@7GHz さんの記事でグラフがかけることがわかったので、自分もSplunkを間違った方向に使っていきたいと思う。
はじめに
やはり巷ではビッグデータやらAIやら機械学習が流行っているのになんとか乗っていきたい。
でも、統計の基本がないので少しずつ勉強していきたいと思う。
統計といえば、ということで代表値を求めて、度数分布表を書いてみようと思う。
Splunk Machine Learning Toolkitが必要です。
サンプルデータ
| makeresults count=1000
| eval value=random() % 100 + 1
| table value
| value |
|---|
| 37 |
| 43 |
| 93 |
| ... |
| とりあえずは1000個の1〜100までの数を作った。 |
代表値
Rでいうところのsummary()
基本的にはここらへん(About calculating statistics)のコマンドを使っていくことになる
| stats
| transpose 0
| column | row 1 | description |
|---|---|---|
| count(value) | 1000 | フィールドXの出現回数 |
| distinct_count(value) | 100 | フィールドXの個別の値のカウント |
| max(value) | 100 | フィールドXの最大値 |
| mean(value) | 49.784 | フィールドXの算術平均 |
| median(value) | 50 | フィールドXの中央値 |
| min(value) | 1 | フィールドXの最小値。 |
| mode(value) | 45 | フィールドXの最頻値 |
| stdev(value) | 28.3523755830301 | フィールドXの標本標準偏差 *1 |
| sum(value) | 49784 | フィールドXの合計 |
| sumsq(value) | 3281500 | フィールドXの値の2乗の合計 |
| var(value) | 803.8572012012013 | フィールドXの不偏分散 |
| *1 不偏分散の正の平方根 |
なにも引数をいれないstatsだとこういった結果がでる。
今回調べてみたら、基本的な値は出てますね。
Rのsummary()だとMin. 1st Qu. Median Mean 3rd Qu. Max. なのであと少し足りない。
| eventstats
| eventstats exactperc25(value) as "Q1(value)" exactperc75(value) as "Q3(value)"
| head 1
| transpose 0
| column | row 1 |
|---|---|
| Q1(value) | 26 |
| Q3(value) | 76 |
| count(value) | 1000 |
| distinct_count(value) | 100 |
| max(value) | 100 |
| mean(value) | 51.353 |
| median(value) | 52 |
| min(value) | 1 |
| mode(value) | 88 |
| stdev(value) | 28.68493012395561 |
| sum(value) | 51353 |
| sumsq(value) | 3459133 |
| var(value) | 822.8252162162161 |
statsだと元のデータが変更されるため、eventstatsで集計した。
Splunkのフィールド名は数字から始まるのは奨励されていないので、一応変えてみたのと、あと余計な行は消してます。
これで代表値が出揃った。
MLTK
ここまで書いてきて、衝撃の事実。
MLTKで一発でだせるという
Appを「サーチ」から「Splunk® Machine Learning Toolkit」変更して
| makeresults count=1000
| eval value=random() % 100 + 1
| table value
| `boxplot`
| calculations | value |
|---|---|
| exactperc25 | 29 |
| exactperc75 | 78 |
| max | 100 |
| median | 53 |
| min | 1 |
```Splunk:boxplot
| makeresults count=1000
| eval value=((random() % 100) + 1)
| ifields + value
| untable _x field_name value
| stats min exactperc25 median exactperc75 max by field_name
| untable field_name calculations value
| xyseries calculations field_name value
| eval calculations=rtrim(calculations,"(value)")
⌘+⇧+e(🍎)で先ほどのクエリーを展開してみたもの。
なるほど、参考になります。`transpose`で楽しちゃいけませんね
# histogram
[MLTK Custom Visualizations](https://docs.splunk.com/Documentation/MLApp/latest/User/Customvisualizations)にやり方が書いているのでまずはそこからやってみる。
Appを「サーチ」から「Splunk® Machine Learning Toolkit」変更して
| bin value bins=10
結果がでない...。数を自動的には数えてもらえないらしい。
あとは1〜100までの数だけど、`bin`だと0〜10でまとめてしまい、100~110の欄ができてしまう。
それはダメだろう。(そんなもんなんでしょうか?)
## つくりました。
```Splunk:SPL
| makeresults count=1000
| eval value=random() % 100 + 1
| table value
| stats count by value
| sort value
| streamstats current=f count(eval(value%10==0)) as session
| eventstats min(value) as start max(value) as end by session
| eval bins=start."-".end
| stats sum(count) as count by bins
| table bins count
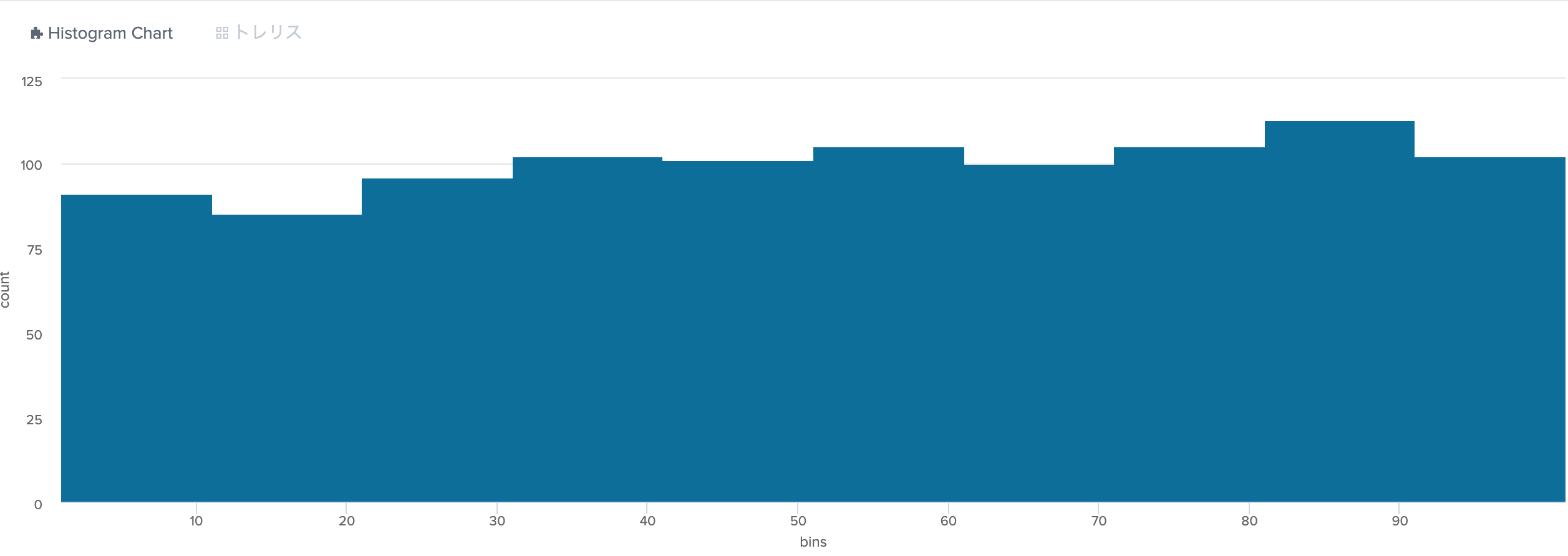
解説
- 1〜10をひとかたまりにするために
streamstatsで10ずつ数えた。
-
streamstatsを使うので、sortして、current=fとvalue%10==0で10ずつになる。
- いちいち_bin_を作るのが大変なので
eventstatsで先ほどの塊ごと、最小値と最大値で_bin_を作った。 - それを
statsでまとめて不要なフィールドを削除 - Histogram Chartで表示
度数分布表
ここまで書いていて衝撃の事実。
度数分布表って以上〜未満で書くのね。
テストの点とかだと百点って最後に含めると・・・・。そいつはいけない。
| makeresults count=1000
| eval value=random() % 100 + 1
| eval value=if(value=100,99,value)
| chart count(value) as count by value span=10
binでいいかとも思ったが、せっかくなのでchartを使ってみる。
せこく、100の項を99に変更して集計している。
これできれいに出来た。
一応binバージョンも
| makeresults count=1000
| eval value=((random() % 100) + 1)
| bin value
| eval value=if(value="100-110","90-100",value)
| stats count by value
まとめ
MLTKがあると、統計値関連はだいたいなんとかなりそうな気がしてる。
度数分布表が出来たので、次も頑張りたいと思う。
![]() 統計をきちんとやっていないからこうなんだな。
統計をきちんとやっていないからこうなんだな。