はじめに
前回は、transformer を用いた tensorflow の音声認識プログラムを、日本語を認識できるようにと音響特徴量を PCEN に改修して報告させていただきました。
今回は、「Python で学ぶ音声認識」の rnn-attention のプログラムを、非自己回帰型の transformer に改修したことをご報告させていただきます。
学習結果(15epochs/20epochs)
途中経過ですが、20epochs中の15epochs目で、validation データの誤り率が 27 % です。データを掲載します。n_batch:4750 は、38000データ(約51時間分)を batch_size = 8 でというこです。train loss と train token error rate は、訓練データの損失と間違え率です。n_batch:125 は、1000データの batch_size = 8 ということです。validation loss と validation token error rate は、開発用データの損失と間違え率です。train reference が訓練用の教師データで、train hypothesis が訓練用の推論データです。val reference が開発用の教師データで、val hypothesis が開発用の推論データです。<sos> が start of sentence で、<eos> が end of sentence です。訓練データは学習が問題なく反映されています。開発データもかなり学習の効果が表れていると思います。
epoch 15/20:
n_batch:4750
train loss: 0.002525
train token error rate: 9.599095 %
n_batch:125
validation loss: 0.118597
validation token error rate: 26.680335 %
train reference: <sos>しち<eos>
train hypothesis: <sos>しち<eos>
train reference: <sos>再び常識が作られこれによって人間は生活するようになる<eos>
train hypothesis: <sos>再び常識が作られこれによって人間は生活するようになる<eos>
train reference: <sos>それが歴史的種と考えられるものであり即ち種々なる社会である<eos>
train hypothesis: <sos>それが歴史的種と考えられるものであり即ち種々なる社会である<eos>
train reference: <sos>現象即実在として真に自己自身によって動き行く創造的世界は右の如き世界でなければならない<eos>
train hypothesis: <sos>現象即実在として真に自己自身によって動き行く創造的世界は右の如き世界でなければならない<eos>
val reference: <sos>文体が作家に持つ関係は色彩が画家に対するのと同じである<eos>
val hypothesis: <sos>分隊が作家にもつ関係は色彩がかに対するのと同じである<eos>
val reference: <sos>年輩の夫婦は贈り物より現金を好むことが多いがそれはそうした贈り物は必要でもなければ置く場所もないからである<eos>
val hypothesis: <sos>年配の夫婦は送り物より元金を好むことが多いがそれはそうし送り物は必要でもなければ屋馬所もないからである<eos>
val reference: <sos>燃えるゴミと燃えないゴミの区別もよく分からないよね<eos>
val hypothesis: <sos>燃エルゴミと思えないごミの区別もよくわからないよね<eos>
val reference: <sos>脳手術の最中は医者も看護婦も慎重にしかもできるだけ迅速に患者を扱わなければならない<eos>
val hypothesis: <sos>脳手術の最中は医者も間護踏も慎重にし下も出来るだけ人族に患者を扱わなければならない<eos>
学習結果(20epochs/20epochs)
20 epochs 目の TER は
(base) ...$ python3 04_scoring.py
TER: 17.24% (SUB: 12.67, DEL: 3.17, INS: 1.40)
です。
推論された評価用データです。掲載の都合上5つに絞っています。
BASIC5000_0001 <sos> 水 を マ レ ジ 上 か ら 買 わ な く て は な ら な い の で す <eos>
BASIC5000_0002 <sos> 木 曜 日 定 戦 階 団 は 何 の 神 展 も な い も 真 終 了 し ま し た <eos>
BASIC5000_0003 <sos> 上 院 議 員 は 私 が で ー タ を め た と 告 発 し た <eos>
BASIC5000_0004 <sos> 一 週 間 し て そ の ニ ュ ー ス は 本 当 に な っ た <eos>
BASIC5000_0005 <sos> 結 ツ は 健 康 の パ ロ メ ー タ ー と し て 重 要 で あ る <eos>
教師データです。
BASIC5000_0001 <sos> 水 を マ レ ー シ ア か ら 買 わ な く て は な ら な い の で す <eos>
BASIC5000_0002 <sos> 木 曜 日 停 戦 会 談 は 何 の 進 展 も な い ま ま 終 了 し ま し た <eos>
BASIC5000_0003 <sos> 上 院 議 員 は 私 が デ ー タ を ゆ が め た と 告 発 し た <eos>
BASIC5000_0004 <sos> 1 週 間 し て そ の ニ ュ ー ス は 本 当 に な っ た <eos>
BASIC5000_0005 <sos> 血 圧 は 健 康 の パ ロ メ ー タ ー と し て 重 要 で あ る <eos>
学習曲線
次に、訓練の損失と開発の損失のグラフを掲載します。
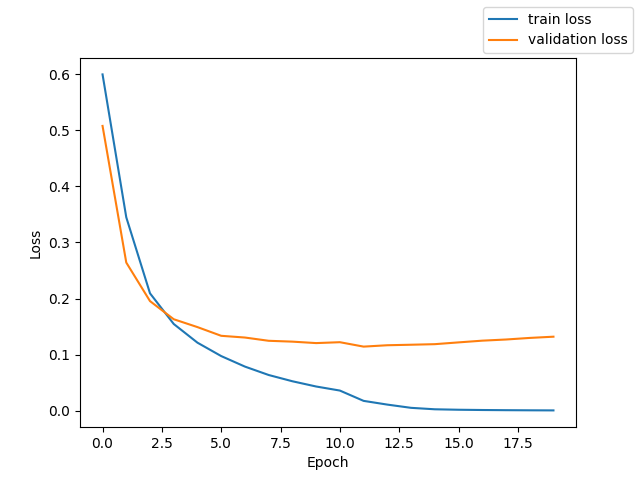
次に、訓練の誤り率と開発の誤り率のグラフを掲載します。

学習のためのデータ
今回は、教科書「Python で学音声認識」の学習プログラムを非自己回帰型に改修して、学習させました。一応、学習データは、JSUT BASIC 5000発話と Mozilla Common Voice Japanese 11 35000発話の 4万発話を test 1000発話、validation 1000発話、train 38000発話にしました。Mozilla Common Voice Japanese 11 は、mp3 をダウンロードし、wav に変換しました。JSUT と Mozilla Common Voice の wav ファイルを original フォルダに入れ、教科書の 00_prepare_wav.py を BASIC 発話以外も扱えるように改修して、16000Hz の wav ファイルを作りました。これとは別に、オリジナルのプログラムで、unit = char の text_char ファイルを作りました。03_subset_data.py で、1000 + 1000 + 38000 発話に分けて、test + validation + train_large を作りました。train_small は 4800 発話です。01_compute_fbank.py はメルスペクトログラムの次元数を80に改修して、01_compute_mfcc.py は修正しないでデータを作りました。02_compute_mean_std.py も改修しませんでした。学習は、fbank で行いました。
プログラムの改修点
教科書のプログラムの 06rnn_attention フォルダをもとに改修しました。プログラムの主な改修点は三つです。まず第一に、rnn ではなく、encoder と decoder には、position wise feed forward network の代わりに 2層の convolution を用いた、transformer を用いました。encoder の入口には、3層の convolution 層で、フィルター数は 256 です。encoder と decoder の隠れ層の数はともに 512。層数はともに 12 です。第二点は、decoder は自己回帰型ではなく、非自己回帰型でプログラミングし、decoder の前に、encoder の出力を down sampling するモジュールを入れました。encoder 出力を時間方向に 1/4 にダウンサンプリングし、decoder の q 入力としました。デコーダーの k, v 入力は、エンコーダー出力としました。三つ目の改修点は、損失の計算に CTCLoss を用いました。その結果、デコーダー出力を教科書の ctc_simple_decode 関数でデコードしました。
学習と評価に使ったプログラムを github にアップしておきます。
評価
fbankを音響特徴量とした非自己回帰型の音声認識で、デコーダーも取り入れたのは数少ないと思います。
さらなる学習
この学習過程を再現しようとしても、Token Error が95% より下がらなくなりました。加えて、精度を上げるために、layer 数、head 数、dimension を増やしても学習しません。2023年12月20日追記
さらなる開発
2024年1月15日追記
Wav2Vec2.0 の Context Network( Transoformer Encoder ) の部分に、上述の Transformer Encoder + downsampling + Transformer Decoder を当てはめて、事前学習と Fine Tuning を行いました。
事前学習のTrain Loss = Lm + α Ld ( α = 100 )の推移。

事前学習のValidation Loss = Lm + α Ld ( α = 100 ) の推移。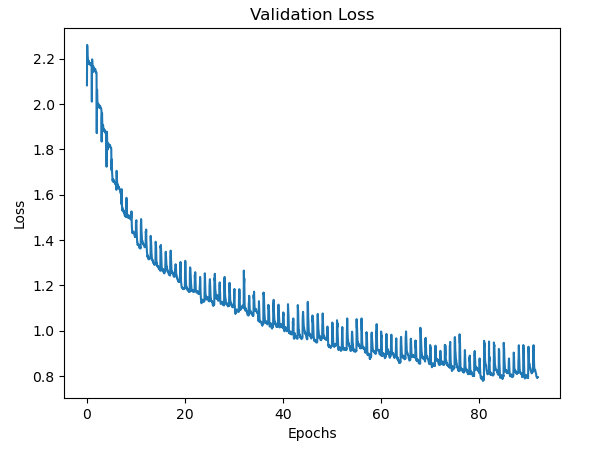
事前学習は、50時間程度 38,000 データの訓練データで、学習は 4日程度、90 epochs 程度行った。
Fine Tuning の Train CTC Lossの推移。

Fine Tuning の Train Token Error の推移。単位は %。
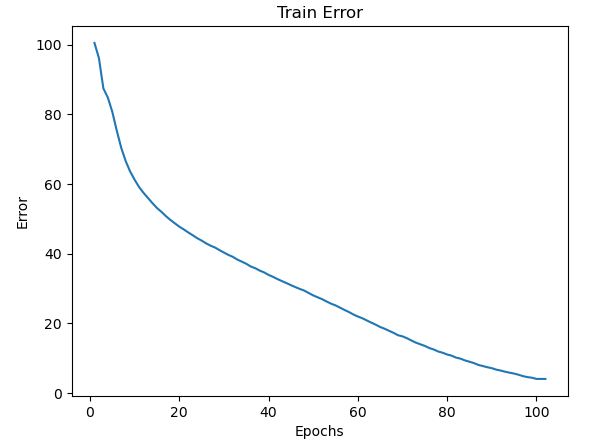
Fine Tuning の Validation CTC Loss の推移。

Fine Tuning の Validation Token Eroor の推移。単位は %。

Fine Tuning は、JSUT 1.1 の 4700 train data + 200 val data について行った。100 epochs およそ8時間の学習であった。
最終エポックの train データ
train, reference :子供を叱るのは親の仕事である
train, hypothesis:子供を叱るのは親の仕事である
train, reference :タオルを冷たい水で湿して額のタオルと取り替えてやる
train, hypothesis:タオルを冷たい水で湿して額のタオルと取り替えてやる
train, reference :早苗さんの才能に嫉妬しない同業者はいないだろう
train, hypothesis:早苗さんの才能に嫉妬しない同業者はいないだろう
train, reference :この前の旅行で買った漆器に料理を盛って写真に収める
train, hypothesis:この前の旅行で買った漆器に料理を盛って写真に収める
train loss: 0.060480
train token error rate: 4.014703 %
最終エポックの validation data
validation, reference :布を斜めに裁ちなさい
validation, hypothesis:のなめに立ちなさい
validation, reference :豹はその斑点を変えることはできない
validation, hypothesis:税はその本手を買えることは出きない
validation, reference :筆者はそうした風潮を好まない
validation, hypothesis:道者はうしたず人をこのまない
validation, reference :飛行機は瞬く間に見えなくなった
validation, hypothesis:飛行機はたく間に見うえなくなった
validation loss: 0.484739
validation token error rate: 45.161290 %
データ量が少ない割に学習できていると感じています。