これのベストプラクティスはなんなんだろう?
とりあえずできたので、紹介します。
前提条件
前回のCSV
を利用するためにApps seikaを作成。
ディレクトリ構成はこんな感じ
tree
├── bin
│ ├── README
│ ├── dl.py
│ └── seika_dl.sh
├── data
│ ├── seika_20210113.csv
│ └── seika_20210114.csv
├── default
│ ├── app.conf
│ └── data
│ └── ui
│ ├── nav
│ │ └── default.xml
│ └── views
│ └── README
├── local
│ ├── app.conf
│ ├── inputs.conf
│ └── props.conf
└── metadata
├── default.meta
└── local.meta
inputs.conf
inputs.conf
[script://$SPLUNK_HOME/etc/apps/seika/bin/seika_dl.sh]
disabled = false
index = main
interval = 0 20 * * *
sourcetype = csv
[monitor:///Applications/Splunk/etc/apps/seika/data]
disabled = false
sourcetype = seika_csv
crcSalt= /Applications/Splunk/etc/apps/seika/data
seika_dl.shのintervalは_午後8時に実施_
検証の時にはinterval = 0 * * * * _毎分0秒に実施_に変更していました。
ここのsourcetypeは使われないので適当
monitorのsoucetypeは今回のため作成したものを使用
crcSaltをつけることで、ファイルができたら強制的に読み込むようにしている。
seika_dl.sh
bin/配下の二つのスクリプトはchmod 755済
seika_dl.sh
cd $SPLUNK_HOME/etc/apps/seika/data
/opt/anaconda3/bin/python ../bin/dl.py
データ格納用フォルダーに移動したのち、ダウンロード用scriptを起動しているだけのもの
/usr/bin/env/ pythonで行けるかと思ったら、Splunk内のpythonが起動してしまうため、フルパスで記載。
dl.pyは前回のにシバンをつけただけ。
pandas入れて欲しいよ〜 ![]()
props.conf
props.conf
[seika_csv]
INDEXED_EXTRACTIONS = csv
KV_MODE = none
LINE_BREAKER = ([\r\n]+)
NO_BINARY_CHECK = true
SHOULD_LINEMERGE = false
TIMESTAMP_FIELDS = date
TIME_FORMAT = %Y-%m-%d
category = Structured
disabled = false
pulldown_type = true
読み込みやすいようにpython側で加工しているのでシンプル
python側でdate列を一番左にしておくと時間の設定も多分いらない。
検索
SPL
miyagi.spl
index=main sourcetype=seika_csv area="宮城" category="野菜"
| stats sum(*_price) as *_price by date, product_name
結果
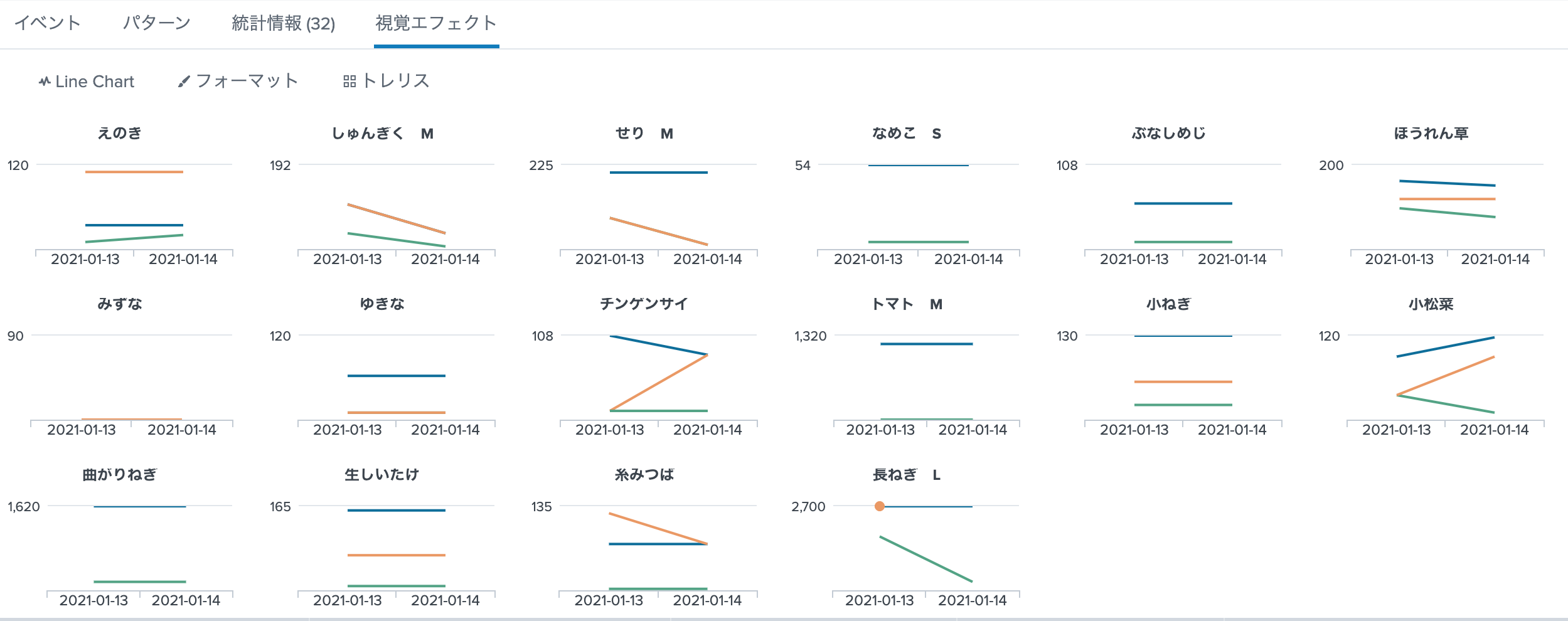
解説
- _trellis_表示は
stats byの引数を第1:X軸 第2:_カテゴリー_とすると、このように綺麗に表示できる。 - ['high_price','middle_price','low_price']の3つをグラフにするので
(*_price) as *_priceで省略して記述している。
まとめ
まだ二日分なのでつまらないけど、データが集まってくるといろいろ使えそうな感じまで持っていけた。
本格運用するのであれば、データそのものはローカルに保存しない方法を検討したほうがいいんだろうなと思いました。