セマンティックセグメンテーションとは
セマンティックセグメンテーションとは、画像に含む複数物体に対して、物体の領域と物体名を、ピクセルレベルで付与するタスク。← 物体検出では物体を矩形領域で囲んだ
入力:画像
出力:各ピクセルが所属するクラスラベル
用途:製品の傷検出、医療画像診断における病変部分の検出、自動運転における環境把握
PSPNet(Pyramid Scene Parsing Network)
セマンティックセグメンテーションのアルゴリズムの一つ。
PSPNetによるセマンティックセグメンテーションの流れ
- 画像の前処理(リサイズ、色の標準化など)
- PSPNetのネットワークに画像を入力し、各ピクセルの各クラスの確信度(クラス数 x width x height の配列)を出力
- PSPNetの出力が最大値のクラスを抽出
- 3の出力の配列を元の画像の大きさに戻す
ネットワークモデル
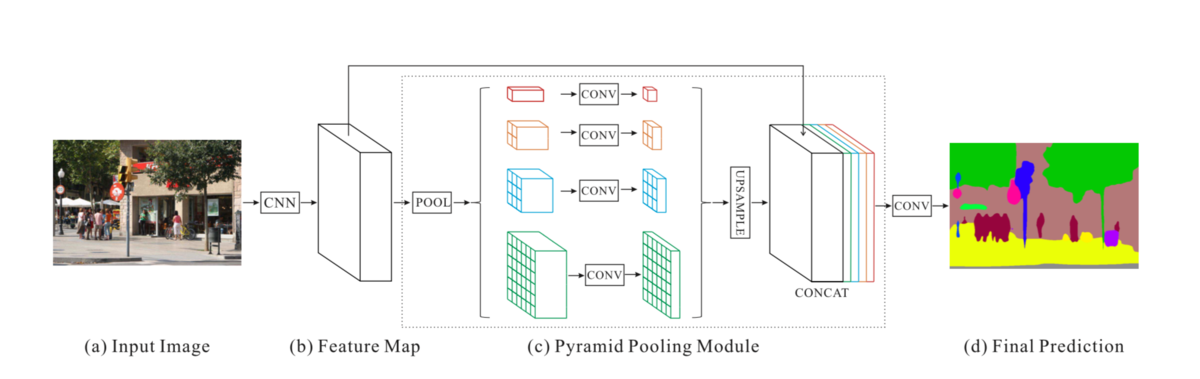
モジュール単位の説明
PSPNetは、Feature, Pyramid Pooling, Decoder, AuxLossモジュールからなる。
Feature(Encoder):2048 x 60 x 60(ch x height x width) の特徴量を出力。特徴をつかむことが目的で、ポイントはチャネルが2048, 特徴量のサイズが60 x 60 に小さくなる部分。
Pyramid Pooling:PSPNetの特徴的な部分。ピクセルの物体ラベルを求めるために、周辺だけでなく、広い範囲の画像情報を利用。4種類の大きさの特徴量マップを用意。← 画像内全体を占める大きさの特徴量、画像内の半分程度、画像内の1/3程度、画像内の1/6程度の特徴量
Decoder(Upsampling):Pyramid Poolingで小さくなった特徴量の出力を21 x 60 x 60 のサイズに拡大(クラス分類の確信度)。次に、21 x 60 x 60 に変換されたテンソルを元の入力画像のサイズ(21 x 475 x 475)に変換。
AuxLoss:上記3つだけでも、セマンティックセグメンテーションは実現できるが、AuxLossを加えることで、損失関数の計算補助を行い、Feature層途中までの結合パラメータの学習がより良くなる。具体的には、Featureモジュールから途中のテンソルを取ってきて、それを入力とし、Decoderと同様、21 x 475 x 475のテンソルに変換。
AuxLossとDecoderの両出力を画像のアノテーションデータ(正解情報)と対応させて、損失値を計算し、損失値に応じたバックプロパゲーションを行う。
そのため、AuxLossは学習時のみ利用。推論時はDecoderモジュールの出力のみでセマンティックセグメンテーション。
参考
- 作りながら学ぶ! Pytorchによる発展ディープラーニング