概要
-
Evaluating Discourse Phenomena in Neural Machine Translation [Bawden+2017]
- 文脈の意味を推測することができる、state-of-the-artなニューラル翻訳モデル。
- この研究を極めれば、より完璧に近いチャットボットが実現できる、はず。。。
- 翻訳だけではなく一般的な言語タスクにも応用できます。
- 論文を直に読んで、各章のエッセンスを3項目にまとめてみます。
論文のエッセンス
- 章立ては以下の通りです。
- Abstruct
- Introduction
- Evaluating contextual phenomena
- Our contrastive discursive test sets
- Contextual NMT Models
- Single-encoder models
- Multi-encoder models
- Experiments
- Data
- Experimental setup
- Results and Analysis
- Overall performance
- Targeted evaluation
- How much is the context begin used?
- Conclusion
- References
Abstruct
- 対話タスクでは、文に含まれていない文脈から読み取れる情報が重要
- この論文では、マルチエンコーダを用いた性能評価を行った
- 前の文と今の文のつながりを考慮するだけの単純な戦略が、十分な成果を挙げた
Introduction
- 文脈依存の問題は、主に以下の三点に分類される
- コーファレンス[Guillou2016]
- 語彙結合[Carpuat2009]
- 語彙曖昧さ除去[Rios Gonzales+2017]
- マルチエンコーダによる文脈推定の研究では、不適切な評価指標が用いられてきた
- 本稿では新しい文脈モデルと評価方法の提案を行う
Evaluating contextual phenomena
- これまで軽視されていた言い換えの問題では、参照訳との一致度よりも、ターゲット側での一貫性が重要な可能性がある
- 文章単位の翻訳だと簡単に既存の自動評価スコアを挙げられるが、手作業によるあらたな評価も必要になる
- 手作業だとコストがかかるので、翻訳の対訳対をランキングするモデルを評価する手法を用いる
Our contrastive discursive test sets
- 異なる文脈のモデルが代名詞とコヒーレンス・コヒージョンをどう扱うのか、という比較を行うためのデータセットを手動で作成した。これはOpenSubtitles2016に基づき、品質が保証されている
- 具体的には、曖昧な代名詞が指す言葉が文中には現れず、以前の文脈を参照する必要があるよう選定した
- テストセットは200の対訳対を含み、ベースラインシステムが50%の精度を達成するように設計される
Coreference test set

- このテストセットは4組からなる翻訳対を50件用意したものである
- 4組の内訳は、代名詞の異なる翻訳からなる。男性名詞と女性名詞のパターンに加え、それぞれ対象の名詞の翻訳結果が正しい場合と微妙に違う(準正解)場合を含む。例えば図1では、以下の通りになる
- 1.対象の名詞訳は「ハエ"mouches"」(正しい)、女性名詞(la)が正しい
- 2.対象の名詞訳は「ブヨ"moucherons"」(正しい)、男性名詞(le)が正しい
- 3.対象の名詞訳は「クモ"araignees"」(微妙に違う)、女性名詞(le)が正しい
- 4.対象の名詞訳は「チョウ"palillons"」(微妙に違う)、男性名詞(la)が正しい
- 比較対象となる代名詞は、数と性別ごとで均等に25個の正解例と25個の準正解例が用意された。MTシステムは、曖昧さを除去することでスコア付けを行い、ベースラインは50%のスコアとなる
Coherence and cohesion test set


- 概念や表現についての一貫性を図るデータセットでは、100個のサンプルブロックが含まれ、それぞれ2組の翻訳例からなる
- 曖昧な原文の翻訳結果が、文脈的な(以前の翻訳文との)一貫性を保っているかを検証する。例えば図2では、
- 1."crazy"の文脈的な訳は「"dingue"」、以後の文章での"crazy"は"dingue"と翻訳されるべきで、類義語の"fou"で翻訳されては誤りとなる
- 2."crazy"の文脈的な訳は「"fou"」、以後の文章での"crazy"は"fou"と翻訳されるべきで、類義語の"dingue"で翻訳されては誤りとなる
- 古典的な曖昧さ(コヒージョン)に対する検証として、図3では、異なる文脈に対するまったく同じ文章が設定されている。ただし、これらは依然として曖昧である
- 1.文脈は「お金」、文章は「思ったよりも急だ」、 「お金」の翻訳結果"cher"が出力されるべき
- 2.文脈は「脚」、文章は「思ったよりも急だ」、「脚」の翻訳結果"raide"が出力されるべき
Contextual NMT Models
- こうした文脈を理解する翻訳モデルの研究では、SMTでは、Bawdenらによる代名詞翻訳に焦点が当てられていたが、曖昧さのない文章を得ることは難しい
- NMTにおいては、前のセンテンスを現在のセンテンスに結合して基本的なEncoder-Decoderモデルを利用する方法が提案された。さらに、連結[Zoph and Knight16]や階層的注意[Libovicky & Helcl17]やゲーティング[Jean et al17a]などの、複数のアテンションなどを利用したメカニズムが提案されてきた
- 本稿では、前章のテストセットを利用して、モデルの調査を行う
NMT notation
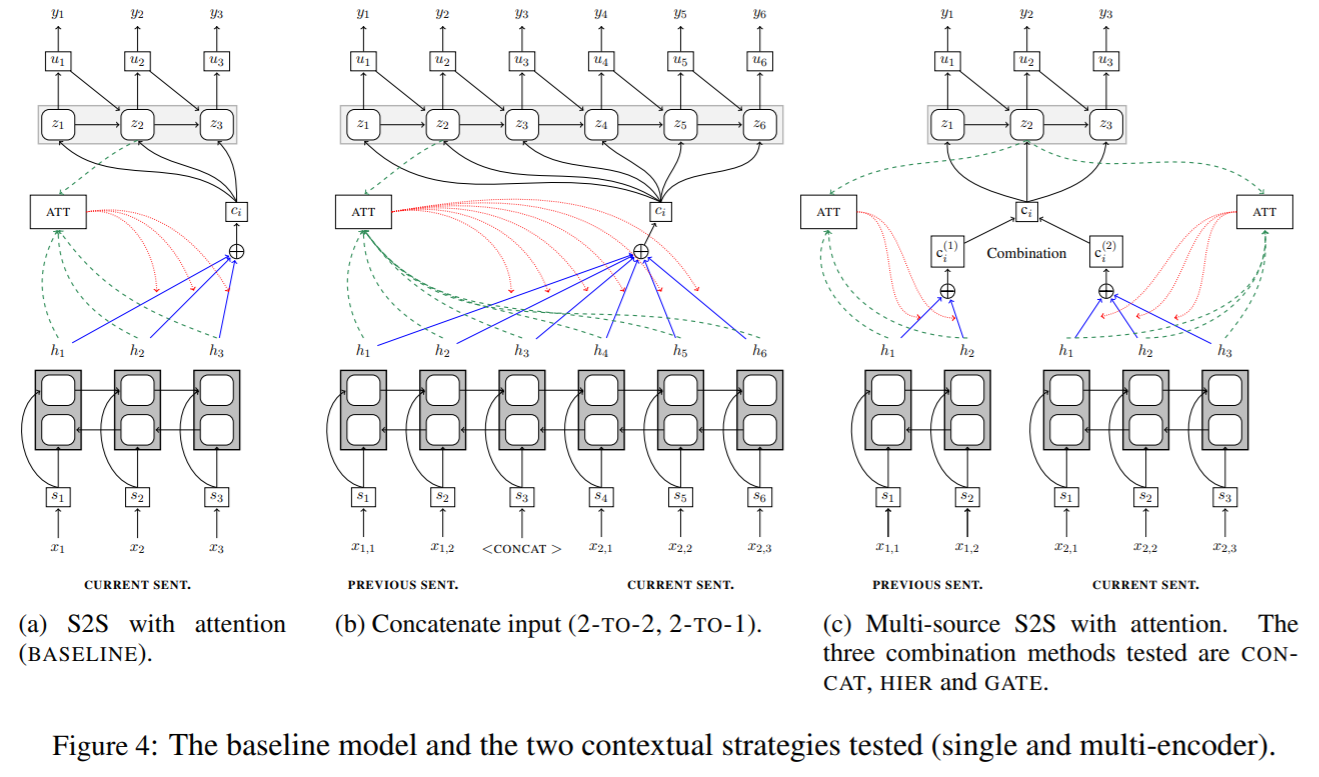
- 提示されたモデルは基本的にBaudanau15モデルをベースとしたものである
- 各デコーダステップにおいて、コンテキストベクトル$c_i$はアテンションに応じたエンコーダ内部状態の加重平均であり、デコーダの内部状態を$z_i$で示す
- 入力が複数ある場合は$x_j^{(k)}$で表し、エンコーダは$c_i^{(k)}$、$W_s$・$U_s$・$b$は最適化するパラメータを指す
Single-encoder models
- 3つの1入力モデルを訓練する。そのうちのひとつは独立した文章を翻訳する単純なベースラインモデルである
- Tiedemann+17では、ふたつの文脈モデルが提案された。これらはともにトークンを利用し直前の文を組み込む
- そのうち2-to-2と呼ばれるモデルでは、前の文と現在の文を一緒に読み込み、前の文と現在の文の訳を同時に出力する。2-to-1というモデルでは、翻訳時に現在の文だけを出力する
Multi-encoder models
- マルチエンコーダ翻訳モデルでは、翻訳する文の補助として、前の文脈を利用する。コンテキストベクトルは独立したエンコーダによって生成される
- 結果として生じるふたつのエンコードされたベクトル$c_i^{(1)}, c_i^{(2)}$は、結合されてデコーダで利用される
- ここでは、連結・アテンションゲート・階層的注意という3種類の戦略の組み合わせについて検討する。各戦略はすべて$c_i$に統合される
Attention concatenation
- $c_i^{(1)}, c_i^{(2)}$を連結した後、倍になった次元を元の次元に戻すために線形変換を行う
Attention gate
- $c_i^{(1)}, c_i^{(2)}$に異なる重要性を与えるため、非線形変換による重み付けを行う
Hierarchical attention
- $k$番目のコンテキストベクトルに対しアテンションを与える
Experiments
- マルチエンコーダ戦略では、どの入力がもっとも曖昧でない出力を得られるのかをテストするために、以前のソース文とターゲット文を追加入力して比較検証される
- S-HIER-TO-2は、前のソース文を補助入力としてエンコードする
- S-T-HIER-TO-2は、前のソース文とターゲット文を補助入力とした3エンコーダモデルである
Data
- OpenSubtitles20165に基づく並列字幕から制作されたデータを使用
- Mosesツールキットによりトークン化され、80トークン以下のものだけを抽出し、サブワード単位に分割される
- 語彙数は英55k-仏60kで、29Mの対訳コーパスを訓練に使用
Experimental setup
- Nematusによる実装を利用
- 埋め込み512・隠れ層1024・バッチサイズ80・Adam・アンサンブル学習等を使用
- 以前のターゲット文を利用する場合はレファレンスを使用して訓練
Results and Analysis
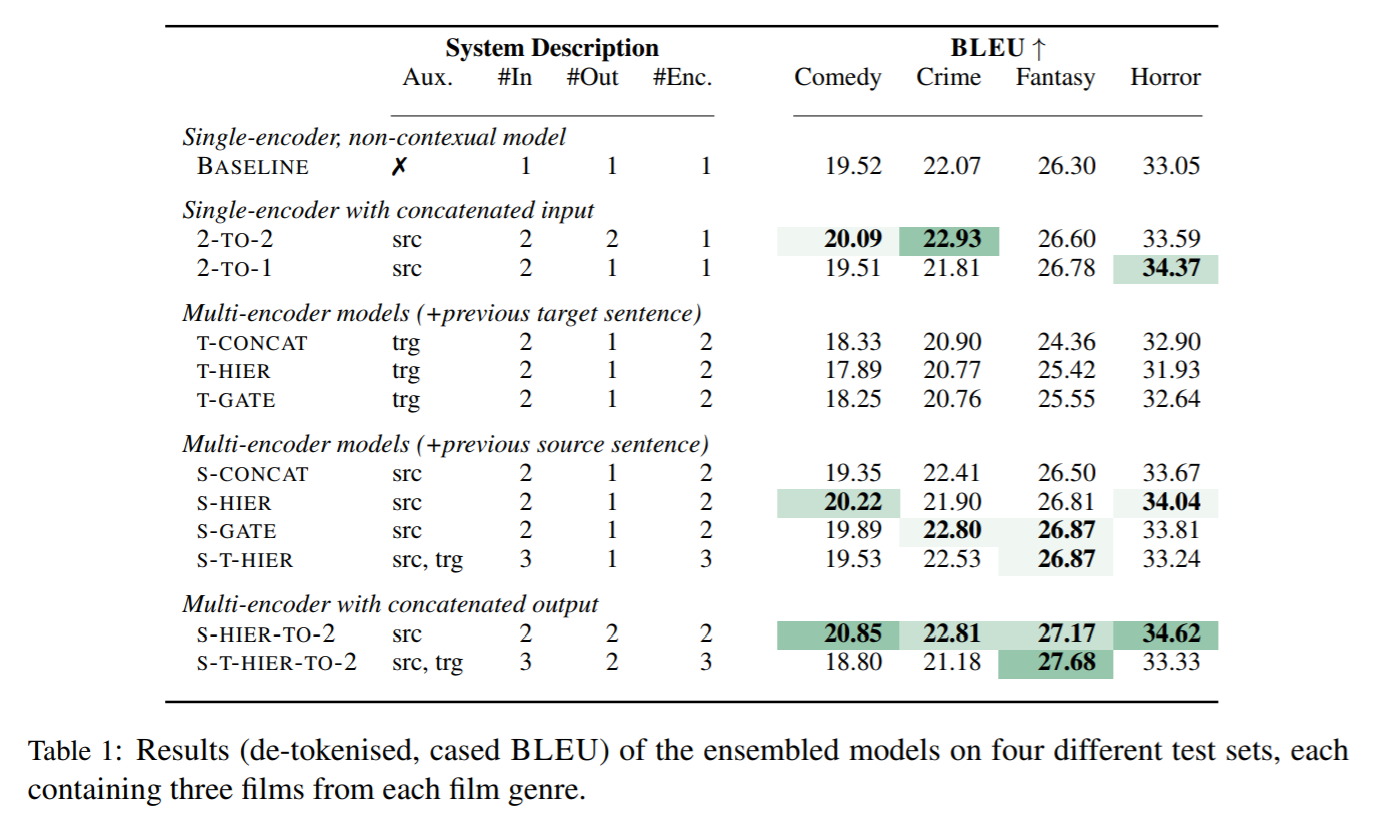
- 全体的な評価としてBLEUを使用(表1)
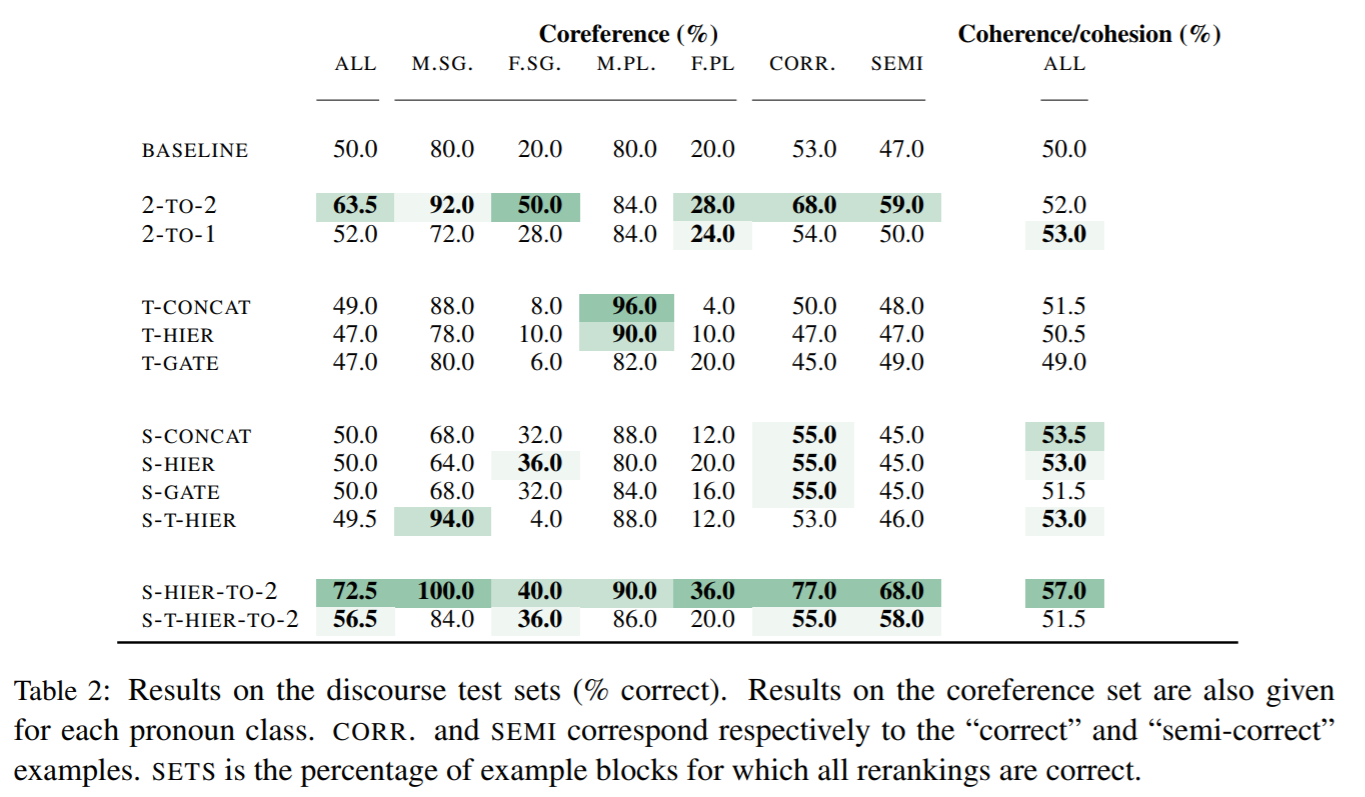
- 2章で提示した評価方法を表2に示す
- #Inは入力分の数、Auxは補助入力、#Outは翻訳文の数、#Encはエンコーダの数であり、単一のエンコーダと複数の入力がある場合は、入力を連結する
Overall performance
- コメディ・犯罪・ファンタジー・ホラーの4ジャンルについてテストを行った
- 前のターゲット文を補助入力として利用すると、全体の性能が大きく低下する。リファレンスを利用しても改善せず
- 最高のモデルは、S-HIER-TO-2モデルであり、ほぼすべてのテストセットでベースラインよりBLEUが+1以上の改善を見せた
Targeted evaluation
Coreference
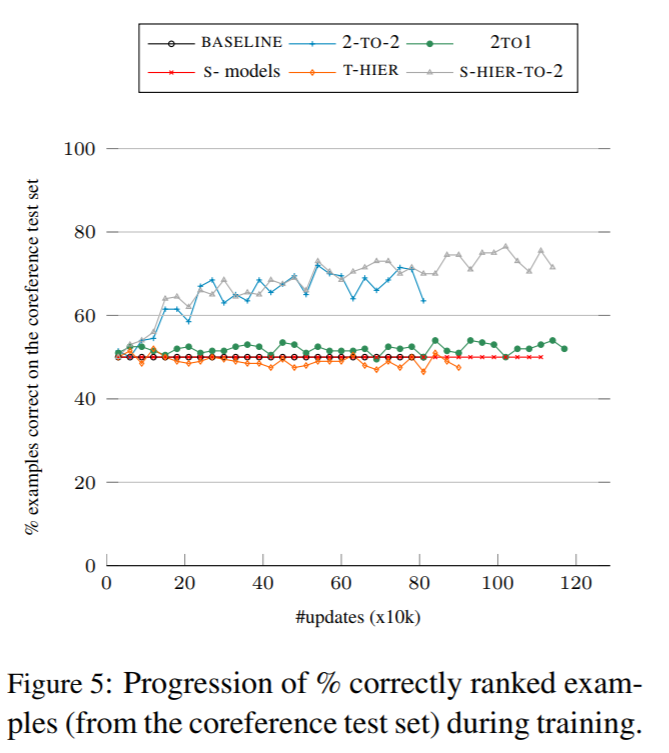
- 2-TO-2モデルとS-HIER-TO-2モデルが有効に機能した
- あまり一般的でない女性代名詞における高評価は、これらのモデルが文脈を捉えられていることの根拠となる
- ターゲット文を補助入力に使用すると、コーファレンスの評価も悪化した
Coherence and cohesion
- S-HIER-TO-2モデルが最も有効に機能した
- これは、マルチエンコーダを前の文と現在の文のデコードに対して組み合わせることで、曖昧な翻訳の処理が大幅に改善されたことを意味する
- 以前のターゲット文を補助入力に加えると、モデルにノイズが追加されるようで、スコアは悪化した
How much is the context begin used?
- コーファレンスの改善のために、デコーダに代名詞が指す語を加えることが期待される
- [Tiedemann and Scherrer2017]と異なり、翻訳された代名詞とその元になった単語との関係性は、観測できなかった
- 本稿の手法では、エンコーダを通した場合よりも、デコーダを通した場合に文脈情報が利用されているように思える
Conclusion
- マルチエンコーダだけでは、文脈を認識する能力には限界がある
- しかし、前のソース文を補助入力に加えて、前の文と現在の文の翻訳を行うモデル(S-HIER-TO-2)は、既存のモデルよりも大幅に良い結果が得られた
- デコーダについて着目すると、文脈認識において有望なのではないか
おわりに
-
Bawden17では各種マルチエンコーダモデルについての調査を行い、その結果、S-HIER-TO-2モデルの有用性が確認されました。
-
早く実装に移さねば……。