先日初めてLTで発表をしてきた佐々木です!!🎉
本当にあたたかい雰囲気の中で発表させていただけて、あれから少しずつ他のLTにも参加するようになりました。
一度参加したらはまります!おすすめです!✨
さてお察しの通り、初めてのLTは「GraphQLへの入門的な内容」でした。
LTで発表する以前、GraphQLについての理解が浅く
GraphQLを触ってみてもイマイチ全容が見えずモヤモヤしていました。
皆さんには本記事を通じて、「GraphQLとはなんなのか?」「どういった設定構成になっているのか?」などを理解し、スムーズにGraphQLに入門いただければと思います。
また、GraphQLとは?聞いたこともないです!
という方でも分かりやすい記事になっていると思いますので、是非ご一読いただけると嬉しいです!
GraphQLとは?
APIの「方式」の1つです。
Facebookが2015年に公開した、比較的新しいAPI方式になります。
特徴としては、以下のようなものがあります。
- エンドポイントは1つだけ
- やりとりするデータに対して型チェックが可能
- リアルタイム通信
これらについて詳しくお話ししていければと思います。
(余談)そもそもなぜAPIに「方式」が必要なのでしょうか?
仮に「一般化された方式」を使わない場合、
「サーバー」と「クライアント」でデータをやりとりする際の方法には以下のようなことを決める必要があります。
- URL / HTTPメソッド(GET, POST, PUT, DELETE)
- リクエストボディ
これらのパターンの組み合わせで、どういった処理をするのか...?
しかしプロジェクトの度に、いちいちこれらの形式を決めるのは 無駄な学習コスト を発生させてしまいます。
そこで、APIのデータのやりとりの方式を一般化することで、学習コストをグッと下げたのです。
GraphQLの全体像を掴む
特徴を具体的に見ていく前に、GraphQLで使われるファイルを一通り把握しておく必要があります。
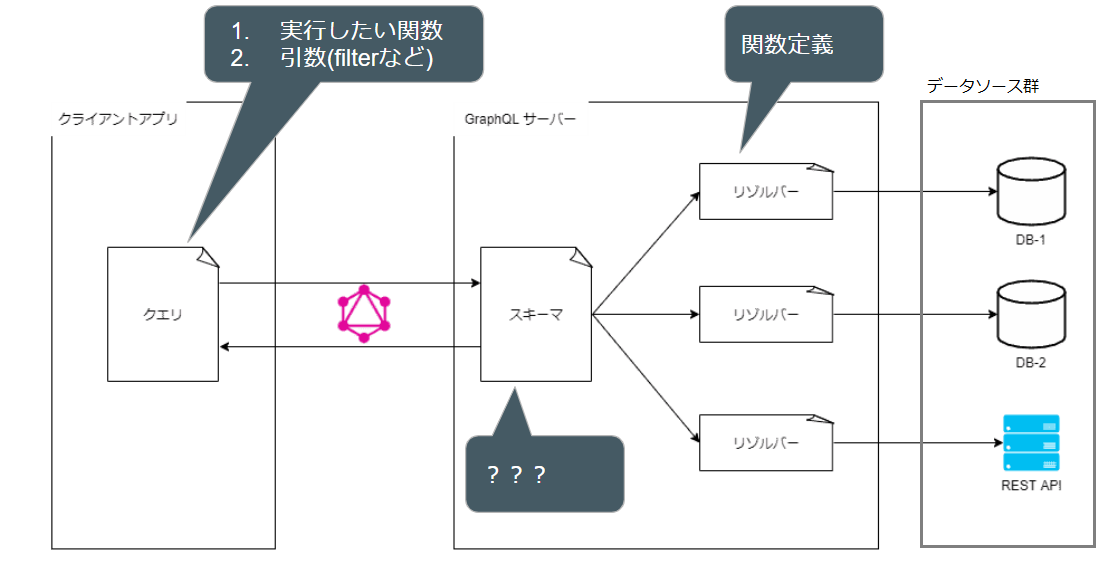
上図の通り、GraphQLは4種類のパーツで構成されます。
- データソース
- リゾルバ
- スキーマ
- クエリ
※説明の都合上、右に記載されているものから書いています
1. データソース
APIで取得(or 操作)したいデータを保管している場所です。
例えば、DBサーバー / ファイルサーバー / REST API などが挙げられます。
プログラムから操作可能な場所なら、基本的にどこでもデータソースになり得ます。
2. リゾルバ
処理を定義する場所です。
ここで定義した関数が、クライアントから呼び出されてデータソースを取得(あるいはその他操作)できるようになっています。
リゾルバに定義される関数は3種類に分けられます。
| 項目名 | 説明 | |
|---|---|---|
| 1 | クエリ | データを取得する関数群 |
| 2 | ミューテーション | データを「作成, 更新, 削除」する関数群 |
| 3 | サブスクリプション | あるテーブルを監視して、更新されたらそのデータをリアルタイムに取得する...関数群 (細かい説明は後述) |
これらはリゾルバ内で、
Query/Mutation/Subscriptionの「Value」として、メソッドを複数定義することができます。
// リゾルバのコード例(モジュールによって書き方は若干変わるので、イメージ程度に思っていただければ...)
const resolvers = {
// <クエリ>: データの取得
Query: {
books: () => {
// DBに接続してデータを取ってくる処理を書く
// ...このような処理を、仮にfetchFromDBと書き置いている
const result = fetchFromDB();
return result;
}
},
// <ミューテーション>: データの作成, 更新, 削除
Mutation: {
createBook: (_, args) => {
// argsで受け取ったデータをDBに追加する処理を書く
},
updateBook: (_, args) => {
// argsで受け取ったデータでDBを更新する処理を書く
}
},
// <サブスクリプション>: データの更新を監視
Subscription: {
subscribeBook: () => {
// pub/subと呼ばれる通信で、Bookテーブルを監視する
}
},
};
3. スキーマ
まとめてお話ししてしまうと混乱するので、後半でご説明します!
一旦忘れても問題ありません💤
4. クエリ
(図のとおり) これのみ、クライアントサイドでの処理になります。
クエリは、リゾルバで定義した関数のいずれを実行するか指定する場所になります。
ここまで理解いただければバッチリです!👍
それではGraphQLの特徴について詳しく説明していきましょう。
特徴1. エンドポイントが1つだけ
GraphQL単体ではメリットをお伝えし難いので、REST APIと比較しつつ進めていきます。
REST APIでのエンドポイント
REST APIを使ったことがある方は多いと思いますので、先にこちらをお話しします。
RESTではURLの設計に、「リソース指向」と呼ばれる設計方法がよく使われます。
具体例を見てみましょう。
データの取得
仮に、「id=2」のグループに所属する、「id=3」のユーザー情報を取得してくる場合、
RESTでは以下のようなリクエストをします。
※以降全て仮想のURLです
GET https://example.com/rest/data/v2/groups/2/users/3/infos
データの更新
同様のリソースを更新したい場合、以下のようにリクエストをします。
POST(or PUT) https://example.com/rest/data/v2/groups/2/users/3/infos
(リクエストボディ)
{
height: 180,
weight: 80
}
すなわち、REST APIは
- リソースを、URLで階層を追って指定
- その情報に対して行う操作(作成, 更新, 削除など)を HTTPメソッド で指定
という形をとります。
GraphQLでのエンドポイント
一方GraphQLでは、エンドポイントは1つです。
先ほどと同様に、
「id=2」のグループに所属する、「id=3」のユーザー情報を取得してくる
というリクエストをする場合でも、以下のエンドポイントにPOSTリクエストします。
POST https://example.com/graphql
全ての「取得」「追加/更新」「削除」で、ここに「POST」でリクエストします。
...では、どこで具体的なリソースや操作を指定するのでしょうか?
答えは簡単、**「リクエストボディ」に「クエリ」**と呼ばれる特殊な書き方をするのです!
より正確には、
- リゾルバに諸々のデータ操作を関数として定義
- クエリでどの関数を使うのか指定
といった形をとっています。
メリット
クエリの中で複数のリゾルバ関数を指定することで、1回のリクエストで「複数のリソース」を取得してくることができます。
例えば、以下のクエリをリクエストボディに詰めるイメージです。
これによって、「書籍のタイトル一覧」と「ユーザー一覧」を1回の通信で取ってくることができます。
Query hogehogeQuery {
books {
title
}
users {
name
age
height
}
}
この際、まとめて取ってこれる分、1度の通信量が増えることが懸念されます。
ところが、実は必要なデータだけを戻り値に指定できるので、むしろ通信量が減ることさえあるかもしれません。
先ほどの例だと、リゾルバではbooks関数がid, title, author, pagesなどの情報が戻り値に設定されているとします。
ですが、先のクエリの実行結果では、書籍のtitleだけがオブジェクトとして返ってくるのです。
このように戻り値を使う分のデータだけに絞って受け取ることができます。
// 戻り値の例
"hogehogeQuery": {
"data": {
"books": [
{
"title": "三国志"
},
{
"title": "徒然草"
},
{
"title": "平家物語"
},
],
"users": [
{
"name" : "ほげ太郎",
"age" : 30,
"height" : 180,
}
]
}
}
ここまでのメリットを整理すると、以下の通りです。
※REST APIと比較して...
- 1回のリクエストで複数のデータを取得することが可能
- 通信の総量は減る
→ すなわち、通信のコストパフォーマンスが良いのです!
特徴2. やりとりするデータに対して型チェックが可能
この章では、先ほど説明をスキップした「スキーマについて」説明していきます。
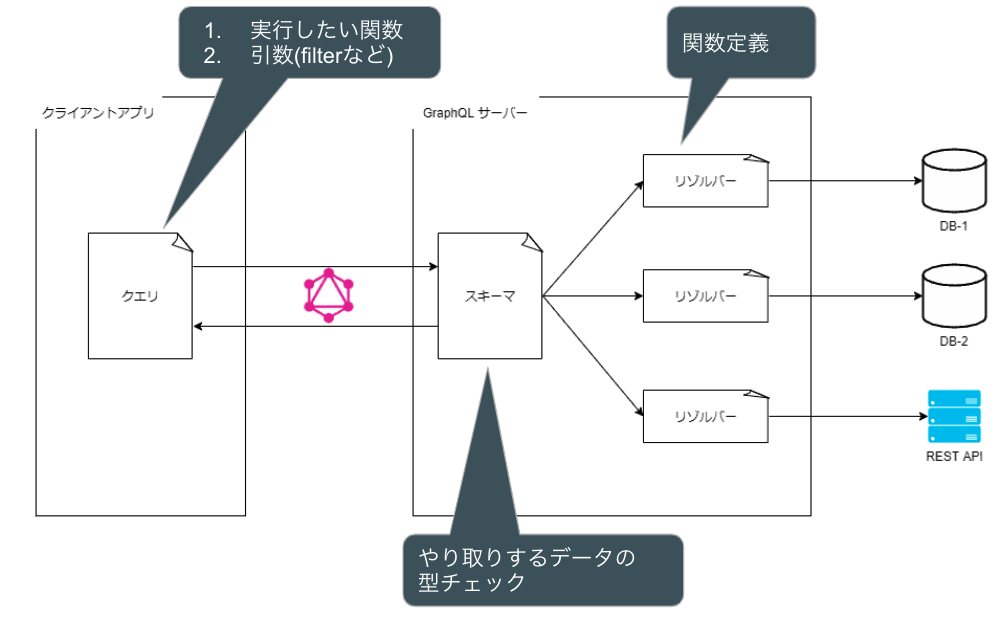
上図の通り、スキーマは「クエリとリゾルバの間」に立って型のチェックをしてくれます。
具体的には、下記のようにリゾルバの関数の「引数」と「戻り値」の型を定義します。
type Query {
books: [{
id: ID!
title: String
pages: Int
authors: [{
firstName: String
lastName: String
}]
}]
}
type Mutation {
// mutationメソッドの型
}
type Subscription {
// subscriptionメソッドの型
}
細かい型の定義は、今回取り扱いません。
簡単に説明しますと、リゾルバのbooksクエリを実行した場合...
- 戻り値は書籍の配列
- 書籍のtitleは文字列型
- 書籍のpagesは整数型
などの制限が加えられます。
また、さらに先の定義から、小さい型定義を切り出すこともできます。
type Book {
id: ID!
title: String
pages: Int
authors: [Author]
}
type Author {
firstName: String
lastName: String
}
type Query {
books: [Book]
}
type Mutation {
// mutationメソッドの型
}
type Subscription {
// subscriptionメソッドの型
}
見やすくなりましたね!(保守性も上がりました)
このように制限することで、型定義で得られるメリットを全て享受することができます。
付属ツール「GraphiQL」
スキーマを頑張って読むことで、
- リゾルバにはどういった関数があるのか
- リゾルバの関数は引数にどういったデータを取るのか
- リゾルバの関数は戻り値にどういったデータが返ってくるのか
といったことが分かります。
すなわち、このスキーマとは**「クライアントサイドとサーバーサイドの間でどういったデータをやりとりするか」を定義する仕様書**(IF仕様書)と同義なわけです。
でもこのままだと読みづらいですよね...?
大丈夫です!GraphQLのモジュールの多くには「GraphiQL」という素敵ツールが付属しています。
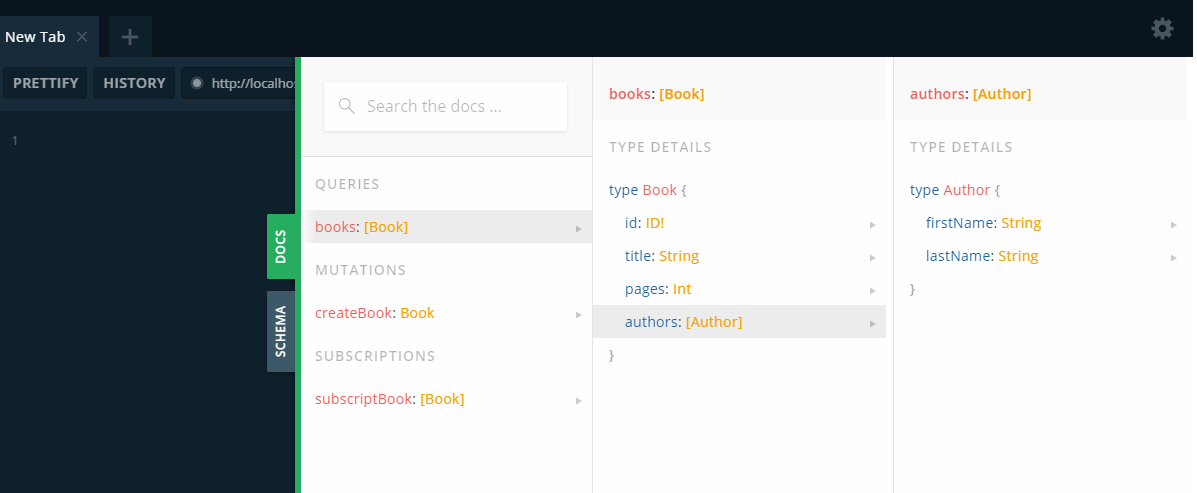
GraphiQLにアクセスすると
アクセスしやすい形で、スキーマを参照することができます。
他にも、手軽にAPIの疎通テストができるところがGoodなポイントになります。
実際に使う際には、是非活用してみてください!
特徴3. リアルタイム通信
先ほどからリゾルバ定義やスキーマ定義に出ていた「Subscription」機能のことです。
この機能は、pub/subという通信方式を用いて、情報の更新を検知・取得します。
そのため、チャットアプリのようなリアルタイム性の求められるアプリの開発などで、非常に役立ちます!
GraphQLに興味が湧いたら...
以上で、GraphQLについての全体像はご理解いただけたと思います。
実装に着手するには、具体的に手を動かしていく必要がありますので、
是非私の書いたブログもご参照いただけると嬉しいです!
GraphQL入門 その1: 仕組みを理解する / ととログ
GraphQL入門 その2: ApolloでGraphQLサーバーを立ててみる / ととログ
GraphQL入門 その3: GraphQLスキーマの書き方 part1 / ととログ
GraphQL入門 その4: GraphQLスキーマの書き方 part2 / ととログ
以上!
本記事で、皆さんが少しでもGraphQLに興味を持ってくださると幸いです🙌