を同時に予測することを目的とする新しい機械学習の例です.
従来の単一出力学習と比較すると,複数の出力に複雑な相互作用があり,構造化された推論によって処理できます.
出力値は,機械学習の問題によってさまざまである.
たとえば,
マルチラベル分類問題に対するバイナリ出力値[4]
多次元分類問題に対する名目上の出力値[5]
順位付けの問題にラベルを付ける順序出力値[6]
マルチターゲット回帰問題への実数値出力[7]
A The 4Vs Challenges of Multiple Outputs
4Vとは,Multi output learningの特性のこと.volume, velocity, variety and veracity(体積、速度、多様性、真実性)
それぞれの課題について説明している.
-
volume
問題- 生成された出力ラベルの爆発的な増加
- データセットのアノテーションが不足
- ラベルの不均衡の問題
-
velocity 課題は,出力分布の変更
-
variety
課題
出力の依存関係の適切なモデリング
多変量損失関数の設計
複雑な構造の問題を解決する効率的なアルゴリズム -
veracity
問題
ノイズ
欠損値
異常
データの不完全性など
2. Life Cycle of output labels
出力ラベルについて書かれている.
A.データのラベル付け方法
B.ラベル表現の形式
C.ラベルの評価と課題
1)ラベル注釈の問題:ノイズの多いラベル,欠落している注釈や誤った注釈をもたらす可能性がある.
2)ラベル表現の問題:ベルには内部構造があるが,ラベルは通常サイズが大きく,構造を定義するにはドメインの知識が必要なので、このような情報を表現に組み込むことは簡単ではない.
3)ラベルセットの問題:データ注釈のラベルセットを取得するには、ドメインの知識を持つ専門家が必要,データに十分なラベルが含まれないことが一般的である.
3. multi output learning
従来の単一出力学習とは対照的に、多出力学習は、出力が多様な分野のアプリケーションを備えた多くの異なるサブフィールドでさまざまなタイプの構造を持つ複数の出力を同時に予測する.
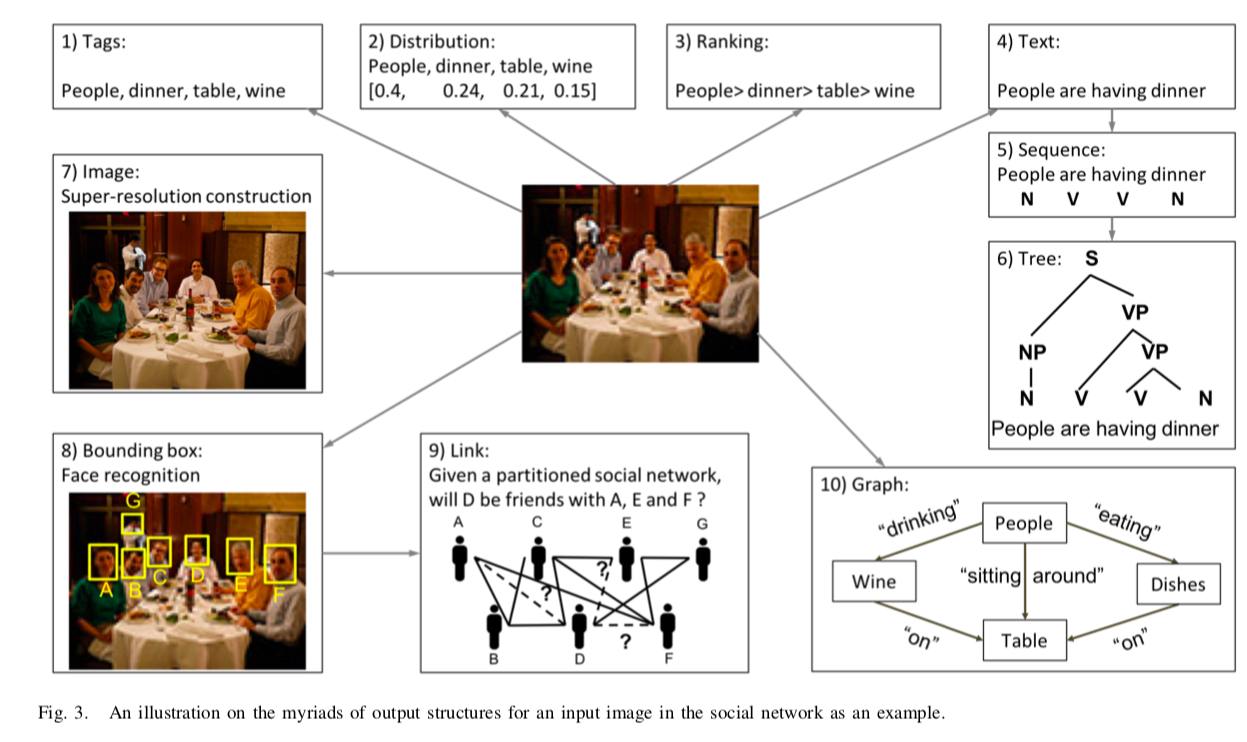
A.無数の出力構造・・・画像を入力とした様々な出力について記述されている.図3を参照
B.多出力学習(MOL)の問題定義
MOLは,各入力(instance)を複数の出力に射影(map)する.
$\mathcal{X}=\mathbb{R}^d$:d次元の入力空間
$\mathcal{Y}=\mathbb{R}^m$:m次元の入力空間
多出力学習のタスクは、トレーニング$\mathcal{D} = ${$(\textbf{$x_i$}、\textbf{$y_i$)} | 1≤i≤n$} から関数$f:\mathcal{X}→\mathcal{Y}$を学習すること
$x_i\in\mathcal{X}$:d次元の特徴ベクトル
$y_i\in\mathcal{Y}$:$x_i$に関連付けられた対応する出力
問題を解くための統一フレームワーク
関数$F:\mathcal{X}\times\mathcal{Y}\rightarrow\mathcal{R}$を見つけること.
$F(x,y)$は入力$x$と出力$y$の互換性を評価する互換性関数
見えないインスタンス$x$が与えられると、出力は最大の互換性スコア
$f(\textbf{$x$})=\tilde{x}=argmax_\textbf{$y\in\mathcal{Y}$}$F(x,y)
1)マルチラベル学習:
C.多出力学習の特殊なケース
D.モデル評価指標
E.多出力学習データセット
4. THE CHALLENGES OF MULTI-OUTPUT LEARNING AND REPRESENTATIVE WORKS
A. extreme output dimension極端な出力次元
大規模なデータセットはどこにでもある.
データセットは,以下の観点から大規模だと定義されている.
- 多数のデータインスタンス
- 入力特徴空間の高次元性
- 出力スペースの高次元性
機能選択方法[90]などの機能空間の高次元によって引き起こされるスケーラビリティの問題の解決に焦点を当てた研究は多くあるが,高出力次元の原因は,あまり注目されていない.
出力次元が非常に大きい場合やラベルの数が多い場合,出力スペースが非常に大きくなる可能性があり,計算が非効率的になる.
したがって,マルチ出力学習モデルを設計することが重要.
先行研究では,出力次元が時間が経つにつれて増えてきて,今後もっと増えてくる.
生成モデルと判別モデルの主な違いは,生成モデルが入力xとラベルyの結合確率$P(x、y)$の学習に焦点を当てているのに対し、判別モデルは事後$P(y|x)$に焦点を当てていることです.
(1)定性的アプローチ-生成モデル
GANの説明
(2)定量的アプローチ-識別モデル
入力インスタンスの数を減らす方法や入力次元を減らす方法と同様に,高次元出力の出力次元を減らすようにモデルを設計するのが自然.
Embedding methodsを利用して,ラベルの相関関係や近傍構造などの予想される情報を保持したまま,元の空間を低次元の空間に投影することにより,空間を圧縮できる.
ランダム射影や正準相関分析(CCA)ベースの射影[197][198],[199],[200]などの一般的な方法を採用して,出力ラベルスペースの次元を小さくすることができる.
B. complex structure複雑な構造
ラベル間には強い相関関係と複雑な依存関係が存在することが一般的.以下をモデリングすることが重要.
- dependency between outputs 出力間の依存関係
- multivariate loss function 多変量損失関数
- efficient algorithm 効率的なアルゴリズム
ラベルの数が増えるにつれて,ラベルの固有の構造を理解する必要がある.
ラベル間には強い相関関係と複雑な依存関係が存在することが一般的.
マルチ出力学習では,出力の依存関係を適切にモデリングすることが重要.
(1) 出力依存関係の適切なモデリング
多出力学習の最も簡単な方法は,多出力学習問題をm個の独立した単一出力問題に分解すること
↑代表的なものBR法[204]
しかし,BR法では,出力の依存関係を考慮できない.
そこで,相互依存性を持つ複数の出力をモデル化する手法が提案される.
- Label Powerset (LP)[205]→単一ラベル分類器の数が指数関数的に増えるという問題に対してRandom k- Labelsets [210]という拡張
- Classifier Chains (CC)[206][207]→チェーンの順序が異なると結果が異なるという問題にECC[206],PCC[211] ,CCMC[94]へ拡張
- Structured SVMs (SSVM) [208]
Conditional Random Fields (CRF) [209]
(2)多変量損失関数:いろんなの紹介されてる.
(3)効率的なアルゴリズム:
1)k最近傍(kNN)ベース
2)decision tree ベース
3)k-means ベース
4)hashing ベース
C. extreme class imbarance極端なクラスの不均衡
データから学習した従来のモデルは,多数派クラスをより好む傾向がある.
特に不均衡が極端な場合,マルチ出力学習では課題が残っている.
クラス分布のバランスを取るための1つの自然な方法は,データ空間のリサンプリングを行うこと
少数クラスでオーバーサンプリング手法SMOTE[232]
多数派クラスをダウンサンプリングする[233]
D. Unseen output見えない出力
ラベルの爆発的な増加は,高次元の出力スペースをもたらすだけでなく,テスト中に見えない出力ラベルのために教師あり学習タスクを困難にする.
- zero-shot ゼロショットマルチラベル分類:マルチラベル分類問題は,入力から出力へのマッピングを学習する.ラベルスペースが増加するにつれて,テスト中に目に見えない出力ラベルが表示されることがよくある.[16],[237]
- ちょっとよくわからない...
- open-set オープンセット:現在のオープンセット認識は,マルチクラス分類の設定についてのみ研究されており,マルチ出力学習の他の問題はまだ未調査.
E. noisy outputノイズの多い出力
- Missing Labels:
- Incorrect Labels:
ノイズの多いラベルを処理する既存の多出力学習方法は,主に2つのグループに分類される.
1つ目:ロバストな損失関数[258]〜[260]を構築します.これらは,損失関数のラベルを変更してノイズ効果を軽減します.
2つ目:潜在ラベルをモデル化し,潜在ラベルからノイズの多いラベルへの遷移を学習します[261] – [263].
missing labelsラベルがない
incorrect labels 間違ったラベル
partial labels 部分的なラベル
F. change of output distribution出力分布の変更
出力分布は時間とともに変化し,概念の変化が発生する可能性がある.
例えば,監視[76],運転手経路予測[73],需要予測[75]
監視ビデオの視覚追跡の例[268]だと,ビデオは潜在的に無限.
学習モデルは,考えられる概念の変化に適応し,限られたメモリの下で動作する必要がある.
既存の方法は,アンサンブルベースの方法[269],[271],[270][271],[272],[273]とANNベースの方法[268],[274]によってい,出力分布の変化をモデル化する.
概念変化に対処する戦略には,以下の戦略がある.
さらに,k最近傍(kNN)は複数出力の問題を処理する上で最も古典的なフレームワークの1つ.
非効率性の問題により,うまく適応させることはできない.
G. others その他
上記の課題のいずれか2つを組み合わせた課題に取り組むのはあり.
例えば,
- Eノイズの多いラベルとD目に見えない出力を組み合わせたやつ[278].
- Eノイズの多いラベルとA極端な出力次元の組み合わせ[186]
- F出力分布の変化とEノイズの多いラベルの組み合わせ[279]・・・欠損値を伴うオンライン時系列予測
- B出力の複雑な構造とF出力分布の変化の組み合わせ[282]
H. open challneges オープンチャレンジ
5. Conclution
過去10年間で多出力学習が大きな注目を集めている.
この論文では,多出力学習の研究に関する包括的なレビューを提供しました.
マルチ出力の4V特性と,4Vがマルチ出力学習の学習プロセスにもたらす課題に焦点を当てている.