某ソシャゲで忍衣装のキャラを入手できましたΣ(・ω・ノ)ノ!
記念に個人的なninjaの使い方をまとめます。
TL;DR
個人的なゲーム開発で使用する予定のリソースビルド(データコンバート)のつくり方をまとめます。
ゲーム開発では多くのリソースが必要であり、ゲームで読み込めるようにコンバートする必要があります。例えば
- Excelでデータを入力して
- jsonファイルで出力して
- バイナリファイル(msgpackとか独自形式とか)に変換して
- 複数のバイナリをまとめて一つのファイルに
みたいなものがたくさんあります。ここでninjaに限らずビルドシステムを導入するメリットとしては
- 並列ビルド(複数のCPUで同時にビルド)ができる
- 差分ビルド(変更のあったファイルだけをビルド)ができる
だと思います。
コード全部載せたら結構長文になってしまったのでコード部分は雰囲気で読み飛ばすのが良いと思います。
ninjaとは
ビルドツールです。主にC++等のプログラムをビルドするために使われます。
Chromiumのプロジェクトで使われていて速いを売りとしています。
個人的にはシンプルで学習コストが低いのがとても良いです(forとかifとかすらないです)。
実行環境
- Window10 (64bit)
- Python 3.7.0b4
pythonはコンバータの作成とninjaスクリプトを生成するのに使用します。2.7でも大きな問題はないと思います。
テストデータ
簡単なテキスト変換を作ります。
include/
├ text00.txt
├ text01.txt
├ text02.txt
root.txt
setting.json
{
"chara" : "呼吹丸"
}
<キャラ名>をお迎えすることができました。
inlcude(text00)
inlcude(text01)
inlcude(text02)
Σ(・ω・ノ)ノ!Σ(・ω・ノ)ノ!
<キャラ名>かわいい
<キャラ名>かっこいい
<キャラ名>つよい
setting.jsonのcharaに指定してある文字列でテキストファイルに記述されている<キャラ名>を置換し
root.txtでinclude(*)と記述されている部分をinclude以下のディレクトリから文字列を取得し置換します。
最終的に
呼吹丸をお迎えすることができました。
呼吹丸かわいい
呼吹丸かっこいい
呼吹丸つよい
Σ(・ω・ノ)ノ!Σ(・ω・ノ)ノ!
というテキストファイルを出力できれば完成です。ゲームのデータとしては<キャラ名>はランタイムで置き換える場合が多いですが分かりやすさ優先でこのようにしました。
コンバータを準備する
まだninja関係ないです。ビルドシステムはあくまでコンバータをいい感じに呼ぶだけのものなのでコンバータ自体は自作するなりネットから拾ってくる必要があります。今回は独自ルールなので自作しました。
キャラ名を置換するコンバータ
import os
import argparse
import codecs
import json
if __name__=='__main__':
# 引数処理
parser = argparse.ArgumentParser()
parser.add_argument('input')
parser.add_argument('output')
parser.add_argument('--setting',required=True)
args = parser.parse_args()
# 出力ディレクトリを作成
os.makedirs(os.path.dirname(args.output),exist_ok=True)
# 設定jsonの読み込み
with codecs.open(args.setting, 'r','utf-8') as f:
setting = json.load(f)
chara = setting['chara']
# コンバート
with codecs.open(args.input, 'r', 'utf-8') as f_in:
with codecs.open(args.output,'w', 'utf-8') as f_out:
f_out.write(f_in.read().replace('<キャラ名>', chara))
includeを展開するコンバータ
import os
import sys
import argparse
import codecs
import re
if __name__=='__main__':
# 引数処理
parser = argparse.ArgumentParser()
parser.add_argument('input')
parser.add_argument('output')
parser.add_argument('--depfile')
parser.add_argument('--show_includes', action='store_true')
args = parser.parse_args()
# 出力ディレクトリを作成
os.makedirs(os.path.dirname(args.output),exist_ok=True)
# 入力ファイルを読み込み
with codecs.open(args.input, 'r', 'utf-8') as f:
lines = f.readlines()
# 正規表現
prog = re.compile(r'inlcude((\S+))')
# 依存ファイル
depfiles = list()
# コンバート
with codecs.open(args.output,'w', 'utf-8') as f:
for line in lines:
m = prog.search(line)
if m:
filename = '{}.txt'.format(m.group(1)[1:-1])
infile = os.path.join(os.path.dirname(args.input), 'include',filename)
with codecs.open(infile, 'r', 'utf-8') as f_in:
f.write(f_in.read())
f.write('\r\n')
# gccスタイルの依存ファイル用
depfiles.append(infile)
# MSVCスタイルで依存ファイルを標準出力に出す
if args.show_includes:
sys.stdout.write('Note: including file: tmp\\include\\{}\r\n'.format(filename))
else:
f.write(line)
if args.depfile:
with open(args.depfile, 'w') as f:
f.write('{} : \\\r\n'.format(args.output))
f.write(' {}\\\r\n'.format(args.input))
for depfile in depfiles:
f.write(' {}\\\r\n'.format(depfile))
バッチファイルから呼び出す。
まだninja関係ないです。一旦バッチファイルで一つずつ呼び出して問題がないか確認します。
以下のようなディレクトリ構成で build/tmp以下に<キャラ名>を置換したテキストを出力し、build/out以下に最終テキストを出力します。
build/
├ out/ (ビルド結果を出力するディレクトリ)
├ tmp/ (中間データを出力するディレクトリ)
data/
├ include/
├ text00.txt
├ text01.txt
├ text02.txt
├root.txt
├setting.json
scripts/
├text_converter.py
├text_merger.py
batch_build.bat
@echo off
set setting_file=%~dp0data/setting.json
python %~dp0scripts/text_converter.py %~dp0data/root.txt %~dp0build/tmp/root.txt --setting %setting_file%
python %~dp0scripts/text_converter.py %~dp0data/include/text00.txt %~dp0build/tmp/include/text00.txt --setting %setting_file%
python %~dp0scripts/text_converter.py %~dp0data/include/text01.txt %~dp0build/tmp/include/text01.txt --setting %setting_file%
python %~dp0scripts/text_converter.py %~dp0data/include/text02.txt %~dp0build/tmp/include/text02.txt --setting %setting_file%
python %~dp0scripts/text_merger.py %~dp0build/tmp/root.txt %~dp0build/out/root.txt
正直このくらいの簡単なものなら一瞬で終わるのでこれで十分ですね!
ninjaファイルを生成する
ここからやっとninjaを始めます。build.ninjaというテキストファイルを準備する必要があります。ninjaの文法は公式のドキュメント(英語)を見るのが間違いないですがninjaのgithubにmisc/ninja_syntax.pyというpythonスクリプトがあがっています。ここにWriterクラスが定義されており使えるキーワード等々が大体網羅されているので見比べると理解しやすいと思います。
ninjaファイルは文法自体は単純ですが記述量は多くなります。そのため基本的にはツールなどで自動生成します。ninja_syntax.pyが分かりやすいのでpythonでninjaファイルを生成することにします。
ninjaにはincludeで別ファイルを読み込む機能があるので3つにファイルを分割しました。
- config.ninja (ビルドで共通で使用する変数を定義)
- rule.ninja (コンバーターの呼び出しルールを記述)
- build.ninja (本体。コンバートするファイルを列挙)
小さいプロジェクトなら一つでも十分だと思います。
import os
import sys
import argparse
import codecs
# ninja/miscにパスを通す
sys.path.append(os.path.join(os.path.dirname(__file__),'..','ninja','misc'))
from ninja_syntax import Writer
if __name__=='__main__':
# 引数処理
parser = argparse.ArgumentParser()
parser.add_argument('output')
args = parser.parse_args()
with codecs.open(args.output, 'w', 'utf-8') as f:
writer = Writer(f)
writer.comment('ninjaの定数等を定義するファイル')
writer.newline()
# このリポジトリのルートディレクトリ
root_dir = os.path.abspath(os.path.join(os.path.dirname(__file__),'..'))
writer.comment('テキストコンバーター')
writer.variable(key='text_converter',value=os.path.join(root_dir, 'scripts', 'text_converter.py'))
writer.comment('テキストマージャー')
writer.variable(key='text_merger',value=os.path.join(root_dir, 'scripts', 'text_merger.py'))
writer.comment('中間ディレクトリ')
writer.variable(key='tmpdir',value=os.path.join(root_dir, 'build', 'tmp'))
writer.comment('出力ディレクトリ')
writer.variable(key='outdir',value=os.path.join(root_dir, 'build', 'out'))
writer.comment('設定ファイル')
writer.variable(key='setting_file',value=os.path.join(root_dir, 'data', 'setting.json'))
import os
import sys
import argparse
import codecs
# ninja/miscにパスを通す
sys.path.append(os.path.join(os.path.dirname(__file__),'..','ninja','misc'))
from ninja_syntax import Writer
if __name__=='__main__':
# 引数処理
parser = argparse.ArgumentParser()
parser.add_argument('output')
args = parser.parse_args()
with codecs.open(args.output, 'w', 'utf-8') as f:
writer = Writer(f)
writer.comment('ninjaのルールを定義するファイル')
writer.newline()
# configファイルのインクルード
writer.include('config.ninja')
writer.newline()
# ルール定義
writer.rule(
name='text_converter',
command='python $text_converter $in $out --setting $setting_file',
description='<キャラ名>を置換するコンバート'
)
writer.newline()
writer.rule(
name='text_merger',
command='python $text_merger $in $out --depfile $out.d',
deps='gcc',
depfile='$out.d',
description='includeを展開するコンバート'
)
writer.newline()
import os
import sys
import argparse
import codecs
# ninja/miscにパスを通す
sys.path.append(os.path.join(os.path.dirname(__file__),'..','ninja','misc'))
from ninja_syntax import Writer
def text_converter(writer, infile, outfile):
""" text_converterを呼び出すラッパー """
writer.build(
outputs=[outfile],
rule='text_converter',
inputs=[infile],
implicit=['$text_converter','$setting_file']
)
writer.newline()
def text_merger(writer, infile, outfile):
""" text_mergerを呼び出すラッパー """
writer.build(
outputs=[outfile],
rule='text_merger',
inputs=[infile],
implicit=['$text_merger']
)
writer.newline()
if __name__=='__main__':
# 引数処理
parser = argparse.ArgumentParser()
parser.add_argument('output')
parser.add_argument('--data_dir', required=True)
args = parser.parse_args()
with codecs.open(args.output, 'w', 'utf-8') as f:
writer = Writer(f)
data_dir = os.path.abspath(args.data_dir)
writer.comment('ninjaでビルドするファイルを列挙するファイル')
writer.newline()
writer.include('rule.ninja')
for root, directory, files in os.walk(data_dir):
for infile in files:
# 拡張子のチェック
ext = os.path.splitext(infile)[1]
if ext != '.txt':
continue
fullpath = os.path.join(root, infile)
relpath = os.path.relpath(fullpath, data_dir)
# キャラ名の置換の呼び出し
text_converter(writer,
infile=fullpath,
outfile=os.path.join('$tmpdir', relpath) )
# data_dir直下の場合
if root == data_dir:
text_merger(writer,
infile=os.path.join('$tmpdir', relpath),
outfile=os.path.join('$outdir', relpath) )
生成されたninjaファイルは以下のようになりました。
# ninjaの定数等を定義するファイル
# テキストコンバーター
text_converter = C:\workspace\ninja_res_bld_sample\scripts\text_converter.py
# テキストマージャー
text_merger = C:\workspace\ninja_res_bld_sample\scripts\text_merger.py
# 中間ディレクトリ
tmpdir = C:\workspace\ninja_res_bld_sample\build\tmp
# 出力ディレクトリ
outdir = C:\workspace\ninja_res_bld_sample\build\out
# 設定ファイル
setting_file = C:\workspace\ninja_res_bld_sample\data\setting.json
# ninjaのルールを定義するファイル
include config.ninja
rule text_converter
command = python $text_converter $in $out --setting $setting_file
description = <キャラ名>を置換するコンバート
rule text_merger
command = python $text_merger $in $out --depfile $out.d
description = includeを展開するコンバート
depfile = $out.d
deps = gcc
# ninjaでビルドするファイルを列挙するファイル
include rule.ninja
build $tmpdir\root.txt: text_converter $
C$:\workspace\ninja_res_bld_sample\data\root.txt | $text_converter $
$setting_file
build $outdir\root.txt: text_merger $tmpdir\root.txt | $text_merger
build $tmpdir\include\text00.txt: text_converter $
C$:\workspace\ninja_res_bld_sample\data\include\text00.txt | $
$text_converter $setting_file
build $tmpdir\include\text01.txt: text_converter $
C$:\workspace\ninja_res_bld_sample\data\include\text01.txt | $
$text_converter $setting_file
build $tmpdir\include\text02.txt: text_converter $
C$:\workspace\ninja_res_bld_sample\data\include\text02.txt | $
$text_converter $setting_file
pythonスクリプトの方が記述量が多い…
ninjaビルドを実行する
バッチファイルを準備します。
@echo off
python %~dp0scripts/ninja_config_writer.py %~dp0build/config.ninja
python %~dp0scripts/ninja_rule_writer.py %~dp0build/rule.ninja
python %~dp0scripts/ninja_build_writer.py %~dp0build/build.ninja --data_dir %~dp0data
%~dp0ninja/ninja -C %~dp0build -v %*
実行すると以下のようにかっこよく実行してくれます。
C:\workspace\ninja_res_bld_sample>ninja_build.bat
ninja: Entering directory `C:\workspace\ninja_res_bld_sample\build'
[1/5] python C:\workspace\ninja_res_bld_sample\scripts\text_converter.py C:\workspace\ninja_res_bld_sample\data\include\text00.txt C:\workspace\ninja_res_bld_sample\build\tmp\include\text00.txt --setting C:\workspace\ninja_res_bld_sample\data\setting.json
[2/5] python C:\workspace\ninja_res_bld_sample\scripts\text_converter.py C:\workspace\ninja_res_bld_sample\data\include\text02.txt C:\workspace\ninja_res_bld_sample\build\tmp\include\text02.txt --setting C:\workspace\ninja_res_bld_sample\data\setting.json
[3/5] python C:\workspace\ninja_res_bld_sample\scripts\text_converter.py C:\workspace\ninja_res_bld_sample\data\include\text01.txt C:\workspace\ninja_res_bld_sample\build\tmp\include\text01.txt --setting C:\workspace\ninja_res_bld_sample\data\setting.json
[4/5] python C:\workspace\ninja_res_bld_sample\scripts\text_converter.py C:\workspace\ninja_res_bld_sample\data\root.txt C:\workspace\ninja_res_bld_sample\build\tmp\root.txt --setting C:\workspace\ninja_res_bld_sample\data\setting.json
[5/5] python C:\workspace\ninja_res_bld_sample\scripts\text_merger.py C:\workspace\ninja_res_bld_sample\build\tmp\root.txt C:\workspace\ninja_res_bld_sample\build\out\root.txt --depfile C:\workspace\ninja_res_bld_sample\build\out\root.txt.d
そのままもう一度実行すると
C:\workspace\ninja_res_bld_sample>ninja_build.bat
ninja: Entering directory `C:\workspace\ninja_res_bld_sample\build'
ninja: no work to do.
のようにコンバートの実行をスキップします。またdata以下のファイルに変更があれば変更に関係する部分だけコンバートを実行してくれます。
またビルドで生成されたファイルはcleanコマンドで削除できます。
C:\workspace\ninja_res_bld_sample>ninja_build.bat -t clean
Cleaning...
Remove C:/workspace/ninja_res_bld_sample/build/tmp/root.txt
Remove C:/workspace/ninja_res_bld_sample/build/out/root.txt
Remove C:/workspace/ninja_res_bld_sample/build/tmp/include/text00.txt
Remove C:/workspace/ninja_res_bld_sample/build/tmp/include/text01.txt
Remove C:/workspace/ninja_res_bld_sample/build/tmp/include/text02.txt
5 files.
依存関係について
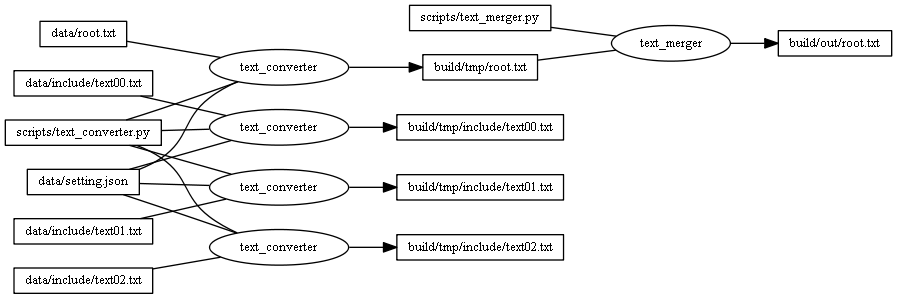
リソースビルドを作るうえで最も注意しなければならないのはビルドの依存関係です。依存関係を適切にninjaに伝えることでこのコンバートのあとこのコンバートを実行するだとかこのファイルが変更されたらこのコンバートを実行する等が正しく行われます。
基本は$in(入力)と$out(出力)です。コンバートの出力を次のコンバートの入力に繋いでいくことで依存関係を構築していきます。今回のサンプルではimplicit(暗黙の入力)、depfile(gcc形式での依存関係)も使用しているのでその辺りを突き詰めていくと細かい依存関係の制御ができるのではないかと思います。
依存関係はninja_build.bat -t graphでgraphviz形式で表示されます。dotファイルとして保存してgraphvizで画像ファイルに変換する、もしくはVSCodeのプラグインを導入することでプレビューできます。depfileを使用した依存関係は残念ながら繋がってないようですがビルドの流れがおおよそ把握できます。
終わりに
今回使用したファイル一式をgithubにあげています(https://github.com/towazumi/ninja_res_bld_sample)
自由に改変して使ってください。
C:\workspace\ninja_res_bld_sample>ninja_build.bat -t urtle
,;;;!!;;
,;<!!!!!!!!!!!;
`'<!!!!!!!!!!(``'!!
,;;;;;;, `\. `\ .,c$$$$$$$$$$$$$ec,.
,;;!!!!!!!!!!!>; `. ,;!>> .e$$$$$$$$"". "?$$$$$$$e.
<:<!!!!!!!!'` ..,,,.`` ,!!!' ;,(?""""""";!!''<; `?$$$$$$PF ,;,
`'!!!!;;;;;;;;<!'''` !!! ;,`'``''!!!;!!!!`..`!; ,,, .<!''`).
```'''''`` `! `!!!!><;;;!!!!! J$$b,`!>;!!:!!`,d?b`!>
`'-;,(<!!!!!!!!!> $F )...:!. d" ) !>
```````''<!!!- "=-=' . `--=",!>
.ze$$$$$$$$$er .,cd$$$$$$$$$$$$$$$$bc.'
.e$$$$$$$$$$$$$$,$$$$$$$$$$$$$$$$$$$$$$$$$$.
z$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$c .
J$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$c
$$$$$$$$$$$$$$P"`?$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$b
$$$$$$$$$$$$$$ dbc `""?$$$$$$$$$$$$$$$$$$$$$$?$$$$$$$c
?$$$$$$$$$$$$$$$$$$c. """"????????"""" c$$$$$$$$P
.,,. "$$$$$$$$$$$$$$$$$$$$c. ._ J$$$$$$$$$
.,,cc$$$$$$$$$bec,. `?$$$$$$$$$$$$$$$$$$$$$c.```%%%%,%%%, c$$$$$$$$P"
$$$$$$$$$$$$$$$$$$$$$$c ""?$$$$$$$$$$$$$$$$$$$$$bc,,.`` .,,c$$$$$$$P"",cb
$$$$$$$$$$$$$$$$$$$$$$$b bc,.""??$$$$$$$$$$$$$$FF""?????"",J$$$$$P" ,zd$$$
$$$$$$$$$$$$$$$$$$$$$$$$ ?$???% `""??$$$$$$$$$$$$bcucd$$$P""" ==$$$$$$$
$$$$$$$$$$$$$$$$$$$$$$$P" ,;;;<!!!!!>;;,. `""""??????"" ,;;;;;;;;;, `"?$$