はじめに
最近、Large Vision Language Model(以下LVLM)ではLLaVA NEXTのように画像を高解像度のまま入力することでモデルの性能が上がるという論文をarXiv上でよく見かけます。
そこで性能が高いImage Encoderを使用し、入力を高解像度にすることでLLMのバラメータ数が少なくても良い性能のVLMができるのではないかと考え日本語入力可能なモデルを学習させてみました。
結論を最初に書くと1.86Bという比較的小さいモデルにも関わらず、7Bほどのモデルと比較して同等もしくはそれ以上の性能を持つモデルができあがりました。
学習に使用したコードは以下で公開しています。
モデルは以下で公開しています。
デモは以下で公開しています。
以前LLaVAと同じ構造で学習させたという記事も書いていますので、LLaVAについて知りたい方は以下を読んでください。
モデルの構造
モデルの構造は以下の図のものを使用します。
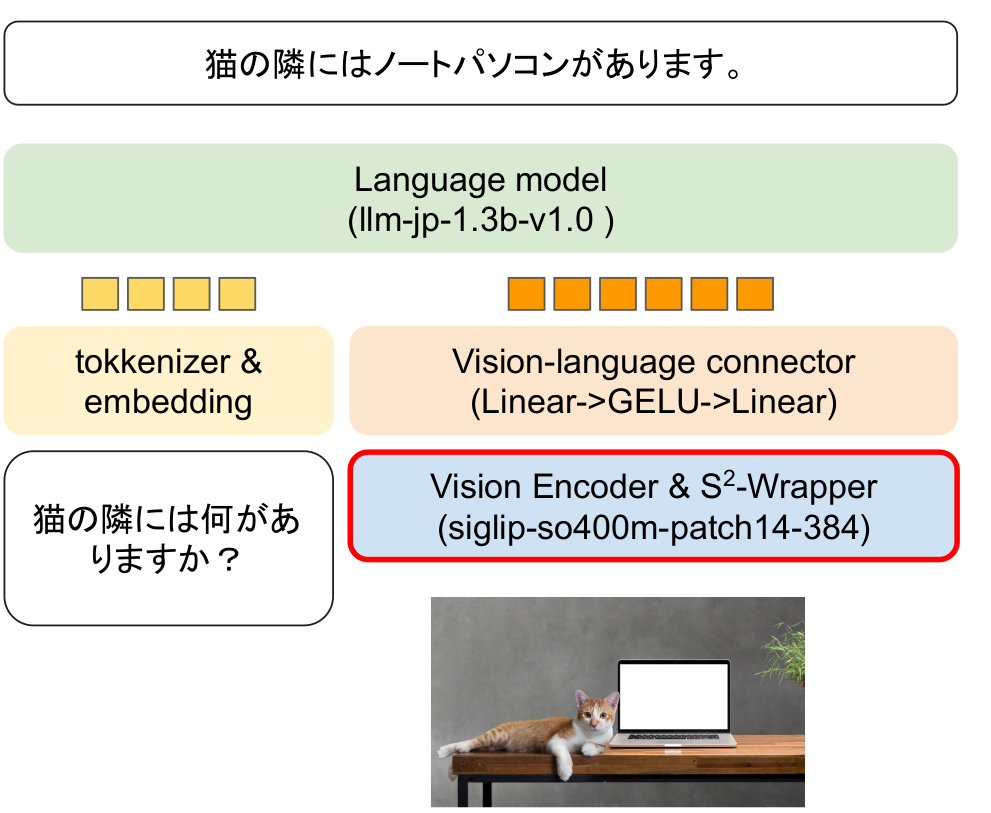
基本的にはLLaVAと同じ構造です。
LLMはパラメータ数が1.3bのllm-jp-1.3b-v1.0を採用しました。
Image Encoderは元々の入力解像度が高く性能が良いsiglip-so400m-patch14-384を使用しました。
LLaVAと異なる点はVision Encoderに画像を入力するときにS2-Wrapperを使用することで解像度の高い画像を使用している点です。(LLaVA NEXTでは同じような処理をしているので実際はLLaVAとほぼ同じ…)
S2-Wrapperとは
S2-WrapperはWhen Do We Not Need Larger Vision Models?, Shi. et al. 2024で提案された入力サイズが小さなViTを使用している場合でも、解像度の高い画像の入力を可能にする手法です。
こちらの論文については丁寧に解説しませんが、パラメータ数の小さいモデルでもS2-Wrapperを使用することでパラメータ数の大きいモデルと同等以上の性能がでるという内容になっています。実験も丁寧にされており、読み応えがあります。
S2-Wrapperの構造は以下のようになっています(Image Encoderにsiglip-so400m-patch14-384を使用した場合の例)。
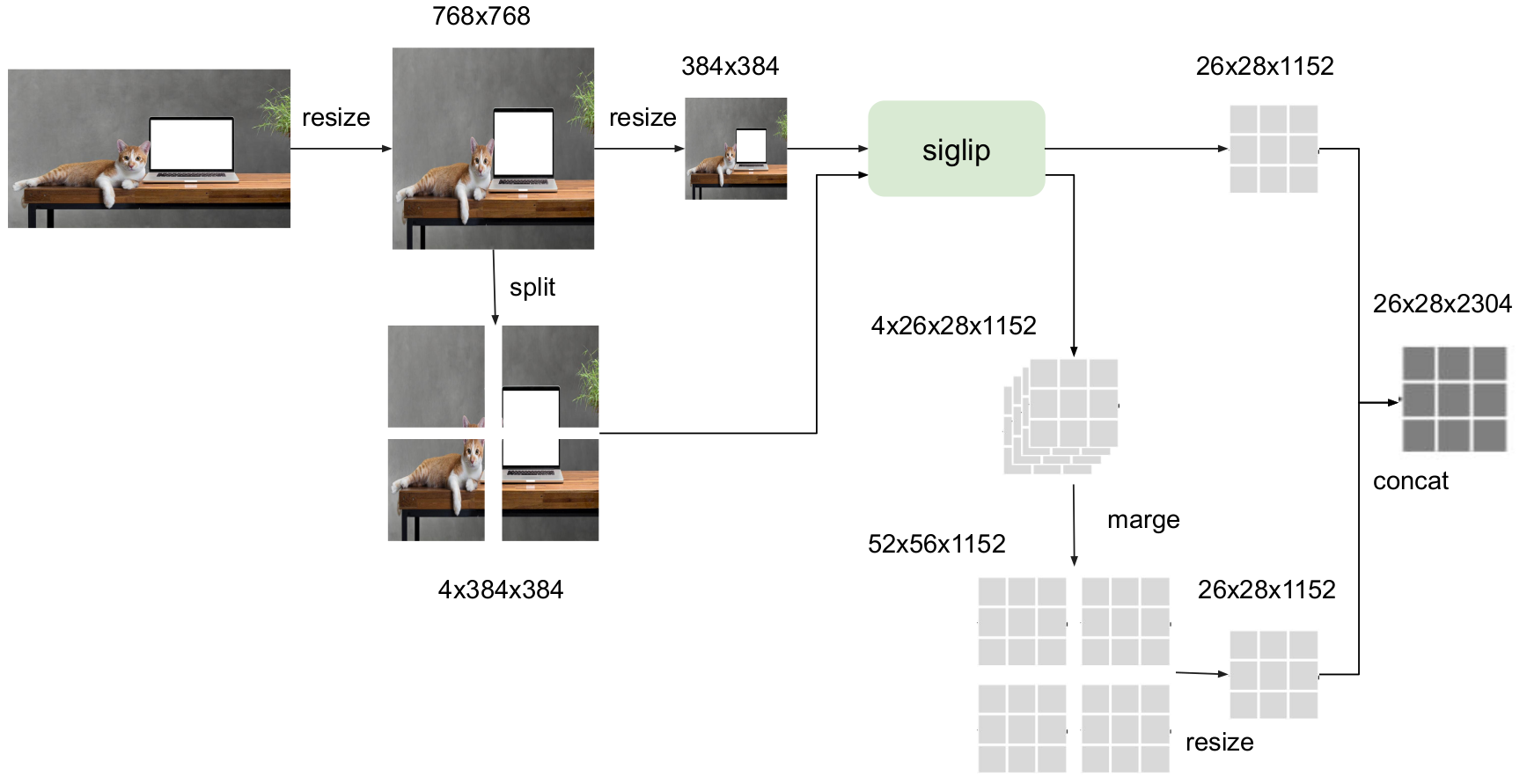
やっていることはすごくシンプルで解像度の高い画像をImage Encoderに入力可能なサイズ(384x384)にパッチ分割することで、解像度を落とさずにImage Encoderへ入力することができるようにしています。最終的にリサイズしで画像全体を入力した出力とパッチ分割した出力をconcatして画像特徴量として使用する方法です。
欠点はImage Encoderへの入力回数が増えるため処理が遅くなることです。ただ、リアルタイム性が重視されない環境ではかなり有効な手法だと考えられます。
本記事ではS2-Wrapperを使用して768x768の画像が入力可能なVLMを学習させました。
実験
今回S2-Wrapperを使用して768x768の入力が可能なモデル(llava-jp-v1.1)、S2-Wrapperを使用しない384x384の入力が可能なモデル(llava-jp-v1.0)を比較します。
また、既存の公開されている日本語VLMとも比較しました。
学習データ
独自に学習したモデルは以下のデータセットで学習を行っています。
| データセット名 | 学習フェーズ |
|---|---|
| LLaVA-Pretrain-JA | 事前学習 |
| LLaVA-v1.5-Instruct-620K-JA | ファインチューニング |
学習パラメータ
学習パラメータは以下のものを使用しました。
| パラメータ名 | 事前学習 | ファインチューニング |
|---|---|---|
| Epoch | 1 | 1 |
| Learning rate | 1e-3 | 2e-5 |
| warmup ratio | 0.03 | 0.03 |
| batch size | 32 | 16 |
| model max length | 1532 | 1532 |
| optimizer | AdamW | AdamW8bit |
学習戦略
学習戦略としてVision Encoderは常に凍結しています。LLMを学習させるかどうかが事前学習とファインチューニングの異なる点です。
| 学習部位 | 事前学習 | ファインチューニング |
|---|---|---|
| Image Encoder | × | × |
| Vision-language connector | ○ | ○ |
| LLM | × | ○ |
評価データ
評価データとしてRouge-Lで評価するJA-VG-VQA-500とJA-VLM-Bench-In-the-Wild、GPT4で評価を行うHeron-Benchを使用します。
| 評価データ | 評価手法 |
|---|---|
| JA-VG-VQA-500 | Rouge-L |
| JA-VLM-Bench-In-the-Wild | Rouge-L |
| Heron-Bench | GPT4 |
結果
今回学習させたモデルと既存の日本語入力可能なVLMのベンチマークスコアは以下のとおりです。
| モデル | パラメータ数 | JA-VG-VQA-500 | JA-VLM-Bench-In-the-Wild | Heron-Bench(Detail) | Heron-Bench(Conv) | Heron-Bench(Complex) | Heron-Bench(Average) |
|---|---|---|---|---|---|---|---|
| Japanese Stable VLM | 7.57B | - | 40.50 | 25.15 | 51.23 | 37.84 | 38.07 |
| EvoVLM-JP-v1-7B | 7.57B | 19.70 | 51.25 | 50.31 | 44.42 | 40.47 | 45.07 |
| Heron BLIP-7B | 8.15B | 14.51 | 33.26 | 49.09 | 41.51 | 45.72 | 45.44 |
| Heron GIT-7B | 7.32B | 15.18 | 37.82 | 42.77 | 54.20 | 43.53 | 46.83 |
| llava-jp-v1.0 | 1.86B | 12.69 | 44.58 | 51.21 | 41.05 | 45.95 | 44.84 |
| llava-jp-v1.1 | 1.86B | 13.33 | 44.40 | 50.00 | 51.83 | 48.98 | 50.39 |
- ※1 llava-jp-v1.0とllava-jp-v1.1以外の結果はHeron-Bench: A Benchmark for Evaluating Vision Language Models in Japanese, Inoue. et al. (2024)から引用しています。
- ※2 赤字は1番スコアが高いもの、青字は2番目にスコアが高いもの
結果から分かるとおりllava-jp-v1.1は他のモデルと比べてパラメータ数が約1/4ほどしかないにも関わらずベンチマーク上では同等もしくはそれ以上のスコアを出すことができました。
Heron-Bench(Complex)とHeron-Bench全体の平均スコアでは現在の日本語VLMでトップのスコアとなりました。
一方、JA-VLM-Bench-In-the-Wildではそれなりのスコアがでているのですが、JA-VG-VQA-500では他のモデルと比べると結果が悪いです。
llava-jp-v1.1の出力を確認した限り、「ベッドは何台ありますか?」のような数についての質問に対して間違いが多く、スコアが低くなったと考えられます。
またS2-Wrapperを使用していない、llava-jp-v1.0も比較的スコアが高いことからVLMではLLMのサイズが小さくても、性能が良いImage Encoderを使用していれば性能が良くなることが分かりました。
llava-jp-v1.0とllava-jp-v1.1を比較するとJA-VLM-Bench-In-the-WildとHeron-Bench(Detail)ではllava-jp-v1.0の結果のほうが良く、S2-Wrapperを使用するだけでは改善されないタスクがあることも分かりました。
以下はベンチマークの結果を比較したレーダーチャートになります。

出力例
今回学習させたモデルのHeron-Benchの出力を確認します。
例1 「鳥の羽の色は何色でしょうか?」

| モデル名 | 出力 |
|---|---|
| llava-jp-v1.0 | 鳥の羽は青と白。 |
| llava-jp-v1.1 | 鳥の羽の色は青です。 |
llava-jp-v1.0だけ間違ったことを言っています。
例2 「力士たちは何を行っているか説明してください。」

| モデル名 | 出力 |
|---|---|
| llava-jp-v1.0 | 画像の力士は、おそらく日本の伝統的な相撲の試合に参加しているのでしょう。彼らは、おそらく競技場か同様の場所で、互いに競い合うように配置された大きなマットの上に立っています。彼らは、おそらく競技の一環として、あるいは単に観客として、試合を観戦しているのでしょう。 |
| llava-jp-v1.1 | 画像の中の力士たちは、おそらく相撲の試合か、おそらく日本の伝統的な儀式で、リングの上で互いに競い合っています。彼らは互いに近くに立ち、互いに接近しています。彼らは、おそらく試合中に技を披露し、観客の注目を集めているのでしょう。 |
llava-jp-v1.0とllava-jp-v1.1ともに相撲の会場で力士がいるということは理解していますが間違った回答をしています。
llava-jp-v1.1に関しては儀式をしている可能性があると言っているのですが、その後試合で競い合っていると言った間違った出力を行っています。
例3 「あなたは車を運転しており、交差点で右折しようと思っています。このまま交差点に向かってよいでしょうか?」

| モデル名 | 出力 |
|---|---|
| llava-jp-v1.0 | はい、画像の男性は交差点で車を運転しており、交差点で右折しようとしています。 |
| llava-jp-v1.1 | いいえ、画像の男性は車を運転しており、交差点で右折しようとしています。彼は交差点で停止し、交通信号を待っています。 |
llava-jp-v1.0とllava-jp-v1.1ともに前方の男性が運転しているといった回答をしています。また、質問内容にしっかりと答えることができていませんでした。
以上の3つの例からllava-jp-v1.0と比較してllava-jp-v1.1のほうが定性的にも正しく回答していることが確認できました。
ただ、llava-jp-v1.1も日本語ベンチマークでは従来よりも高いスコアがでましたが、正しく回答できないものも多々あるというのが現状です。
同様の手法で言語モデルのサイズを大きくすれば問題を改善できるのかは気になりますが、計算資源の関係で筆者はこれ以上大きなモデルの学習が困難であるため誰かに試してほしいです…。
まとめ
S2-Wrapperを使用して解像度の高い画像を入力として使用することで、比較的小さなLLMを使用している場合でも、VLMの性能を改善できることを確認しました。
今後はS2-Wrapperを改造してさらなるモデルの精度の向上を目指したり、データセットの作成を行っていきたいと思います。