報告の概略
今回の報告は、最終的な形ではなく、LSTM で行っていたことを Transformer で行うことが可能だったという第一報です。合成されたログメルスペクトログラムと development 用データを推論した音声とプログラムを掲載します。
改修の動機
音声認識において、「Python で学ぶ音声認識」(LSTMでの音声認識が解説されている)を勉強しながら、
のページ(Transformer での音声認識)を勉強したり、OpenAI の Whisper のソース(Transformer での音声認識)を勉強していました。LSTM で行っていたことを Transformer に置き換えられそうだったので、 音声合成の Tacotron2 (LSTM)のメルスペクトログラムの合成を Transformer でできないかという発想です。Transformer を用いているので、改修したプログラムを Transtron と呼んでいます。
合成されたログメルスペクトログラム
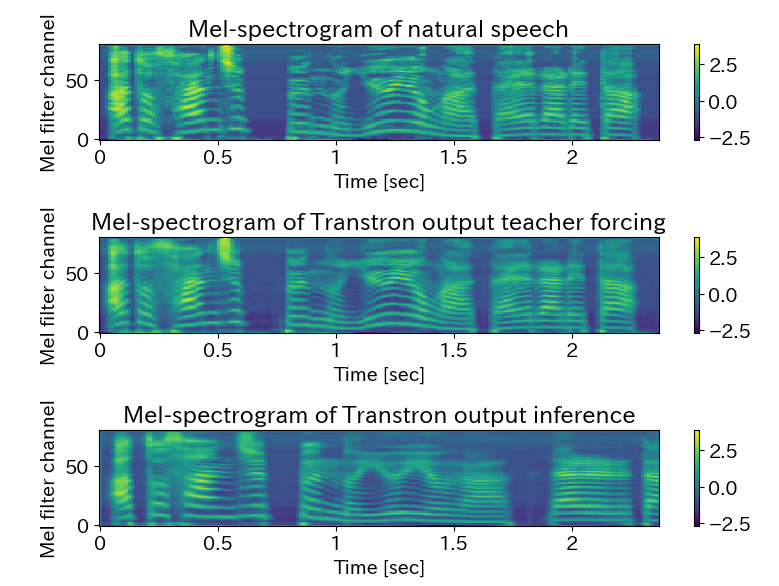
図に合成したログメルスペクトログラムを掲載します。一番上のスペクトログラムが、テストデータの音声をログメルスペクトログラムに変換したものです。二番目のスペクトログラムが、テキストの韻律記号付き音素と decoder_targets として時間的な最初に0を入れて時間方向に1だけずらしたメルスペクトログラムを入力とした teacher forcing の方法で予測したスペクトログラムです。三番目がテキストの韻律記号付き音素と 0 を ( 1,1,80 )だけ並べた decoder_targets を初期値として、自己回帰モデルで予測したメルスペクトログラムです。なんとか、予測できていると思われます。
三番目のスペクトログラムの時間的に終わりの方(右側)が、一番目のスペクトログラムに似ていないという点は、自己回帰モデルであるのでスペクトログラムを時間的に最初の方から予測していくため、後の方は誤差がたまり似ていないのではないかと考えられます。解決策としては、Encoder 4層+Decoder 4層を、Encoder 6層+Decoder 6層とモデルを精緻にして、学習回数を増やすことで、誤差が少なくなるのではと考えます。
合成された音声。
こちらが元の音声で
https://drive.google.com/file/d/1IlOlF8lZ0yXOQZ3lV83rc1QuUMo4Y1L8/view?usp=sharing
推論した音声
https://drive.google.com/file/d/1tIc6VLqzPSNYFRx2fFPlBq0zwzl98NIR/view?usp=sharing
です。なんとか、それらしいと思います。ボコーダーには、「Python で学ぶ音声合成」の WaveNet ボコーダーを使いました。
学習について。
学習データは、教科書「Ptyhonで学ぶ音声合成」に準拠しました。JSUT 1.1 の BASIC5000 発話の 4700 発話が train で、200発話が development です。損失の学習曲線を掲載します。図
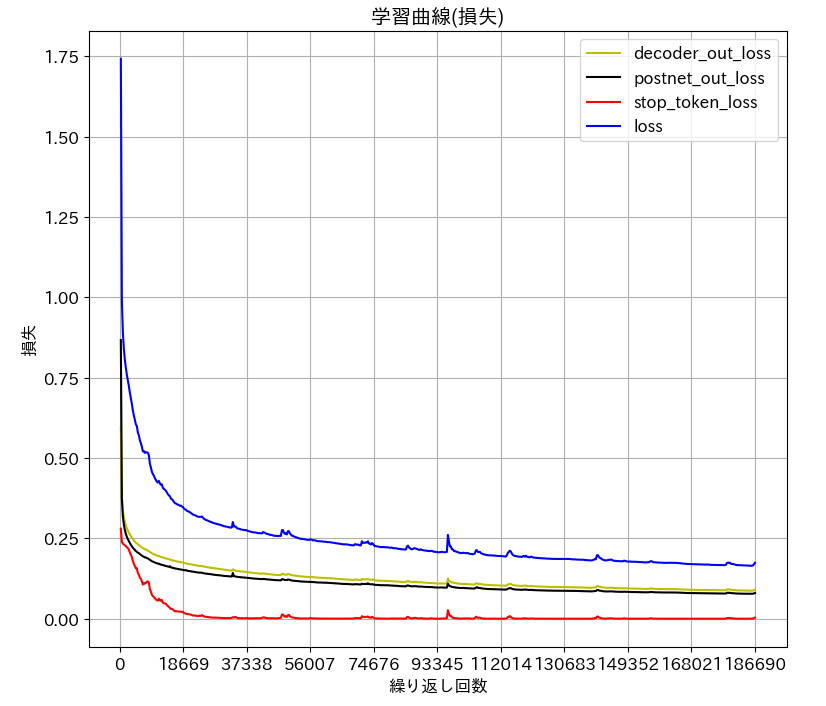
が train の損失です。epoch は635 で step は186690 です。batch_size は 16です。図
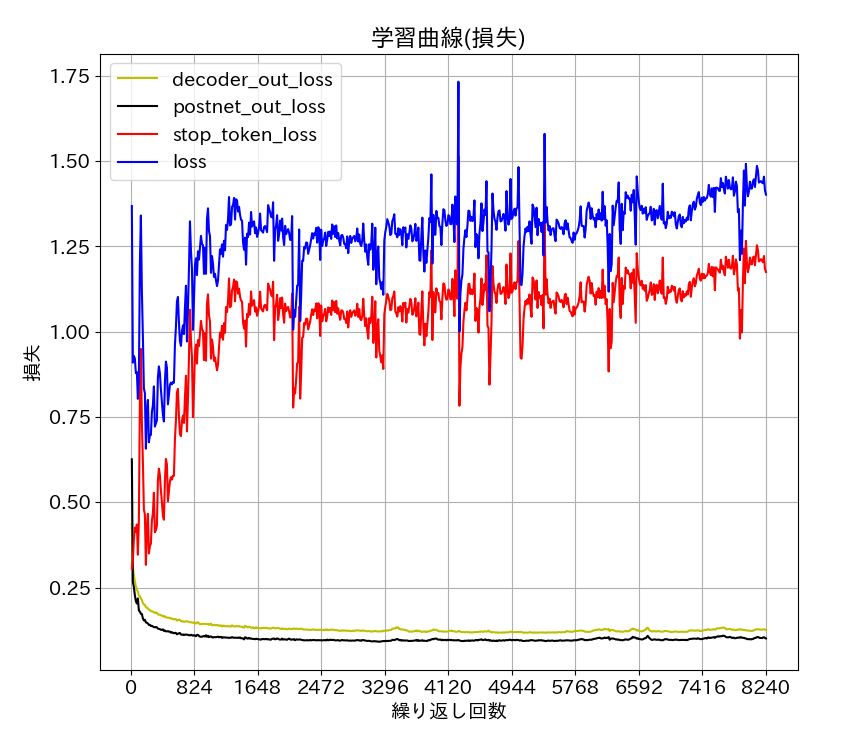
が development の損失です。epoch は 634 で、step は8242 です。batch_size は 16です。epoch 630 くらいから train loss が増え始めたので途中で停止させました。
プログラム。
学習プログラムは、「Python で学ぶ音声合成」に準拠し、ttslearn-master/notebook フォルダで、 ch28_learning_transtron.ipynb として実行しました。レシピの run.sh の形ではなく、ブラウザ上で実行しました。教科書の ttslearn-master フォルダの recipes フォルダの tacotron フォルダをコピーして transtron フォルダを作ってください。tacotron フォルダは、一度、レシピを実行したものをコピーしてください。
ch28_learning_transtron.ipynb は、github においておきます。
https://github.com/toshiouchi/transtron
よろしくお願いします。