新型コロナ データ一覧
でオープンデータとして、コロナウィルス感染者数のデータが公開されるようになった。
データは
https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_domestic_daily_data.csv
など
取り込み
ヘッダーをみると
日付,国内の感染者数_1日ごとの発表数,国内の感染者数_累計,国内の死者数_1日ごとの発表数,国内の死者数_累計
となっていたのでそのままだとSplunkで処理できないので、一応
date,infected_daily,infected_accum,death_daily,death_accum
として取り込んでみる。
props.conf
[ NHK_CSV ]
pulldown_type=true
PREAMBLE_REGEX=日付
FIELD_NAMES=date,infected_daily,infected_accum,death_daily,death_accum
TIMESTAMP_FIELDS=date
TIME_FORMAT=%Y/%m/%d
SHOULD_LINEMERGE=true
LINE_BREAKER=([\r\n]+)
CHARSET=UTF-8
NO_BINARY_CHECK=true
category=Structured
disabled=false
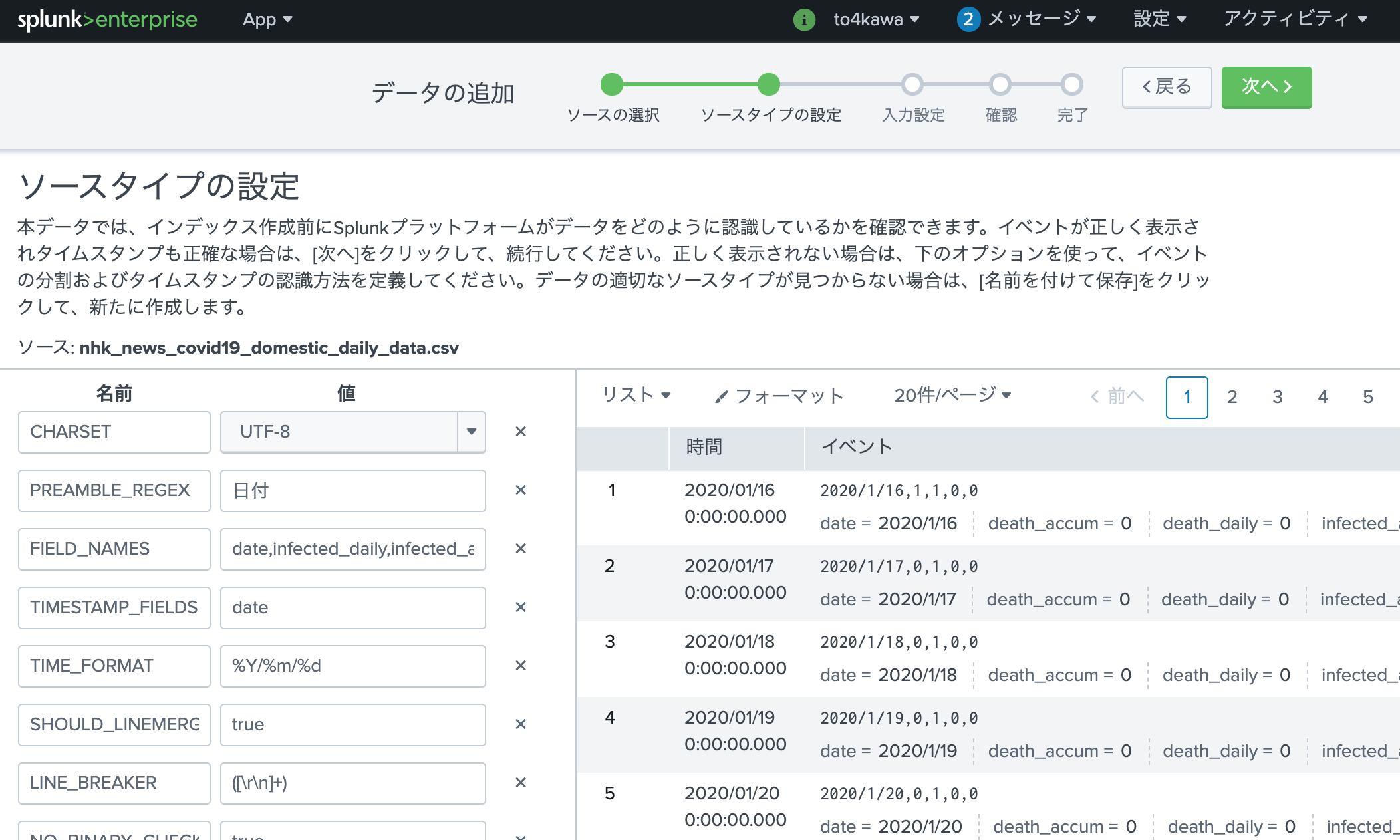
で準備する。
グラフ
graph.spl
sourcetype="NHK_CSV" earliest=0
| table _time ,infected_daily,infected_accum,death_daily,death_accum
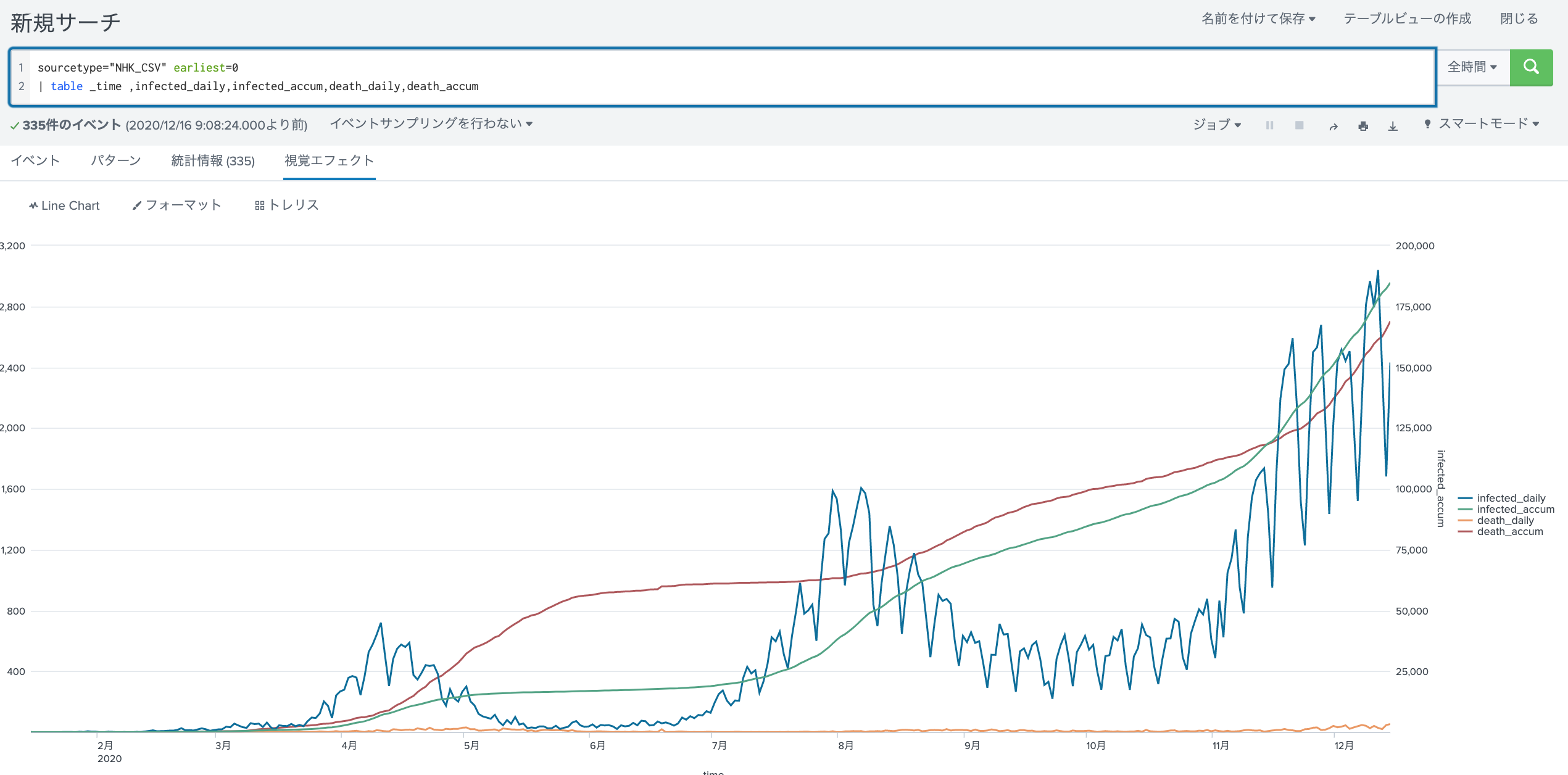
infected_accumを対数のオーバーレイ表示にしている。
定期的にとる。
https://qiita.com/toshikawa/items/ab8eeb4bb997b64bc0af#inputconf%E7%94%A8
を参考にしてもらえれば。
get_csv.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
headers={'accept': 'text/csv', 'content-type': 'text/csv'}
url = 'https://www3.nhk.or.jp/n-data/opendata/coronavirus/nhk_news_covid19_domestic_daily_data.csv'
response=requests.get(url,headers=headers)
response
という簡単なスクリプトで十分だと思う。
inputs.conf
[script:///opt/splunk/etc/app/ourapp/bin/get_csv.py]
disabled = 0
index = foo
interval = 86400
sourcetype = NHK_CSV
とかで読み込み。
すいません、検証していません。![]() どなたか動くやつをお願いします。
どなたか動くやつをお願いします。
まとめ
GOJASで発表した時はNHKのデータを使用しました。その時はビミョーな感じでしたが今回きちんとした形で利用ができるようになりました。
日本語ヘッダーCSVはどこかで加工しないとSplunkで読み込めないので、
1.ダウンロードした時に加工
2.Splunk側で加工
としないといけないのが厳しいですね。![]()
今、また広がりつつあるので、データを持ってきてみてみてはいかがでしょうか?