目次
最近Hasuraなる最強のフレームワークを触りまして、様々感動したポイントがありました!
今回はそこから抜粋して
「migration」についてHasuraではどのように実装するのか 見ていこうと思います!
記事を読んだあと、是非Hasuraを触ってみてください😎
💁♂️ Hasura is 何?
Hasuraとは、GraphQLのAPIサーバーを10倍早く構築できる(と言われる)
ローコードなフレームワークです。
ローコードと聞いて、こんなご意見が聞こえてきそうです… ↓
🤔「migrationやseedもできないんだろ?」
🤔「自由度低くてプロダクトユースできないんだろ?」
🤔「ユーザーのアクセス制御の自由度が低いんじゃない?」
🐕 < そんなことはありません!!!
- Remote Schema
- Hasura Actions
などの機能により、めちゃめちゃ高い自由度を持たせることも可能ですし
(例えばAWS Lambdaと接続したり…)
ユーザーロールを設定してDBのレコード単位 or カラム単位での制御も可能です✨
今回お話したいことからは外れるので、詳しい説明は省かせていただきますが
お時間のある方は、チュートリアルの記事 をやっていただくとよくよく実感いただけると思います!
↓ ↓ ↓
それでは早速Hasuraを立ち上げて、migrationの挙動を見ていきましょう!
🧱 前準備(docker環境を立ち上げる)
hasura cliをPCにinstallして、hasuraとPostgresDBのDockerコンテナを立ち上げるところまでが本章でやることです。
開発にあたり「hasura cloud」を使うことで手軽に環境を用意することも可能です。
しかし、料金的にも開発体験的にも localに立てた方がメリットがありそうと感じましたので
今回は docker環境でlocal にhasuraを立てていきます。
hasura cliのinstall
以下の記事に従ってサクッとcliを入れましょう。
https://hasura.io/docs/latest/hasura-cli/install-hasura-cli/
続いて、localにhasuraが動作する上で必要なファイル群を生成します。
hasura initを実行しましょう。
$ hasura init
? Name of project directory ? hasura
INFO directory created. execute the following commands to continue:
cd hasura
hasura console
ファイル群には、Hasuraのmetadataなどが様々含まれています。
例えば「cronとバッチ処理」や「テーブル定義」「アクセス権限まわり」などです。
これに加えて「migration」や「seed」もファイル管理されています。
dockerコンテナの用意
ファイル群は用意できましたが、これだけではまだ立ち上がりません。
「hasuraの実行環境」と「接続先のPostgresDB」をコンテナで立てていくために、docker-composeします。
こちらからテキストをコピーして、docker-composeファイルを作成します。
config.yamlファイルと同じ階層に設置して、docker-compose up -dを実行してください。
以上でhasuraの実行環境は準備完了です!!🎉🎉
🧪 migrationを検証
それでは、migration周りをHasuraではどのように管理するのか 見ていきましょう!!
【手順】
- テーブル作成(カラム定義)
- この動作でmigrationファイル生成される
- migrationファイルの統合方法
- rollbackしてみる
- migrateしてみる
適当なテーブルを作成
hasura consoleを実行。
→ Hasuraの設定をいじったり、APIリクエストを試せるクライアントがブラウザで立ち上がります。
今回はテーブルを作成するので、DATAタブから Database > public をクリック
Create Tableから、テーブルを作成しましょう。
テーブルの設定値はこんな感じ ↓
(Todoアプリのイメージ)
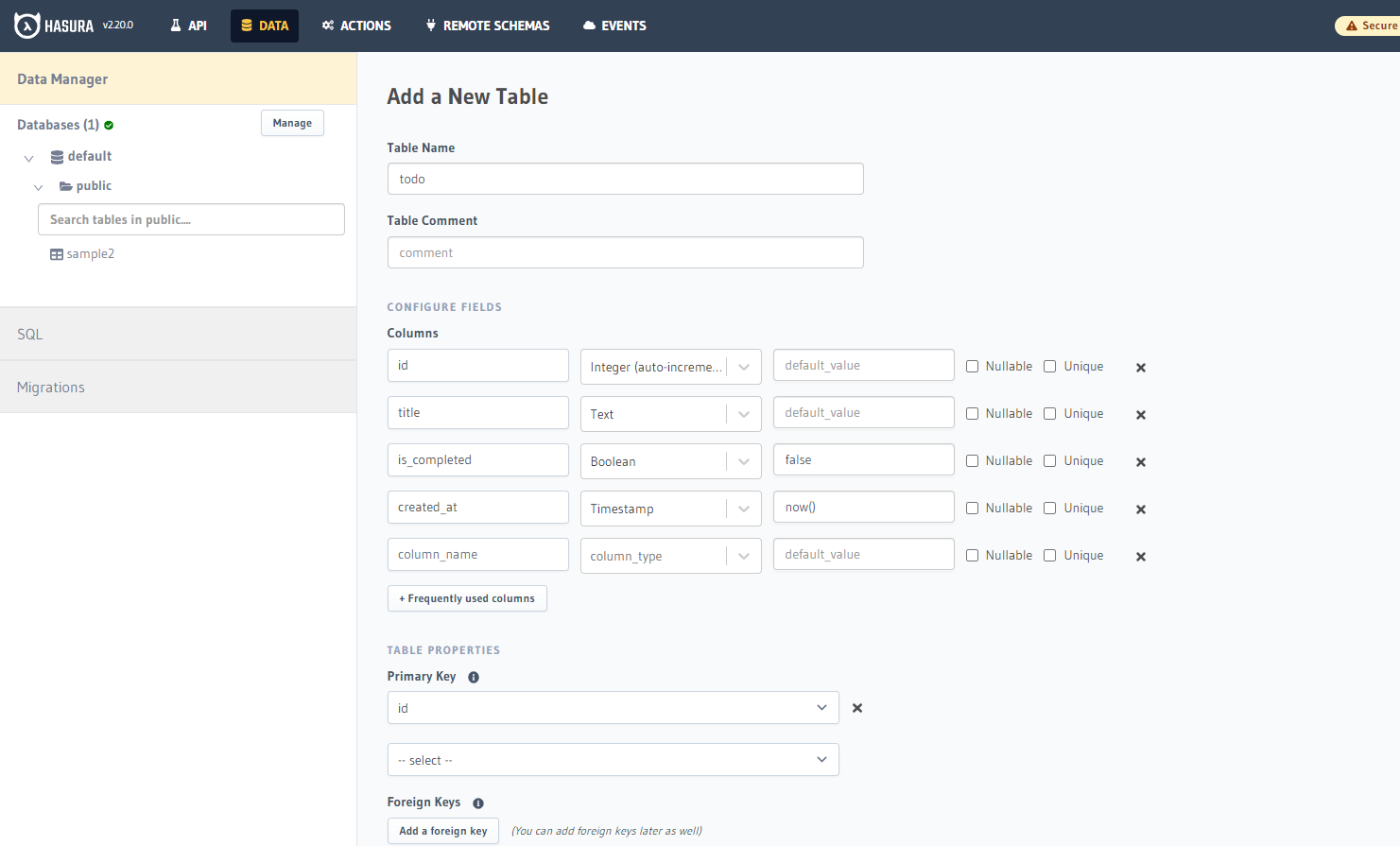
Add Tableボタンを押してください…
これでテーブル作成が完了です!!
migrationファイルは自動生成される
先のテーブル作成後にgitの差分を見ると、様々なmetadataが更新されていると思います!😇
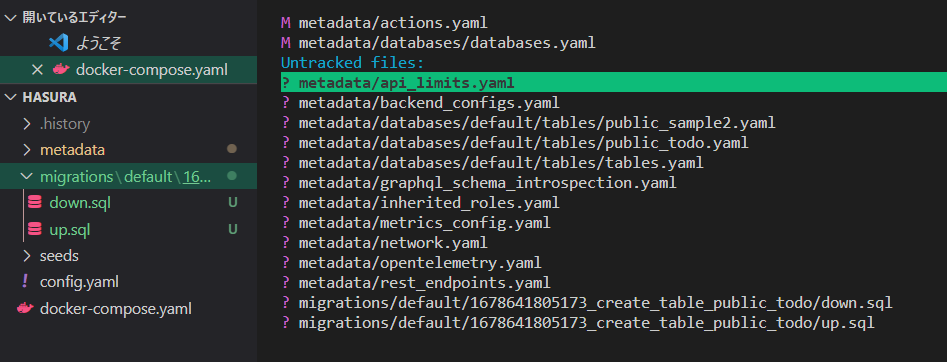
そうです!
Hasuraのconsoleからテーブルを作成・編集すると、都度migrationファイルが生成・更新されるのです!!
メインのmigrationファイルは以下の二つです。(作成と、rollback時に使用されるdownファイル)
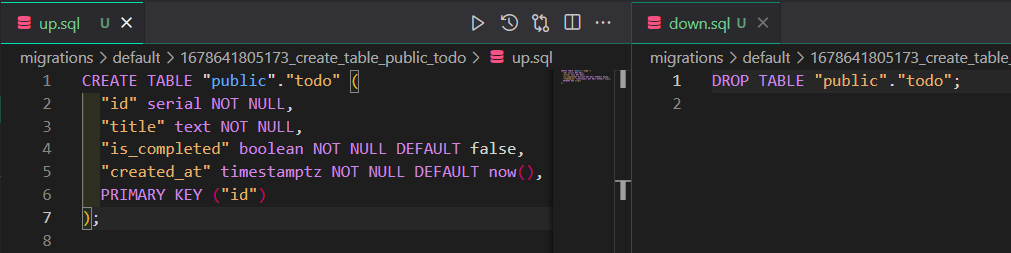
migrationのファイル命名は、UnixTimestampのmsまでと操作したテーブルやカラム名を合わせたもののようです。
Hasura consoleを使わずに、localhost:8080から諸々設定値を変更しても
metadataやmigrationファイルは変更されないことにご注意ください!
以下のイメージです。
hasura console → 開発用
localhost:8080 → プロダクト用
migrationファイルを統合する
作業時に、様々にテーブル定義をいじって検討した形跡が
毎回migrationファイルとして 多数 残るのは不本意だと思います。
試しに以下の操作をすると、ファイルがその分生成されます…
- タスクの期限
expired_atカラムを追加する(not nullable) -
expired_atをnullableに変更
※ テーブル定義の変更は、Hasura ConsoleのModifyタブからできます。
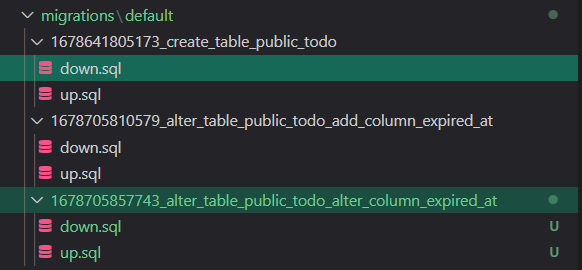
もしTodoテーブルを作成するというタスクなのであれば、Todoテーブル作成から諸々の修正は1つのmigrationにまとめるべきですよね。
以下のコマンドを実行して、migrationファイルをsquashしてみましょう!
(fromの後ろは最初のmigrationファイルのUnixTimestampに変更してください)
hasura migrate squash --name 'quashed_migration_create_todo_table' --from 1678641805173 --database-name default
すると、以下のようにこれまでのmigration文をつなぎ合わせたファイルが生成されます👍
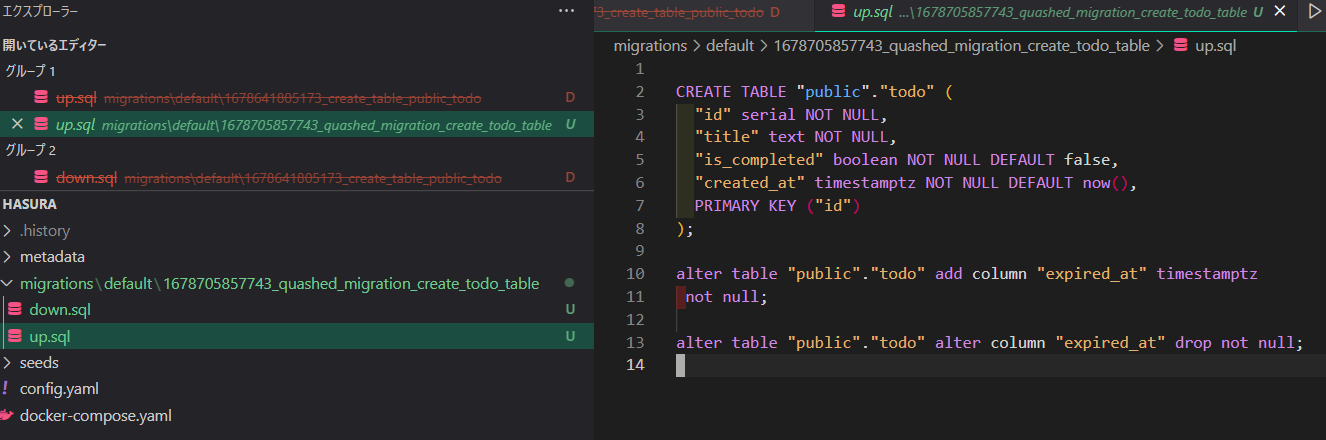
rollbackしてみる
統合前に戻すため、一度現在のテーブルの状況からmigrationを再生成してみましょう。
この状態から、新しいカラムを追加しましょう。
私は担当者のカラム、assigneeを追加しました。

ただし、このときdownのmigrationファイルは推測しきれずにコメントアウトされています。
以下のコードを追記しましょう。
alter table "public"."todo" drop column "assignee" cascade;
それでは、assigneeカラム追加直前までrollbackしてみます。
コマンドはこちら…
hasura migrate apply --down 1
※1migrationファイル分さかのぼる処理です。
Hasura Consoleでリロードして、カラムが消えていることを確認出来たらOKです。
migrateしてみる
続いて、最新の状態(assigneeがあるところ)までmigrationで持っていきます。
コマンドはシンプルです。
hasura migrate apply --database-name default
これで、カラムがまた戻っていることを確認出来たらOKです!
まとめ
以上で、Hasuraの手軽さを実感いただけたのではないでしょうか😎
ここまでで少しでも魅力を感じていただけた方は、是非チュートリアルまで進んでみてください!
さらにAPI開発が早くなること請け合いです👍
📢 「いんでぃーはっかーの集い」の宣伝
個人開発をしたり、ポートフォリオを作りたい方
毎日やっている「もくもく会」に是非いらしてください!!
アイデアレベルでも勿論OKです。
人が使ってくれるサービスになるよう、一緒に頭をひねりましょう!
私も個人開発でHasuraを使って開発中です😈