Challenge Details
| Name | NuttyShell File Manager |
| Author | Karma |
| Final Solves | 8 |
| Final Points | 487 |
| Description | Episode 26 of Evangelion... but for computers! Files are losing their 'ego' and turning into LCL of 1s and 0s. All hope is not yet lost because the files are still separated by 'buffers' of 00s. Restore 'ego' of 3 files and 'carve' them out. |
Introduction
We are given a weird file named "Fanta_file_new", and the challenge description tells us to "carve" exactly $3$ files out...
Running strings on the file, we find that along with a bunch of random characters, there also exists delimeters "File ends right before this sentence" and "File starts right after this sentence"! We can use this to split the file into $3$ individual files.
Asking Gemini-2.0-Flash to make such python program to split files, it came up with this:
def split_file(input_file, output_file_prefix="output", split_string="File ends right before this sentence"):
"""
Splits an input file into multiple output files based on a delimiter string,
handling potential decoding errors.
Args:
input_file (str): Path to the input file.
output_file_prefix (str, optional): Prefix for the output file names. Defaults to "output".
split_string (str, optional): Delimiter string to split the file by. Defaults to "File ends right before this sentence".
"""
file_count = 1
current_output_file = None
try:
with open(input_file, 'rb') as infile: # Open in binary mode to handle all characters
file_content = infile.read()
# Split the binary content by the split string (encoded as bytes)
split_string_bytes = split_string.encode('utf-8') # Encode split string to bytes
parts = file_content.split(split_string_bytes)
# Iterate through the parts and write them to separate files
for i, part in enumerate(parts):
output_filename = f"{output_file_prefix}_{file_count}.txt"
try:
with open(output_filename, 'wb') as outfile: # Open in binary write mode
# If it's not the first file, prepend the split string
if i > 0:
outfile.write(split_string_bytes)
outfile.write(part) # Write the binary content directly
print(f"File '{output_filename}' created successfully.")
file_count += 1
except Exception as e:
print(f"Error writing to file '{output_filename}': {e}")
except FileNotFoundError:
print(f"Error: Input file '{input_file}' not found.")
except Exception as e:
print(f"An error occurred: {e}")
if __name__ == '__main__':
input_filename = "input.txt" # Replace with your input file name
split_file(input_filename)
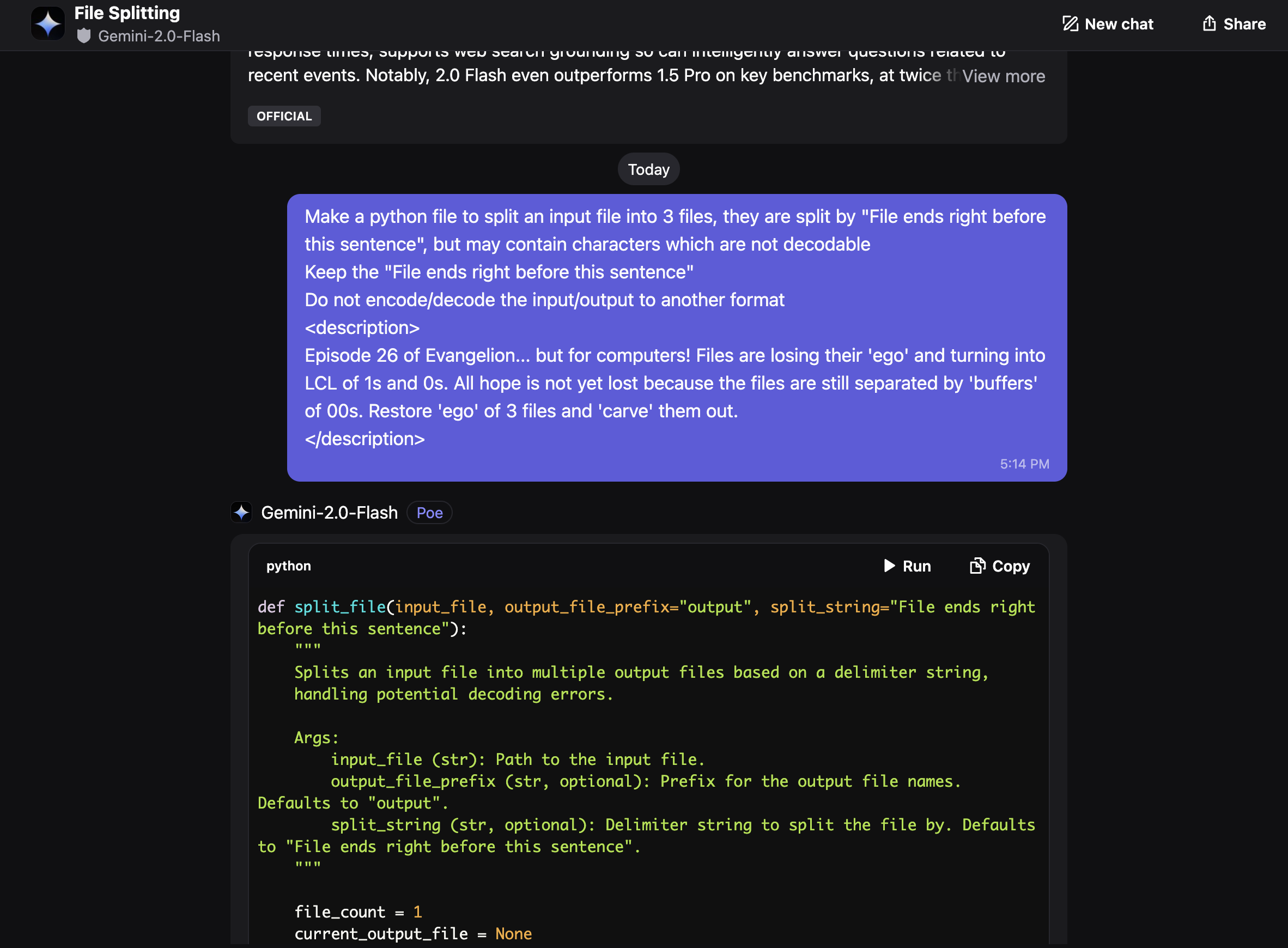
We run it to get 3 perfectly split files...
The First File
Let's first take a look at output_1.txt! It seems to contain an IHDR header ![]()
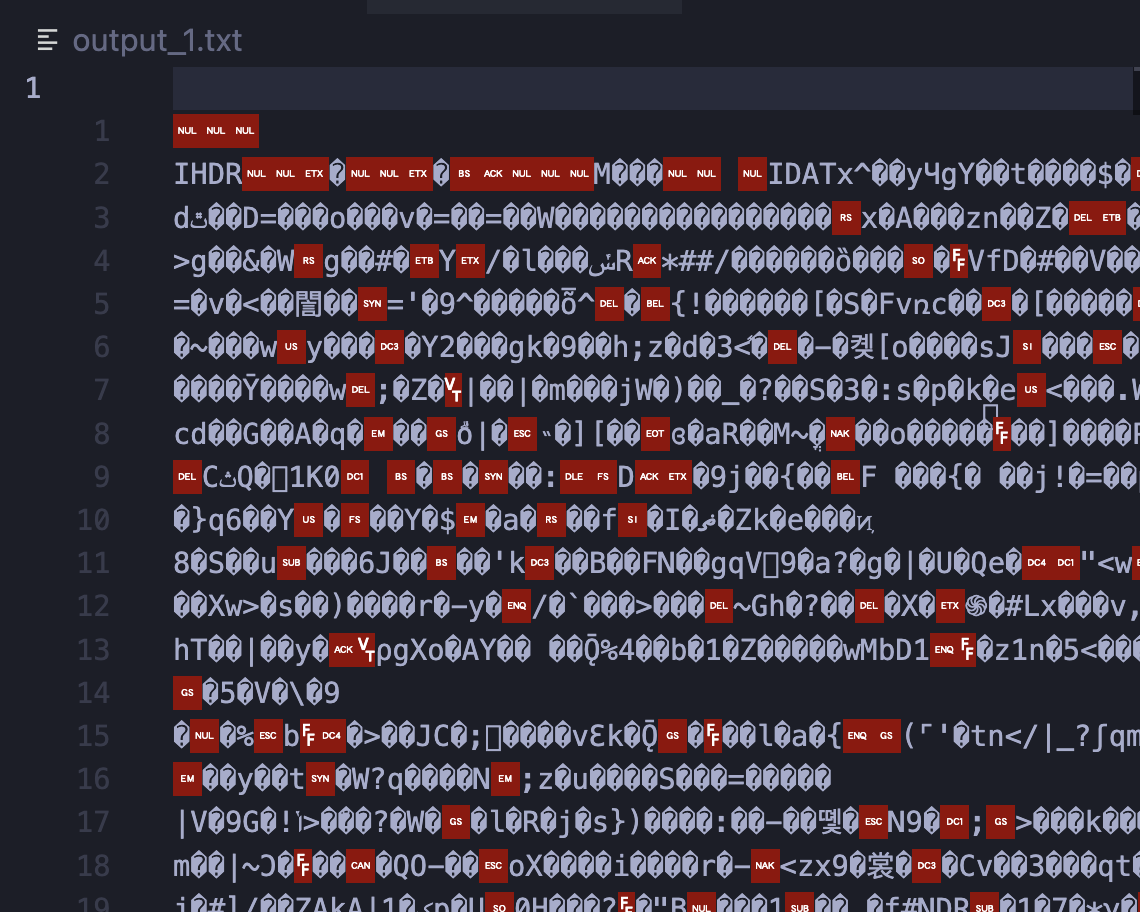
Google seems to suggest that it's a PNG file, however, it does seem to be missing some PNG file signature/magic bytes, and indeed, when we try to rename the file to output_1.png, the image doesn't load!

We can add back the signature in front of IHDR...
with open("output_1.txt", "rb") as f:
data = f.read()
png_signature = bytes([0x89, 0x50, 0x4E, 0x47, 0x0D, 0x0A, 0x1A, 0x0A])
ihdr_pos = data.find(b'IHDR')
chunk_start = ihdr_pos - 4
with open("recovered1.png", "wb") as f:
f.write(png_signature + data[chunk_start:])
Now when we open the file, it indeed loads an image! However, the image doesn't seem to show any flags, so let's run it through my favourite stego tool for images: AperiSolve
At the bottom of the AperiSolve analysis, the zsteg tool seems to have recovered part of the flag!
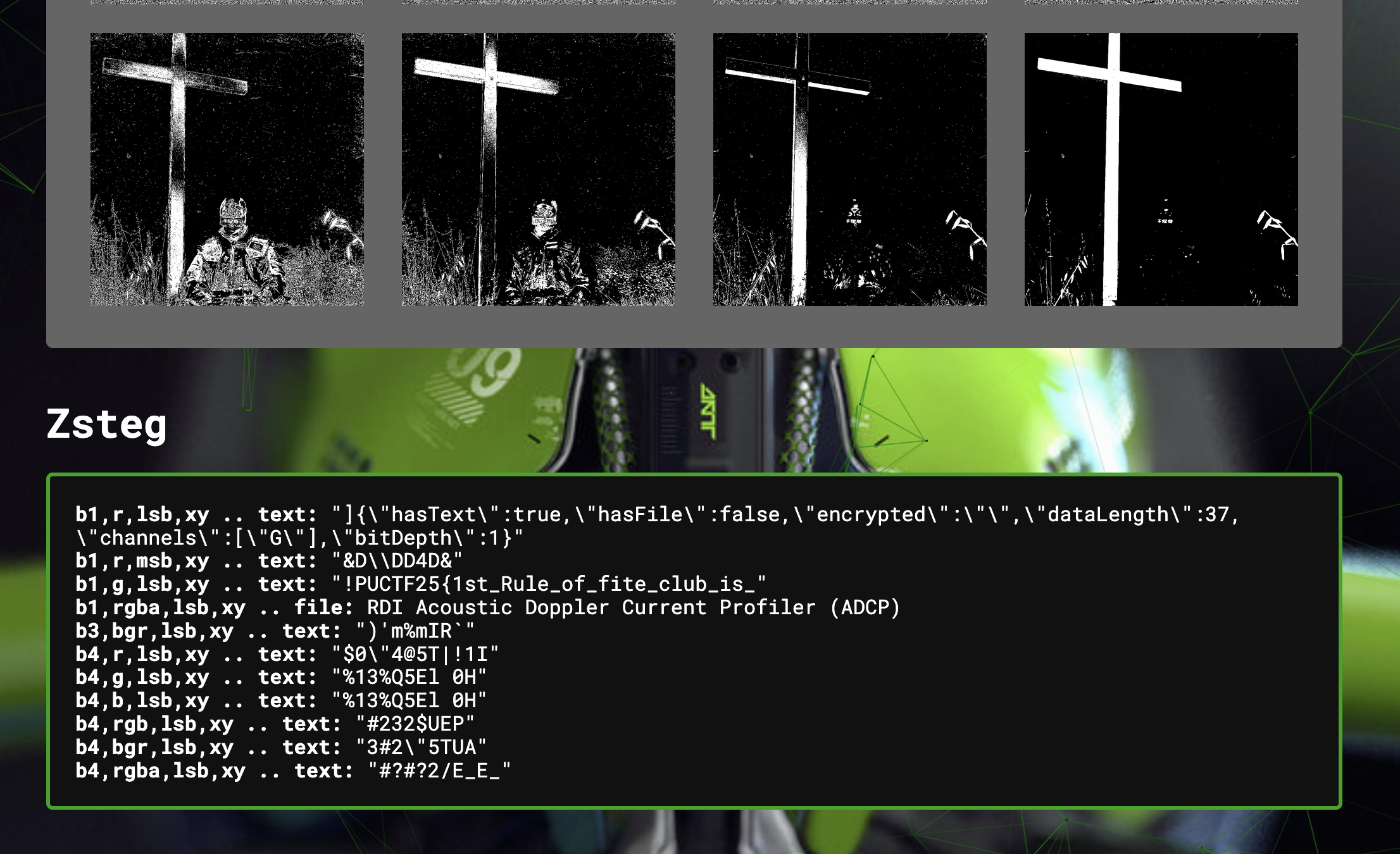
First part: PUCTF25{1st_Rule_of_fite_club_is_
The Second File
Looking into output_2.txt, the first line reads mimetypeapplication/vnd.oasis.opendocument.text after "File starts right after this sentence", which suggest that this is of the .odt format.

Being too lazy to do anything, I tried to run binwalk on output_2.txt, which succeeded!
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
DECIMAL HEXADECIMAL DESCRIPTION
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
393 0x189 ZIP archive, file count: 18, total size: 12780 bytes
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
[+] Extraction of zip data at offset 0x189 completed successfully
--------------------
extractions/output_2.txt.extracted
└── 189
├── Configurations2
│ ├── accelerator
│ ├── floater
│ ├── images
│ │ └── Bitmaps
│ ├── menubar
│ ├── popupmenu
│ ├── progressbar
│ ├── statusbar
│ ├── toolbar
│ └── toolpanel
├── content.xml
├── manifest.rdf
├── media-type
├── META-INF
│ └── manifest.xml
├── meta.xml
├── settings.xml
├── styles.xml
└── Thumbnails
└── thumbnail.png
This looks quite interesting and promising at the same time, particularly the file thumbnail.png displays the following text:

More interestingly, looking at media-type we find the following text:

This seems to be base64 but with lots of 09 in between! We can recognise it from the padding = and charset.
Removing the 09s and decoding it from Base64, we don't get anything too interesting...
However, thumbnail.png mentions XOR, so let's try that too!
Key = 09 seems to have decrypted the text, showing to_nEvEr_w0rry_and_havE_funn_!
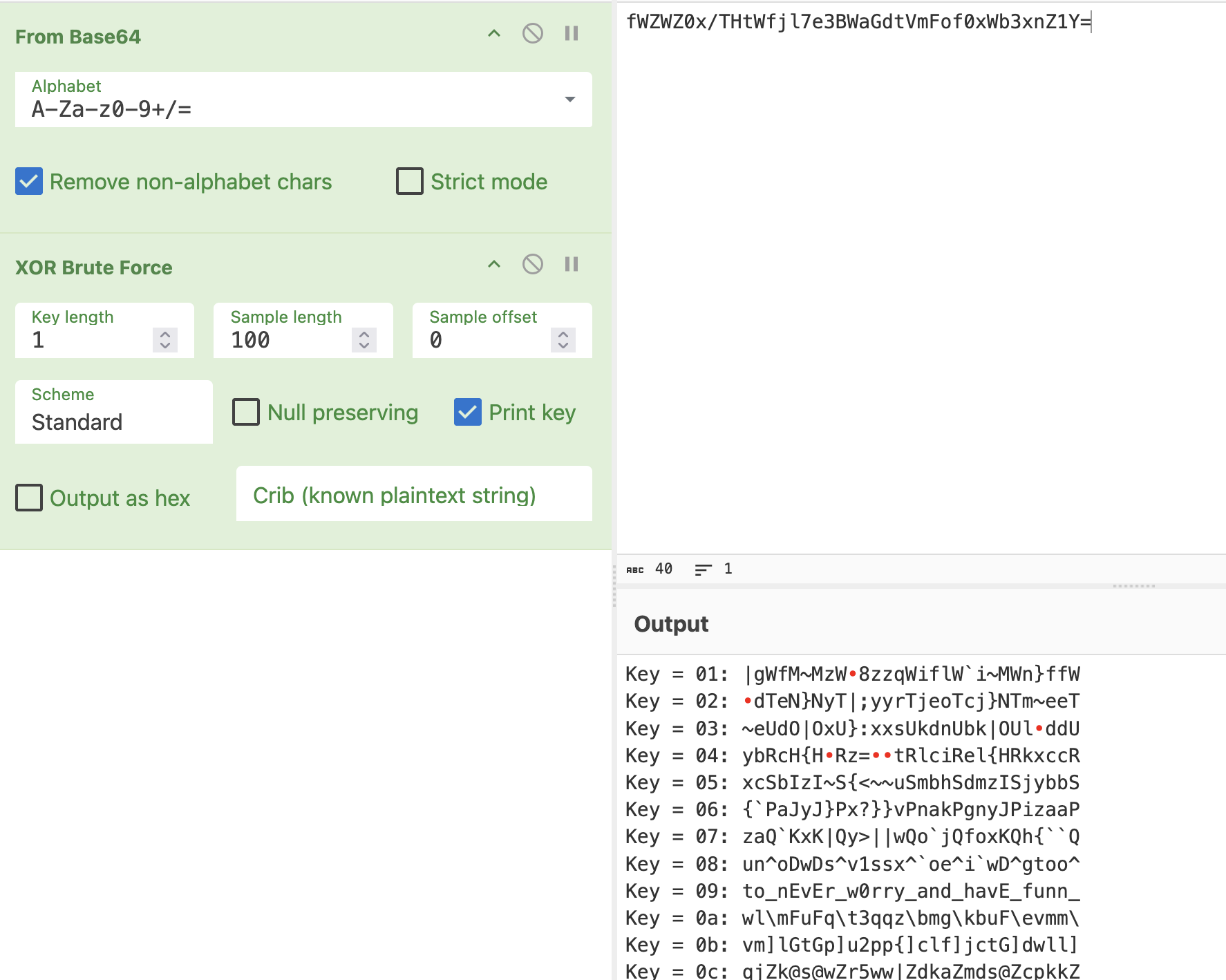
Second part: to_nEvEr_w0rry_and_havE_funn_
The Third File
output_3.txt seems to be an mp4 file, as shown by the first line within it!

Recovering the mp4 by removing stuff in front of its file signature, we just find a video without anything particularly interesting...


Looking at output_3.txt in more detail, we find this very interesting piece of code...
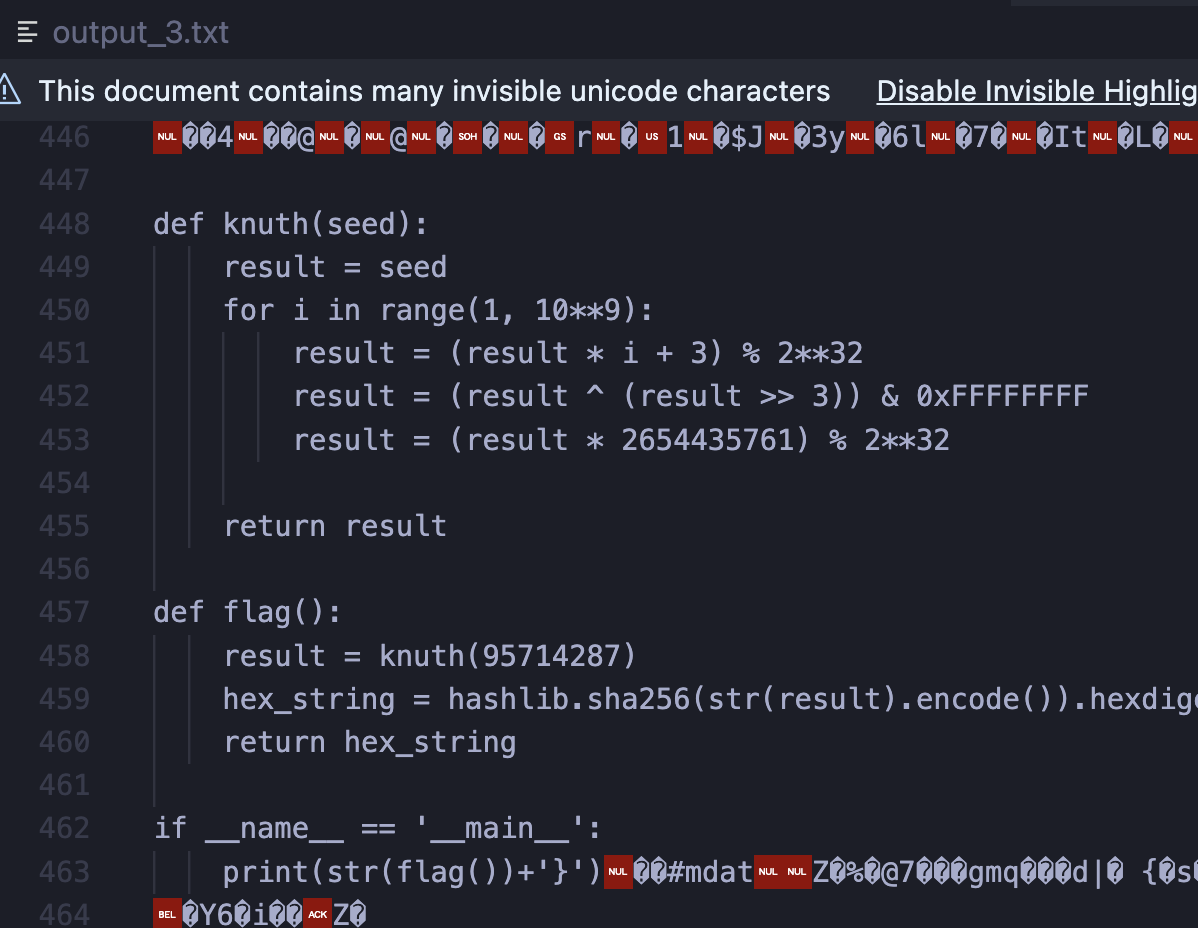
It appears that we can just run the file to obtain the last part of the flag... As running knuth function in python was a bit too slow, we asked ChatGPT to recreate the function in c++, which returned 238837843.
#include <cstdint>
#include <iostream>
#include <iomanip>
#include <sstream>
#include <string>
uint32_t knuth(uint32_t seed) {
uint32_t result = seed;
for (uint32_t i = 1; i < 1000000000u; ++i) {
// All operations wrap modulo 2^32 automatically on uint32_t overflow
result = result * i + 3;
result = result ^ (result >> 3);
result = result * 2654435761u;
}
return result;
}
int main() {
uint32_t r = knuth(95714287u);
std::cout << r << std::endl;
}
Putting the result back into the python file, we get the last part of the flag!
def flag():
result = 238837843
hex_string = hashlib.sha256(str(result).encode()).hexdigest()[:32]
return hex_string
if __name__ == '__main__':
print(str(flag())+'}')
Final part: 3601bc5bcef53e15254046faf34ef764}
Combining the parts
First part: PUCTF25{1st_Rule_of_fite_club_is_
Second part: to_nEvEr_w0rry_and_havE_funn_
Final part: 3601bc5bcef53e15254046faf34ef764}
PUCTF25{1st_Rule_of_fite_club_is_to_nEvEr_w0rry_and_havE_funn_3601bc5bcef53e15254046faf34ef764}