
1.簡単な概要
この記事では、小説「天気の子」の文章を自然言語処理して、感情分析をするやり方を解説していきます!
一般的に 感情分析 とは、文章中に含まれる 「感情」 を発見し数値化し、その文章の意見を判断することを指します。
自社の製品やサービスに対するユーザーの意見を機械的に分類することができるため、現在注目されている分野です。
一方で、
「レビューや口コミ以外にも感情分析が活用できるのでは?」
と思い、本記事では巷でほとんどやられていない「小説」を題材にした感情分析にチャレンジすることにしました。
小説を感情分析すれば、「物語のおおまかな展開や登場人物の性格を推察できるのでは?」というのが本記事の趣旨です。
例えば物語の中で、
・感情値の浮き沈みが激しければ、非常にドラマチックな展開である
・感情値によりポジティブからネガティブへの転換点を見つかれば、物語の起承転結を客観的に発見することができる
といった具合です。
そして、今回選んだ題材は、天気の子です!
前作の 「君の名は。」 に引き続き大ヒットした作品で、映画をご覧になった方も多いのではないでしょうか。

まだ、記憶に新しい~~(さすがにもう忘れてるか)~~と思いますので、劇場へ行かれた方は映画のシーンを思い出しながら見ていただけると楽しめるのと思います。
映画と小説の違い
- 小説は、登場人物の視点(一人称)が入れ替わりながら物語が進行する。
- 視点は主人公の帆高の視点がメインだが、陽菜や夏美が視点の章もある。
- ストーリーは基本的に同じ。小説の方が説明が詳しい。
個人的な感想ですが、映画とは少し違った視点から物語を楽しめます。
2.感情分析のやり方
今回は最もシンプルな感情分析である**「ポジネガ分析」**を行いました。
**「ポジネガ分析」**とは、文章がポジティブな意見なのか、ネガティブな意見なのか、それともニュートラルなのかを、一連の単語から判断する分類手法です。
まず、感情分析のおおまかな流れを、簡単な例をあげながら説明していきます。
最初に、文章を形態素解析して、以下のように形態素(単語)ごとに分解します。
『はいっと夏美さんが元気に手を上げ、須賀さんはそれを無視する。』
↓
['はいっ', 'と', '夏美', 'さん', 'が', '元気', 'に', '手', 'を', '上げ', '、', '須賀', 'さん', 'は', 'それ', 'を', '無視', 'する']
そして単語ごとにポジティブかネガティブかを判定し、それぞれに感情値を付与します。
['はいっ', 0],['と', 0],['夏美', 0], ['さん', 0], ['が', 0], ['元気', 1],['に', 0], ['手', 0], ['を', 0],['上げる', 0],['、', 0],['須賀', 0],['さん', 0],['は', 0],['それ', 0],['を', 0],['無視', -1],['する', 0]
この文では、感情極性値のある元気と無視に、
元気:+1
無視:-1
の感情値が付与されました。
最後に、文章感情値を算出するために合計値を出します。上記の文の場合だと、1+(-1)で感情値は0ということになりますね。このようにして、一文ごとに感情値を出していきます。
単語のポジネガ度を判定するためには、感情辞書というものを使います。
感情辞書とは、以下のようにどの単語がポジティブかネガティブなのかがあらかじめ記されている辞書のことです。
この辞書でいうと、ネガ(評価)と入っている単語がくれば感情値に-1をし、ポジ(評価)がくれば+1をする、といった具合です。
この辞書を基準として感情値を出していきます。

また、下記のように複数語によるポジネガ判定もできる仕様にしております。
[口角+上がる,+1][声+弾ける,+1][元気+ない,-1][途方+暮れる,-1]
3.コーパスの作成
まず、元となるコーパスを作成します。
私は友人に協力してもらい、このような感じで自作しました。↓

** ※著作権の都合上、コーパスは公開できないため一部のみの紹介となります**
友人でありコーパス作成者のSさんより一言
今回、「よくわからないけど間違いなく面白いやつだ」という直感で文字起こしを引き受けました。
Kindleの『メモとハイライト』を使い、数文ずつコピペして分割する作業に丸々一週間。正直非常に大変でした。
ページや天気は文章をドラッグしながらコピペして入力できますが、コピペ作業で疲弊している状態でこれをやったら、なんだかラリホーな感じになりました。
納品時に「コーパスありがとう!」と言われましたが、『コーパス』がわからなくてこっそりググっていたことを今ここに告白します。
4.感情辞書を準備
前述の通り、感情分析を準備します。
今回は、東北大の乾・岡崎研究室が公開されている「日本語評価極性辞書」を天気の子の内容に合うように一部改編し、使用することにします。
先ほど紹介しました[口角+上がる,+1]のような複数語によるポジネガ判定のための**「複数語辞書」**については、マンパワーで自作しました。
5.一文ごとに感情値を出す
感情辞書をインポートさせ、一文ごとに感情値を出していきます。
コードは本記事の最後に記載しますが、手っ取り早く日本語の感情分析をされたい方は、「oseti」 というライブラリが非常に便利です。私も参考にさせていただきました。
日本語評価極性辞書を利用したPython用Sentiment Analysisライブラリ oseti を公開しました
テキストを入力すると返り値として感情値が返ってくるスクリプトを作成し、下記のようにコーパスのdataframeに感情値を付与しました。
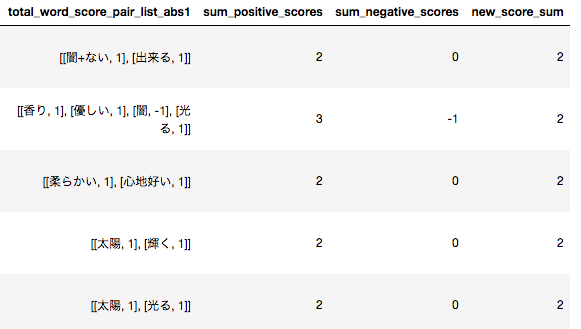
カラムの説明
total_word_score_pair_list_abs1:感情極性値がある形態素とその感情値のリスト
sum_positive_srore:ポジティブ値の合計
sum_pegative_srore:ネガティブ値の合計
new_srore_sum:ポジティブ値とネガティブ値を加算した値
6.感情値の推移をグラフ化・小説の内容と比較
可視化ライブラリのseabornを使って、感情値をグラフにしてみます。
1ページごとの感情値を合計し、時系列で推移を見ていきます。
x軸がページ数、y軸が感情値です。
※ここからネタバレを多分に含みます。ご注意下さい。
import matplotlib.pyplot as plt
from statistics import mean, median
from matplotlib import pyplot as plt
import seaborn as sns; sns.set()
import re
%matplotlib inline
page_sum_df = df_tenki2.groupby("page_num").new_score_sum.sum().reset_index()
sns.lineplot(x="page_num", y="new_score_sum", data=page_sum_df)
結果がこちら!
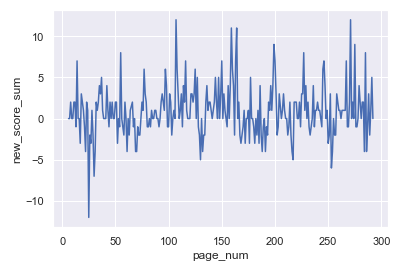
感情の起伏がかなり激しいですね!ポジティブとネガティブが交互に現れています。
このグラフから読み取れること
- ページごとにポジティブとネガティブが起伏として明確に現れている
- ポジティブ値、ネガティブ値が極端に高いページがある
- 物語と展開によって感情値の推移している(かもしれない)
しかし、グラフでは起伏が非常に細かく、特徴がちょっとわかりづらいですね...
もう少しざっくりとした特徴を掴むために、x軸のページ単位から章単位に置き換えて合計して出してみます。
chapter_sum_df = df_tenki2.groupby("chapter_flag").new_score_sum.sum().reset_index()
sns.lineplot(x="chapter_flag", y="new_score_sum", data=chapter_sum_df)
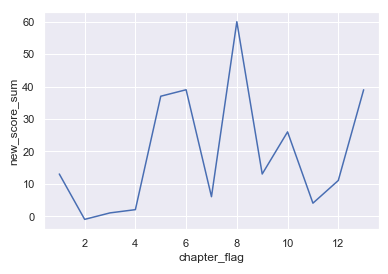
グラフから読み取れること
- ページ単位よりも章単位の方が大局的に特徴を掴むことができる
- 章ごとに感情値の起伏が大きく、感情値が下降した直後の章では感情値が大きくポジティブ振れる傾向がある。
- 章単位でみると感情値がネガティブとなっている章がない
感情の起伏がさっきよりもわかりやすく解釈しやすくなりましたね!
が、しかし...
グラフのy軸の値に注目して見てみてください。
ネガティブな値がほとんどありません。
映画や小説を見た人は、違和感を感じたのではないでしょうか?
「天気の子ってこんな平和ボケした作品でしたっけ...?」
ということで,もう一歩踏み込んで分析してみましょう。
次は、感情値を合計値ではなく、ポジティブ値とネガティブ値の2つに分けてグラフを描画します。
chapter_sum_df = df_tenki2.groupby("chapter_flag").sum_positive_scores.sum().reset_index()
sns.lineplot(x="chapter_flag", y="sum_positive_scores", data=chapter_sum_df,color="red")
chapter_sum_df2 = df_tenki2.groupby("chapter_flag").sum_negative_scores.sum().reset_index()
sns.lineplot(x="chapter_flag", y="sum_negative_scores", data=chapter_sum_df2,color="blue")
赤いグラフがポジティブ値、青がネガティブ値の推移です。
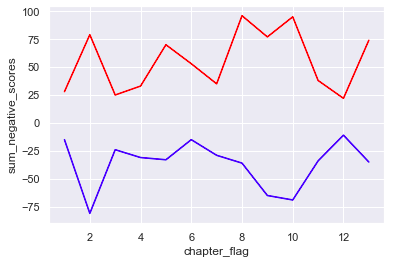
ポジ度とネガ度の両方の特徴がはっきりと見えるようになりました!
先程のように、ポジ値とネガ値を合計して一つのグラフで表現した場合、
「ポジ値とネガ値が両方大きい値を示していたときに、値が相殺されて特徴が見えづらくなっていた」
ようです。
さて、ここからは小説の内容も交えて簡単に考察をしていきましょう。
全体感を見ると、物語の最初と後半、感情値の振れ幅が大きくなっていますね。
chapter2とchapter8以降の章は、ポジティブ値、ネガティブ値共にかなり高く推移しています。
起承転結で言うところの**「起」の部分と「転」**の部分でしょうか。
続いて、値の大きさについても見てみましょう。
このグラフからchapter8とchapter10のポジティブ値が一番大きくchapter2が一番ネガティブであることが読み取れます。
chapter8
chapter8は、比較的平和な場面です。
みんなで公園で遊んだり、**「帆高」が「陽菜」に告白するために、陽菜の弟の「凪」**に相談したり指輪を買いに行ったりするところです。ポジティブ値が高くなっている理由もうなずけますね。
chapter10
chapter10は、物語のクライマックスです。
**「陽菜」を助けようとして、「帆高」が奮闘する場面です。ポジティブ値だけでなくネガティブ値も高くなっているので、「帆高」**の感情が激しくなっていることが想像できます。
chapter2
chapter2は、物語の序盤の場面です。
家出をした「帆高」が東京に来て、バイトを探そうとするも都会の波に揉まれ、最後に**「須賀」の事務所を訪ねて働いていく場面です。都会の波に揉まれたり「須賀」**に叱られたりしているところがネガティブ値に現れたのでしょうか。
7.登場人物ごとに感情値を比較
ここからは登場人物ごとに感情値を比較してみます。
各キャラのセリフ一文あたりの感情値の平均を出してみます。
平均値の算出方法
各キャラのセリフの感情値の合計 / 各キャラのセリフ数
今回は主要人物の**「帆高」、「陽菜」、「須賀」、「夏美」**の4人で比較してみます。
df_tenki3=df_tenki2.groupby(['speaker_name'])['new_score_sum'].mean().reset_index()
df_tenki4 = df_tenki3.sort_values('new_score_sum', ascending=False)
df_tenki_person = df_tenki4[(df_tenki4["speaker_name"] == "suga") | (df_tenki4["speaker_name"] == "hodaka") | (df_tenki4["speaker_name"] == "natsumi") | (df_tenki4["speaker_name"] == "hina")]
sns.catplot(x="speaker_name", y="new_score_sum", data=df_tenki_person,height=6,kind="bar",palette="muted")
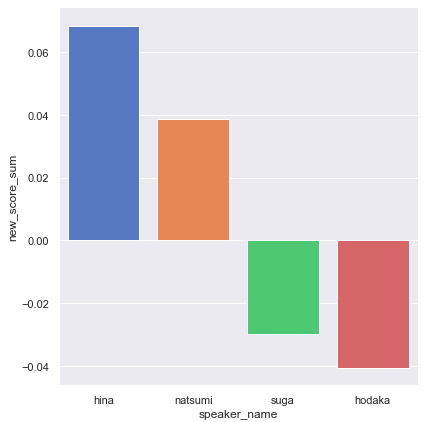
男女でポジネガがはっきりと分かれましたね。
女性陣はめっちゃポジティブです!
逆に男性陣2人はかなりネガティブです。
2人ともかなり近い値を示していますね。
実際に、小説内でも主人公の穂高と須賀は、
「この二人はよく似ている」
と、周囲から言われる描写がありますが、感情値という点から見ても似ていることがわかります。
ポジティブ値とネガティブ値についても見てみましょう。
df_tenki3=df_tenki2.groupby(['speaker_name'])['sum_positive_scores','sum_negative_scores'].mean().reset_index()
df_tenki4 = df_tenki3.sort_values('sum_positive_scores', ascending=False).reset_index()
df_tenki_person2 = df_tenki4[(df_tenki4["speaker_name"] == "suga") | (df_tenki4["speaker_name"] == "hodaka") | (df_tenki4["speaker_name"] == "natsumi") | (df_tenki4["speaker_name"] == "hina")]
sns.catplot(x="speaker_name", y="sum_positive_scores", data=df_tenki_person2,kind="bar",palette="muted")
sns.catplot(x="speaker_name", y="sum_negative_scores", data=df_tenki_person2,kind="bar",palette="muted")
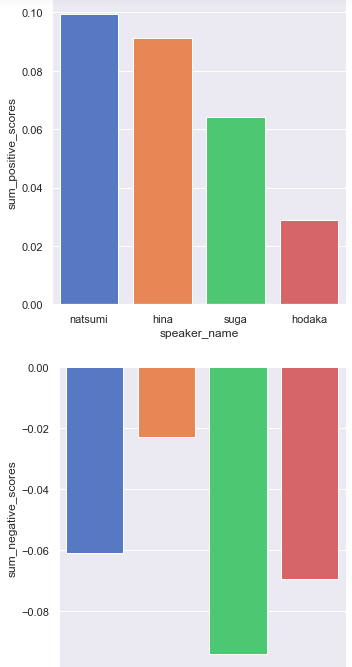
**「陽菜」**は3人に比べてネガティブな言葉をほとんどしゃべっていないようです。なんて強い女の子なんだ...
**「夏美」**はポジティブ値はトップですが、ネガティブ値もそこそこ高いです。
**「夏美」は普段はかなり明るいほうではありますが、就活に悩んで自己嫌悪したり須賀に文句を垂れたりと色々とネガティブな言葉もしゃべっている印象があります。
そして「帆高」のポジティブ値がかなり低くなっています。確かに明るい印象はあまりないですよね...
でも「陽菜」**のポジティブさが引っ張っていってくれるなら、この2人はいいコンビなのかもしれないですね(?)
8.天気と感情値に関連性はあるのか
最後に、この物語の鍵になる「天気」と感情値の関係を調べてみます。
やり方は、登場人物のときと同様、それぞれの天気の場面ごとで平均値を算出します。
天気の種類は、コーパス作成時に描写から判断し下記6分類としました。
「晴れ(sunny)」「雨(rain)」「小雨(light_rain)」「豪雨(heavy_rain)」「快晴(clear)」「雪(snow)」
雨の強さは3種類あるため、雨の強さと感情値の関連を見ることができます。
ちなみに、物語の設定上、ヒロインの**「陽菜」**が晴れを願ったときと、あることが起こったとき以外は基本的に物語の舞台(東京)は「雨」の状態です。
毎日雨が降っている状況のため、街の人々はみんな晴れることを望んでいるわけです。
仮説
仮説として、晴れのシーンは大きくポジティブになり、雨が強くなればなる程ネガティブになるのでは?
と予想してみました。
では、結果を見てみましょう!
sns.catplot(x="weather_flag", y="new_score_sum", data=df_tenki2_edited,height=6,kind="bar",palette="muted")
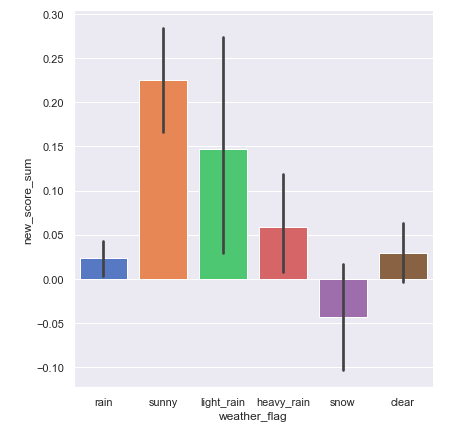
やはり晴れが一番ポジティブになっていますね!予想的中です!
雨の強さについてはあまり関連はなさそうですね。
しかし、「晴れ」は非常にポジティブであるにも関わらず、「快晴(clear)」はあまりポジティブな方に推移していません。なぜでしょうか...?
前述したように、天気が晴れるのは陽菜が晴れを願ったときとあることが起こったときだけなのですが、そのあることとは.....
そう、
"陽菜が消えてしまったことです"
陽菜が消えてしまったことにより、今まで雨ばかり降っていた街は一気に快晴になります。
しかし、**「陽菜」が犠牲になったことなど知らない一般の人々は、晴れたことに素直に喜んでいます。
ただ、主人公の「帆高」だけはそのことを知っていて、非常に悲しむわけです。物語の中で一番いい天気のはずなのですが、ここでは「帆高」**の感情は世間とは真逆にいくんですね。なので晴れているにもかかわらずあまりポジティブにはならないんですね。
最後に雪についてですが、ここが一番ネガティブになっています。ここは映画を観たことがある人であれば、しっくりくるのではないでしょうか。
ここは、クライマックスで、**「帆高」と「陽菜」**が警察から逃げてラブホテルへ逃げ込むシーンですね。
8月なのに雪が降るという超異常気象に、世間も帆高たちも大混乱していて、非常にネガティブな表現が多いシーンです。
9.結論
小説を感情分析をしてわかったこと
- 物語の大まかな展開や起承転結の転換点の読み取りができる
- 登場人物の性格をポジネガ値からざっくり判断ができる
- 時系列ごとの感情値の変遷は、章単位でかつ、ポジティブ値とネガティブ値に分けると解釈が容易になる
そして、今回は一番わかりやすい天気と感情値との関連性を調べてみましたが、他の要素との関連性も調べてみると面白い結果が出てきそうです。
「こんな分析したらおもしろそう!」みたいなアイディアがありましたらコメントいただけますと幸いです。
10.課題
小説の表現の幅の広さ
当然覚悟はしていましたが、予想以上に小説の表現の幅が広く、単語単位でポジネガを付与するのが難しい描写がありました。
最後のシーンで**「帆高」**が「天気なんて狂ったままでいいんだ」と叫ぶセリフがありますが、物語の中で一番力強くポジティブなシーンですが、言葉通りに受け取るとネガティブになります。
単語の単位で感情値を付与するだけでは限界があり、このあたりは非常に難しいところです。