2017年7月ごろから衝動的にコンパイラを自作し始めました。2年経っても完成には程遠く、完全に自己満足の世界なのですが、誰かの為になることも書けるかも(?)知れないので日記・覚書をここにつけてみます。 いいね少なくても2年間続けられたのでいまさらですが、いいね貰えたら多少モチベ上がるかも。
Githubリポジトリ: Palanソースコード(C++)
リファレンス: Palanリファレンスv0.3
ヒストリ
プログラミング言語Palan開発日記 1年目
プログラミング言語Palan開発日記 2年目
日記
更新を楽にするため、上の方が最新です。時系列で読みたい人は下から読んでね![]()
実装中
英語リファレンス
7月7日 4年目
仕事でVue.js/Vuex/Typescript/Vuetify等を使うので、そちらの勉強に時間取られてる。これらを組み合わせてちゃんと開発しようとすると、どれも王道のはずなんだが意外と情報がなくて困る。まぁ、最新の開発を学ぶのは言語仕様を考える上での参考になる。にしても、最近のFrontend開発はたくさんの言語処理系が入り混じって、さらにそれを簡単にしようとさらにいろいろ盛沢山ですごいね。IE11の亡霊が健在で頭痛いが、、
ついに開発も4年目になったので、この日記はこれで終わります。4年目日記を立ち上げて、英語リファレンス完成させてver0.3をリリースせねば。
6月24日 v0.3リファレンス公開
Palan日本語リファレンスv0.3が大体できたのでQiitaに公開。もう少しソース改良しながらWikiの英語版リファレンス作成に移ろう。
6月18日 関数コールなし関数
先日の"狙い"の日記を書いた後、ふと気づいた。今、内部に関数コールがない関数についてはスタック変数確保のRSPの加算と減算のアセンブリを省略して最適化してたけど、ローカル変数のアクセスにRBP使うのやめてRSP使うようにすれば、PUSH/POP RBPとMOVE RSP, RBPごっそり消せるんじゃないか?・・と。 試しにやってみたら上手くいった!! なぜ今まで気付かなかった!? 気を付けないといけないのはPUSHを使わない分、6個以上の戻り値のケースなど、8byte分は調整するケースがあったぐらい。
これを入れると、Nクイーンベンチマークも1.83sぐらいになりそう。レジスタ割り付け実装直後の2.34sから大分改善してきた。
また、レジスタ割り付けでスタックに確保する変数が0個になったときも、類似の最適化できるのではないかと思っている。ただ、今のレジスタ割り付け法だと関数コールがあるとスタックに保存が必要なレジスタを使ってしまうケースがほとんどなのと、コールスタック乱して後々のデバッグで困るかもしれない予感があり、こちらの実装はあきらめた。
6月15日 狙い
先日のバクは直したけど、今度は狙っているアセンブリ出力ができていないのでちょっとモヤモヤしている。あと一歩とは思うんだけど、スマートにできる方法が思いつかない。
何をやりたいかというと、複数戻り値の時は引数と同じレジスタを使う仕様にしているので、関数呼び出しがない関数などは値の受け渡しを完全に省略したい。例えば、下記のようなコードだと
func calc(int64 a, int32 b) -> int64 a, int32 b
{
a + 1 -> a;
a + b -> b;
}
今はこんな感じに出力されてしまうが
calc:
pushq %rbp
movq %rsp, %rbp
movq %rdi, %rcx # arg -> a
movslq %esi, %rdx # arg -> b
movq %rcx, %rax # a -> %accm
incq %rax # %accm + $
movq %rax, %rcx # %accm -> a
movq %rcx, %rax # a -> %accm
addq %rdx, %rax # %accm + b
movslq %eax, %rdx # %accm -> b
movq %rcx, %rdi # a -> retval
movslq %edx, %rsi # b -> retval
popq %rbp
ret
ホントは↓までもっていきたい。
calc:
incq %rdi # a + $
addq %rdi, %rsi # b + a
ret
raxの省略は後でもいいけど、引数・戻り値等はv0.3で省略できるようにしたい。どうすればスマートに出来るんだろうか。
6月10日 複数リターン
戻り値のレジスタの実装が考えていた仕様と違ってたので、直したらバグ見つかる。
リターン値が複数のとき、前のリターン値を上書きしてしまうことがある。C言語なら戻り値1個なんでこんなことは起こらない。どこのロジックがおかしいのか今のところ不明 orz。
// 引数と戻り値を入れ替えるだけの関数
func as_is(int64 a, int32 b) -> int32 b, int64 a
{
}
s_is.ovWktncL_W:
pushq %rbp
movq %rsp, %rbp
movslq %esi, %rsi # arg -> b
# {
# 複数の戻り値の場合は、rdi/rsiレジスタを使用。
movslq %esi, %rdi # b -> retval # rdiを変数aに割り当てているのでaをbで上書いてしまう。
movq %rdi, %rsi # a -> retval
popq %rbp
ret
# }
なかなか進まないなー。
6月8日 あるある
引数渡しのレジスタ割り付け改良をやってたら、関数呼び出しの未実装見つけて、実装しようとすると設計悪いのに気づき、いつの間にかファクタリング作業している。
6月3日 引数とレジスタ
ドキュメントも書き始めてるが、それだけだとやはりモチベーションが上がらないので、結局レジスタ割り付けの改良も並行で実施中。今は割り付けるレジスタは一度も使っていないレジスタしか割り付けの対象にしなかったが、例えば引数のRDIレジスタなどはそのまま使える場合は他に変数の領域を用意して代入したりせずに、そのままRDIを変数として使ったほうがいいはず。。のような処理を追加する。これができると使えるレジスタが増えたり、関数呼び出し後のコピーが不要など、確実に速くなる。
いろいろ考えた結果、引数に絞らすレジスタがソースとなるMOVE処理を対象にした方がシンプルな設計でいける気がして、それでやってみてる。
Nクイーンベンチも、1.99sから1.90ぐらいは改善する見込み。
5月26日 配列代入
文字列リテラルでできてないところを、実装して埋めていっているが、ちょっと効率が悪い処理がある。例えば下記の場合、
[32]byte str = "abc";
本来は4バイトコピーで事足りるのだが、今はコピー先の型のものを使ってるので32バイトコピーしてしまう。これだけなら直せる気がするのだけど、将来的にはスライスというか部分配列とかを扱えるようにしたいので、今は対応せずに、そちらの仕組みを作ったときにそれを利用して実現し方がいい気がしている。とりあえず忘れないようここに覚え書き。
5月19日 ver0.3落としどころ
もうすぐ3年なので、そろそろver0.3としてのリリース準備したいところ。落としどころをどこに持っていこうか悩み中。配列を文字列リテラルで初期化するのができてないので、そこまでやると、なんとかC言語関数呼んで実用的に使えるレベルという目標は達成したことになるかな?。本来は文字列型とか作るべきなんだろうけど、まだまだ先だな。あとは、ドキュメントが一番面倒。
その他の候補は、++の実装とか、レジスタ割り付け(引数あたり)の改良とか、Docker環境かな。これらは0.4に回すかどうか。0.4の候補もモジュール化に行くか、要素数保持配列の実装に行くか迷うところ。
まだまだ趣味Toyコンパイラの領域だが、実装に使える時間もそんなに確保できないので、なるべくステップ刻んで丁寧に作って、作り直しは避けたいねぇ。
5月16日 条件文改良完了
ようやく条件文の改良ができて、きれいなアセンブリが出力できるようになった。なぜか設計もすごくスッキリした。前はコメントで想定パターンしっかり書かないと何やってるかわからないレベルだったが、そんなの無くても自然にわかるコードになった気がする。
最近こんなん多いな。
次何しようかな。Docker化見越してディレクトリ構成の見直ししようか。今動いてるCIが壊れそうなのでなかなかやる気になれなかったが、今のキリの良さならいける気がする。
5月11日 改良結果
まだNot文が完全にはできてないが、パフォーマンスが上がってるか確認。ジャンプしすぎで遅くなっていた部分が大分マシになった。まだまだO1には遠い。
| 改良前 | 改良後 | gcc -O0 | gcc -O1 | gcc -O2 | |
|---|---|---|---|---|---|
| Nクイーン(13) | 2.34s | 1.99s | 2.78s | 1.35s | 1.19s |
アセンブリは狙ったとおり修正されている。
movq %r9, %rax # col -> %accm
subq %rcx, %rax # %accm - j
incq %rax # %accm + $
cmpq $0, %rax # %accm > $
jle .L12 # jump if cmp is false
movq %r8, %rax # i -> %accm
imulq $13, %rax # %accm * $
movq %rax, %r13 # %accm -> (temp@add)
movq %r9, %rax # col -> %accm
subq %rcx, %rax # %accm - j
addq %r13, %rax # %accm + (temp@add)
movq %r10, %rbx # board -> base
movq %rax, %rdi # %accm -> index
movslq (%rbx,%rdi,4), %rax # board[] -> %accm
cmpq $0, %rax # %accm != $
je .L12 # jump if cmp is false
# {
movq $1, %rax # $ -> return
movq -8(%rbp), %rbx # restore reg
movq -16(%rbp), %r12 # restore reg
movq -24(%rbp), %r13 # restore reg
popq %rbp
ret
# }
.balign 2
.L12: # end if
5月7日 条件反転
条件反転は通常 !(A&&B) → !A||!Bなんだけど、実はこれをC系の言語では全くイコールではない。!(func1()&&func2())だと、func1()が偽のときはfunc2()は呼ばれないけど、!func1() || !func2()だと、func1()が偽でもfunc2()が呼ばれてしまう。というわけで、And/Or文のNotをとるときには、この変換は使えない。ややこしい。
5月6日 Not
And/Or分まで修正がなんとか終わった。後はNot文の修正。これが意外とややこしい。単純に0と1を反転させていたのでは余計な処理で遅くなってしまう。やはり本筋の設計は条件自体の反転となるので、結構頭を使わないといけない。
4月28日 スローペース
のろのろ条件文修正中。今度の設計ならいける気がしてきた。速くなるといいな。
4月15日 条件文再設計中
うーん。最初の設計しくじった。ほぼ作り直しかな。orz
4月3日 条件文速度改良
先日のパフォーマンス解析で分かった条件演算子がボトルネックのところを直すことに着手したい。チェックに使ったNQueen問題では、下記のところがgccの最適化ありに比べてすごく遅いようだ。
if 0 < col - j + 1 && board[i,col-j] {return 1}
↓該当箇所の現在のアセンブリ。日本語でボトルネックのポイントを追記している。さて、今のままでも結構複雑な処理で頭が追い付かないのに、上手く改良できるのか。
movq %r9, %rax # col -> %accm
subq %rcx, %rax # %accm - j
incq %rax # %accm + $
movq %rax, %r10 # %accm -> (temp) # 冗長な一時変数
movq $0, %rax # $ -> %accm
cmp %r10, %rax # %accm == (temp)
jge .L12 # && # ここですぐ抜けた方がいい
movq %r8, %rax # i -> %accm
imulq $13, %rax # %accm * $
movq %rax, %r10 # %accm -> (temp@add)
movq %r9, %rax # col -> %accm
subq %rcx, %rax # %accm - j
addq %r10, %rax # %accm + (temp@add)
movq %r12, %rbx # board -> base
movq %rax, %rdi # %accm -> index
movslq (%rbx,%rdi,4), %rax # board[] -> %accm
cmpq $0, %rax # %accm == $
jmp .L13 # ここですぐ抜けた方がいい
.balign 2
.L12: # 真偽値を代入するための処理、if文のときは不要のはず
setl %al # cmpflg -> %accm # 同じく不要
movzbq %al, %rax# 不要
cmpq $0, %rax # %accm != 0# 不要
.L13: # end && # 不要
je .L14 # if # 不要
# {
movq $1, %rax # $ -> return
movq -8(%rbp), %rbx # restore reg
movq -16(%rbp), %r12 # restore reg
movq -24(%rbp), %r13 # restore reg
popq %rbp
ret
# }
.balign 2
.L14: # end if
3月28日 codecov
coveralls復活の兆しがないので、不本意ながらcodecov使ってみた。UIの見た目はいかにも現代的なんだけど、どちらかというと見た目重視でかゆいところに手が届かない。例えば、カバレッジのグラフも見た目はいいんだが、100%近いプロジェクトでは、ただの緑の円。
palanはほぼカバレッジカバー満たしたあと、今は追加コードと既存コードの差分の細かいところだけを集中的に見ればいい段階なので、その場合は全体的な情報はあまり役に立たない。まじめにテストでカバレッジキープしてるプロジェクトにはcodecovは合わないのかも。
また、通っていないラインもほぼAssert文でノイズなので、除きたいのだかその機能がない。AssertをOFFにするのも違う気がする。C++の制限なのか、何回ラインを通ったかもわからない。coveralls並みの細かい数値が欲しい。
Coverallsは機能的にはいいんだけど、サポートの悪さとデザインのくせの強さでユーザーが離れてしまったかな。もったいない。
3月22日 継続
ある程度できたので、カバレッジ見つつ細かいところを直そうと思ったが、coverallsへのアップロードがsslのハンドシェイクエラーで失敗してチェックできない。並び替えのバグもいくつか報告されてるのに放置されてる。coverallsは最近サポート放置気味で最近やる気失ってるのが見えて悲しくなってくるな。C++で数えたくないラインを除くことができたので重宝してるんだが、このままサービスがフェードアウトしそう。一度成功してもサービスを継続していくのは難しい世の中だね。でも、いまさらcodecovに移るのもなんかやだなー。
3月9日 sqlite3
まだ途中だが、ポインタのポインタを扱えるようになったので、これでsqlite3を使えるようになったかサンプルコードを書いてみた。ちょっとAPI定義調べるのに時間がかかった。まぁ、使えないことはないかなー。
// std C lib
type FILE;
type c_str = [?]byte;
ccall printf(@c_str format, ...) -> int32;
ccall strlen(@c_str str) -> int64;
ccall exit(int32 status);
// sqlite3 API
type sqlite3;
type sqlite3_stmt;
ccall sqlite3_open(@c_str filename => sqlite3 db>>) -> int32:sqlite3;
ccall sqlite3_close(sqlite3 >>db) -> int32;
ccall sqlite3_errmsg(@sqlite3 db) -> @[?]byte;
ccall sqlite3_prepare_v2(@sqlite3 db, @c_str sql, int32 nbyte, @, int64 tail_dummy=0 => sqlite3_stmt stmt>>) -> int32;
ccall sqlite3_bind_int(@sqlite3_stmt stmt, int32 ind, int32 val) -> int32;
ccall sqlite3_bind_text(@sqlite3_stmt stmt, int32 ind, @c_str str, int32 len, int64 destructor_type) -> int32;
ccall sqlite3_step(@sqlite3_stmt stmt) -> int32;
ccall sqlite3_column_int(@sqlite3_stmt stmt, int32 icol) -> int32;
ccall sqlite3_column_text(@sqlite3_stmt stmt, int32 icol) -> c_str;
ccall sqlite3_reset(@sqlite3_stmt stmt) -> int32;
ccall sqlite3_finalize(@sqlite3_stmt >>stmt) -> int32;
const SQLITE_OK = 0;
const SQLITE_NG = 1;
const SQLITE_ROW = 100;
const SQLITE_DONE = 101;
const SQLITE_STATIC = 0;
const SQLITE_TRANSIENT = -1;
// DBのオープン + テーブル作成
sqlite3 db;
sqlite3_open(":memory:" =>> db) -> check(db, "open db");
{
sqlite3_stmt tbl_stmt;
sqlite3_prepare_v2(db,
"CREATE TABLE fruits ("
" id INTEGER PRIMARY KEY,"
" name TEXT NOT NULL"
");",
-1, 0 =>> tbl_stmt)
-> check(db, "table sql");
tbl_stmt->sqlite3_step() -> check(db, "create tbl");
tbl_stmt->>sqlite3_finalize() -> check(db, "finalize");
}
// データの挿入
{
sqlite3_stmt ins_stmt;
@c_str ins_sql = "INSERT INTO fruits VALUES(?, ?);";
sqlite3_prepare_v2(db, ins_sql, -1, 0 =>> ins_stmt) -> check(db, "insert sql");
const NUM = 2;
[NUM]@c_str fruits = ["apple", "orange"];
i=0;
while i<NUM {
sqlite3_bind_int(ins_stmt, 1, i) -> check(db, "bind int");
sqlite3_bind_text(ins_stmt, 2, fruits[i], strlen(fruits[i]), SQLITE_STATIC) -> check(db, "bind txt");
ins_stmt->sqlite3_step() -> check(db, "insert dat");
ins_stmt->sqlite3_reset();
i + 1 -> i;
}
ins_stmt->>sqlite3_finalize() -> check(db, "finalize");
}
// データの表示
{
sqlite3_stmt sel_stmt;
@c_str sel_sql = "SELECT * FROM fruits;";
sqlite3_prepare_v2(db, sel_sql, -1, 0 =>> sel_stmt) -> check(db, "select sql");
int32 rc;
while (sel_stmt->sqlite3_step()->rc) == SQLITE_ROW {
id = (sel_stmt -> sqlite3_column_int(0));
printf("%d: %d\n", id, sqlite_column_text(sel_stmt, 1));
}
rc -> check(db, "select all");
sel_stmt->>sqlite3_finalize() -> check(db, "finalize");
}
db->>sqlite3_close();
// 戻り値簡易チェック
func check(int32 ret_val, @sqlite3 db, @c_str method) {
if ret_val != SQLITE_OK && ret_val != SQLITE_DONE {
printf("%s error: %s\n", method, sqlite3_errmsg(db));
exit(1);
}
}
以下、気になる箇所メモ
- 関数宣言で、デフォルト引数とプレースホルダが重なると、うまく動いてない? 引数省略すると関数が引けない。
- リファレンスの配列で要素数省略するとassertionで落ちる。あと、配列要素数を取得する手段が欲しい。
- コールバックが使えない。
- やっぱり関数を別名にできるようしてsqlite3_を省略できた方がスマートな気がする。
- ポインタのポインタでNULLを指定できるところをどうするか。今はint64で回避。デフォルト引数ができればいいかもしれない。
- 引数なので仕方ないが、dbやstmtなどは変数初期化時に割り当てたい。
2月27日 コーディング欲
最近、仕事でコーディングしてコーディング欲が満たされたせいか、こちらの開発の進捗が悪い。でも、止まってしまったら、また動き始めるのにかなりのエネルギーがいる気がするので、毎日数行だけでも進めるようにしている。
2月18日 ポインタのポインタ
strtolとかsqliteのDBオープンなどを使えるようにポインタのポインタ引数を実装しようとしてるんだけど、意外に仕様がなかなか決まらない。
strtolはリファレンス、sqliteはmoveの書き込みで対応しようとしてるんだけど、いまいち文法がしっくりこないんだよな。特にリファレンスの方。null安全に似た文法を考えてるんだが、間違うと後で困ってやり直すことになりそう。
2月11日 ボトルネック
C互換性強化を進めてみるも、先のNクイーンのgcc -O1の1.35sにどこで届いてないのか分からずモヤモヤしてた。気になって手動でアセンブリを直して小手先の最適化をしてみても、あまり改善せず、2.0sの壁をなかなか越えられなかったのだ。
でも、今日やっと見つけたよ。if文の中で使う条件演算&&のアセンブリが悪かった。無駄なジャンプや無駄な一時変数を使ってる箇所。ここを直すと、一気に1.2sを達成して、ようやく-O1を超えられることがわかった。ここ、たまたま一番通る箇所なのもあると思うが、ほとんどメモリ触ってないのにそんなにボトルネックになってたとは。。高速化を次トライする際はレジスタ割付け強化しようかと思ってたけど、まずは条件演算の出力アセンブリをきれいすることからだな。
次に大きそうなボトルネックがプリフェッチと感じた。今回の0.2sぐらいはココと思う。インテルCPUの場合、条件ジャンプ先のラベルが進む先にある場合、ジャンプしない前提で先読み、逆にもどるジャンプの場合は戻ったラベルから先読みするようだ。つまり、よく通るメインロジックのコードは一続きに出来るだけ並べて、たまに通る分岐のコードはメインロジックの外に出すと速くなるようだ。これは構造化プログラムと微妙に相性悪くて、難しそう。
2月7日 gccの背中
見えてきたような気もするが、まだまだ遠いなー。
| palan | gcc -O0 | gcc -O1 | gcc -O2 | |
|---|---|---|---|---|
| フェボナッチ(40) | 0.76s | 0.96s | 0.96s | 0.59s |
| Nクイーン(13) | 2.34s | 2.78s | 1.35s | 1.19s |
2月6日 最適化で遅くなる
小手先で最適化したら少しマシになるかと思い、あれこれ試すが少し速くなったり遅くなったりよくわからず困惑してた。今度は明らかに不要なアセンブリコードを削除したら逆に遅くなった。ん?と思いnopを付けたら速くなってやっと気づいたよ。
コードのアラインメントも考えないといけなかったのか!理由を調べたら、アラインしないとCPUのプリフェッチで問題がでるらしい。なるほど、ジャンプするとそれまで先読みしてたコードを捨てることになって、ジャンプ先のコードを読もうとしたときに、メモリ番地のきりが悪いとすぐに処理できないということ?
ただ何でもラベルの前でアラインすればいいわけでもないみたいだ。結局、関数のラベルの前だけで16バイトアラインするのが一番速かった。
たったこれだけで5%もパフォーマンスが変わった。これは大きい。全然知らなかった。
むむむ、あれ?今まで最適化で速くなったと思った事があったのも、アラインがたまたま合っただけだったとかもありそうだな。。まだ、試してみてるが、どうもこのプリフェッチとアラインの影響の予測がたたない。命令の長さが変わる最適化をすると、プリフェッチの効率を悪くして逆に遅くなる事も多い気がする。
2月3日 コスト対効果
レジスタの保存場所の最適化がようやくできるようになった。ほとんどのケースでは効果がない割に、かなりのコード量になってしまったのでコスト対効果は悪い。
ただそれよりも、今回の簡易レジスタ割付けを適用した際に、パフォーマンスが落ちるケースがなくなったというのは、この簡易レジスタ割付けをデフォルトにできるという意味で大きい。アルゴリズム的にもコンパイル速度への影響も少ないと思う。
まだ、ここダメだなぁという部分はあるが、恐らく大体のケースでgccの最適化無しよりは速くなったのではと考えてるが、甘いかな?
これ、マージしたらC互換性強化に戻ろう。
1月28日 停止性問題
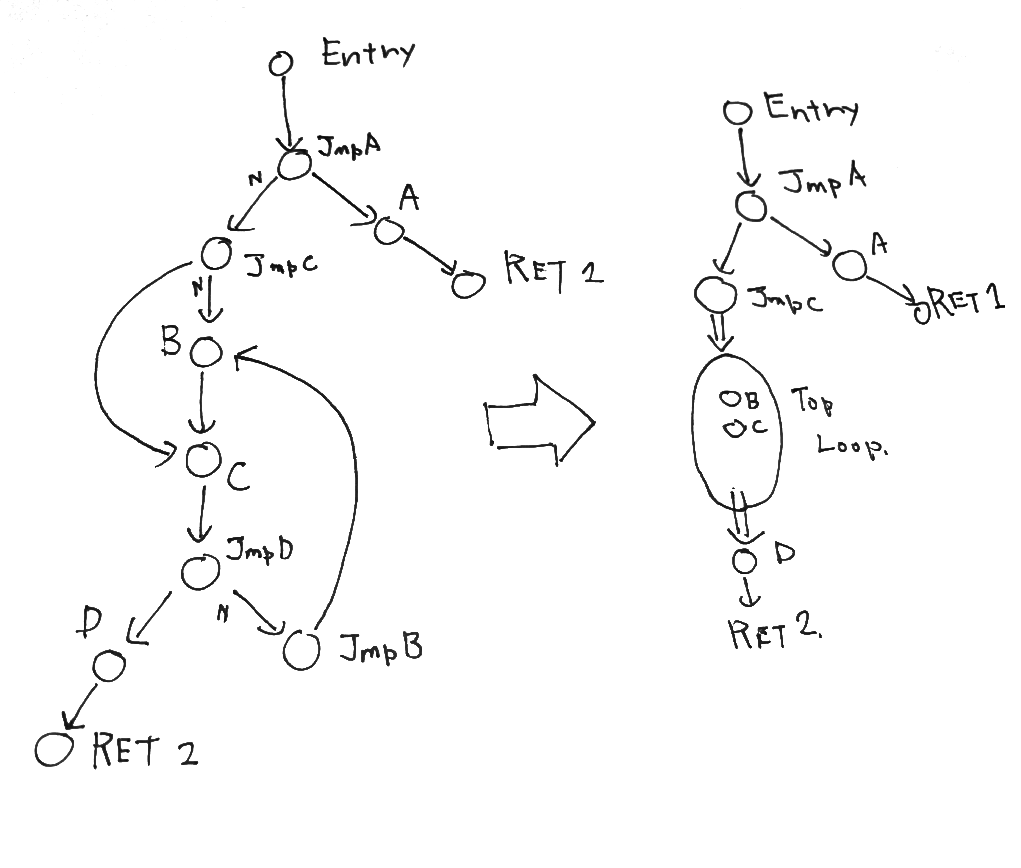
制御フローグラフ(CFG)の構築自体は簡単なので、ちょっと作って、そのグラフそのまま使って上手いことレジスタの影響を伝播できないかと思ったが、ループが絡むとなかなか難しい。自己流でやるとスタックオーバーフローなのか謎のbad-allocが発生。その辺りの伝播方法や依存の検出方法が書いてあるWebページも見つけらない。なんか停止性問題解いてる感覚になってきたのでCFGそのままの解析は諦めたい。
結局、先日思いついたツリーへの変換が現実解なのかもしれない。基本的な考えはそんな難しくなく、あるブロックに直接到達する二つ以上のブロックがあるなら、一つになるまでブロック同士を結合していくだけ。割と早く収束しそうだし。
たまに最適でないツリーができる可能性はあるかもだけど、動かないコードにはならないんじゃないかと思ってる。
競技プログラマならあっという間なんだろうなぁ。
1月25日 用語
レジスタ保存位置の最適化がググっても全然見つからないので、自力であれこれ考えてた。そして、ラベルを起点、ジャンプを終点、リターンを葉とするノードのグラフ作って、うまい具合に単純なツリーに変換できれば、できるんちゃうかと思いついた。
そうしてから、またググると、ようやく制御フローグラフとか基本ブロックと用語がヒットして、その用語を使うとそれっぽい情報が引っかかり始めた。やっぱり同じようなこと考えるんやね。でも用語を知ってるって大事。知らないと検索もできない。
まぁ、結局ズバリのは見つかってないけど、それらを参考に自分流でやってみよう。
思いついたやつ↓
1月20日 虫の跡
構造変えてカバレッジ下がったので、ローカルでカバレッジ見ながらテスト埋めて、コード通ったと思ってプッシュ。そしたらCIでテスト成功するもCIのカバレッジみるとコードが通らないところがでてるよ。これ、絶対どこかにバグ![]() が潜んでるパターンや。。しかも超わかりにくいやつ。。
が潜んでるパターンや。。しかも超わかりにくいやつ。。
2020/1/21 ・・っと思ったが割と簡単に見つかった。グローバル変数対応時に追加したメンバの初期化忘れだった。そもそもこのメンバ不要かもしれん。
1月15日 コスト
rbx, r12-r15レジスタは関数呼び出しで破壊されない代わりに、使う際はデータを保存して、戻る際は復帰しないといけない。わかってきたのが、このコストをちゃんと考えておかないとメモリをレジスタに置き換えたからといって確実に速くなるわけではないということ。
アクセス回数が低いメモリにはこれらを割り当てないようにすることは考えてるけど、例えばif文で足切りしてすぐに戻るようなコードのことは検討できてなかった。
今は単純に、関数の最初で全部保存、リターン時に全部復帰してるので、足切りのリターンまでにr12等のレジスタを使う処理がない場合は、この保存、復帰処理が無駄になり、逆にかなり遅くなってしまう。
レジスタ使うケースがないリターンの場合は、保存、復帰を後ろに持ってきたいんだけど、どうすれば実現できるんだこれ。わからん。
1月13日 副産物
アセンブリ生成のリファクタリングが成功し、複雑なif文が単純なswitch文となり、未実装のパターンの検出と追加が楽になった。浮動小数点の汎用レジスタ割り付け版のテストも動き始めた。ようやく前に進めるよー。
いつも思うが最初からこう書けてれば楽だったのに、、。でも、アセンブリ生成のコードが読むのが難しくて何とかできないかなと思っていたのが、今回、レジスタ割り付け実装の副産物で解決でき、メンテナンス可能なコードに出来たので、レジスタ割り付け挑戦してよかった。
これからレジスタ割り付けのコードをブラッシュアップして、きりがいいとこまで仕上げたい。
1月10日 Simplify
汎用レジスタに少数点割り付けたら、さらに複雑になるなーとか思いつつ、いろいろ比較演算の生成処理見直してたら気づいてしまった。算術演算と同じように左辺をアキュームレータに入れることを必須としたら、パターンが数分の一にシンプルになるやん。。何でこんなに超複雑にしてたのか。。なんか、アセンブリの命令のいろんな仕様に惑わされてたな。
Simple is Best!
1月8日 Complex Comp
生成パターンを整理したおかげで、MOVEと算術演算については、単純化できるメドはついた。コードは増えるが、複雑さをコントロールできてる感が出てきた。
ただ、比較演算について完全に忘れてた。こっちはアカン。
パターンがさらに複雑で、場合によっては右左逆転させたりしてるし、同じようにできる気がしない。よくこんなの書けたな。さて、どうしようか。。
1月4日 MOVE
あってるかわからないが、自分なりにMOVEのアセンブリ生成パターンをまとめてみた。
こういう情報って意外とないんだよね。記法は省略しているが下記のような感じ。
xmm8f: ベクタレジスタ(8byte浮動小数点)
これを使えば、今まで組み合わせ爆発気味の複雑なif文生成処理を単純なマップの処理にできるかもしれない。
float -> float
1. xmm8f->xmm8f: MOVSD
2. xmm8f->mem8f: MOVSD
3. xmm8f->reg8f: MOVQ
4. xmm8f->xmm4f: CVTSD2SS
5. xmm8f->mem4f: CVTSD2SS(X11) + MOVSS
6. xmm8f->reg4f: CVTSD2SS(X11) + MOVQ
1. xmm4f->xmm4f: MOVSS
2. xmm4f->mem4f: MOVSS
3. xmm4f->reg4f: MOVQ
4. xmm4f->xmm8f: CVTSS2SD
5. xmm4f->mem8f: CVTSS2SD(X11) + MOVSD
6. xmm4f->reg8f: CVTSS2SD(X11) + MOVQ
1. mem8f->xmm8f: MOVSD
2. mem8f->mem8f: MOVQ(R11) + MOVQ
3. mem8f->reg8f: MOVQ
4. mem8f->xmm4f: MOVSD(X11) + CVTSD2SS
5. mem8f->mem4f: MOVSD(X11) + CVTSD2SS(X11) + MOVSS
6. mem8f->reg4f: MOVSD(X11) + CVTSD2SS(X11) + MOVQ
1. mem4f->xmm8f: MOVSS(X11) + CVTSS2SD
2. mem4f->mem8f: MOVSS(X11) + CVTSS2SD(X11) + MOVSD
3. mem4f->reg8f: MOVSS(X11) + CVTSS2SD(X11) + MOVQ
4. mem4f->xmm4f: MOVSS
5. mem4f->mem4f: MOVL(R11) + MOVL
6. mem4f->reg4f: MOVSD(X11) + CVTSD2SS(X11) + MOVQ
1. reg8f->xmm8f: MOVQ
2. reg8f->mem8f: MOVQ
3. reg8f->reg8f: MOVQ
4. reg8f->xmm4f: MOVQ(X11) + CVTSD2SS
5. reg8f->reg4f: MOVQ(X11) + CVTSD2SS(X11) + MOVQ
6. reg8f->mem4f: MOVQ(X11) + CVTSD2SS(X11) + MOVSS
1. reg4f->xmm4f: MOVQ
2. reg4f->mem4f: MOVL
3. reg4f->reg4f: MOVQ
4. reg4f->xmm8f: MOVQ(X11) + CVTSS2SD
5. reg4f->mem8f: MOVQ(X11) + CVTSS2SD(X11) + MOVQ
6. reg4f->reg8f: MOVQ(X11) + CVTSS2SD(X11) + MOVQ
float -> integer
1. xmm8f->memNi: CVTTSD2SI(R11) + MOVn
2. xmm8f->regNi: CVTTSD2SI
3. xmm4f->memNi: CVTTSS2SI(R11) + MOVn
4. xmm4f->regNi: CVTTSD2SI
1. mem8f->memNi: MOVSD(X11) + CVTTSD2SI(R11) + MOVn
2. mem8f->regNi: MOVSD(X11) + CVTTSD2SI
3. mem4f->memNi: MOVSS(X11) + CVTTSS2SI(R11) + MOVn
4. mem4f->regNi: MOVSS(X11) + CVTTSS2SI
1. reg8f->memNi: MOVQ(X11) + CVTTSD2SI(R11) + MOVn
2. reg8f->regNi: MOVQ(X11) + CVTTSD2SI
3. reg4f->memNi: MOVQ(X11) + CVTTSS2SI(R11) + MOVn
4. reg4f->regNi: MOVQ(X11) + CVTTSS2SI
integer -> float
1. memNi->xmm8f: MOVn(R11) + CVTSI2SD
2. memNi->mem8f: MOVn(R11) + CVTSI2SD(X11) + MOVSD
3. memNi->reg8f: MOVn(R11) + CVTSI2SD(X11) + MOVQ
4. memNi->xmm4f: MOVn(R11) + CVTSI2SS
5. memNi->mem4f: MOVn(R11) + CVTSI2SS(X11) + MOVSS
6. memNi->reg4f: MOVn(R11) + CVTSI2SS(X11) + MOVQ
1. regNi->xmm8f: CVTSI2SD
2. regNi->mem8f: CVTSI2SD(X11) + MOVSD
3. regNi->reg8f: CVTSI2SD(X11) + MOVQ
4. regNi->xmm4f: CVTSI2SS
5. regNi->mem4f: CVTSI2SS(X11) + MOVSS
6. regNi->reg4f: CVTSI2SS(X11) + MOVQ
integer -> integer
1. memNi->regNi: MOVn
2. memNi->memNi: MOVn(R11) + MOVn
3. regNi->memNi: MOVn
4. regNi->regNi: MOVn
1月3日 再整理
レジスタ割り付けを実装し始めたが、浮動小数点を汎用レジスタに割り付けたところで、アセンブリ生成が追従できずに詰まる。moveの組み合わせ爆発が更に広がるので、一旦整理しないとコードも修正できる気がしない。
しばらくパターン再整理作業かな。
12月26日 機微
レジスタ割り付けを簡易実装して評価してみたが、思ったほど効果がでないのでgccのアセンブリと再度にらめっこ。どうも加算時の前後問題や戻り値渡しの影響が大きいようだ。これはソースコード修正レベルで解決できるので直してみた。
↓これを
func fib(int64 n) -> int64 n
{
if n < 2 { return }
fib(n-2) + fib(n-1) -> n;
}
↓こう直すだけで
func fib(int64 n) -> int64 n
{
if n < 2 { return }
m = fib(n-2);
return fib(n-1) + m;
}
加算+返却部分のアセンブリは、↓これから
call fib.keNHAQKS.O
movq %rax, -24(%rbp) # return -> (temp@add)
movq -32(%rbp), %rax # return(save-%accm) -> %accm
addq -24(%rbp), %rax # %accm + (temp@add)
movq %rax, -8(%rbp) # %accm -> n
movq -8(%rbp), %rax # n -> return
↓こうなる。
call fib.keNHAQKS.O
addq -16(%rbp), %rax # %accm + m
これでgcc -O0同等だろうと計測するが、、なぜか勝てない。何か違うのかと思いさらににらめっこすると、gccの方は関数戻り時にleaveを使っておらず、スタックポインタを足し戻してる。試しにやってみた。↓これを
leave
ret
↓こうする。すると、、
addq $32, %rsp
popq %rbp
ret
速くなった! ようやくgcc -O0超えできたっぽい。
なるほど、フェボナッチは関数呼びまくるから、この違いがもろに効いてくるのか。高速化の機微に触れた気がする。
12月25日 無知道
C言語は広域変数はどうも変数とは別にフラグをグローバルに確保して初期化したかどうかを判断しているみたいだった。それだけでなくスレッドも考慮して排他ロックなども考える必要もあるみたいでなかなか深く、externのおまけの実装は諦めた。
最近アドベントカレンダーの言語実装を見てみたりするが、自分は理論なしでやってるので無知を実感してみたりしてる12月。
刺激を受けて何気にフェボナッチで速度測ってみたらgccの最適化無しに30%ほど負けてしまって少しショック。速いとは言わないまでもgcc最適化無しと同等ぐらいかなぁと思ってたのに。
アセンブリで比較するとレジスタ割り付け分で負けているような気がするので、次は前からやってみたかったレジスタ割り付けにトライしてみようかな。
一応、そこを見越して実装はしているので下地はできてるはず。グラフ彩色とかは、よくわからないし、何となく遅そうなので、また独自理論になりそうだが。まぁ無知のまま進むのもそれはそれで面白い。
12月23日 広域変数
stderr等の標準Cライブラリのグローバル変数を使うため、externを実装。浮動小数点リテラル時に土台ができてたので、割と簡単にできた。
ついでに広域変数static等も簡単にできないかなと思ったが、初期化の仕組みに悩む。ん?CとかC++ってどうなってんだっけ?
初期化前か初期化後かはどこで判断してるんだろうか。。勉強不足が露呈。
12月19日 読み取り専用構造体
オブジェクトメンバーを持たないとの制限付きだけど、読み取り専用領域に構造体を配置できるようになった。リファレンス等で直接参照できる。
type A { int32 i; int64 l; flo32 f; }
type B { int32 i; int64 l; };
type C { int64 l; flo32 f; };
@A a = [1,2,1.23];
@B b = [1,2];
@C c = [2,1.23];
生成されるアセンブリは以下のようになり、ある程度、同じ値も共有される。
movq $.LC0, %r11
movq %r11, -8(%rbp) # [1,2,1.23] -> a
movq $.LC0, %r11
movq %r11, -16(%rbp) # [1,2] -> b
movq $.LC1, %r11
movq %r11, -24(%rbp) # [2,1.23] -> c
~
.align 8
.LC0:
.long 1
.align 8
.LC1:
.quad 2
.long 1067282596 # 1.230000
将来的には読み取りオブジェクトのリンクまで読み取り領域に配置できるようにしたいな。そこまでやっている言語は知らないが。
12月12日 配列宣言
配列の宣言の仕様を修正した。これまでは下記のようにJava/C#風?だった。
int64[2,2] arr = [1,2][3,4];
byte[10] str = "12345"; // コピー
byte[10]@ strref = "12345"; // RO領域への参照
byte[2][10]@ strs = ["abc", "efg"]; // リファレンスの配列
↓のようにgo風に変えた。
[2,2]int64 arr = [1,2][3,4];
[10]byte str = "12345"; // コピー
@[10]byte strref = "12345"; // RO領域への参照
[2]@[10]byte strs = ["abc", "efg"]; // リファレンスの配列
とくにリファレンスと配列の関係性が明確になったと思う。単純に後ろから読んでいけばわかるはず。strsでいうと「byteの配列(10)の参照の配列(2)」とそのまま読める。上のJava/C#風だと混乱する。今度こそ、この仕様は変えないと思う。
今回もパーサーを作り直したが、コンフリクトにはほとんどハマらなかった。慣れとは偉大だな。それより仕様変更によるテストコード修正の方が大変だった。
12月7日 二転三転
リファレンスの配列ができるようになってきたが、配列の宣言の仕様をまた変えたくなってきた。
1年目はD言語風、2年目Java/C#風、で、今回はgo風を考えてる。後置は嫌なのでそこは変えないけど。C言語のようにポインタ型であればそこまで不自然でなかったと思うけど、今のpalanの配列のような表記になると、要素の親子関係が分かりづらく不自然さが際立ってきた。。
もっとも1年目からgo風は検討してたんだけど(過去日記見ればわかるが)、変更に踏み切った時はjava風の方が変数宣言をすぐに確定できてパーサー的には都合が良かったので、実装の楽さに負けたんだよね。
今は先読みの関係で、その都合の良さもなくなったので、頑張ってパーサー描き直してみようかな。コンフリクト地獄が待ってるが。
12月4日 目的は?
リファクタリングが完了した。さて、構造体仕上げるかーと思って追加テスト書いてたら、気づいた。リファクタリングのそもそも目的であるリファレンスの配列実現ができてない。
単に実現不可能だったから可能になるように下回りを変えただけで実現するにはまだまだ考えることがたくさんあったよ。リファクタリングが大きすぎて、これ終わったら自然にできるとすっかり思い込んでたぜー![]()
11月28日 平凡
未だにリファクタリング地獄から抜け出せないが、やってて気づくのは、上手くリファクタリングできるとコードが平凡になるということ。難しいことを解決したぜみたいな、一箇所で色々やっているコードが平凡になっていく。。
平凡に見えるコードが、実は究極のビューティフルコードだったりするかもしれないな。
11月19日 絡まってる
型の付加情報を追加したので、役割が被っているクラスのメンバー変数の削除のため、芋づる式でリファクタリング中。やはり影響範囲半端ない。
一見複雑に見えないけど、いろいろなところと微妙に関連しててなかなか処理と切り離せず消せないな。あ、これ、スパゲティってやつや。
11月14日 定義修正
前の定義で進めてみたらうまくいかない所があったので修正。
一意性
- m: 所有権移動可
- c: 変更可(リファレンス先が変わる。所有権は持てない。)
- i: 一意性維持(リファレンス先が変わることはない)
- n: 一意性なし(その場限り)
ロケーション
- h: ヒープに確保された変数。(メモリ確保、解放の責務あり)
- s: スタックに確保された変数。
- r: 変数の実体へのリファレンス(ReadOnlyの領域も指せる)
- i: 即値などメモリに存在しないもの
11月8日 型情報定義
しばらくコーディングはせず、あるべき型の付加情報を考えていた。一旦、下記のようにして進めてみたい。型に付加する情報としては3種類を持たせる。
- アクセス権限(Access Right)
- 一意性(Identity)
- ロケーション(Allocation)
アクセス権限
- r: 読み取り専用
- w: 読み書き
- o: 書き込みのみ(output)
一意性
- c: 変更可(リファレンス先が変わる可能性あり)
- i: 一意性維持(リファレンス先が変わることはない)
- n: 一意性なし(その場限り)
ロケーション
- o: ヒープに確保された変数。所有権あり(メモリ確保、解放の責務あり)
- s: スタックに確保された変数。
- r: 変数の実体へのリファレンス(ReadOnlyの領域も指せる)
- i: 即値などメモリに存在しないもの
ミュータブル/イミュータブルは最近の言語というか古くはJavaからのそれっぽい概念で、型情報に入れようとしてみたけど、どうもpalanには合わないみたい。ていうか、個人的にJavaは理解できるが、python/Rustあたりのイミュータブルの概念がなんとなく理解できた気がしない。
10月29日 型の権限
リファクタリングが進み、型にReadOnly等の情報を持たせられるようになって、処理の切り替えもできてきた。テストもクリアしている。情報はファイルのフラグみたいに文字のキャラクター例えば"wmr"などとして書き込み/ミュータブル/参照等の意味等を持たせる仕組み。
ただ、正しく意味づけするのが実は結構難しい。rは読み取り専用などと何となく定義して動いてはいるが、例えば配列変数でどこまでが読み取り専用なのか、全体なのか、参照先のオブジェクトなのか、要素のアクセスなのか、をちゃんと定義してあげないと、将来的に大混乱に陥りそう。
ここでキチンとロジカルに決められれば、コンパイルエラーとかの処理も楽になるはずなんだけど、やってみると考えるのがすごく大変。
よく、mutableとかreadonlyとか宣言できる言語はあるけど、実際、直観的に使いやすくできてる言語は少ないんじゃいないかな。
10月24日 影響範囲MAX
型の構造を絶賛リファクタリング中。小細工も考えてちょっとやって見てうまく行きそうだったが、やっぱり本筋にすべきだと考えなおした。
構造の直し自体は簡単なのだが、ほぼコードのどこかで使っていて、受け渡しにも使う型を変えてしまうので、影響範囲が半端ない。半端なプロジェクトでこれをやると、プログラムが壊れて復帰不能になりかねないと正直思う。
Palanはカバレッジがほぼ100%なのと、テストが早いのと、大規模なリファクタリングを何度も成功させてコツもつかんだつもりなので、時間がかかっても、安全にうまくリファクタ完遂できると確信している。
10月22日 隣の芝生
今年(2019)のU22コンテストのBlawn。中学生がflexとBisonとLLVM使って数週間で言語作って賞を貰うだと?こちとら2年強細々やって型設計の間違いに四苦八苦しとるというのに。技術の選択の正しさもあるし、使い方とか短期間でマスターできるのは凄すぎる。ホントに昨今の若者ときたら。。若いってええのー。
でも、自分が若くても、とてもできる気はしないな。
10月11日 大混乱中
うーん。正直よくわからなくなってきた。とりあえずリファレンスの記号は&から@に変更。関数定義と型定義を先読みしている関係で、将来的にビットAND演算子&とのコンフリクトが避けられない。ビットANDの記号を変えることも考えたけど他の言語でも&がほとんどだし、できれば&は演算子として使えるようにしときたい。結局、先読みとC++風で天秤にかけて先読みを取った。@の方がアドレスの意味が強い記号なので、まぁ違和感はないだろう。
また、昨日の読み取り専用レファレンスの型の記述も微妙な気がしてきた。基本直前のものに対して、修飾するべきだからこうすべきか。
byte[3][?]@ strtbl = ["aa","b","c"]; //固定文字列へのテーブル。
strtbl[1][0]; // 'b'
もし、関数の引数とかで、変数自体を読み取りリファレンスで受け取りたいのであれば、こうなる。
func f(byte[3]@[?] strtbl)
これはわかりにくいな。。まぁ、配列の配列でなければそこまで混乱する記述にはならないんだけど。
実装の設計もどうしたらいいかよくわからない。型のモードが読み取りになった場合は別の新たな型にしたほうがいいと思うんだけど、いろいろ組み合わせとか構造が爆発しそうで悩む。別の型にしないのもそれはそれで難しい。
こう考えると設計ミスというより、トライして難しかったのでとりあえずの設計にしていただけの気がする。でも仕事じゃないので、時間かかってもいいので妥協せず、こういうところにこだわって進めたい。
10月10日 設計ミス
初期化ができたので構造体のメンバーとしてリードオンリーのリファレンスの定義を着手しようとしたが設計ミスに気づく。
リファレンスかどうかの情報を変数に持たせてたが、型に持たせないといけなかった。どっちに持たせるか迷った際、型の比較の部分が面倒そうだったので間違った選択をしてしまった、、
このままだと構造体はいいにしても、リファレンスを要素とする配列がつくれない。例えば以下のようにできない。
byte[?]&[3] strtbl = ["aa","b","c"]; //固定文字列へのテーブル。(byte[?]&)[3]とカッコが正しい?
これができないと単純に固定アドレスだけの代入でいいところが、メモリ確保やコピーなど無駄なことをしないといけない。
思い出せないが、誰か設計はデータの持ち方が9割と言ってたような気がするが、実際その通りかも。リファクタリングはするにしても、さて、どう情報を持たせようか。。
10月8日 構造体初期化
構造体の初期化を実装した。本当はjson形式で初期化を考えているのだけどCのようなメンバー名指定なしの初期化のほうがよく使うだろうと思い、そちらを実装。ブロックやjsonと文法が重なるのが嫌だったのでCの{}ではなく配列表現[]で初期化できるようにした。
配列表現を扱うためのアルゴリズムは去年何とかできていたので、多少ハマったものの少ない労力で構造体の初期化が実現できたと思う。以下のように書ける。
// 構造体の宣言
type A {
int32 a;
int32 b;
};
// 初期化 aa.a=1, aa.b=2
A aa = [1,2];
// 代入も書ける
[3,4] -> aa;
A[2] arr = [1,2][3,4];
// 構造体をメンバーとする構造体
type B {
A a;
int32 b;
};
B bb = [[1,2],3];
10月3日 使わない関数
オブジェクトをメンバーにもつ構造体の実装は大体できた。オブジェクトが入れ子になる場合は専用のアロケータやコピーの関数を生成しているが、今までは使っているいないに関わらず再生していたので、複雑な型を作ると生成アセンブリの検証が面倒になってきていた。
なので、生成順を動的にして関数をコールしたカウントをとり、コールしたことがある関数から生成するように修正した。
あとはリードオンリーの参照も構造体のメンバーにできるようにしたかったのだが、今構造体を初期化する方法がないので、参照の初期化が出来ず意味がない。しょうがないので、面倒そうで何となく後回しにしていた初期化に着手することにしよう。
9月24日 構造体再着手
テトリス作成で見つけたエラー処理の追加が終わったので、オブジェクトをメンバーにした構造体も定義できる実装に着手しようと思う。
設計を思い出すために配列型の実装見てたら、そちらのリファクタリングをした方がいいような気もしてくる。しばらくあるべき設計に悩みそう。
9月17日 テトリス
でけた。→ソース
どこまででも改善できそうだがこれぐらいで止めよう。
言語的な問題はいろいろ抽出できた。一番醜いのはブロックが変わると同じ名前の変数が型推論で再定義できるところ。代入のつもりでつい=で書いてしまうと変数の値が思ったように更新できずにハマる。これはなおさないと。
基本部分は割と早くできたが意外にテトリスの流儀みたいなのを調べるのに時間がとられた。TGMとかワールドルールとかいくつかあるのね。本プログラムはTGMに近づけてる。細かい所は全然だけど。
9月6日 パイロット
型のエイリアスはあっさり完了。構造体を本格的に実装してもいいのだが、せっかくC関数をいい感じに呼べるようになってきたので、何かパイロット的にちゃんとしたプログラムを作ってみたくなった。実用に不足する部分も洗い出せそうだし。
コンソールで動くテトリス辺りがお手頃な気がするのでトライしてみよう。作ったことないけど。。で、cursesを使おうとしたらリンクするライブラリの指定ができないと、さっそく困る。プロトタイプの文法に指定できるよう追加。
8月30日 Read-onlyリファレンス
時間がなくてなかなか進捗しないが、読み取り専用のリファレンスを実装した。下記のような感じでlocaltime()がちゃんと使えるようになった。
time_t等が使えないので、次は型のエイリアスをやってみよう。
ccall printf(...)->int32;
ccall time(uint64 tloc)->uint64;
ccall localtime(uint64 &t) -> struct_tm&;
type struct_tm {
int32 tm_sec;
int32 tm_min;
int32 tm_hour;
int32 tm_mday;
int32 tm_mon;
int32 tm_year;
int32 tm_wday;
int32 tm_yday;
int32 tm_isdst;
};
t = time(0);
struct_tm& tm1 = localtime(t); // Read-only ref.
struct_tm tm2 = localtime(t); // Deep copy.
printf("%d %d\n", tm1.tm_year, tm2.tm_year);
8月12日 localtime()
プリミティブ型のメンバーをもつ構造体が扱えるようになった。構造体や配列はまだ含むことができない。今の目標はC標準ライブラリを呼ぶことに置いているので、構造体の実装は一旦中断して、リファレンスを扱えるようにしてみたい。せっかくstruct tm型を定義しても、リファレンス(というかポインタ)の言語機能がないとlocaltime()が使えないから。でもlocaltimeってスレッドセーフじゃないし内部の構造体を返す設計でいかにも昔のAPIって感じだな。
8月7日 パディング
構造体のサイズ計算が簡易すぎたので以下のようなパディングも考慮するようにしてみた。C言語は環境依存とは言われているが、同様の実装が大半と思う。
- メンバー変数の宣言順に配置する。
- メンバー変数のバイト数でアラインする。例でいうと1byte変数は1の倍数、4byteは4の倍数に開始アドレスを合わせる。つまり1byte変数の後に4byte変数を定義すると1byteの後に3byteパディングされる。そうしないとメモリからレジスタへの読み込み処理が複雑になるから。
- メンバー変数の最大のアラインするバイト数の倍数になるよう、構造体のサイズを調整。4byte, 1byteの構造体だと、後ろに3byteパディングがはいる。そうしないと配列にしたときメンバーのアラインが崩れる。
このあたりを理解している理解していないかは、C言語の熟練度を測る一つの基準かもしれない。
8月6日 struct tm
構造体の実装をしてみている。標準ライブラリが動かせるか試すために、palanで仕様通りtm構造体を定義してctime_r等で使ってみたが、何故かSegってはまった。サイズを増やすと大丈夫そうだったので念のためヘッダをのぞいてみると、マニュアルには書いてないメンバー、tm_gmtoffとtm_zoneがこっそり後ろに定義されていた。こんなのわかるかー。
struct tm
{
int tm_sec; /* Seconds. [0-60] (1 leap second) */
int tm_min; /* Minutes. [0-59] */
int tm_hour; /* Hours. [0-23] */
int tm_mday; /* Day. [1-31] */
int tm_mon; /* Month. [0-11] */
int tm_year; /* Year - 1900. */
int tm_wday; /* Day of week. [0-6] */
int tm_yday; /* Days in year.[0-365] */
int tm_isdst; /* DST. [-1/0/1]*/
# ifdef __USE_MISC
long int tm_gmtoff; /* Seconds east of UTC. */
const char *tm_zone; /* Timezone abbreviation. */
# else
long int __tm_gmtoff; /* Seconds east of UTC. */
const char *__tm_zone; /* Timezone abbreviation. */
# endif
};
7月29日 ファイル処理
ポインタの型の定義ができるようになったので、type FILE;とFILE型を宣言してC標準ライブラリのファイル処理を扱えるようになった。いままでモジュールレベルで型を管理していたのをブロックのスコープレベルに落とすのに苦労した。こんな感じに書ける。関数より早く先読みしているので、型は後宣言できる。
ccall fopen(byte[?] &filename, &mode) -> FILE;
ccall fclose(FILE >>stream) -> int32;
ccall fprintf(FILE &stream, byte[?] &format, ...) -> int32;
ccall fscanf(FILE &stream, byte[?] &format => ...) -> int32;
type FILE;
const filename = "outfile.txt";
FILE file <<= fopen(filename, "w");
file->fprintf("This is test.");
fclose(file>>);
byte[32] str1, str2;
fopen(filename, "r") ->> file;
file->fscanf("%s %s" => str1, str2) -> i;
fclose(file>>);
ファイルストリームのオブジェクトは所有権をfopenで取得しfcloseで返す感じ。上のコードはエラー処理はないがif文でNULLチェックはできる。
7月24日 コンフリクト解消
大分苦労したが何とかレキサー(字句解析)への型名登録無しにパース出来るようになった。Bisonのコンフリクトに困っている人(いるのか?)のための参考にやったことをメモ。大体以下の3種類の対応をした。
(1) TYPENAMEという特別な識別子をやめ、一般なIDに統一。下のような文法定義を
type: TYPENAME | type array_def;
array_def: '[' array_sizes ']';
array_sizes: expression | array_sizes ',' expression;
var_expression: ID | var_expression array_item;
array_item: '[' array_indexes ']';
array_indexes: expression | array_indexes ',' expression;
こんな感じにした。型の定義と変数の表記が被ってて確定できない間は同じトークンを使用するようにした。
type: type_or_var;
var_expression: type_or_var;
type_or_var: ID | type array_def;
array_def: '[' array_items ']';
array_indexes: expression | array_indexes ',' expression;
そうしたらコンフリクトが発生するようになってしまった。
(2) いけそうなのにEmptyを使用しているところでなぜかコンフリクトが起きていた。以下のような文法定義を、
parameters: parameter | parameters;
parameter: ID option;
options: /* empty */ | '&';
こんな感じにEmptyを使わないように直したら解消した。Emptyだと先読みに制限がかかるのだろうか。ただ、なんか本当の原因を理解してない気がする。
parameters: parameter | parameters;
parameter: ID | ID '&';
(3) 同じ文法、処理なのでそれを利用していたが、その場所でコンフリクトした。
statement: declarations '=' inits | subdeclaration '=' expression;
declarations: declaration
| declarations ',' declaration
| declarations ',' subdeclaration
;
declaration: type ID;
subdeclaration: ID;
以下のように流用やめたらコンフリクト解消した。
statement: declarations '=' inits | ID option '=' expression;
declarations: declaration
| declarations ',' declaration
| declarations ',' subdeclaration
;
declaration: type ID option;
subdeclaration: ID option;
文法か返すものが同じでも、状態というか条件が違う場合は分けた方がいい。
っとここまで書いて思ったが後に続くトークンを考慮して文法を書けてなかったからだけかも。後に続くトークンが異なる文法に同じトークンをあててしまっていたのかもしれない。重複コードが増えたのでリファクタリングかねて確認してみよう。
7月23日 Bisonの気持ち
結局、まずはレキサー(字句解析)での型の判定をやめることにした。具体的にはパーサーの型の定義でいうと、例えば
type: TYPENAME | type array_def;
と、書いていたものを、
type: ID | type array_def;
のようにする。IDは変数の識別子と同じトークンを使うことになるので、型名int32[5]なのか変数名a[3]なのか1文字先読みでは区別できなくなり、今の構文定義のままではコンフリクトになる。
ログとにらめっこしてbisonの気持ちになって、どこでどうコンフリクトしていて、どう直せば解消できるか、もがいてみている。自分の勘では上手く書けば1トークン先読みでもコンフリクト無しでいけるはずなんだ。そうするとバックエンドの方で型定義を柔軟にコントロールできるようになるので、こちらがあるべき設計のはず。
7月20日 ジレンマ
FILE型使えるように、型定義ができるよう実装し始めたがジレンマに陥った。今まではプリミティブなら型のみをモジュールレベルで保持してたが、関数/定数と同じようにブロックレベルでできた方がいいと思い進めている。関数宣言は後でもいい仕様にした事もあり、先読みでそのブロック内で使える型が決定する。いい変えると後に宣言されててもいい仕様。
だがパーサーの造りが問題。IDと型は明確にレキサーの時点で判断する造りにしてた。多分文法のコンフリクト防ぐため。。
型の識別子は定義が出てきた時点でレキサーに登録するつもりの設計にしてたのでブロックにする場合は登録解除が必要。何より定義前に使うとブロック内であってもパースエラーになり上記の仕様と食い違う。C言語ならばそれでいけるし、その程度でいいと思っていたから。まあそういう文法だと、決めてしまってもいい気もするし、設計としては、このままではいけないような気もしてるし、かといっていい解決方法思いつかない。
7月17日 FILE
sprintfやscanfなどが呼べるようになった。でも全てのC関数が呼べるにはいろいろ足りない。まずは全ての標準Cライブラリが呼べるところを目指して進めたい。把握している課題は以下。
- 型定義/構造体。FILE/struct tmなどが使えない。
- 所有権を持たないリファレンスの取り扱い。strtolなど。
- ポインタの更新(ポインタのポインタ)ができない。strtolなど。sqliteとか使う場合も必要。
- グローバル変数?stdinなどが使える必要あり。
- インポート。プロトタイプを毎回書かずに済むように。
- マクロ/cpu組み込み機能を使えるにはどうするか。
- palan関数でも引数での出力は使えるようにした方がいい。可変長引数はとりあえずやめとく。
こう書き並べるとまだまだ遠いな。。とりあえずFILEが使えるようにするところから始めよう。
7月15日 トレンド
おかげさまで公開後しばらくQiitaトレンド入りしてたみたいで、この日記にいいねをたくさん頂くことができた。いいねしてくれた方ありがとうございます!ただgithubのデータ見ると、試しに使ってもらえるまでには、まだまだと実感。激励と思い地道に進めよう。
実装の方はsprintf/scanf等が、思ったり少ない修正で動き始めた。エラー処理やテストを追加中。
7月10日 C言語関数の再考
Palanでは独自ライブラリはなるべく持たずに既存のC言語ライブラリを上手く利用できたらなと考えている。ただ、C言語の関数そのままの文法では出力や高速化のためにポインタを使うし、引数が入力か出力もぱっと見では曖昧で初心者には取り扱いが難しい。このC言語の関数呼び出しをPalanの左から右に流れるような文法に融合させたい。色々考えた結果以下のようにしようと思う。
// プロトタイプ
ccall printf(byte[?] &format, ...) -> int32;
ccall strcpy(byte[?] >>dst, &src) -> byte[?];
ccall sscanf(byte[?] &str, &format => ...) -> int32;
ccall sprintf(@, byte[?] &format, ... => byte[?] dst) -> int32;
// 使い方
byte[80] dst;
"Hello World!" -> printf();
printf("Hello %s!", "would");
dst ->> strcpy("Hello") ->> dst; // 所有権を渡して変更されたものを受け取る。
// 将来的にはdst.strcpy("Hello");でもできるように。
int32 a,b = 0,0;
int num_scanned;
"10 20" -> sscanf("%d %d" => a, b) -> num_scanned;
sprintf("a:%d, b:%d", a, b => dst);
=>より右側が出力となる引数となる。出力になる引数を全部右に持っていくので、sprintfのように引数の位置が変わってしまうものも出てくる。その対応づけはプレースホルダ@で補う、というアイデア。
プロトタイプさえ上手く書ければ、左から右に入力出力が自然な形にかけて明確と思う。またポインタも意識しなくていい。
最初は=>以降は()の外に出そうかと思ったが、内部実装と文法が剥離して余計な誤解を生みそうだったのでやめた。->でなくて=>なのは引数に代入を混ぜられると混乱しそうだったから。ホントは|>がいいかなと思ってたけどやめた。
基本、文法の一貫性よりも内部処理の実態(コンピュータの都合)に合わせて誤解を生みにくい記述を優先したい。
プロトタイプの読み込みまでは何とか実装できているが、リードオンリー参照&や可変長引数...、要素数不明?等、色々文法追加してるので関数呼び出しまでちゃんと動くところまで持っていくのはしばらくかかりそう。
7月9日 静的解析
なんとなくcodacyで静的解析かけてみた。そしたら150件もの指摘が、、ってほとんどドキュメントのマークダウンの指摘やんけ。ネストしたリストの*の後のスペース、タブ幅に合わせないといけないらしい。。なんとかマークダウンなおしたら、C++関連は30件ぐらい。静的解析は、あまり本質的でない指摘があるのがいやでやってなかったが、まぁこれぐらならいいかな。お陰でバグも1件見つけた。たまにやる凡ミスによるわかりにくいバグは防げそう。
気をつけないといけないのは、コードを理解せずに指摘通りに直してはいけない。指摘されたところは結構バグが潜んでいるので、理解せずに直してしまうと静的解析でも検出できないさらにわかりにくいバグになってしまう。
7月4日 パイプ演算子
C言語のプロトタイプとかポインタによる出力どうしようと思って、|>みたいな記号使ったらどうなんかなーと検索したらElixer が引っかかったよ。Elixerって初めて知ったよ。
Elixer ではパイプ演算子といって関数の第一引数に入れるらしい、、ってこれ何も知らずにPalanに組み込んだチェーンコールまんまじゃん。さらに調べるとずっと昔の何かの言語にあったものがF#に組み込まれて、JavaScript とか色んな言語に波及中みたい。新発明かと思ってたが、先客いたのね。みんな同じこと考えるもんだなあ。
ただ思ったよりメジャーな演算子ということがわかったので、今回の用途でこの演算子使うのはやめた方がいいかもしれん。
覚書
- 引数と戻り値が同じ時 戻り値側の型はvarで省略できるようにする。
- 実現出来るかわからないけどNULLを使わせないというコンセプトも持ってるが、配列のからコピーせずに要素を取り出す等の用途向けにswapを演算子<->等を組み込むのは有用かもしれない。
- 数値計算などパフォーマンス上げる為にfreeをしないモードを入れてもいいかもしれない。
- 名前付きブロック。宣言した時点でメモリ確保してしまうので、子のブロックで親のブロックの変数を宣言できる方がいい。ループ内の振る舞いは要検討。
- 関数呼び出し時のデーブコピーは呼び出し元でやってるが、リードオンリーの際リファレンスを使うかどうかを呼び出し元で選べるから呼び出し先でやってもいいかも、と、一瞬思ったが、引数確定後に元の値が変わる恐れがあるのでやっぱり今まで通りでいい。
- Bool(and/or)は改良の余地ありかも。比較の種類を返すのではなくて上位if文からジャンプラベルもらった方がいいかも。
- 継承は便利なもことも多いが、子の型が確定しているときに子のデータにダイレクトにアクセスしたい時が面倒。共用体のように型変換せずとも気軽にアクセスできる仕組みがあればいいと思う。
- 引数にコピーを指示している関数にmoveで渡せてもいい。用途はsetterとか。そもそも引数宣言にmoveの指定は無くていいのかも。fopen/closeは強制できたほうがいいか。
- インポートするモジュールをいちいち指定するのは面倒。パースの際に未解決識別子を認識して、それに応じたモジュールを自動でインポートできれば嬉しいかも。