2-1 実務に向けて学ぶBI応用
前章の内容だけだとまだまだ不十分。本章では実務に近い知識を学んでいく。
BIツールと他領域の接点、ビジネスとデータサイエンスの2つから学んでいく。
2-2 KPIモニタリングとKPIマネジメント
BIツールがよく用いられるのがこの2つ。KPI(重要業績評価指標)は応用情報でも触れましたね。
KPIモニタリングの利用ケース
KPIを定量化し、評価から主観などを取り除く。
全員が数値と基準の運用を信用が必要になる。信用が得られた場合、KPI次第で行動を変えていく。これがKPIモニタリング。
KPIが単なる数値として終わるのを避けるため、KPIを見れる体制を構築する必要がある。
PDCAを回しながら数値に基づいた業務改善をするのが、KPIモニタリングとKPIマネジメント。
ハンズオン
・テイクアウトアプリ_注文データ
・KPIモニタリング
・KPIモニタリング_中間シート
3つのシートのデータを使う。これらを組み合わせてダッシュボードを構築する。
1.データの加工と読み込み
KPIモニタリングシート
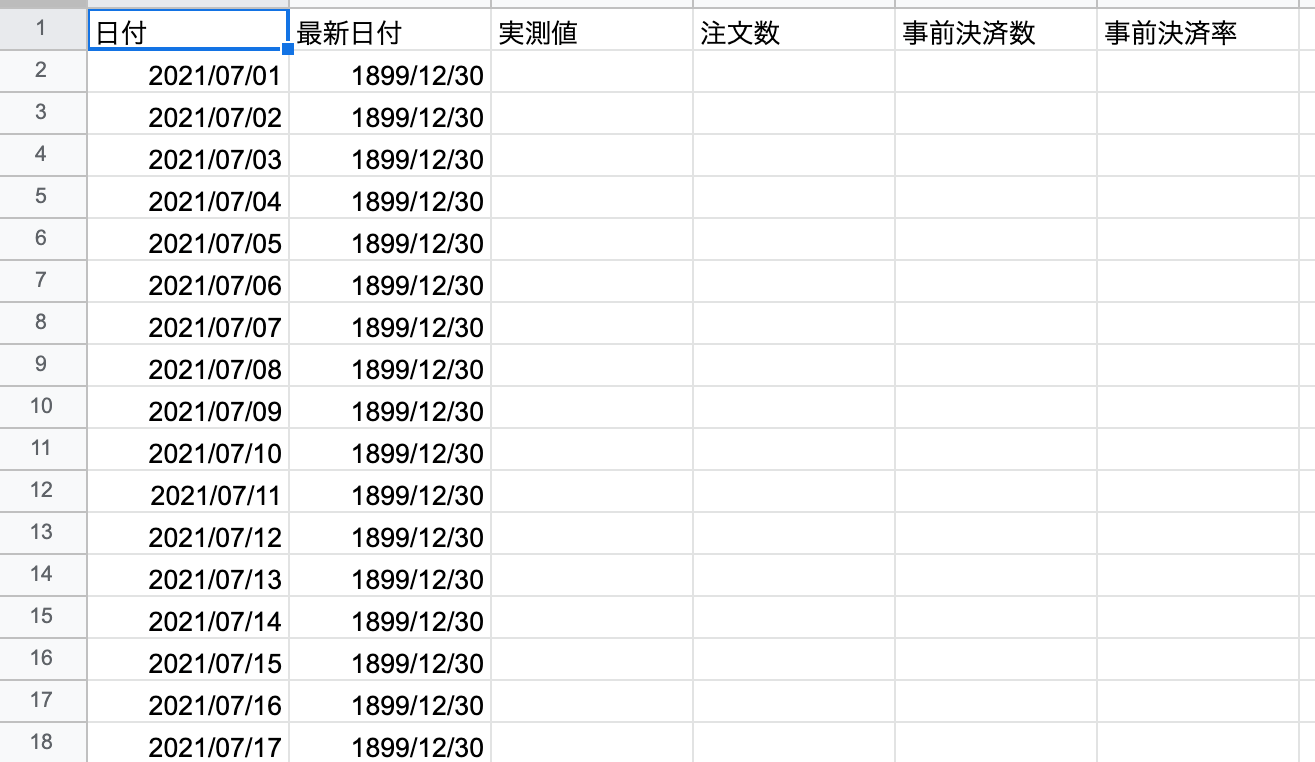
事前決済率改善の確認のため、まだ来ていない日付も表示に使う必要がある。
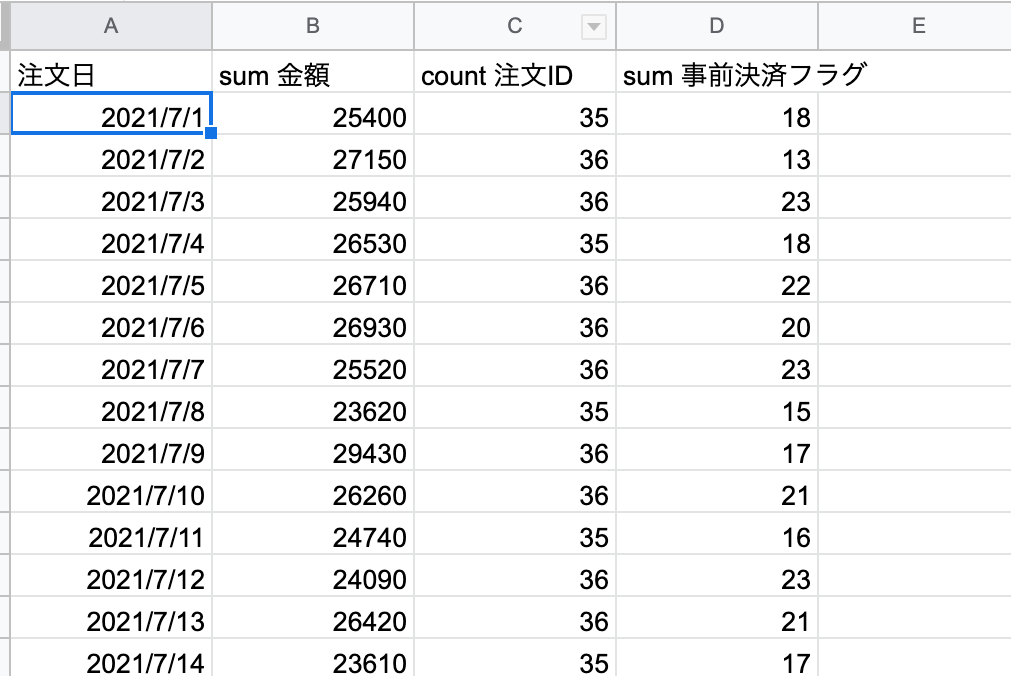
1章で使ったデータを取り込み、中間シートを作成していく。A1セルに以下の関数を入力。query(参照先,加工の内容)という書き方。where以降が削除しない条件。
=query('テイクアウトアプリ_注文データ'!A:L,"select C,sum(K),count(A),sum(L) where A is not null group by C",1)
そうするとこんな感じに。
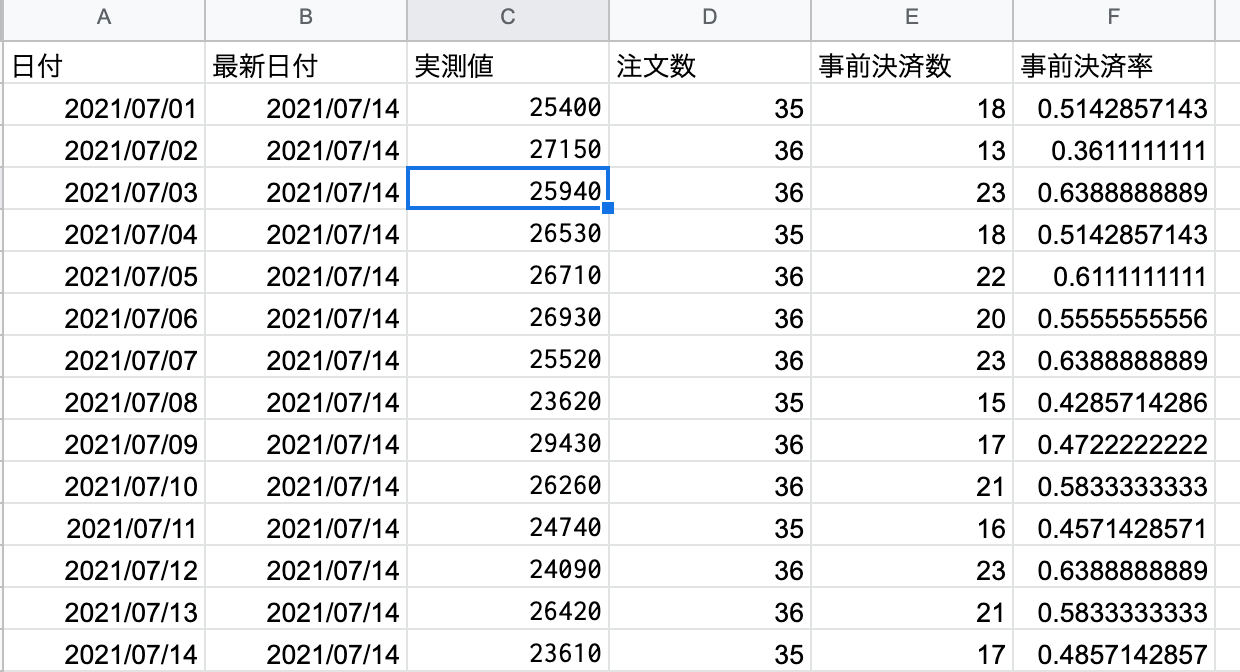
このシートの内容をKPIモニタリングシートに結合する。C2セルに以下の数式を入力。これをvlookupと呼び、データを結合する際に用いる。
vlookup(条件,結合対象データ,何列目か,0)で書く。
ifna(vlookpu(A2,'KPIモニタリング_中間シート'!A:B,2,0),"")
そしてData PortalでKPIモニタリングシートを指定したスプレッドシートを作成する。
2.上記データの可視化
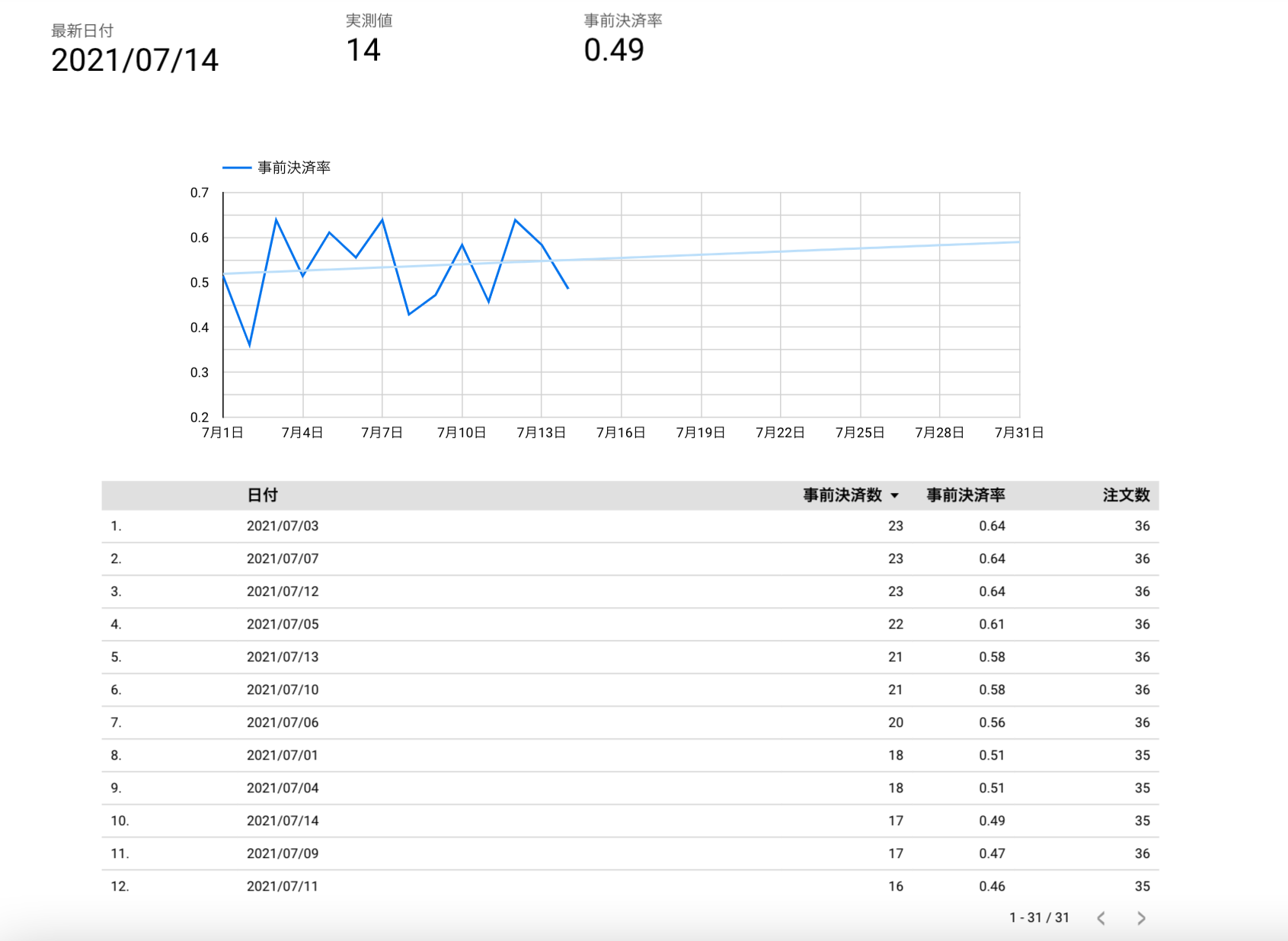
以下のグラフを作成する。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | 実測値(個数) | なし | なし |
| スコアカード | 最大日付(最大値) | なし | なし |
| スコアカード | 事前決済率(平均) | なし | 最新の日付と等しい |
| 折線グラフ | 事前決済率 | 日付 | なし |
| 表 | 注文数、事前決済数、事前決済率 | 日付 | なし |
色々やったらこんな感じに。
2-3 KPIの分析
ここでもKPIを扱っていく。
KPIの分析と利用ケース
KPIの分析は以下の手順
1.KPIの関係性の把握
一般的に複数あるKPIを整理する。1番上にくるKPIを成果KPIやKGIなどと呼び、動かす目標とする。
関係性の繋ぎ方は3つあり
・四則演算
上位のKPIを下位のKPIの計算で表現する。
わかりやすいが、行動の基準にするのが少し難しい。
・相関や因果
仮説で影響を与えそうな要因を考え、データ分析した結果を繋げる。これは説明が可能になるが、関係性の正しさや納得のできる前提を組織で揃えるのが難しくなる。
・CSF(Critical Success Factor)
これで繋ぐ場合は、やるべきことでKPIが繋がる。上位のKPIを上げるには、どのような業務や試みが必要か考える必要がある。
組織の実際の行動に近い形で表現ができるが、組織の戦略を考慮する必要がある。
2.課題発見
関係性を整理しつつ、問題を探す。理想を設定し、それと比較しながら探すのがポイント。
3.解決策の検討
単純な提案にとどまらないようにする。
ここでの分析方針は2つある。
・上手くいっているパターンを見つけ、同様のものを探す
これはデータの可視化、定量化を行い、外れ値を見つけることで行う。
・KPIを作り出す構造を分解し、悪い部分を見つけ、そこに施策を実施する
これはいろんな分析を用いて、ボトルネックを見つける。
ハンズオン
・テイクアウトアプリ_注文データ
・テイクアウトアプリ_行動データ
・テイクアウトアプリ_行動マスター
3つのシートのデータを使う。行動マスターからファネル番号を取得する。
行動データシートに以下のようにvlookupを入力。
=VLOOKUP(D2,'テイクアウトアプリ_行動マスター'!$A$1:$B$4,2,0)
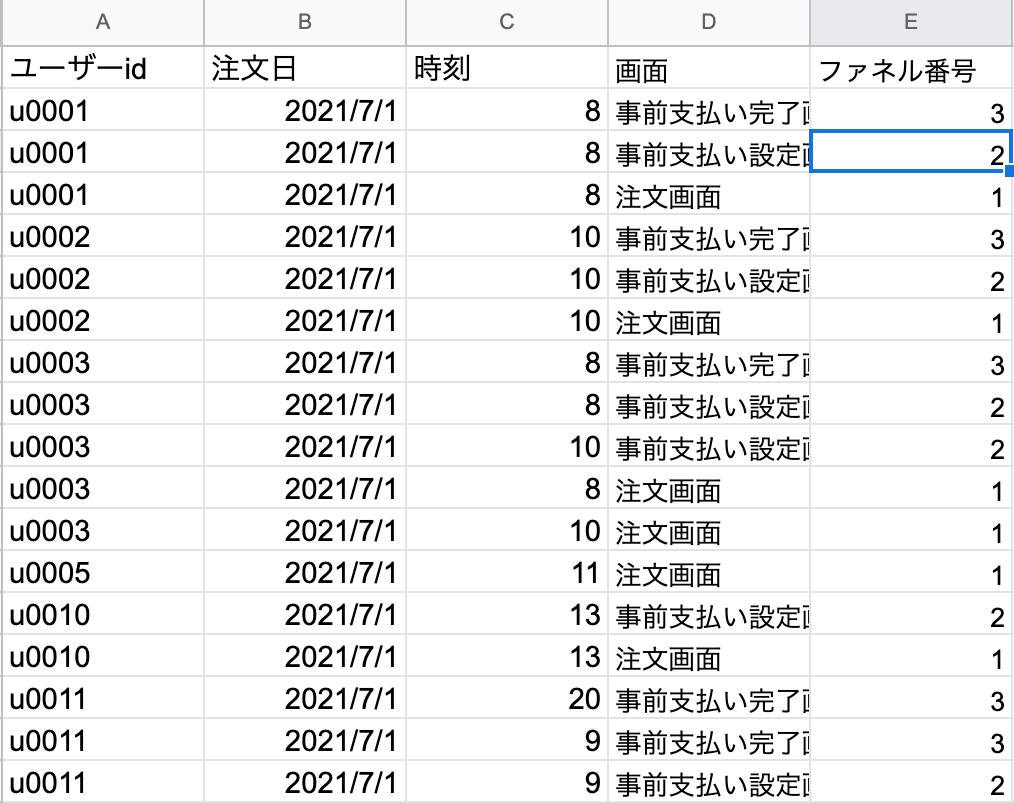
ファネル番号の取得が完了。
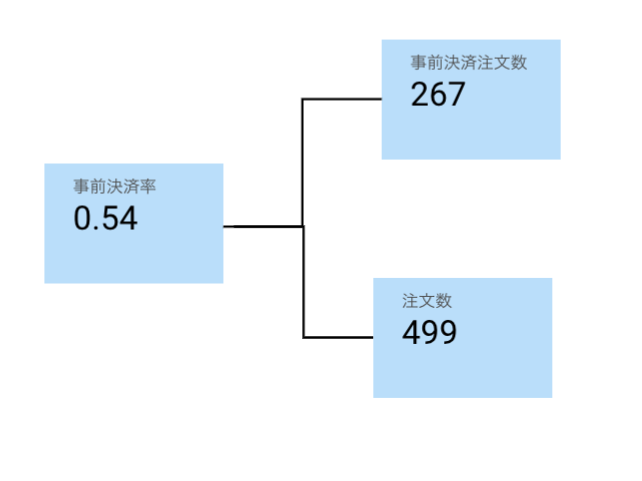
1.KPIツリーを作る
以下のスコアボードを追加。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | 事前決済率(平均) | なし | なし |
| スコアカード | 注文数(合計) | なし | なし |
| スコアカード | 事前決済グラフ(合計) | なし | なし |
色々やったらこんな感じに。
2.解像度を上げる
定量化できていないKPIを別のデータで可視化する。
以下の2つのグラフを作成する。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 棒グラフ | Record Count | 画面 | なし |
| 折線グラフ | Record Count | 注文日、画面 | なし |
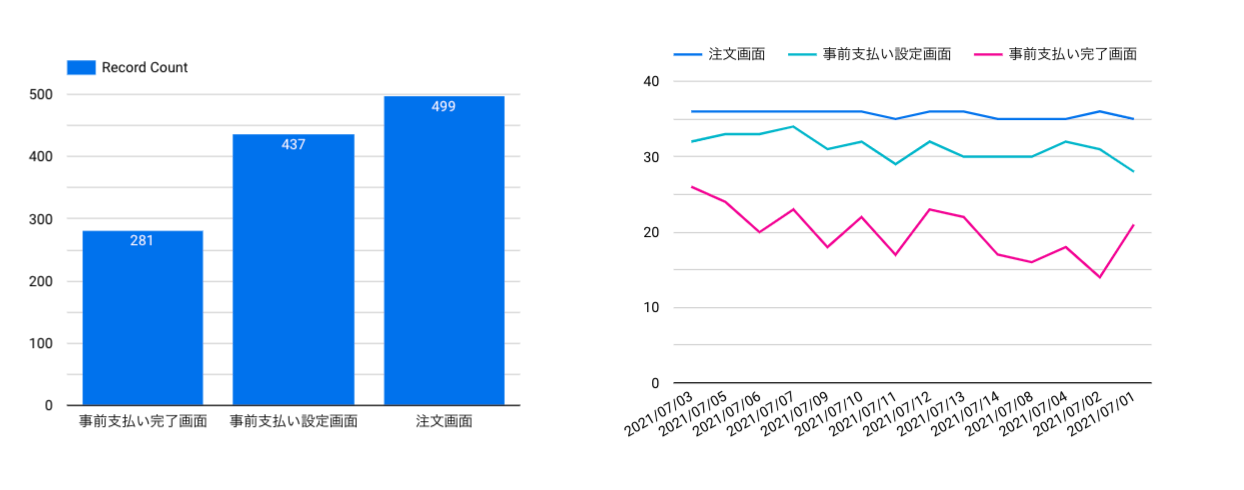
棒グラフで問題を確認できるように。設定画面まではいっているのに、完了している数が少ないので、設定画面に問題があることが考えられそう。
2-4 意思決定のための分析
ここでは意思決定にデータを用いるケースを扱う。
意思決定のプロセスとしては
1.意思決定の評価軸と基準の決定
2.選択肢を洗い出す
3.選択肢の評価軸を埋める
4.比較し、基準に基づいて決める
前半が大事で、ここがしっかりしてないと後半が始められない。基準や軸を作る際にもデータや統計の考えを用いることができる。
良い意思決定は将来的にもプラスになる。
ハンズオン
今回は
・テイクアウトアプリ_注文完了ログ
だけを使う。受け渡しに関するデータが記録されている。
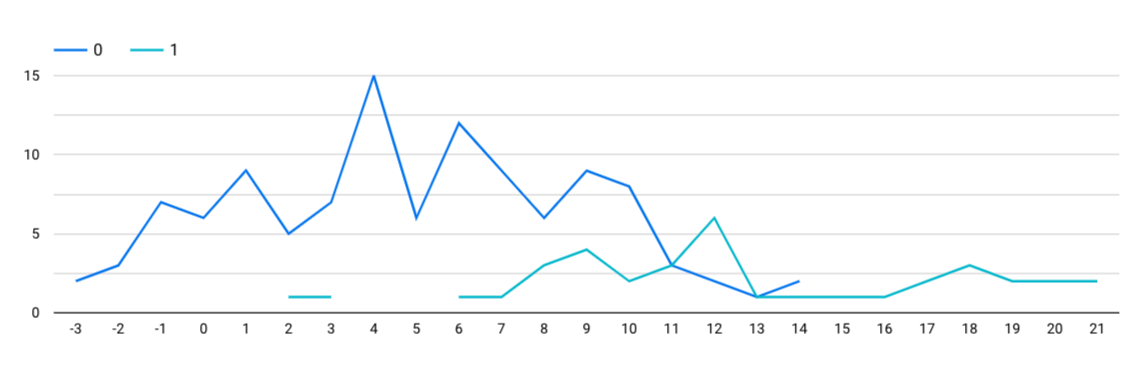
1.データの読み込みと全体の把握
経過時間ごとに差があるか確認するグラフを作成する。これを参考に、キャンセル判断の閾値を決定する
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 折線グラフ | Record Count | 受け取り予定時間、キャンセルグラフ | なし |
時間経過とキャンセルの有無の関係性がわかるようになり、操作の入れ替わりのタイミングを閾値にすると良さそう。
2.シミュレーションの作成
判断のためのシミュレーションを作成していく。閾値を動的に変えて試すために、パラメータを作成する。デフォルトは上記を参考に11でやっていく。
パラメータを用い、以下の2つのグラフを作っていく。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| ピポットテーブル | Record Count | 閾値超えセグメント | なし |
| 円グラフ | Record Count | 操作 | 受け取り予定時間が閾値以上 |
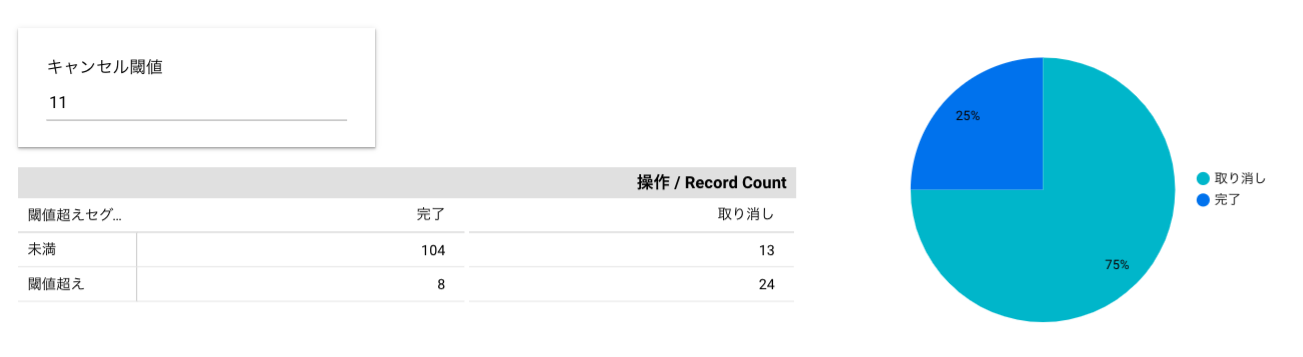
こんな感じで作成できました。
3.上段グラフの作成
最後に上端に判断タイミングごとに、結果がどう変わるか表示する。
フィルターを変えて3つ作る。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 円グラフ | Record Count | 操作 | 受け取り予定時間が11以上 |
| 円グラフ | Record Count | 操作 | 受け取り予定時間が13以上 |
| 円グラフ | Record Count | 操作 | 受け取り予定時間が15以上 |
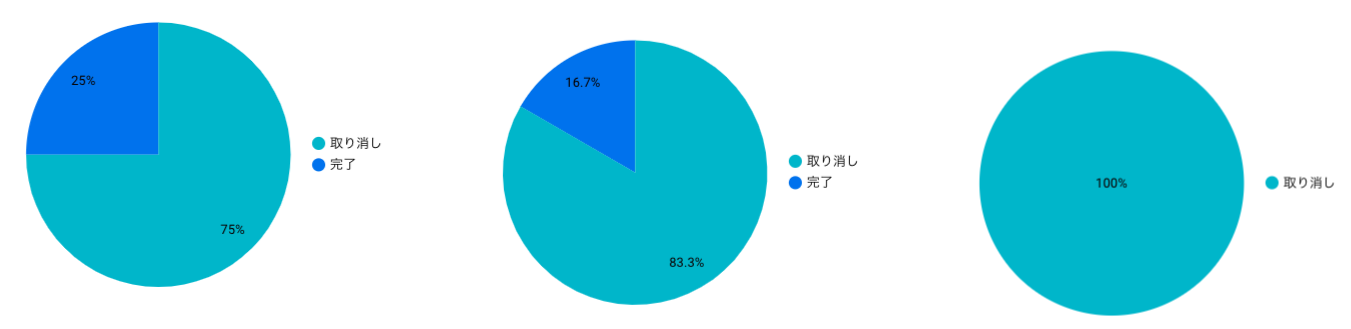
作成した3つのグラフを見ていくと、キャンセルのタイミングは15分以降になっている。
また、時間ごとの失敗率がわかる。その失敗率によって得られる期待値が、また判断材料となる。
2-5 業務情報を検索するダッシュボード
ここでは細かい情報探索にBIツールを使うケースを扱う。
ハンズオンでは情報収集のためのダッシュボードを作成していく。
これには2つのメリットがあり
1.情報の伝達
蓄えたデータにより、意思決定に失敗がしにくくなる。
2.データの統一化
全員が同じツールを使い、データを統合することで、やり取りを減らせる。
ハンズオン
地理情報を可視化していく。使用するデータは1つだけ。
・チラシ配りデータ
1.データの読み込みと地図の作成
以下の地図表示を設定。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| Googleマップ | Record Count | 位置を住所、ツールチップを場所 | なし |
こんな感じに。指標で大きさや色が変わるっぽい。
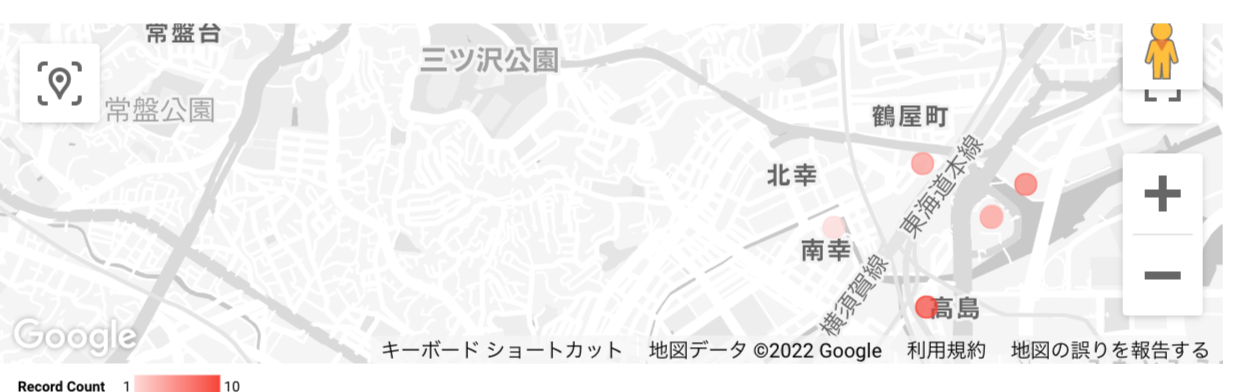
2.その他のグラフの作成
地図以外を追加する。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | Record Count | なし | なし |
| スコアカード | 配り時間(分)(平均) | なし | なし |
| スコアカード | 平均配布率(平均) | なし | なし |
| スコアカード | 平均チラシ枚数(平均) | なし | なし |
| 表 | 指標を配り時間(分)、チラシ枚数、配布率 | 日付、曜日、場所、開始時刻 | なし |
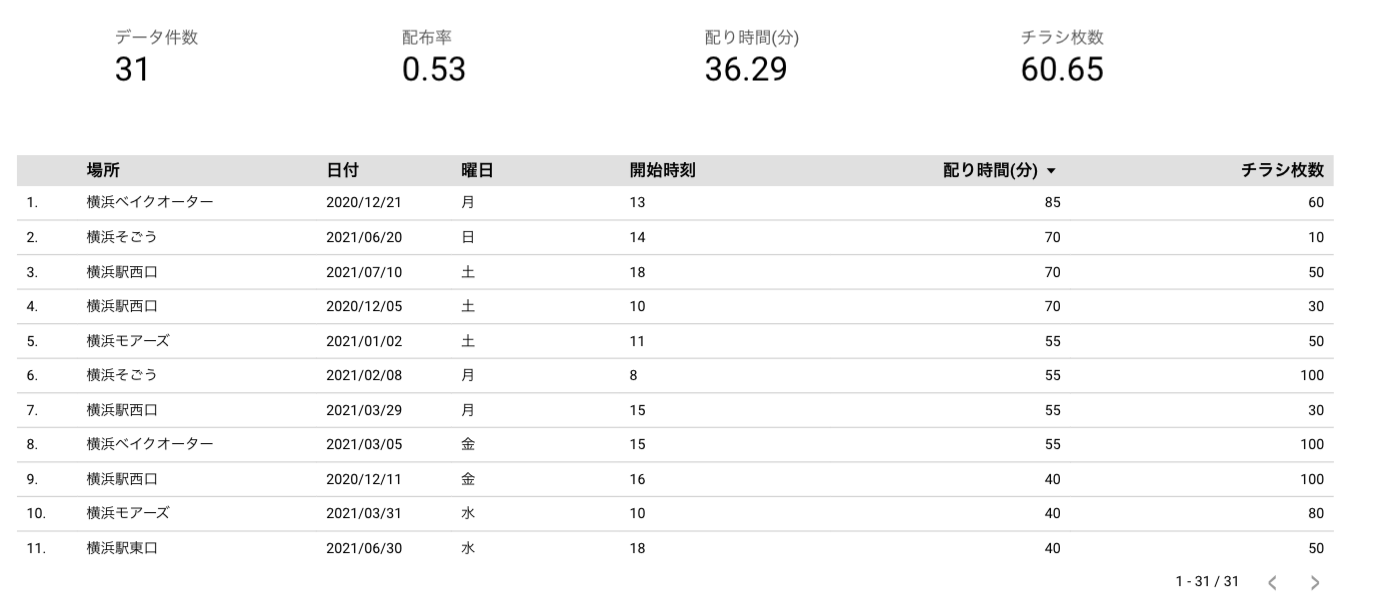
ここらへんもだいぶ手慣れてきました。
3.コントロールと入力の追加
コントロールを追加。フィルターで調べたいものを絞れるように。

2-6 データサイエンスを取り入れる:単回帰分析
ここからはデータサイエンスを扱う。
BIツールとデータサイエンスの関係性
ここではデータサイエンスを統計学や機械学習の手法を用いて、科学的に考える分析プロセスと設定する。
現在のBIツールではデータサイエンスのアウトプットと似たものを出力することはほぼできない。
データサイエンスはプロセス、手法が重要で、分析支援ツールのBIツールのは別物である。
また、BIツールの多くはデータサイエンス支援ツールとしての機能はほとんどない。
簡単なデータサイエンスの分析と、そのアウトプットをBIに接続する方法をハンズオンしていく。
単回帰分析とその利用ケース
KGIは外部から与えられたり、過去の傾向から設定される。KPIはそれを達成するために連動する必要がある。
KPIを目標設定するために、数値の関係を数式で表せると良い。
単回帰分析はデータから指標間の関係性を数値化でき、その数式を得ることができる。
y=ax+bの形で表せる。
ハンズオン
ここでは
・単回帰分析_データ
・単回帰分析_分析結果
を使っていく。
1.単回帰分析の実施とBIツールで読み込みシートの用意
単回帰分析_分析結果シートにデータを転記するために
=query('単回帰分析_データ'!A:E,"select D,E where A <= date'2021-07-01'")
を入力。
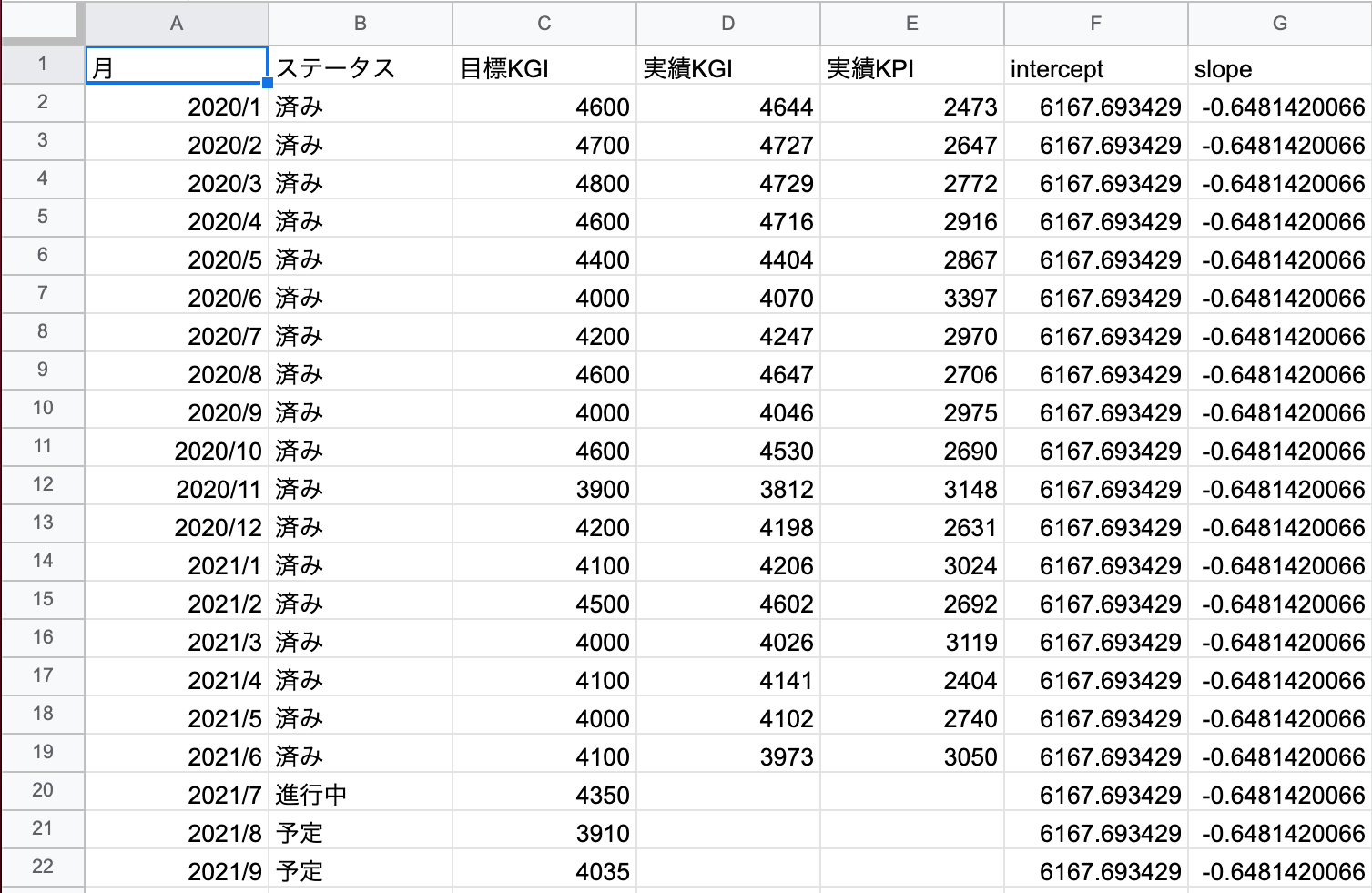
このデータに単回帰分析をかけていく。傾きは=slope()、切片は=intercept()という関数。中身は(予測の出力側、予測の入力側)といった形。切片と傾きに関数を入れるとこんな感じに。
2.BIツールで上記シートの読み込みと基本的なグラフの作成。
ここでは以下のグラフを作成。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | 目標KGI | なし | なし |
| スコアカード | KPI予測 | なし | なし |
| 散布図 | 実績KGI、実績KPI | 月 | なし |
| 表 | 目標KGI、実績KGI、実績KPI、KPI予測 | 月 | なし |
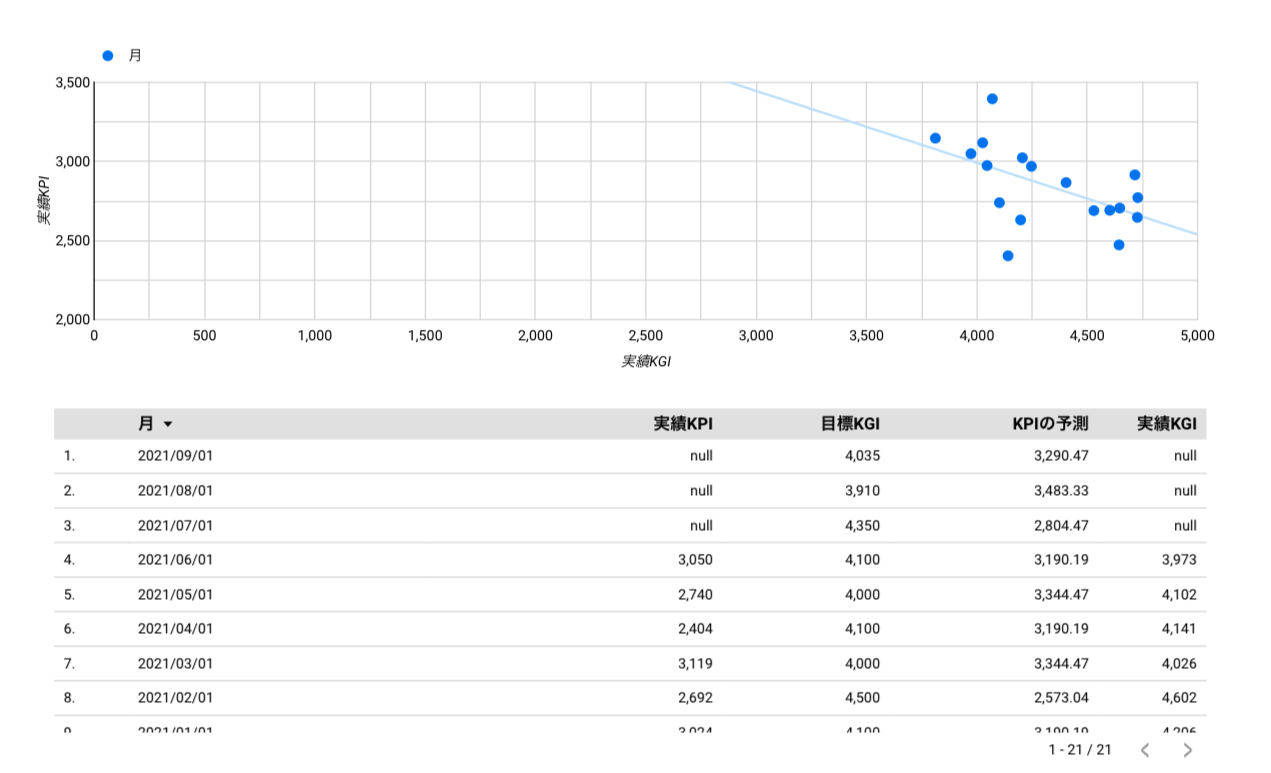
散布図と表ができました。こんなことも簡単にできるなんて、Google先生凄い。。
3.パラメータを用いてシミュレーションを作成
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | OUTPUT_KGI | なし | なし |
| スコアカード | slope | なし | なし |
| スコアカード | intercept | なし | なし |

これらをy=ax+bの形に置き換えれるっぽいんですが、記号をどこで出せるかわからないので割愛で。。
2-7 データサイエンスを取り入れる 2:時系列解析
時系列解析は
1.傾向
データの変動のこと。
2.パターン
周期的な数値があるもの。
3.上記以外のノイズ
の3つに分けることができる。周期性などを計算するために用いる。
時系列解析と利用ケース
ハンズオン
ここでは
・テイクアウトアプリ_注文データ
・時系列_分析シート
・時系列_表示シート
・時系列_イベント記録
1.時系列解析の実施
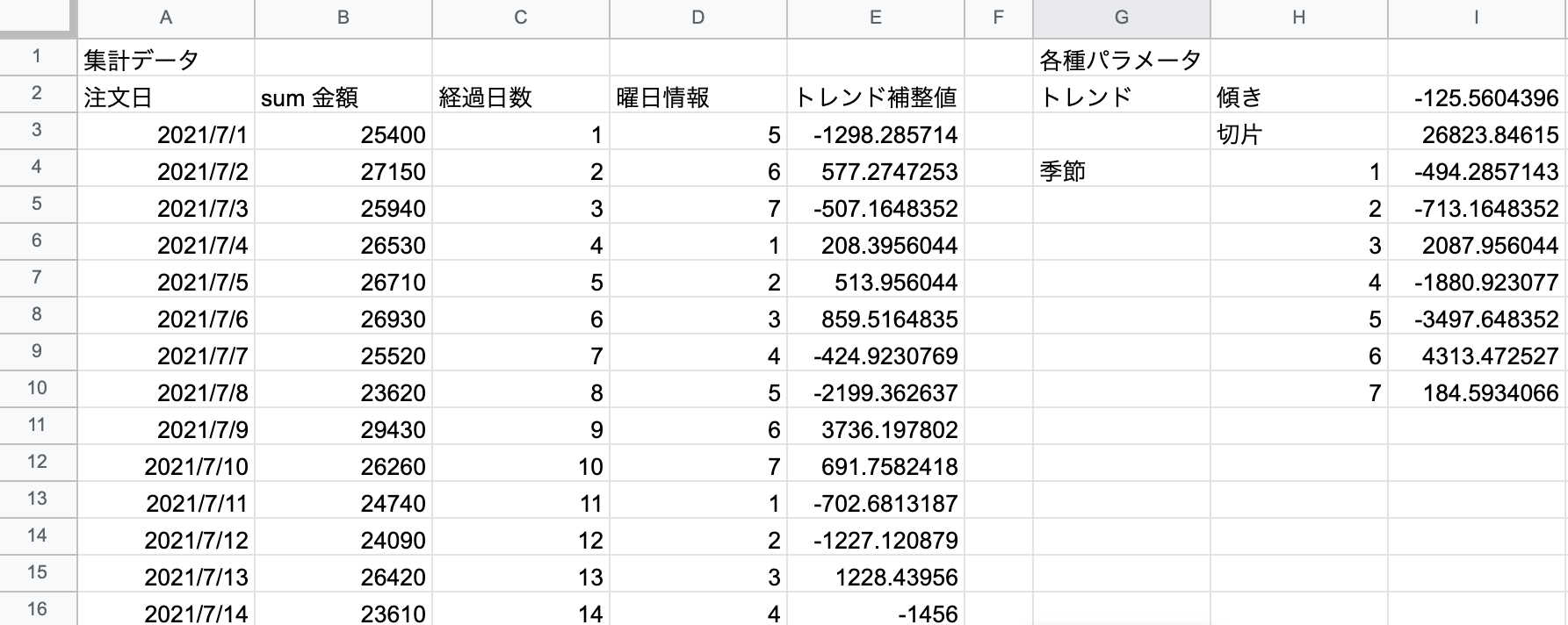
時系列_分析シートに以下のクエリを記述。
=query('テイクアウトアプリ_注文データ'!A:K,"select C,sum(K) where A is not null group by C",1)
そしたらこんな感じに。
表示シートにも転記されました。
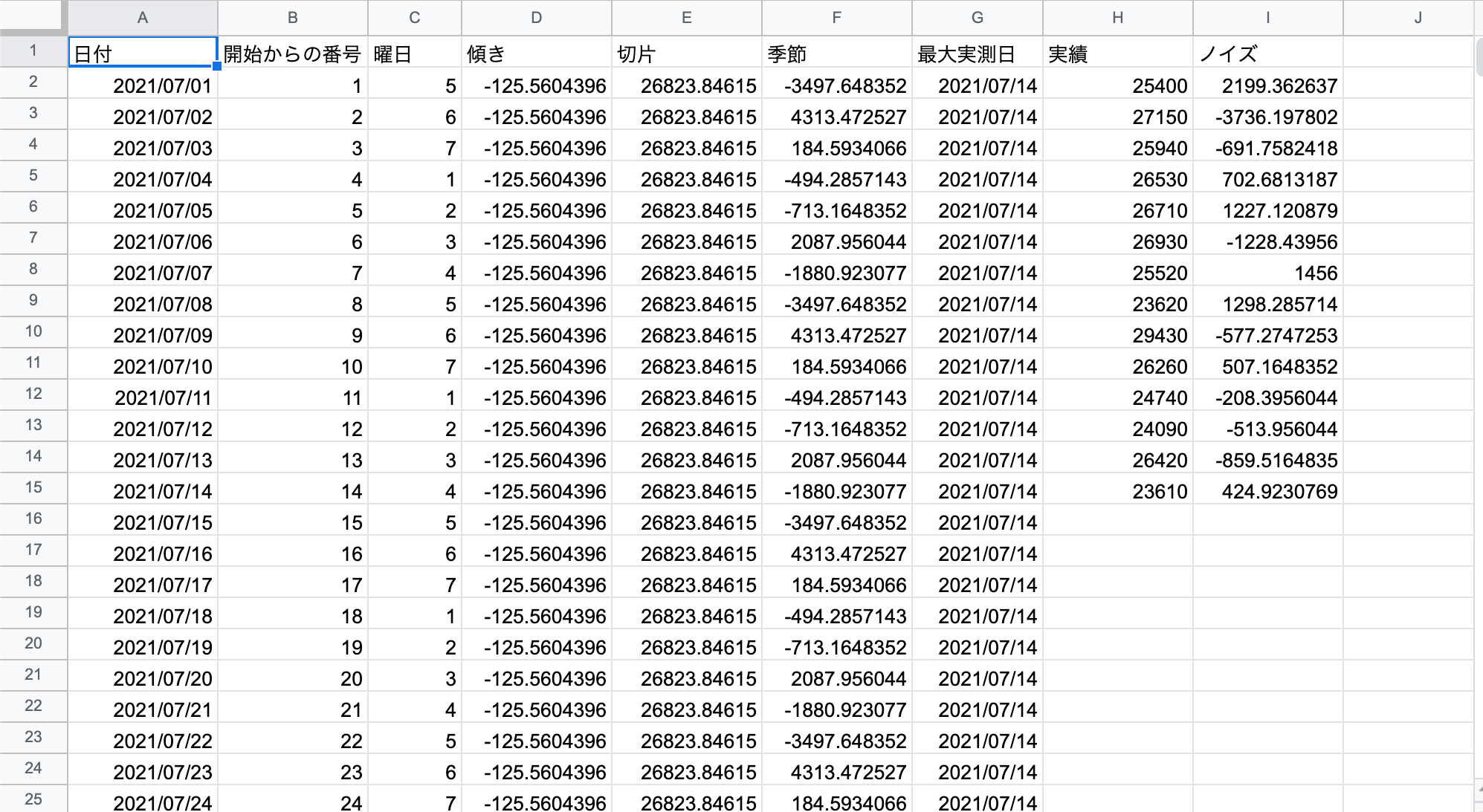
2.表示の作成
以下のグラフを作成。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | 着地予想 | なし | なし |
| スコアカード | 実績 | なし | なし |
| 折線グラフ | 実績、トレンド予測値、トレンド+季節予測値 | 日付 | なし |
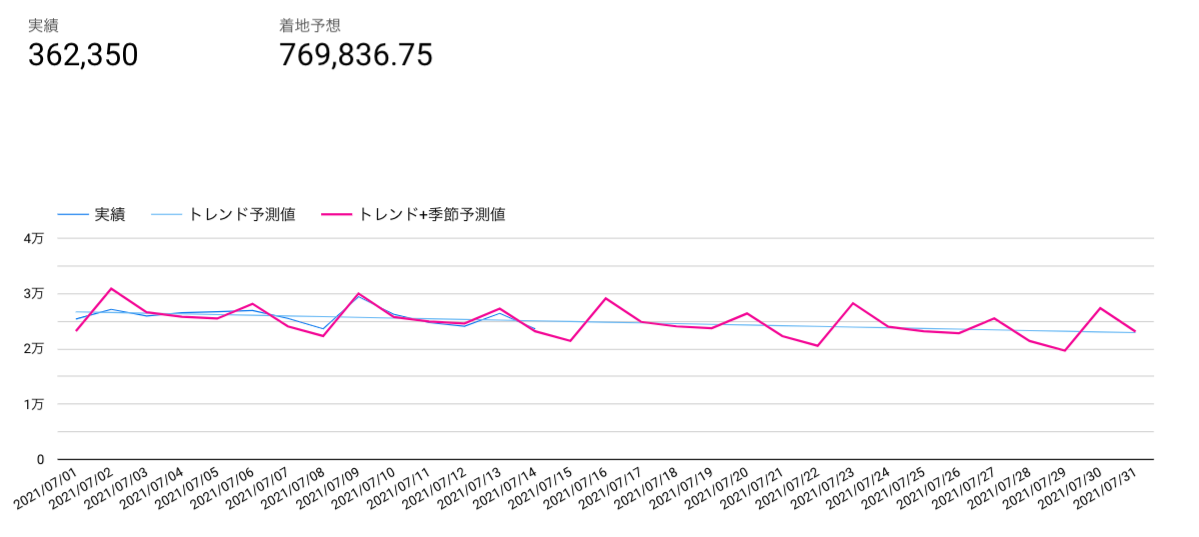
フィールドがどういった形で扱われるかを意識。関数入力の時エラーになる。
次は以下のグラフを作成。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 棒グラフ | 季節 | 曜日 | なし |
| 表 | ノイズ | 日付、曜日 | なし |
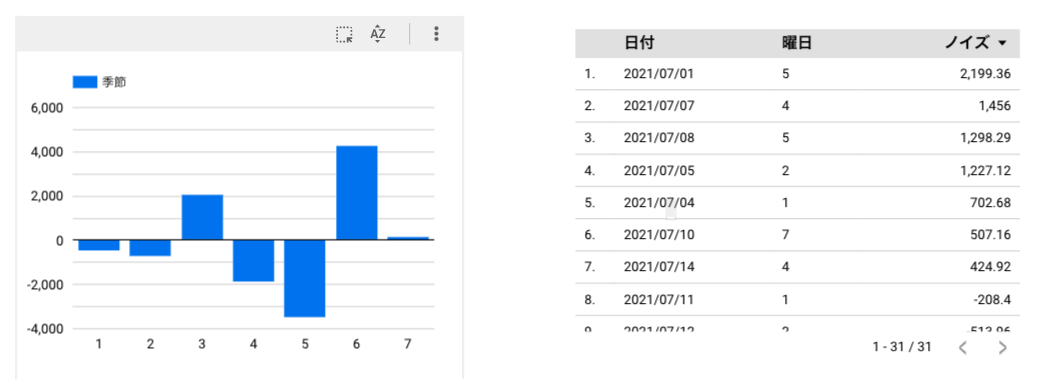
時間で値が変わっていく流れを表示できました。ただし、簡易な方法なので、複雑なものに対応できるためには高度なモデルの選択が必要。
2-8 データサイエンスを取り入れる 3:類似度
データを分けるときに、定量的にデータを見るために類似度の考えを用いる。
類似度の利用ケース
レコメンドやユーザーのクラスタリング時に用いられるが、スプレッドシードでの実装は難しい。今回はPMが新機能を作成するときに、ターゲット像を設定するために類似度を用いることにする。
ハンズオン
今回は
・類似度_ユーザーデータ
・類似度_ターゲット
を使う。
1.類似度の計算シートを作成
距離の計算では三平方の考えを使う。
距離の計算を行う計算式を入力
=sqrt(sum(Arrayformula(($B2:$D2 - '類似度_ターゲット'!$B$2:$D$2)^2)))
距離が入力されました。これで各レコードとターゲットの類似度が計算できた。
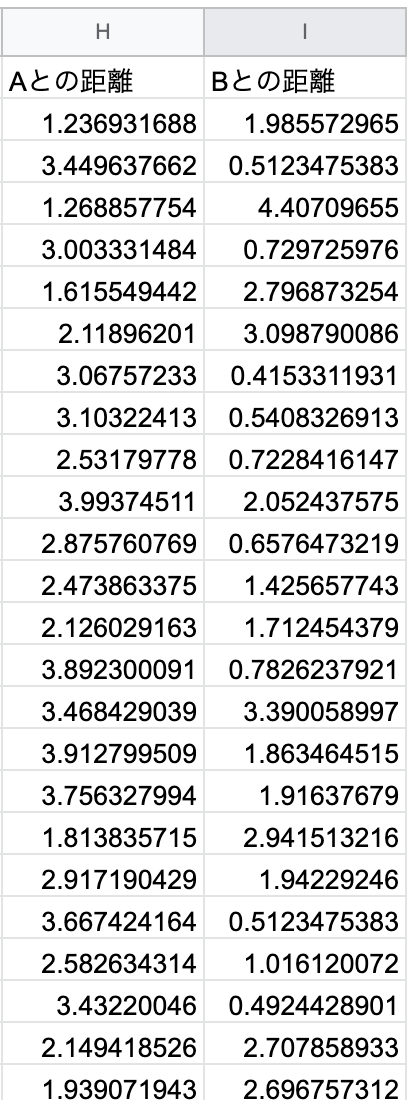
2.シートの読み込みと散布図の作成

計算を色々やったらこんな結果になったので、閾値は2.78で設定。
作成するグラフは以下。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 散布図 | Aとの距離、表示用 | ユーザーid | なし |
| 散布図 | Bとの距離、表示用 | ユーザーid | なし |
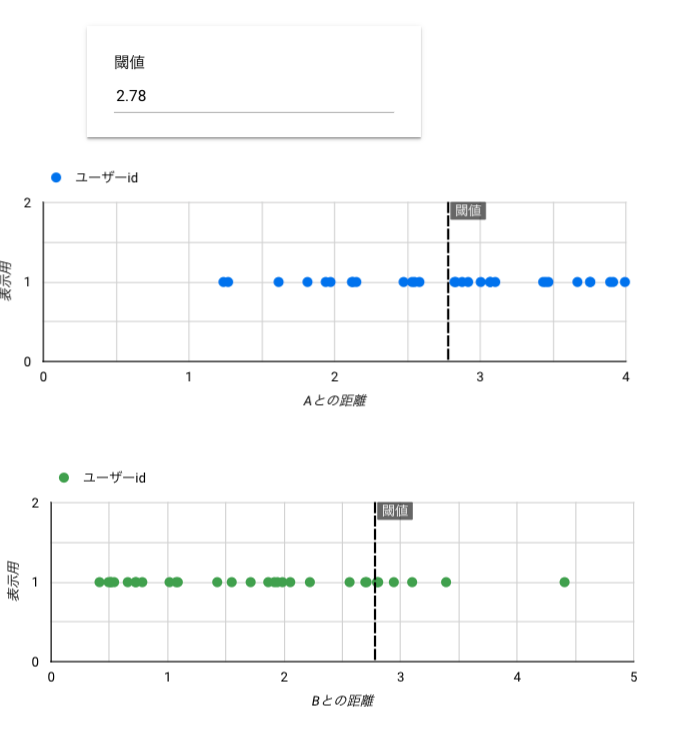
3.それぞれのターゲットに似たユーザーの情報の表示
残りのグラフを作成。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| スコアカード | Record Count | なし | Aとの距離が閾値より低い |
| スコアカード | Record Count | なし | Bとの距離が閾値より低い |
| 棒グラフ | 平均単価(M)(平均) | 表示用 | Aとの距離が閾値より低い |
| 棒グラフ | 何分おきの来訪か(F)(平均) | 表示用 | Aとの距離が閾値より低い |
| 棒グラフ | 何周おきの来訪からの経過日数(R)(平均) | 表示用 | Aとの距離が閾値より低い |
| 棒グラフ | 平均単価(M)(平均) | 表示用 | Bとの距離が閾値より低い |
| 棒グラフ | 何周おきの来訪か(F)(平均) | 表示用 | Bとの距離が閾値より低い |
| 棒グラフ | 何周おきの来訪からの経過日数(R)(平均) | 表示用 | Bとの距離が閾値より低い |
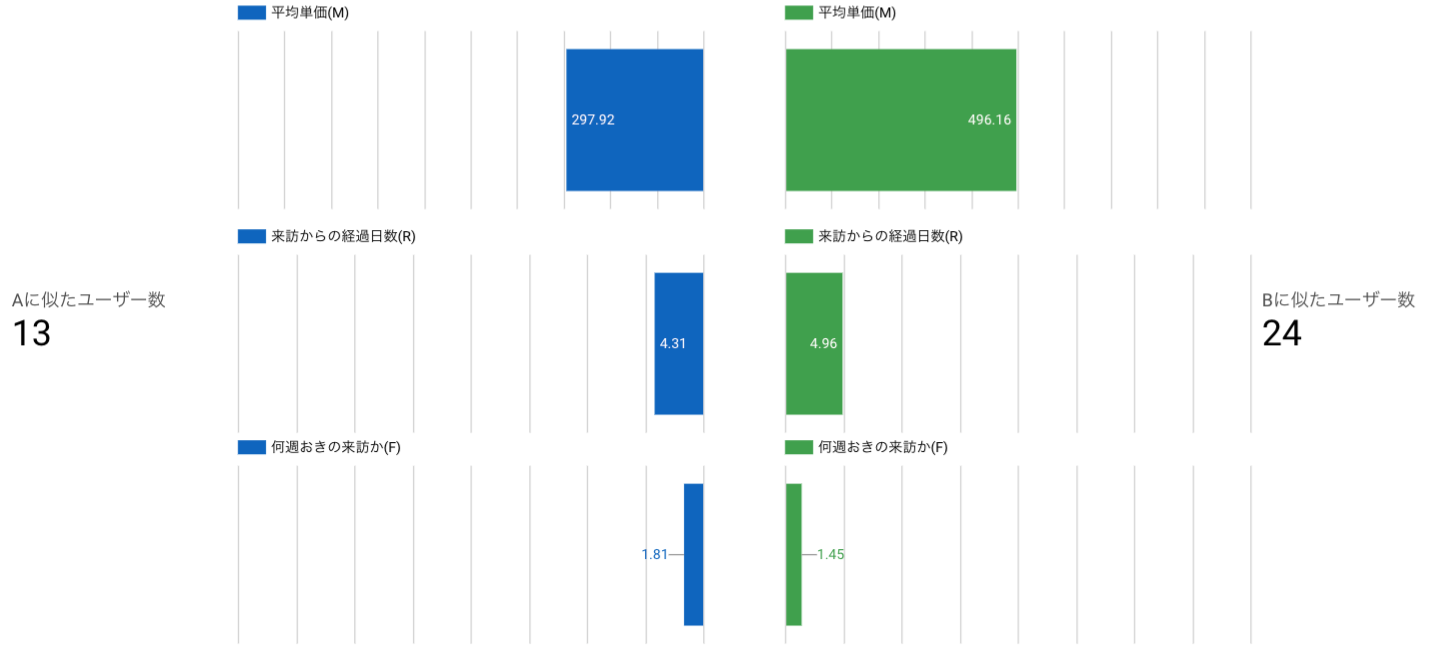
いい感じにできました。
2-9 データサイエンスを取り入れる 4:DID
DIDの利用ケース
DIDはDifferene in Differenceの略。差の差法のこと。
前後比較やグループ間比較での効果の改善時などに用いる。
DIDでは平行トレンド仮定といって、グループ間で数値の絶対値は違っても、トレンドは同じ動きをする仮定が必要になる。
ハンズオン
今回は
・DID_データ
・DID_分析結果
を使う。
1.DIDの計算を実施
データを集計し、分析結果に載せる。関数はqueryを使う。
=query('DID_データ'!A1:D32,"select B,avg(C),avg(D) group by B")
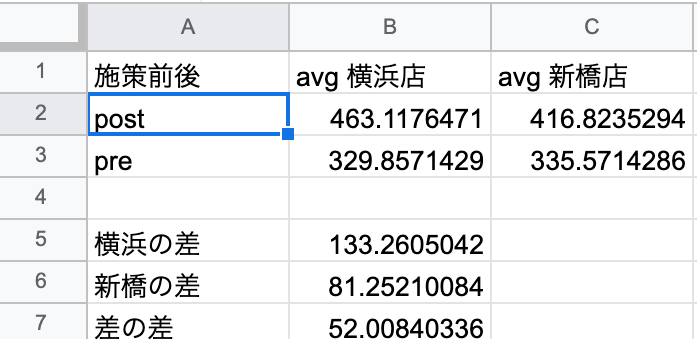
分析結果にDIDの結果が反映されました。
2.ダッシュボードの基礎の作成
以下のグラフを作成。
| グラフの種類 | 指標 | ディメンション | フィルター設定 |
|---|---|---|---|
| 折線グラフ | 表示用(post)(合計)、表示用(pre)(合計) | 日付 | なし |
| 折線グラフ | 横浜店(合計)、新橋店(合計) | 日付 | なし |
| 折線グラフ | 横浜店(累計)、新橋店(累計) | 日付 | なし |
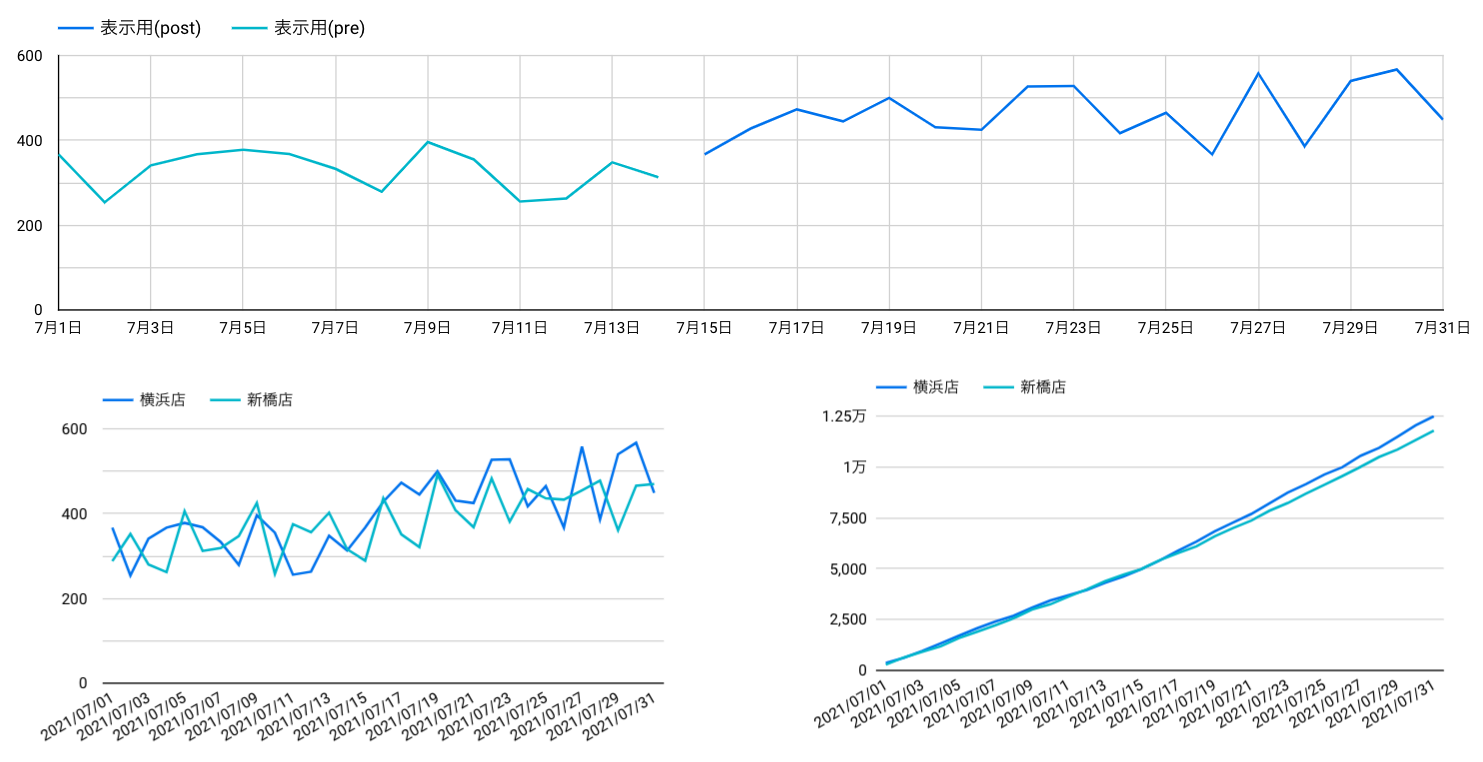
これで効果確認のダッシュボードが作成できた。
他にもダッシュボードの管理やデータの加工について学べた。
感想
手を動かしていろんなアウトプットができたのが面白かったです。
SQLとかスプレッドシートのことを勉強したらもっとうまいことを使えるようになりそう。
実際の業務でどう使われているかも気になりましたね!