0. 概要
- タイピングゲームを作るための「ローマ字入力の正誤判定」を行うJavaScriptライブラリです
- 例えば「ひっしゅう」は、hisshuu, hisshilyuu, hiltushilyuuなどと複数の入力パターンがあります。それらを網羅した入力正誤判定を行うことができます
- ひらがな と、ローマ字のどこまでをすでに打ったのかを得ることができます
1. このライブラリを使用して作成したタイピングゲームの例
これらのサンプルはすべて simple_typing_game.html ファイルでできています。この simple_typing_game.html では、打ち終わったキーとこれから打つキーを span タグに入れているので例えばCSSによって以下のようにカスタマイズすることもできます。
/* 既存項目の変更例 */
.done {
/* background-color: grey; 元々の設定:背景色を灰色にする */
color: lightgray; /* 例えば打ち終わった文字を薄くする */
}
/* 新規項目の作成例 */
#key_candidate {
visibility: hidden; /* 例えばこれから打つキーを隠す */
}
simple_typing_game.htmlファイルは以下のところからダウンロードできます。
2. ダウンロード
ライブラリは、keygraph.js ファイルです。
simple_typing_game.htmlファイルがライブラリを使ったタイピングゲームの例です。
simple_typing_game.htmlでは、keygraph.js以外にsound.jsファイルも読み込みます。
3. ライブラリの使い方
<!-- ライブラリの読み込み -->
<script src="keygraph.js"></script>
<script>
// DAGの作成、keygraph.jsを読み込むとkeygraph変数が使えるようになります。
keygraph.build("ひっしゅう");
// これから打つキー、すでに打ったキーを表示、 ... は適宜変更してください。
const disp = ()=>{
// これからタイプしなければいけないキーの取得
document.getElementById("...").innerText = keygraph.key_candidate();
// タイプし終わったキーの取得
document.getElementById("...").innerText = keygraph.key_done();
// これから打つ ひらがな の取得
document.getElementById("...").innerText = keygraph.seq_candidates();
// 打ち終わった ひらがな の取得
document.getElementById("...").innerText = keygraph.seq_done();
}
// keydownのイベント処理
document.body.addEventListener("keydown", e => {
if (keygraph.next(e.key)) {
// 入力がタイピングするキーと一致している場合
}
if (keygraph.is_finished()) {
// すべての文字をタイプし終わったとき
}
disp();
});
disp();
</script>
これからタイプしなければいけないローマ字について
4. タイプする文字を自分で作成するアプリ
タイピングゲームのアプリ例である simple_typing_game.html は、URL引数によってタイプする文字を指定することができます。以下のは、そのURL引数を作成するアプリの例です。

↑ の左側で漢字混じりの日本語を打つと、右側に ひらがな が自動作成されます。自動変換された ひらがな は、間違えていれば自分で修正することもできます。登録した文字を打つタイピングゲームのURLは画面下に表示され、URLにマウスをもっていくと「実行」「URLの短縮」「URLのコピー」のそれぞれのボタンが表示されます。URLの文字数が最大の4096文字になるまで文字を追加することができます。
ひらがな 自動変換について
短縮URLについて
5. ライブラリは、ひらがな からキーパターンを網羅した有向非巡回グラフ(DAG)を作成します
有向非巡回グラフとは、グラフ理論における閉路のない有向グラフのことです。ライブラリに「ひっしゅう」と入力すると、以下のようなDAGを作成します。
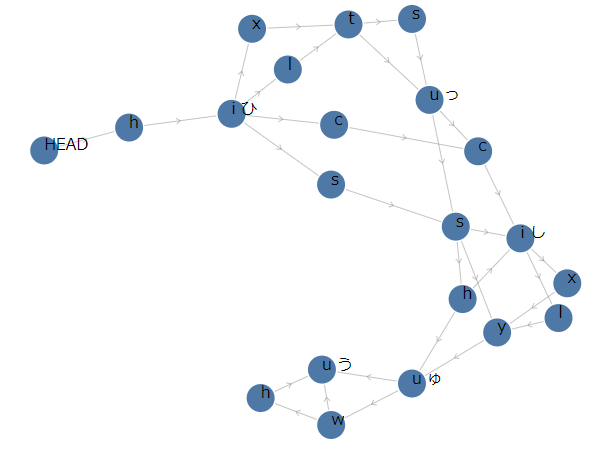
グラフ理論では、丸いものを「ノード」、その丸を繋ぐ矢印を「エッジ」と呼びます。DAGの場合はエッジに方向が付いていて、片方にしかDAG内を移動することができません。また1つのノードからスタートして同じノードに戻ってくるという巡回経路がありません。
↑ の例で「HEAD」は、このDAGをたどる最初のノードと、このライブラリではしています。HEAD以外のノードには「h」などのキーが割り当てられていて、そのキー打つとそのノードに達する、という感じです。また「ひ」などの ひらがな が書かれているノードは、そのノードに達したときにその ひらがな までが打ち終わったことを表します。
このDAGは次のようにして使われます。
- まず、このDAGの現在位置を「HEAD」とします。
- キー入力があったときに、現在位置の先に移動できるキーならば、現在位置を移動させます。例えば「HEAD」に現在位置があるときは、「h」キーが入力されたときだけ現在位置が「h」のノードに移動します。
- 移動先のない終端のノードに着いたら、タイピングが完了したことを表します。上のDAGの場合は、「う」と書かれているノードが終端のノードです。
「ひっしゅう」のDAGでは、まず最初の「ひ」は「hi」しか選択肢がないので、「HEAD」「h」「i」とDAGをたどる経路は1本道となっています。そして「i」の先は4つに分かれています。たとえば「sshu」と辿ると「っしゅ」までを一度にタイプできて、「っ」「し」「っ」を1文字ずつタイプするような場合は、「xtu」「xtsu」「ltu」「ltsu」のどれかをたどって「っ」のノードまでたどり着きます。そこから「si」「ci」のどちらかの経路で「し」まで到達し....と続いて最後の「う」のノードまでたどり着けば「ひっしゅう」を打ち終わったことになります。
6. ひらがな からDAGを作るためのアルゴリズム
6.1. アルゴリズムの概要

↑ の例は、架空のある ひらがな"〇" を打つキーが"abde", "acde"の2種類ある場合のDAG作成例です。まず最初の"abde"の1文字が1ノードとなってグラフになります。次に"acde"を作成するわけですが、最初の文字から順にすでにDAGにあるキーは、この場合は"a"は、同じノードを共有します。次の"c"は先に作った"abde"の"b"とは異なるので"a"から枝分かれします。そしてそのあとの"d","e"は"c"の後につながります。"d","e"は1つ目のキーですでにノードが作られているわけですが、一度枝分かれしたらそのあとはノードを統合せずに別れたまま進みます。
そしてすべてのキーパターンがDAGに入ったら、最後に追加したノードのマージ処理を行います。この例の場合は、2つの"e"ノードが対象です。同じノードは1つにマージして、さらにマージした"d"ノードの親もマージして、と続いてマージできないところまでさかのぼってマージを繰り返します。
このノードのマージは、マージ対象のノードがすべてDAGに追加されてから処理が開始されます。例えば上記の場合は、ある架空の〇文字だけを対象としていますが、「っ〇」「〇」と「〇」文字まで到達する ひらがな の経路が複数ある場合も、すべての「〇」を打つキーパターンがDAGに追加されてから、ノードマージ処理が行われます。「っしゅ」の「ゅ」の場合だと、ひらがな の経路でいうと一度に3文字を打つ (1)「っしゅ」、2文字と1文字の2回に分ける (2)「っし」→「ゅ」、1文字ずつ打つ (3)「っ」→「し」→「ゅ」の3種類の経路があります。この3種類のすべてのキーパターンがDAGに追加されてからノードマージ処理を実施することになります。

もしも途中でノードマージ処理を実施してしまうと、↑ のように一度マージして統合したノードをあとでもとに戻さなければいけないことが発生するからです。例えば「っ」のキーパターンが ↑ のように定義されているとします。"ltu","xtu"でノードマージしてtuが統合されたあとで、"ltsu"を追加してまた最後のuをマージしてしまうと、以下のように"xtsu"というキーパターンにはない経路がDAGに作られてしまいます。この場合の正確なDAGは、↑ の右のDAGです。最初に"x"を打つと、"xtsu"は定義されていないので、残りの経路は"t"→"u"の一本道になります。

次にDAGは、1つの ひらがな の作成が終わったらその最終ノードから次の文字のノードが作られます。最終ノードが ↑ のように2つある場合には、その2つからそれぞれ次の文字のノードが作成されます。ただ ↑ では文字"△"のキーパターンがすべてDAGに追加されたあとで最後のノードはノードマージ処理されますので、"d"→"e"は1つだけが残ることになります。
必ず母音で終わる日本語では、複数のキー入力候補であってもローマ字入力では同じキーで1つの ひらがな は終わります。よって基本は ↑ のようなキーパターンの例はないのですが、例外は「ん」のケースです。「ん」は"nn"または"xn"で入力できるのですが、「ん」の次の文字が子音から始まる場合は、"n"の1つでも大丈夫です。もちろん"nn"と2つ打ってもよいので、この場合のみ「ん」の終了ノードは、"nn"の1つ目の"n"と2つ目の"n"の2か所となります。よって次の文字は、1つ目の"n"と2つ目の"n"の両方から経路が作成されます。
以上がDAG作成の処理の大まかなイメージです。
6.2. アルゴリズムの詳細
ここからは、より詳細にアルゴリズムについて述べていきます。
横型探索の要領で ひらがな からDAGを作成します。アルゴリズムは、同じキーは同じノードを共有し、別のキーがでてきたときに枝分かれするようにDAGを作成していきます。枝分かれしたエッジは1つの ひらがな が終わってから後ろから統合します。イメージとしてはツリーを作って、ツリーの下から同じノードを統合していく、という感じです。
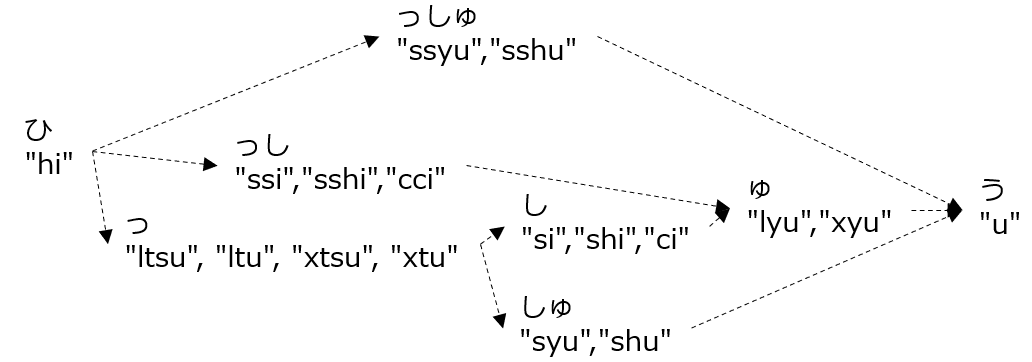
ひらがな のタイピングパターンは ↑ のようになります。まず「ひ」のノードとして「h」「i」を作り、「っ」のノード、「っし」のノードと増やしていきます。ひらがな の1塊が終わるたびに後ろからノードを統合して処理の途中で不要にDAGが大きくなることを防ぎます。
以下は、アルゴリズムの詳細です。OPEN変数には、先にエッジが伸びる可能性があるノードを保管しておきます。OPENを「打ち終わった ひらがな」の文字数の昇順でソートすることにより、DAGはHEADに近い方から順に広がっていくイメージで作成されます。OPEN変数は、{p:ひらがな の何文字目か, parents:親ノード一覧} を要素とした配列です。
| 手順 | 手順内番号 | 処理内容 |
|---|---|---|
| 1 | OPENにp:0,親ノード:HEADとした要素を入れる | |
| 2 | ① | OPENの先頭を取り出す。これを n とする。OPENが空の場合は、処理を終了する。 |
| ② | n.parentsのノードマージ処理をする。 | |
| ③ | n.pから始まる文字列に一致する文字をCHAR_KEYS_TABLEからすべて抽出する。 | |
| ④ | すべてのCHAR_KEYS_TABLE.charのすべてのkeysについて、同じキーを表すノードは複数作成せずに、異なるキーは枝分かれしながらn.parentsのすべてに子ノードとして追加する。ここでは枝分かれしたエッジは最後まで統合しないのでノードマージ処理がはいるまでは、一時的にノードは木構造となる。また1つのcharのkeysがすべて追加した時点で、p+char.lengthとしたOPENの要素を捜し、あればそのparentsにkeysで作成された最後のノードを追加する。なければ、新しいpを最後のノードとともにOPENに追加する。 | |
| ⑤ | OPENのpの昇順でソートする。 | |
| 3 | 2の処理に戻る |
DAGの子ノードの方から親ノードを統合していく処理を「ノードマージ処理」と呼んでいます。

このノードマージ処理とは「同じキーを表す」かつ「子ノード一覧が同じ」なノードは、DAG上で1つにまとめることができるので、それらを統合します。それらの処理は、残るノードを parent, 置き換えられるのが parent-removedとしたとき、それぞれの子ノード一覧を children, children-removed、それぞれの親ノード一覧を granpas, granpas-removed とすると、次のようになります。
| 手順 | 処理内容 |
|---|---|
| 1 | すべてのchildren-removedの親ノード一覧から parent-removed を削除, すべてのgranpas-removed の子ノード一覧から parent-removed を削除(parent-removedの上下エッジの削除) |
| 2 | すべてのgranpas-removedの子に parent を追加、parentの親一覧にすべての granpas-removed を追加(親の引継ぎ) |
| 3 | parent-removed は以後の処理で使用しないようにするために _merged 変数を true にセットする。 |
この処理でマージされずに残ったparentノードは、さらにその上の親ノードがマージできる可能性ができるため、parentの親ノード一覧のノードマージの対象として再帰的に処理する。
以上が ひらがな からDAGを作成するアルゴリズムです。
7. DAGの可視化
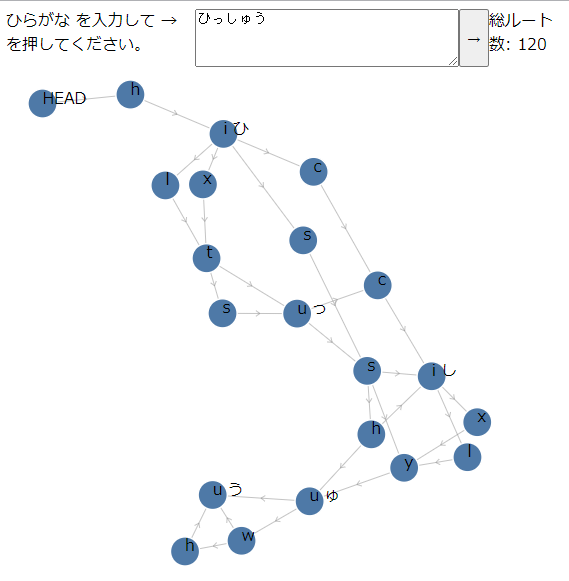
ライブラリとは直接関係がないですが、DAGを可視化するアプリです。ひらがな を入力すると、そのキーパターンを表したDAGが表示されます。タブや改行も打つことができますが、DAG上では空白に見えるのでご注意ください。ソースコードは、上記のダウンロードのところから参照することができます。
DAGの表示について
8. 性能
DAGは複数の経路が作成されても ひらがな の1文字ずつの終わりの時点では基本は閉じて1経路になります。よって本アルゴリズムの計算量はO(n)です。ここで n は ひらがなの文字数です。
以下の環境で約1500文字の ひらがな は、約0.1秒でDAGを作成することができます。
Intel Core i7-8500Y 1.60 GHz, 16.0 GB RAM, 64 bit Windows 11, Chrome 113.0.5672.93, 調査日 2023年5月11日
一度DAGが作成されればキー入力の正誤判定はDAGのサイズに依存しないので、リアルタイムで処理できると思われます。
9. パブリックドメインソフトウェア
本ライブラリは、パブリックドメインソフトウェアです。パブリックドメインソフトウェアとは著作権を放棄したソフトウェアで、商用利用、再配布、改変などもちろん何でもOKです。