2017年~2018年4月までのディープラーニング(Deep Neural Network)を用いたText to speech手法をまとめました。
Text to speech(TTS)とは
TTSとは、文章を入力し音声に変換して出力する技術のことです。
TTSのソフトウェアとしては、VOICELOIDや、「ゆっくり」こと棒読みちゃんが有名です。
既存のソフトウェアのほとんどはDNNを用いずに音声を合成していますが、近年ではDNNによるTTSが盛んに研究されています。
TTS手法の概要
DNN以前のTTSでは、次の図のように「テキスト」→「言語特徴量」→「音響特徴量」→「音声」という手順でテキストから音声へと変換します。
DNNを用いる手法の場合、このモデルの中でどの部分をDNNで行うかが手法によって異なります。
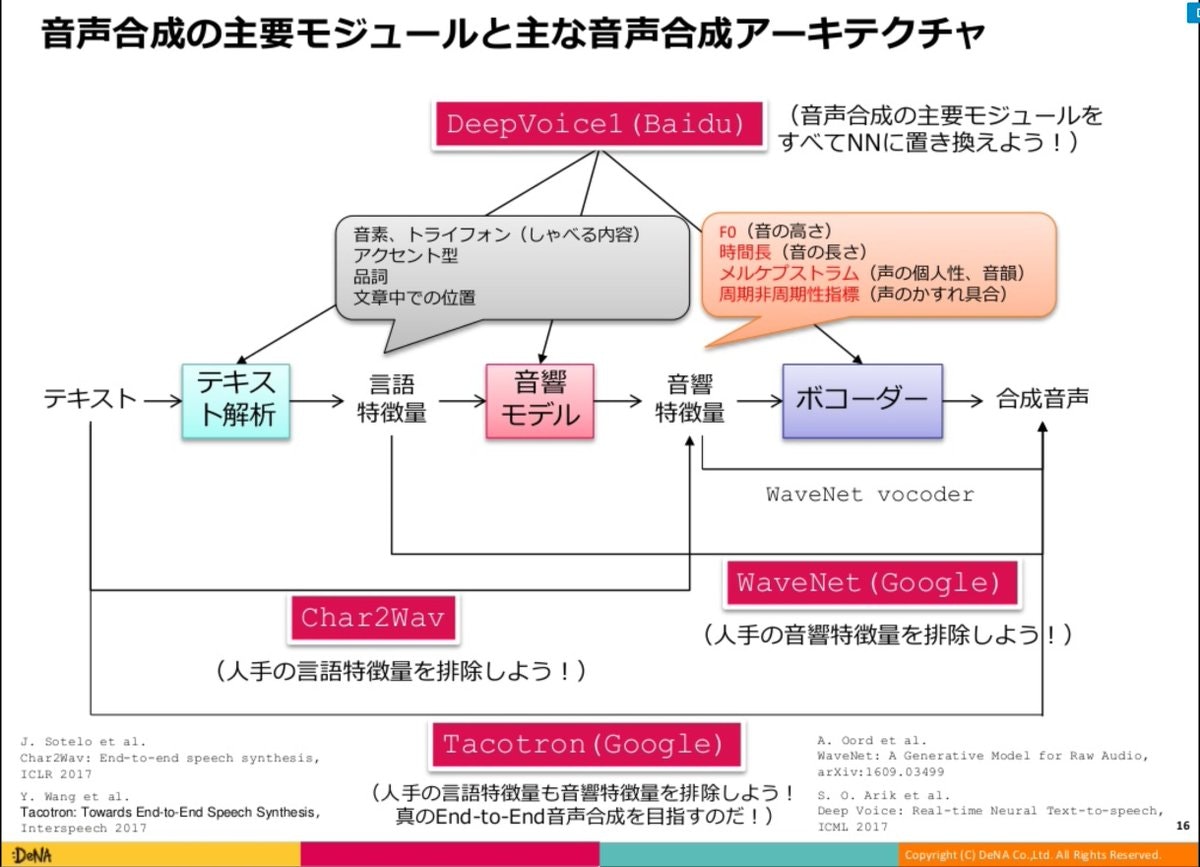
上の図を参考に、より新しい手法についての図を作りました。
この記事で説明している重要なことはほとんどこの図に書いてあります。
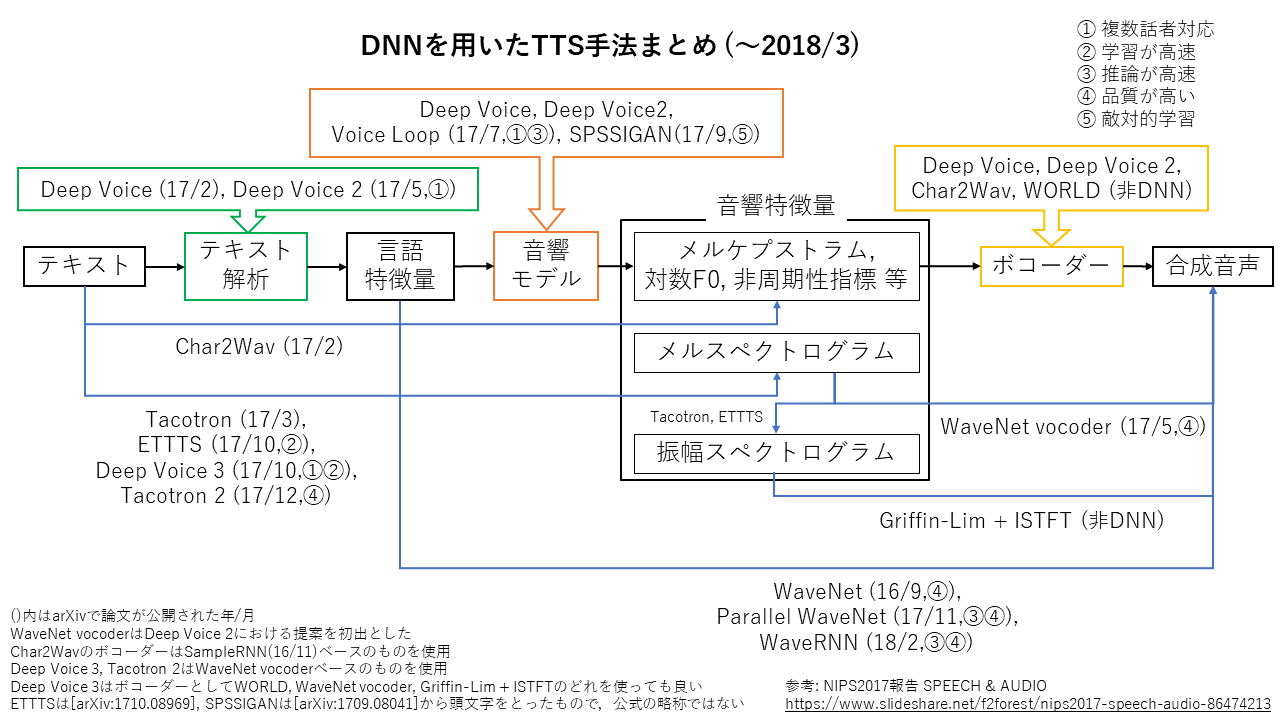
手法の特徴
Tacotron(2017年3月提案)以降の手法では、以下の4つの特徴のどれかを持っています。
- 複数話者対応
- 学習の高速化
- 推論の高速化
- 高品質化
複数話者対応
通常は単一話者による長時間の音声データを元に訓練を行いますが、この学習データは作成コストが非常に高いです。
そこで複数話者対応のモデルでは、多くの話者が短時間話しているデータを元に学習を行います。
基本的には、話者ベクトルを各層の処理に埋め込むことで複数話者対応を実現します。
学習の高速化
TTSでは入出力が長くなりやすいです。基本的には時系列データの処理ですが、RNNを用いてしまうと学習が時間方向に並列化できなくなってしまいます。
そこで学習を高速化しているモデルでは、RNNを用いずにCNNのみのSeq2Seq構造にすることで、時間方向に並列化して学習できるようにしています。
推論の高速化
DNNで波形を直接生成するモデルでは、その出力長の大きさ(毎秒20000~500000個程度)から推論に長い時間がかかってしまいます。
推論を高速化しているモデルでは、できるだけ単純な計算のみで推論できるようにしたり、推論時に時間方向に並列化して音声を生成できるようにしたりしています。
高品質化
DNNがどの形式で生成するかは、合成音声の最終的な品質に大きく関わってきます。
現在主流となっているDNNの生成形式は以下の3つです。
- DNNで音声波形を直接生成
- DNNで振幅スペクトログラムを生成 → Griffin-Limによる位相推定[^15] + 逆短時間フーリエ変換 で波形を生成
- DNNで音響特徴量を生成 → ボコーダーで波形を生成
今のところ、音声波形を直接生成するところまでDNNで行う手法が最も品質の高い音声を合成できています。
以下ではそれぞれの生成形式について説明します。
音声波形を直接生成
現状最も高品質な音声を生成できている生成形式はこの形式です。
質が高い一方、先に述べたとおり出力長が大きいために推論時間が非常に長くなりがちです。(数秒の音声の生成に15分かかる等)
振幅スペクトログラムを生成
スペクトログラムや逆短時間フーリエ変換についてはこちらの解説記事で説明されています。
この方法でもある程度質の良い音声が合成できますが、波形を直接生成しているものと比べると見劣りします。
振幅スペクトログラムはGriffin-Limにより位相推定を行った後、逆短時間フーリエ変換を行って音声波形へと変換することが一般的ですが、振幅スペクトログラム(またはメルスペクトログラム)→音声波形の処理もDNNで行うことで高品質化する手法(WaveNet vocoder)も登場しています。
音響特徴量を生成
DNNの出力をDeep以前からあったソフトウェアに入れることで音声を合成します。
ボコーダーにはWORLDが用いられることが多いです。
合成される音声の質はそこそこですが、非常に単純なネットワークでもある程度の質が得られます。
各手法のメモとリンク集
まともに(?)説明するのはここまでで、これより後は各手法のメモとリンク集になります。
WaveNet1
- 波形を直接生成するのが特徴。
- 波形の生成は8bitで行う場合、μ-lawアルゴリズムによる量子化を行う。
- 生成された音声の品質は高い。
- 生成が非常に重く、リアルタイム向きでは無い。学習にも時間がかかる。
- 振幅スペクトログラムから音声波形を生成することにも用いられる
参考
- 公式の解説ブログ
- 日本語の解説と再現実装
- メルスペクトログラムから波形を生成するボコーダー(後述)としての再現実装。かなり綺麗な音声が生成できている。
Parallel WaveNet2
- WaveNetの順伝播を並列に行えるようにしたもの。
- Google Assistantで使われているらしい。
- ParallelでないWaveNetを教師モデルとして知識蒸留することで訓練を行うので、WaveNetの学習済みモデルが必要。
参考
Tacotron 3
- 一応end-to-endのTTSシステム。内部でRNNを用いている。
- 文字レベルの入力からスペクトログラムを出力し、それを逆短時間フーリエ変換(Griffin-Lim)して波形を生成する。逆短時間フーリエ変換部分がボコーダー。
- 逆短時間フーリエ変換を微分可能になるように実装している。
参考
- 公式の音声サンプル
- 再現実装 他にも色々な再現実装があるが、恐らくこれが最も高品質。しかし公式のものと比べるとだいぶ品質が落ちる。学習時間は12日間ほど?
- 日本語の解説と再現実装 Tacotronの再現がかなり大変な事がわかる。
補足
- 公式サンプルほど上手く行かない最も大きな原因は、おそらくデータセットの品質とハイパーパラメータの調整不足。
- 再現実装では、元論文のように「逆短時間フーリエ変換を微分可能にしてend-to-endで学習する」のではなく、「データセットから前処理としてスペクトログラムを抽出しておき、それをターゲットとして学習する」ということをしているものばかりだった。公式の音声サンプルほど上手く行かない理由にはこのことも関連している可能性もある。
- ただし、元論文通りの学習手法では、学習により多くの時間が必要になってしまうと思われる。
- 最新版のTensorflowだと微分可能な逆短時間フーリエ変換が実装されているらしい。
Tacotron 2 4
- Tacotronで文字からメルスペクトログラムを出力し、それをWaveNetに入力して波形を出力する。(それぞれモデル構造の改良はある)
- 実験では、2つのモデルはほとんど独立して訓練されている。(文字→スペクトログラム・スペクトログラム→波形)
- 低頻度後には弱い。
- リアルタイムな生成は難しい。
- 学習も重い。(WaveNet部分の訓練に32GPU使っている)
参考
Deep Voice 25
- 最初の図の通り、TTSシステムの書くモジュールの処理をDNNで行う。
- Deep Voiceを複数話者で話せるように改良+モデル構造改良。
- ボコーダーとしてWaveNetを使うことを初めて提案した?
- TacotronのボコーダーにもWaveNetを導入し比較している。
- Deep Voice 2の方が良いという主張。
参考
Deep Voice 3 6
- Deep Voice2とはかなり別物。
- 文字からスペクトログラムを生成する。
- 重要な点はRNNを廃してCNNを使っていることで、学習が並列化でき高速だということ。(Tacotronと同等以上の品質で一日程度で学習できると主張)
- Vocoderは何を使っても良い。Griffin Lim, WaveNet, WORLD等。
- WORLDで生成する場合、メルスペクトログラムにする前の出力をConverterと呼ばれるモジュールに入力し、WORLDで必要になる特徴量を出力する。
- 複数話者データに対応。
参考
ETTTS 7
- Deep Voice 3と同じくCNNを用いた音声生成。
- 訓練しやすいアイデアの導入。(Guided Attention)
- 複数話者データには対応していない。
- ボコーダーはGriffin Lim。
- (時間単位で)解像度の低いスペクトログラムを出力→そのスペクトログラムを元に解像度の高いスペクトログラムを出力 という生成を行う。
参考
Voice Loop8
- テキストを音素列に変換(CMU pronouncing dictionary)してからモデルに入力する。
- ボコーダーはWORLD。WaveNet等を試してみたが改善は見られなかったとのこと。
- Attentionを使った特殊な構造をしている(Memory Netowrk系)。
- "near real-time"で動作するとしている。(ただし"on an Intel Xeon E5 single-core CPU and x5 when on M40 NVIDIA GPU")
- 従来の音声合成手法の音響モデルをDNNで置き換え、複数話者対応を実現したことが重要。
参考
- 公式音声サンプル
- 公式実装 (CC-BY-NCライセンス)
- 日本語のデータセット(JSUT)で訓練したモデルの出力
- JSUTで訓練した結果をETTTSと比べると、VoiceLoopの方が音質が良いように聞こえる。(ただし、ETTTSの精度もまだ上がると考えられる。)
WaveRNN9
- 直接波形を生成する
- 推論が非常に高速(リアルタイム)
- WaveNetに劣らない品質
- 非常に浅いRNNのみで音声を合成する
- モバイルデバイス向けの工夫もある
参考
所感
WaveRNNが衝撃的でした。再現もうまくいくようであれば、TTSの研究は新しいステージへ進む気がします。
その他
- GANを使った音声合成10
- DNN音声合成のためのライブラリの紹介とDNN日本語音声合成の実装例
参照
-
Aaron van den Oord et al. WaveNet: A Generative Model for Raw Audio. https://arxiv.org/abs/1609.03499 ↩
-
Aaron van den Oord et al. Parallel WaveNet: Fast High-Fidelity Speech Synthesis. https://arxiv.org/abs/1711.10433 ↩
-
Wang et al. Tacotron: Towards End-to-End Speech Synthesis. https://arxiv.org/abs/1703.10135 ↩
-
Shen et al. Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. https://arxiv.org/abs/1712.05884 ↩
-
Arik et al. Deep Voice 2: Multi-Speaker Neural Text-to-Speech. https://arxiv.org/abs/1705.08947 ↩
-
Ping et al. Deep Voice 3: 2000-Speaker Neural Text-to-Speech. https://arxiv.org/abs/1710.07654 ↩
-
Tachibana et al. Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention. https://arxiv.org/abs/1710.08969 ↩
-
Taigman et al. VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop. https://arxiv.org/abs/1707.06588 ↩
-
Kalchbrenner et al. Efficient Neural Audio Synthesis. https://arxiv.org/abs/1802.08435 ↩
-
Saito et al. Statistical Parametric Speech Synthesis Incorporating Generative Adversarial Networks. https://arxiv.org/abs/1709.08041 ↩