はじめに
ARNってご存知でしょうか?
AWSを利用している人なら、何度も目にしていると思いますが、
arn:aws:iam::123456789012:user/Development/product_1234/*
こんなものですね。
詳細は、AWSのドキュメントにもあるので、そちらを参照してもらうとして、
「ああ、URIのAWS独自スキームでURNっぽいなぁ」と思いました。
ではURIなのか、URNとどう違うのか?など気になったので、URIとURNと比較して見てみましょう。
その前に少し小話を一つ。Webで検索するとURIとURNと同列にURLが並べられて説明されていますが、URL(Uniform Resource Locators)は技術文書(RFC)では、正式には定義されていません。正確には、RFC1738で規定されていましたが、URIの規定がなされた2005年のRFC3986で更新され、さらにRFC4248とRFC4266の策定によって廃止とされています。ということがRFCを読むと読み取れるので、URLとURIでどっちの言葉使うの?とかモヤモヤしたことがある人は、技術的な正しい定義が必要なところはURIで、それ以外ではコミュニケーションが成り立つならどちらでもいいんじゃないかなというのでよさそうですね。
URIとURNと比較して
以下、RFCの引用とその日本語訳を
RFC原文は引用
RFC原文の日本語訳は斜体
という形式で記載していきます。
URIと比較
URIとは、RFC3986のIntroductionに、
A Uniform Resource Identifier (URI) provides a simple and extensible means for identifying a resource.
Uniform Resource Identifier (URI) は、リソースを識別するためのシンプルで拡張可能な手段を提供します。
また、同Abstractで、
The URI syntax defines a grammar that is a superset of all valid URIs, allowing an implementation to parse the common components of a URI reference without knowing the scheme-specific requirements of every possible identifier. This specification does not define a generative grammar for URIs; that task is performed by the individual specifications of each URI scheme.
URI構文は、すべての有効なURIのスーパーセットである文法を定義し、可能なすべての識別子のスキーム固有の要件を知らなくても、実装がURI参照の共通コンポーネントを解析できるようにします。この仕様ではURIの生成文法は定義されていません。このタスクは、各URIスキームの個々の指定によって実行されます。
とあります。つまり、URIは一般的文法を定義しているだけで、 文法上で表せない詳細な定義や意味は各URIスキーム個別に定義してねと言っています。
スキームって?という話になるかと思いますが、Section 3でURIの構文があります。
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
URIはschemeから始まりコロン: まで、ARNでいうと arn になります。
ちなみに、 hier-part とは?と思う方も居るかもしれません。何の略かの説明がないのですが、文意的に階層を表す Hierarchy(ヒエラルキー) Partではないかと私は想像しています。
さて、スキームについて、RFCのSection 3.1 Scheme にて以下の様に説明しています。
Each URI begins with a scheme name that refers to a specification for assigning identifiers within that scheme. As such, the URI syntax is a federated and extensible naming system wherein each scheme's specification may further restrict the syntax and semantics of identifiers using that scheme.
各URIは、そのスキーム内で識別子を割り当てるための仕様を参照するスキーム名で始まります。このように、URI構文は統合された拡張可能な命名システムであり、各スキームの仕様は、そのスキームを使用する識別子の構文およびセマンティクスをさらに制限することができる。
つまり、URIとしての構文定義の範囲内で、 arn 以下の定義がなされれば、URIのサブセットとして、中身に関わらず解析できたり、URIを知っている人から理解しやすくなります。Parserでも作ろうかと考えることがある場合は気になる話でですね(世の中にいるかどうかは分かりませんが)。
URIの構文定義を少し見てみます。2.2 Reserved Characters を見てみましょう。
URIs include components and subcomponents that are delimited by characters in the "reserved" set.
URIには、 「予約済」 セット内の文字で区切られたコンポーネントおよびサブコンポーネントが含まれます。
If data for a URI component would conflict with a reserved character's purpose as a delimiter, then the conflicting data must be percent-encoded before the URI is formed.
URIコンポーネントのデータが、デリミタとしての予約文字の目的と競合する場合は、競合するデータをパーセント・エンコードしてからURIを作成する必要があります。
予約語を見てみると、
reserved = gen-delims / sub-delims
gen-delims = ":" / "/" / "?" / "#" / "[" / "]" / "@"
sub-delims = "!" / "$" / "&" / "'" / "(" / ")" / "*" / "+" / "," / ";" / "="
デリミタ(区切り文字)以外でこれらを用いる場合は、パーセントエンコードしなさいと言っています。ARNでは :(コロン)を resource-specific information の区切り文字に使っていますので、URIの目的と競合しません。また、 resource-type/resource-id と利用している /(スラッシュ)もサブコンポーネントの区切り文字という解釈ができるでしょう。ここまではARNはURIに準拠していそうです。
ただし、最初に示した例のARNだと、
arn:aws:iam::123456789012:user/Development/product_1234/*
として、 * (アスタリスク)が書かれていました。これは、URIではsub-delimisとして予約されています。ARNの * は階層化されたこの直下のリソース全ての表現ですので、区切り文字という解釈は難しそうです。URIに従うなら、パーセントエンコードが必要になります。なので、ARNはURI準拠でなく、URI風と考えるべきですね。(だれも準拠なんて言っていないので余計なお世話ですね)
ちなみにRFC3986には、 * を含むいくつかの文字が予約語に移動した説明があります。
Section 2, on characters, has been rewritten to explain what characters are reserved, when they are reserved, and why they are reserved, even when they are not used as delimiters by the generic syntax. The mark characters that are typically unsafe to decode, including the exclamation mark ("!"), asterisk ("*"), single-quote ("'"), and open and close parentheses ("(" and ")"), have been moved to the reserved set in order to clarify the distinction between reserved and unreserved and, hopefully, to answer the most common question of scheme designers.
文字に関するセクション2は、総称構文で区切り文字として使用されていない場合でも、どのような文字が予約されているのか、いつ予約されているのか、なぜ予約されているのかを説明するために書き直されました。感嘆符 ("!") 、アスタリスク ("") 、単一引用符 ("'") 、および開き括弧と閉じ括弧 (" ("および") ") は、予約セットに移動されました。これは、予約と未予約の区別を明確にするためであり、スキーム設計者に最もよくある質問に答えるためです。*
この説明だけでは私の知識では合点がいく訳ではないのですが、そのような質問があって混乱を生んでいたのかと想像で済ませて置きます。
内容とは関係ないですが、後半の英語の文章はピリオドがなく長い一文ですが、英語力の低い私としては、英文を一回読んで理解することができない類いのもですが、最近の機械翻訳に通した文章は、分割されており読みやすく翻訳されているのがありがたい話ですね。最近の機械学習の翻訳の質の向上は目を見張るものがありますね。(ちなみにRFCの日本語訳のサイトで公開されている翻訳文も意味としては理解できない文章になっていますので、自身で翻訳をかけ直すことをおすすめします)
次はURIのPathについて見てみたいと思います。Section 3 Syntax Componentsには、
The scheme and path components are required, though the path may be empty (no characters). When authority is present, the path must either be empty or begin with a slash ("/") character. When authority is not present, the path cannot begin with two slash characters ("//"). These restrictions result in five different ABNF rules for a path (Section 3.3), only one of which will match any given URI reference.
スキームとパスコンポーネントが必要ですが、パスは空 (文字なし) でもかまいません。authorityが存在する場合、パスは空であるか、スラッシュ ("/") 文字で始まる必要があります。権限がない場合、パスを2つのスラッシュ文字 ("//") で始めることはできません。これらの制限により、パス(第3.3章)に対して5つの異なるABNF規則が生成され、そのうちの1つだけが特定のURI参照に一致します。
URIのAuthorityは、パスコンポーネント以下を規定する権限の委任先を表しているので、ARNではAuthorityは定義されていないと考えていいでしょうし、URIの仕様としてもAuthorityがない場合、2つの // で初めてはならないと規定しています。パスコンポーネントとして見た場合、URIのパスの定義としては、説明のように5つ(path-abempty, path-absolute, path-noscheme, path-rootless, empty-path)ありますが、ARNや path-rootless, URNはpath-noschemeだと解釈できそうです。ARNは arn:: という表現が許されているし
arn:aws: として2つめの要素で必ずアルファベット始まりで、 URNはurn:NID のNIDがアルファベットはじまりであると定義されています。
ちなみに5つのABNF規則は(厳密ではないですが)簡単に書き下すと以下のようになります。
- path-abempty:
/始まりか 空か - path-absolute:
/は始まりで、//でない - path-noscheme:
:でない文字始まり - path-rootless:
:で始まってもよい - empty-path: 文字列なし
URNと比較
URNはARNと一文字違いで構文もコロンを区切り文字にしているところがよく似ています。
urn:example:a123,z456
一方ARNのドキュメントでは、
Amazon Resource Names (ARNs) uniquely identify AWS resources.
Amazonリソースネーム (ARN) は、AWSリソースを一意に識別します。
と言っています。
一方、URNは、RFC8141のAbstractにおいて、
A Uniform Resource Name (URN) is a Uniform Resource Identifier (URI) that is assigned under the "urn" URI scheme and a particular URN namespace, with the intent that the URN will be a persistent, location-independent resource identifier.
Uniform Resource Name (URN) はUniform Resource Identifier (URI) であり、 「urn」 URIスキームと特定のURN名前空間の下で割り当てられます。URNが場所に依存しない永続的なリソース識別子になることを目的としています。
と記載されているように場所に依存しない永続的なリソース識別子を掲げています。
ここで場所って何かを考えると、URLはリソースの置き場所としてホスト名やディレクトリ構造を表していました。しかしリソース(いわゆるWebコンテンツとしてHTMLファイル)などは移動がたやすく、リソースとしては同じなのに、アクセするための場所が変わることを想定せざるをえない仕様となっていました。HTTPレスポンスステータスコード 307 Temprary Redirect や 410 Gone などはまさに移動するリソースのためのレスポンスコードですよね。この場所を表すのではなく、識別子として永続的な名前の定義というのがポイントかと思います。永続的であることが期待できるなら、識別子として広くシステム内で参照しても変更は入らないことが期待できます。ARNのドキュメントに永続的なという表現はないですが、ARNが変わったという話は聞かないので、多分期待はしてもよさそうです。
ARNとURNの構文面で見てみましょう。URNでは、スキーム(先頭のurnという文字列)とNID(コロン区切りの2番目の文字列)は、大文字小文字を区別しません。なので、
urn:examle:a123,z456
URN:EXAMPLE:a123,z456
も同じ識別子ですが、ARNは大文字小文字を区別します。
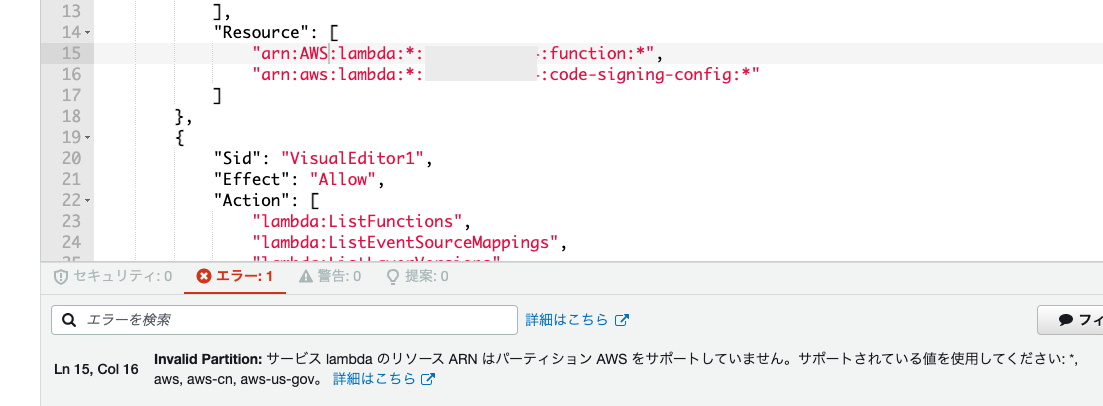
URNを参考にしつつ、面倒な処理は抑えたいのでこのような仕様になっているのかなとも思いました。ただ、URNが想起されるので、「ARNとスキームを表す arn と partitionをあらわす文字列は大文字小文字を区別します」という説明があった方が親切かなとは思います。
ARN独自
ARNはURIやURNに似た構文を持ちつつも、AWSでリソース表現するために都合よい構文としていると思います。基本的にARNはAWSの都合でシステムから与えられるもので、ユーザーが自身で組み立てる必要はないですが、ユーザーが読んでその階層構造と、表現された文字列で伝えようとしている意味が理解しやすい仕様であると感じます。(URIのheir-partという階層構造という前提が所見でもすっと入って来ているのでしょうね。)
例えば、S3のバケットとその直下にあるリソースを表すARNは、
arn:aws:s3:::my_corporate_bucket/*
となりますが、URNに通じるARNが一意にリソースを識別するという理解で見ると、 my_corporate_bucket がawsの partition (ほぼ全てのユーザーにおいてグローバル)のs3に置いてユニーク(な文字列)であると読めます。
account-id が記載されていれば、アカウント内で閉じた識別子なので、衝突よりも外に出ないようにセキュリティを意識する必要があるかもと気を配ったりするのにも役に立ちますね。
最後に
ARNは特にURIに準拠と謳っている訳ではないので、URIやURNと比較すること自体意味はないのかもしれませんが、構文がこれらを想起させるので、何がどう違うのかなと見て来ました。似ているところ、違うところなどありましたが、ベースの知識としてURIやURNがあるとより早く理解が進むのではと思います。
RFCなどの文章に慣れていないと、読むのが辛いところもあるとは思いますが、このような文章には仕様の定義の曖昧性をなくすような記述にもなっているので、仕様定義などしようとする人はこのような表現に慣れて置いてもいいのではと思います。また、RFCの更新と統合と再定義の過程を追うことで、複数の仕様を分解したり、共通項を再定義を包含するための定義のあり方を学ぶよい教材だとも思います。
最近では多くのRFCが日本語化されていますが、日本語訳がおかしいこともあるので、常に原文も参照するのがおすすめです。
なお、この文章の英文の翻訳はすべて株式会社みらい翻訳の Mirai Translator® もしくは みらい翻訳社提供の無料翻訳サイト「お試し翻訳」で翻訳された文章を無加工で載せています。