はじめに
本記事では、Snowflake に突如として現れた新星「Pandas API」について、Snowflake Notebooks での実行も交えながら解説をします。

また、Snowflake Notebooks も、2024年5月末に Public Preview となった最新機能です。この機能と Pandas API の相性がデータ分析者にとって非常に良いと感じたため、今回の組み合わせでの検証を行いました。
バージョン
Pandas API は、Snowpark for Python の 1.17.0 バージョンから使用できるようになっています。ここで、Snowflake のバージョン 8.23 から Snowflake の Anaconda パッケージで Snowpark for Python の 1.18.0 バージョンが使用できるようになっています。
これにより、Snowflake上(Streamlit in Snowflake、Snowflake Notebooks、UDF/SProc など)で Pandas API を使用できるようになりました。
上記のため、Snowflake バージョンが 8.23 以上である必要があります。Snowflake バージョンについては、下記のコマンドで確認できます。
select current_version();
Pandas API とは?
Snowflake における Pandas API とは、クライアント環境で Pandas のメソッドを記述することで、Snowflake上のデータに対して SQL を発行できるようになる機能です。この Pandasメソッドから SQL の変換は Snowpark for Python ライブラリが担い、クエリの実行自体は Snowflake側で行われるため、パフォーマンスやセキュリティに関する懸念を払拭できます。
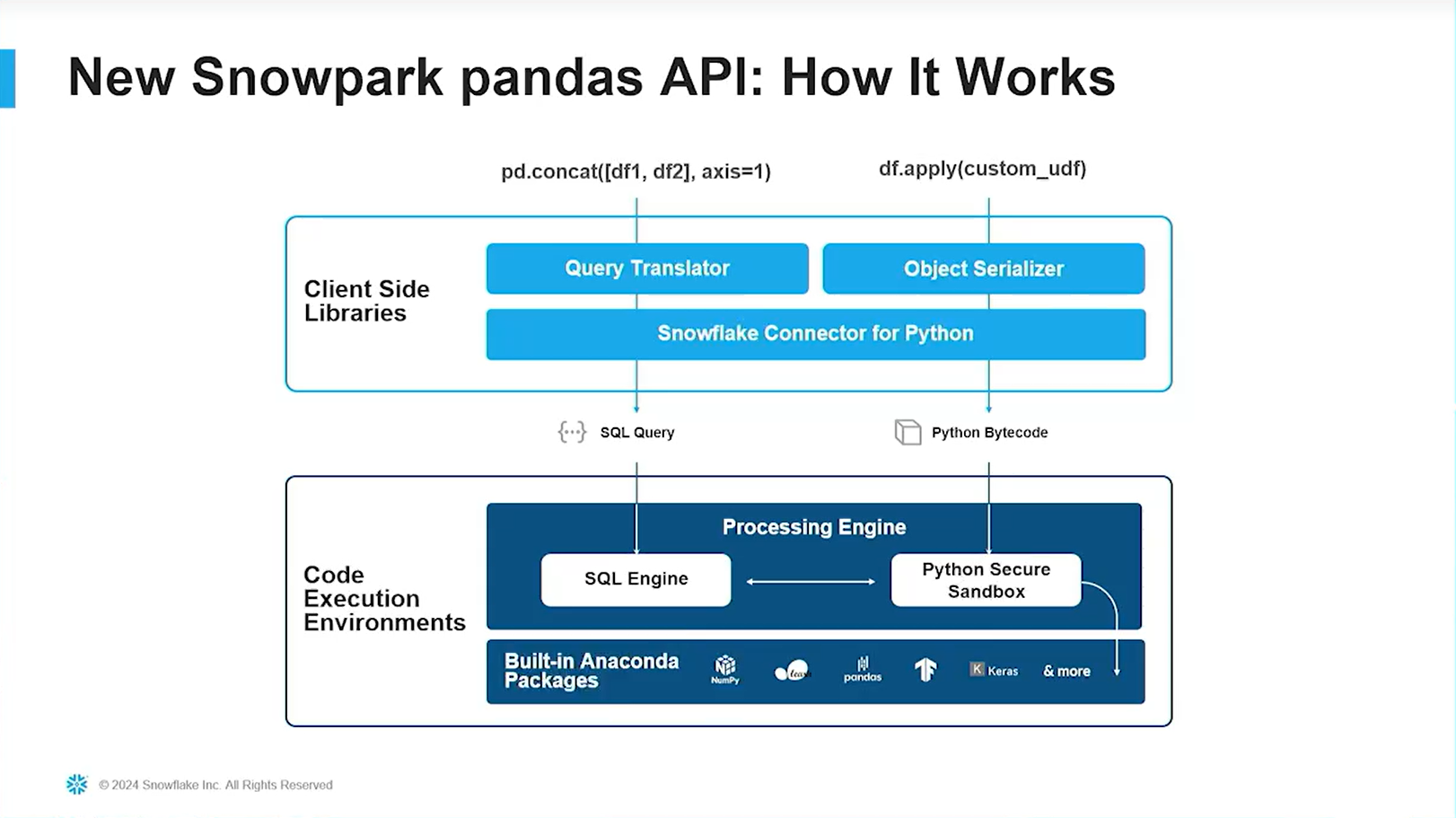
Pandas API を使用するメリット👍を改めて下記に整理します。
- パフォーマンス:Snowflake のコンピューティングリソース上で処理されるため、ローカルに乗り切らない様な大規模データに対するクエリも高速かつスケーラブルに実行できるようになる。
- セキュリティ:Snowflake のデータを Pandas で処理するためにローカルに移動する必要がなくなる。
- 開発スピード:ローカルで記述した Pandas の処理を DWH に移行するために、Spark形式のデータフレームや SQL に書き換える必要がなくなり、ライブラリと接続、テーブルの読み込み方法を変更するだけで良くなる。
Snowpark for Pythonで、Snowpark DataFrame を既に使っている方にはより分かりやすく、Snowpark DataFrame の文法が Pandas 形式に置き換わったものと説明できます。革命的であることが、伝わりましたでしょうか?👀
日本のデータ分析ユーザーは、Spark DataFrame よりも Pandas DataFrame を使っているチームも多いと思いますので、そういったチームでも導入しやすくなったのではないかと感じています。また、これが Snowflake Notebooks で実行できることも手軽さの向上に大きく貢献していますね。
なお、Snowpark Pandas API の Pandas カバレッジについて、Snowflake の公式ドキュメントに記載があり、現時点では約45%をサポートしているとのことです。ネイティブの Pandas API に対する対応有無についても一覧がまとめられているので、非常に親切ですね🥰
💡 深堀って理解:Snowpark
Snowpark とは、開発者が自由な言語で、Snowflake のデータを扱うためのブランドのことです。ブランドとしてはだいぶデカくなってきましたが、「Snowpark Container」も、そういうことだと思っています。
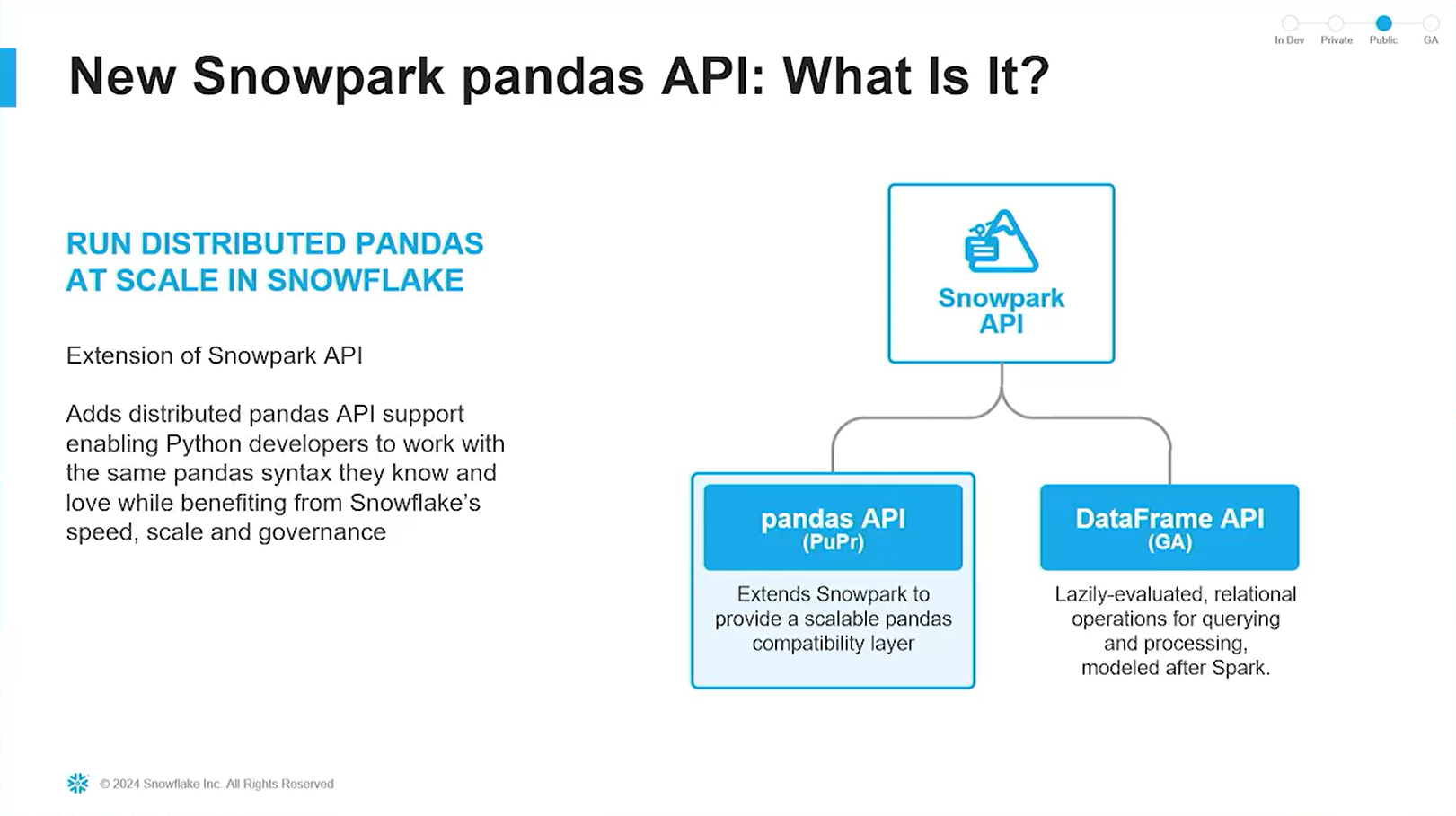
そんな「デカくなってきた」Snowpark ですが、その根幹は登場当初より変わっておらず、下図のような T字の機能群からなります。

左から、データ操作 API や ML API、そしてスケーラブルな関数(UDF)、ストアドプロシージャの 3種類です。今回のテーマである「Pandas API」は、データ操作APIの中の新機能という訳ですね。
Pandas API on Snowflake Notebooks
それでは、Pandas API を Snowflake Notebooks で使用してみましょう。
事前準備🛠️
まず、Snowflake の Web UI である Snowsight にログインします。そうすると、左側のナビゲーションバーで、Projects>Worksheets が選択された状態の画面に遷移するはずです。
Worksheets からは、主に SQL を実行することができます。その他、Notebooks や、Streamlit in Snowflake などについても、この Projects の項目からアクセスでき、右上の+ボタンから作成を行えます。
Snowflake のアカウントやユーザーをお持ちでない場合は、トライアルアカウントを発行することでも、本記事の内容を実行できます。
Notebooks の起動
それでは、Notebooks を作成しましょう。Projects>Notebooks とクリックし、青い+Notebooks をクリックすると、下記のような設定画面が表示されます。(データベースやウェアハウスが存在しない場合は、先述のワークシートから SQL コマンドで作成しておきます)
そうすると、下記のようなNotebooksが表示されます。サンプルで記述されている内容は、削除しておきましょう。また、今回は SQL セルは使わないため、Python セルに戻しておきます。
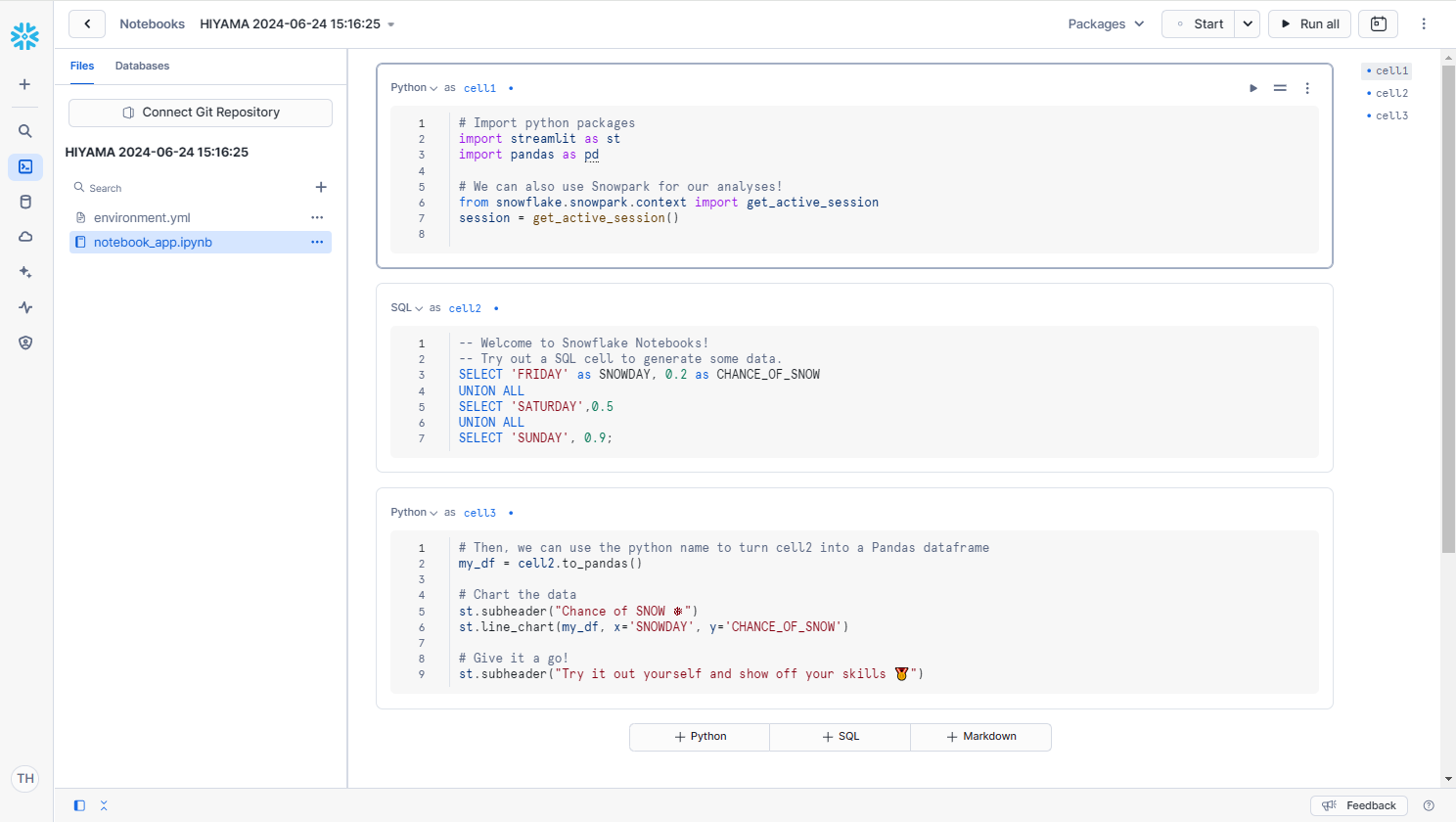
基本的には直感的に操作できる UI になっているため、詳細な解説は省きます。これを機に、色々と触って遊んでみてください!
ライブラリのインポート
ライブラリのインポートも、GUI で非常に簡単に行えるようになっています。右上の「Packages」をクリックし、「Find Packeages」欄に下記のライブラリを入力します。
- snowflake-snowpark-python >= 1.17.0
- modin >= 0.28.1
- pandas >= 2.2.1
上記の最小限のInstalled Packagesを選択した状態は下記のようになります。
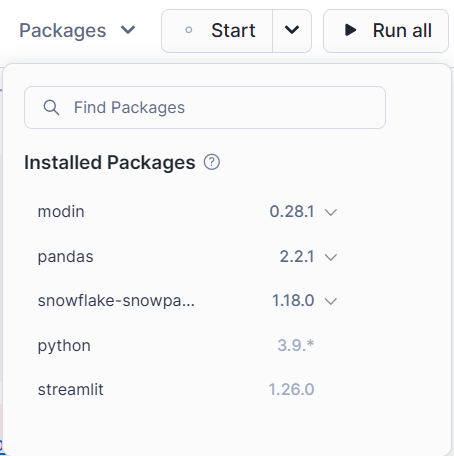
上記のUIから、簡単に使用するライブラリやそのバージョンを変更することができます。
なお、この Notebooks 上で使用できるライブラリは、AnacondaのSnowflakeチャンネルにリストされています。使用したいライブラリが存在しない場合は、データベース内のステージに格納して即座に使用できるようにするか、Anaconda の Snowflake チャンネルにリクエストを送信することができます。
そして、Notebooks上に下記のインポート文を記述します。
import modin.pandas as pd
import snowflake.snowpark.modin.plugin
import streamlit as st
from snowflake.snowpark.context import get_active_session
session = get_active_session()
また、Pandas API を使用するためには、Snowflake とのセッション接続が必要となります。そのために、上記コードでは、セッション情報を取得する関数を使用してセッションを作成しています。
Pandas API の操作🧮
データフレームの作成と保存
それではまずは、リストから Snowpark Pandas DataFrame(以後 Pandas DataFrame)を作成し、それを Snowflake テーブルとして保存する処理を確認します。
df = pd.DataFrame([['a', 2.1, 1],['b', None, 2],['c', 6.3, 3]], columns=["COL_STR", "COL_FLOAT", "COL_INT"])
st.write("■リストから作成したSnowpark Pandas DF")
st.dataframe(df)
df.to_snowflake("pandas_test", if_exists='replace',index=False)
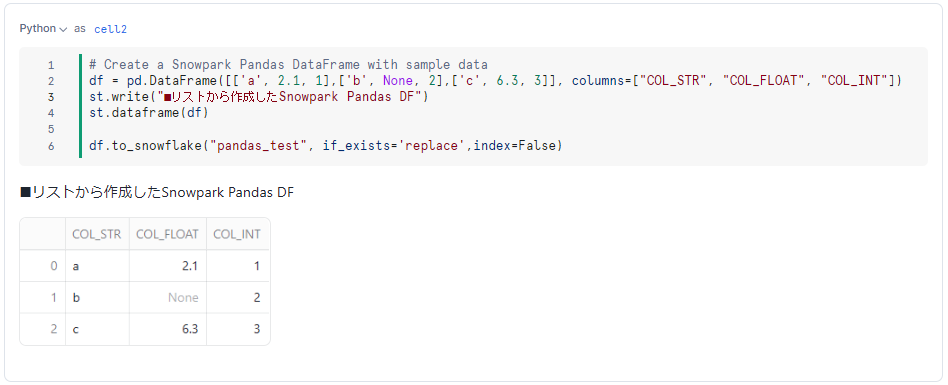
上記の結果からは、テーブルに保存されたかどうかは確認できません。そこで、Snowsight の UI へ戻り、データベースの中を確認してみます。
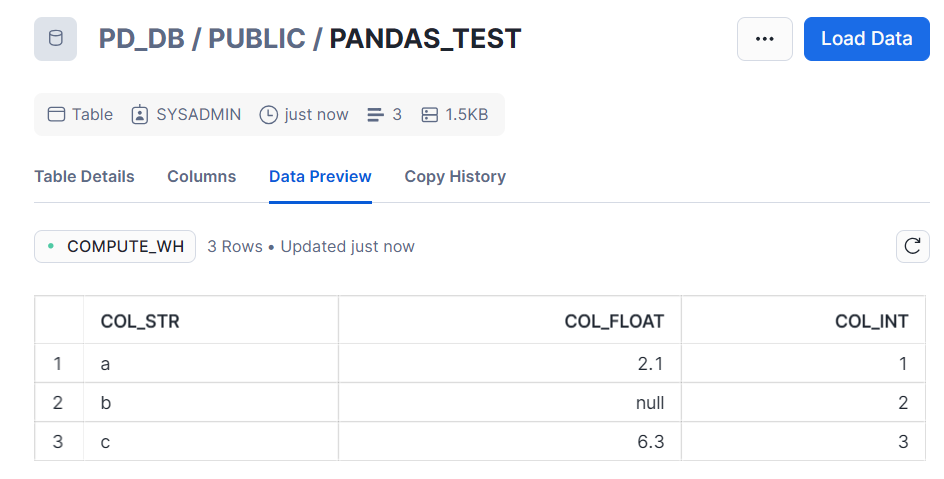
無事に作成できていますね!
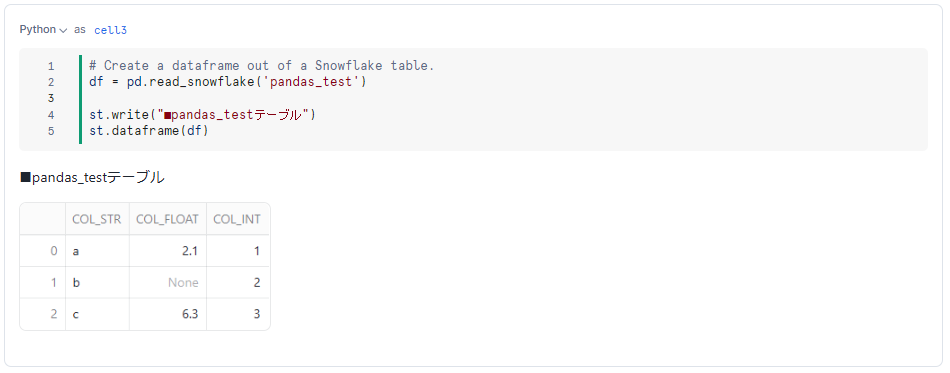
続いて、このテーブルを Pandas DataFrame として読み込む方法を確認します。こちらも、同様に、pd.read_snowflake()メソッドを使って簡単に読み込めることが確認できます。
df = pd.read_snowflake('pandas_test')
st.write("■pandas_testテーブル")
st.dataframe(df)
なお、今回の例ではリストやテーブルからデータフレームを作成しましたが、ローカルや Snowflake ステージに格納されているファイルからpd.read_csv()やpd.read_parquet()などを使ってデータフレームを作成することもできます。詳細はこちらのPandas APIの入出力ページをご確認ください。
四則演算
それでは、Snowpark Pandas DataFrame の処理を確認していきましょう。
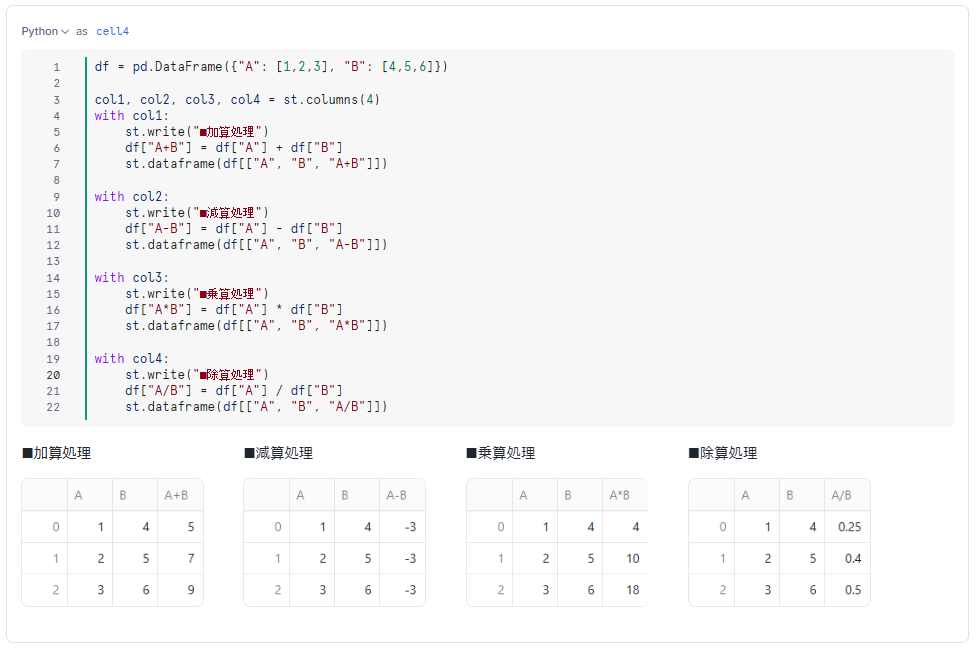
ここでは、カラム同士の四則演算結果を求めてみます。Pandas API であれば、下記のように簡単に列同士の合計値などの計算を行えます。
df = pd.DataFrame({"A": [1,2,3], "B": [4,5,6]})
col1, col2, col3, col4 = st.columns(4)
with col1:
st.write("■加算処理")
df["A+B"] = df["A"] + df["B"]
st.dataframe(df[["A", "B", "A+B"]])
with col2:
st.write("■減算処理")
df["A-B"] = df["A"] - df["B"]
st.dataframe(df[["A", "B", "A-B"]])
with col3:
st.write("■乗算処理")
df["A*B"] = df["A"] * df["B"]
st.dataframe(df[["A", "B", "A*B"]])
with col4:
st.write("■除算処理")
df["A/B"] = df["A"] / df["B"]
st.dataframe(df[["A", "B", "A/B"]])
なお、これらを実行した後、Snowsight からクエリヒストリーを確認すると、下記のようなクエリが実行されています。今回は、加算処理について確認します。
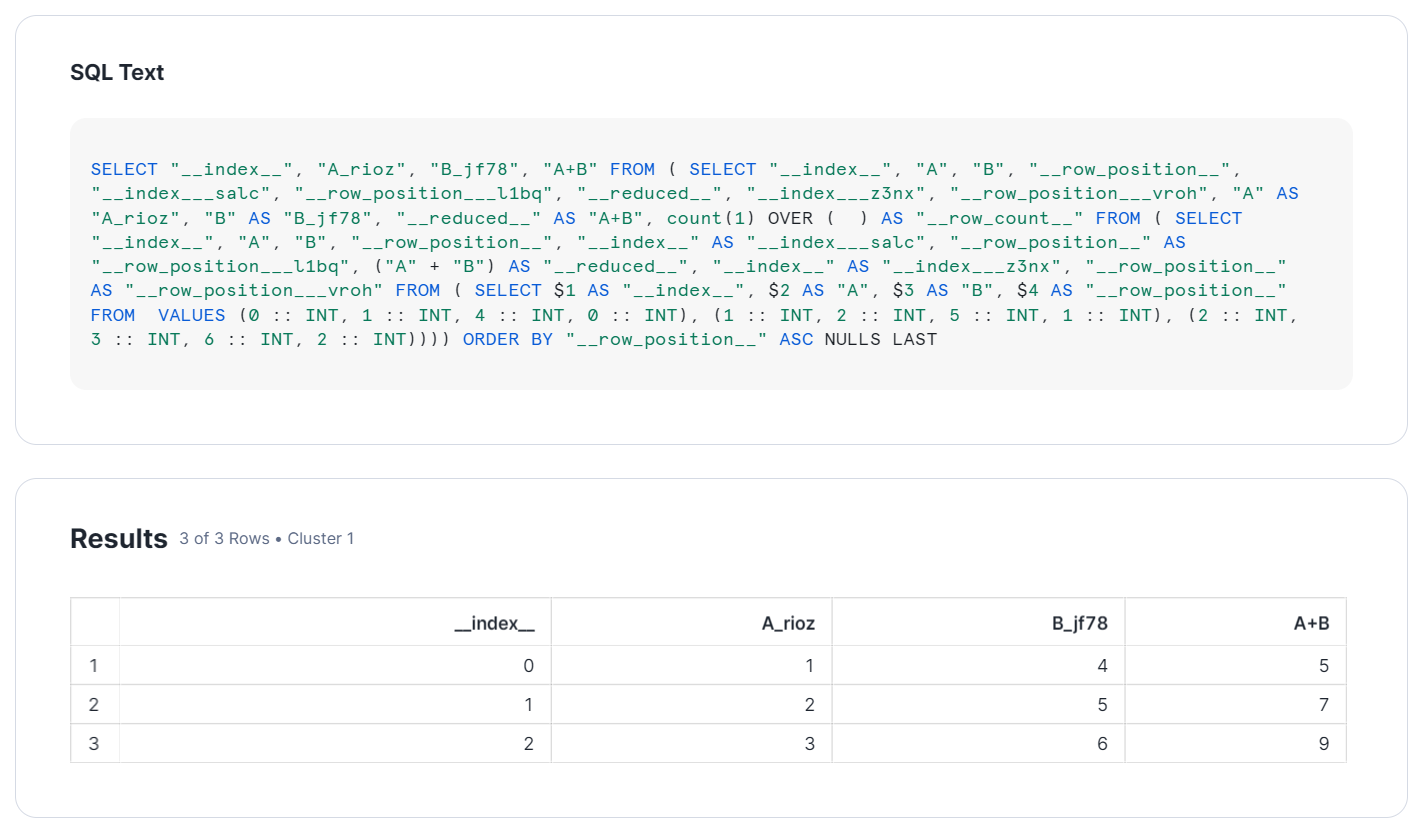
自動生成されたクエリのため若干わかりにくいですが、Pandas で記述した処理が、SQL クエリに変換されていることが分かるかと思います。
💡 深堀って理解:遅延評価とインデックス
詳細には、リストから作成されたデータフレームのため、VALUES 文によって生の値が読まれています。その後に、SELECT 文で加算処理が行われています(SQL 文中程の("A" + "B"))。
このように、複数行の処理(データフレームの作成と加算処理)が一括で行われていますが、これは、Snowpark DataFrame と同様、遅延評価というクエリ実行戦略に基づくものです。Snowpark DataFrame や Snowpark Pandas DataFrame では、表示や保存といった処理のときに初めてクエリをコンパイルします。これにより、最適なクエリ実行を行えます。
また、結果列に「__index__」がありますが、Snowpark Pandas では、行の順序がこのように担保されるようになっています。
集計とグループ化
もちろん、集計クエリやグループ化クエリも実行できます。
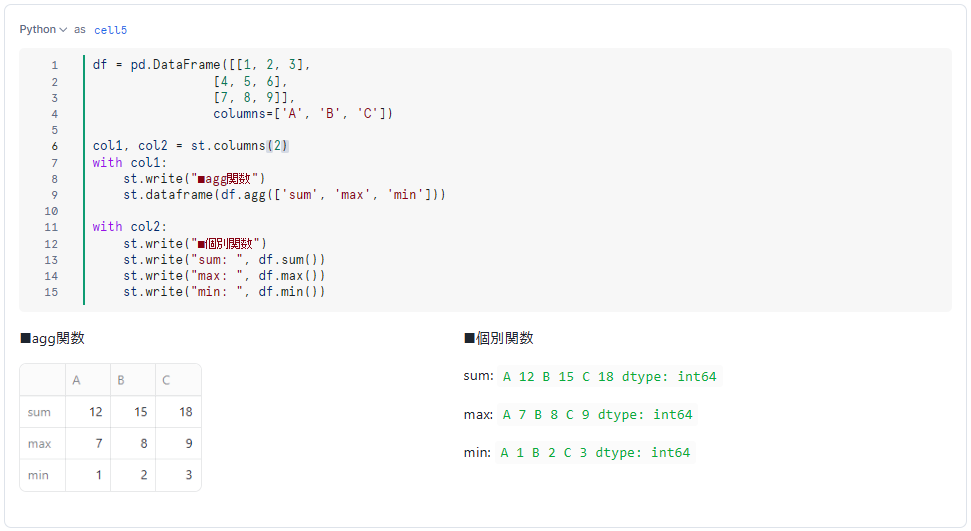
■集計
df = pd.DataFrame([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]],
columns=['A', 'B', 'C'])
col1, col2 = st.columns((1,3)) # 1:3に横分割
with col1:
st.write("■agg関数")
st.dataframe(df.agg(['sum', 'max', 'min']))
with col2:
st.write("■個別関数")
st.write("sum: ", df.sum())
st.write("max: ", df.max())
st.write("min: ", df.min())
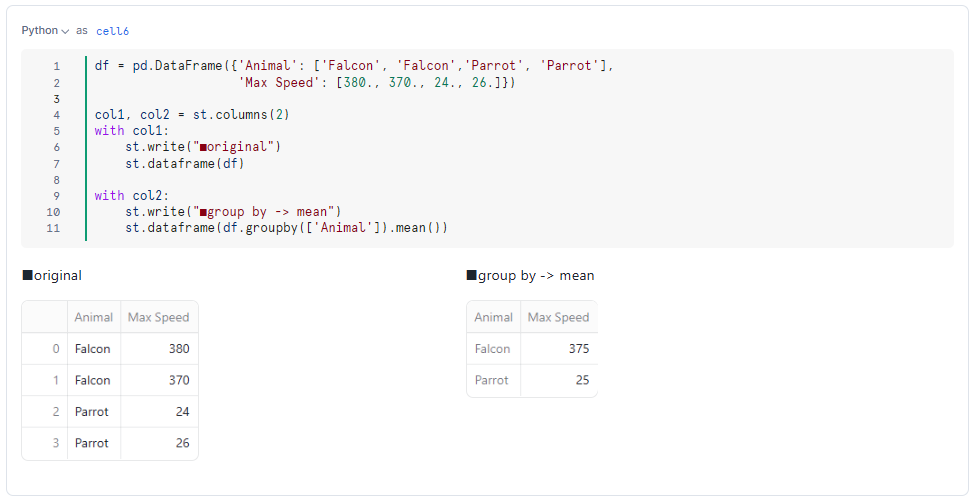
■グループ化
df = pd.DataFrame({'Animal': ['Falcon', 'Falcon','Parrot', 'Parrot'],
'Max Speed': [380., 370., 24., 26.]})
col1, col2 = st.columns(2)
with col1:
st.write("■original")
st.dataframe(df)
with col2:
st.write("■group by -> mean")
st.dataframe(df.groupby(['Animal']).mean())
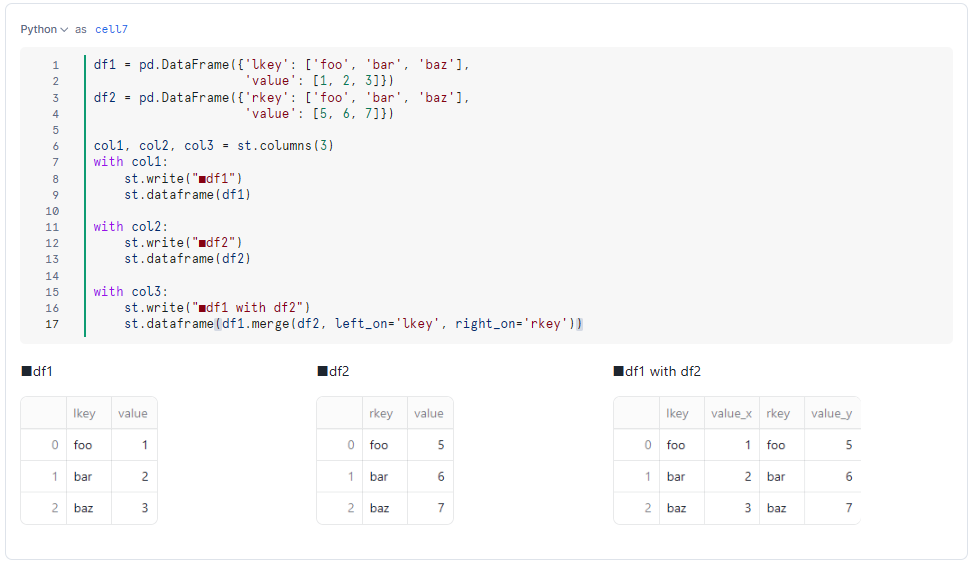
結合
そして、もちろん結合(mergeやjoinによる内部・外部結合)も行えます。
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz'],
'value': [1, 2, 3]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz'],
'value': [5, 6, 7]})
col1, col2, col3 = st.columns(3)
with col1:
st.write("■df1")
st.dataframe(df1)
with col2:
st.write("■df2")
st.dataframe(df2)
with col3:
st.write("■df1 with df2")
st.dataframe(df1.merge(df2, left_on='lkey', right_on='rkey'))
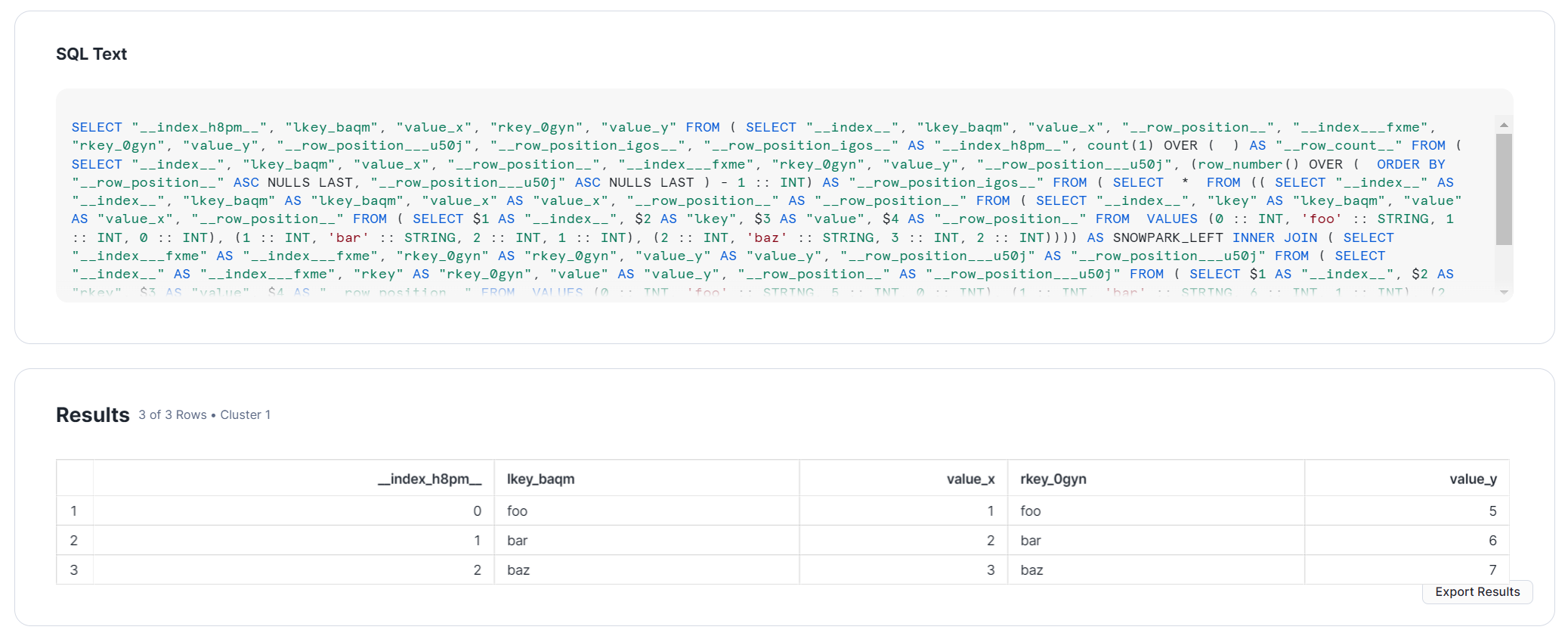
もちろん、この結合操作も、Snowflake上でSQLクエリとして実行されています。
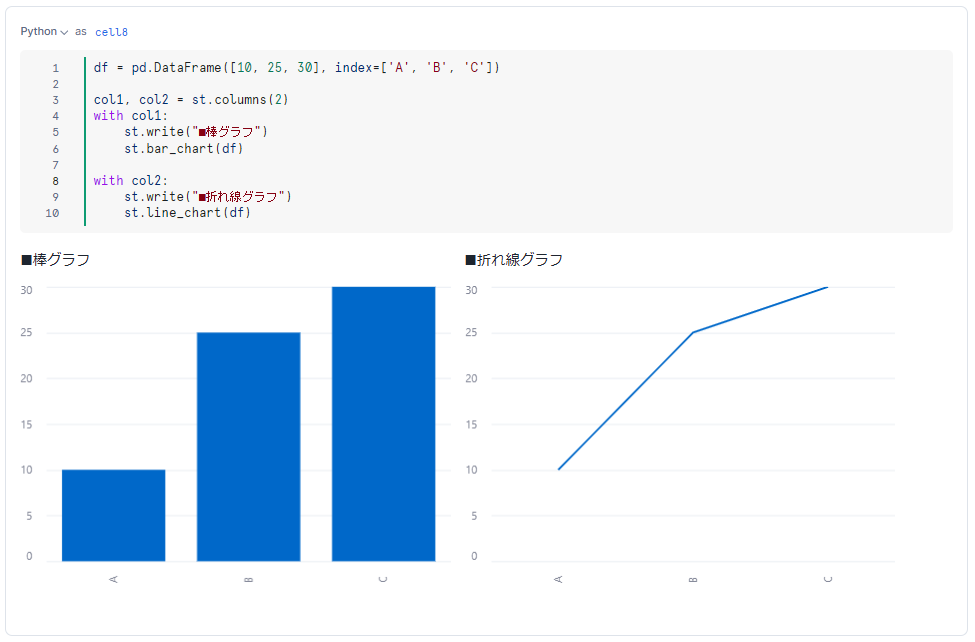
Streamlit による可視化📈
Snowflake Notebooks の大きな特徴でもある Streamlit を使った可視化についても確認します。これも非常に簡単で、Snowpark Pandas DataFrame を、Streamlit のグラフ関数に指定するだけでOKです。
df = pd.DataFrame([10, 25, 30], index=['A', 'B', 'C'])
col1, col2 = st.columns(2)
with col1:
st.write("■棒グラフ")
st.bar_chart(df)
with col2:
st.write("■折れ線グラフ")
st.line_chart(df)
ユースケース
最後に、私が考える Snowpark Pandas API と Snowflake Notebooks をかけ合わせたユースケースについて簡単に紹介します。
- データ探索や可視化📈:従来、Jupyter Notebook 上で Pandas などで行っていたデータ探索やデータ加工、可視化などを、Pandas API と Snowflake Notebooks に簡単に置き換えられます。
- 既存パイプラインの移行⚙️:既存の Pandas パイプラインが存在すれば、大部分はそのまま移行できます。Snowflake では、ストアドプロシージャや、本記事で紹介した Notebooks を定期実行できるため、データパイプラインの定期実行も実現できます。
- データアプリケーションの構築🕹️:最後に、Pandas API と Streamlit in Snowflake や Snowflake Notebooks の組み合わせによるデータアプリケーションの構築です。Streamlit はインタラクティブな UI を数行の Python コードで実装できるライブラリのため、データ可視化や機械学習・予測、データ登録などのアプリケーションを容易に構築できます。この際の Snowflake のデータの加工手段として、Snowpark Pandas API を大いに活用できます。
おわりに
本記事を通して、Pandas API がなにか?や Pandas API を Snowflake Notebooks 上でどのように使用できるか?を紹介させていただきました。先述の通り Pandas API では、Pandas の文法で記述した処理が SQL に自動的に変換され、Snowflake のコンピューティングリソースを使って処理が行われます。
そのため、ローカル環境のリソースを大きくする必要なく、柔軟なコンピューティングリソースで複数人で自由に分析を行えます。しかも、これをコンピューティングリソースの従量課金のみで扱えるということになります。
ただし、冒頭でも述べた通り現時点では Public Preview の機能であり、Snowflake の様々な機能拡張(Snowpark ML・Numpy との統合、ネイティブ Pandas との互換性向上など)もまだまだこれからの段階です。ぜひ、今後のアップデートにも注目いただき、一般提供(GA)に備えておきましょう!💪
また、SnowVillage の #ai-datacloud チャンネルでは、こういった内容の AI やアプリ、基盤を含めた多種多様な Snowflake の機能をかけ合わせたユースケースに関する勉強会を開催しています。初心者・初めての方も参加(ROM専もOK)いただけるので、ぜひ覗いてみてください。
仲間募集
NTTデータ デザイン&テクノロジーコンサルティング事業本部 では、以下の職種を募集しています。
1. クラウド技術を活用したデータ分析プラットフォームの開発・構築(ITアーキテクト/クラウドエンジニア)
クラウド/プラットフォーム技術の知見に基づき、DWH、BI、ETL領域におけるソリューション開発を推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/cloud_engineer
2. データサイエンス領域(データサイエンティスト/データアナリスト)
データ活用/情報処理/AI/BI/統計学などの情報科学を活用し、よりデータサイエンスの観点から、データ分析プロジェクトのリーダーとしてお客様のDX/デジタルサクセスを推進します。
https://enterprise-aiiot.nttdata.com/recruitment/career_sp/datascientist
3.お客様のAI活用の成功を推進するAIサクセスマネージャー
DataRobotをはじめとしたAIソリューションやサービスを使って、
お客様のAIプロジェクトを成功させ、ビジネス価値を創出するための活動を実施し、
お客様内でのAI活用を拡大、NTTデータが提供するAIソリューションの利用継続を推進していただく人材を募集しています。
https://nttdata.jposting.net/u/job.phtml?job_code=804
4.DX/デジタルサクセスを推進するデータサイエンティスト《管理職/管理職候補》
データ分析プロジェクトのリーダとして、正確な課題の把握、適切な評価指標の設定、分析計画策定や適切な分析手法や技術の評価・選定といったデータ活用の具現化、高度化を行い分析結果の見える化・お客様の納得感醸成を行うことで、ビジネス成果・価値を出すアクションへとつなげることができるデータサイエンティスト人材を募集しています。ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
https://enterprise-aiiot.nttdata.com/tdf/
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
TDFⓇ-AM(Trusted Data Foundation - Analytics Managed Service)について
~データ活用基盤の段階的な拡張支援(Quick Start) と保守運用のマネジメント(Analytics Managed)をご提供することでお客様のDXを成功に導く、データ活用プラットフォームサービス~
https://enterprise-aiiot.nttdata.com/service/tdf/tdf_am
TDFⓇ-AMは、データ活用をQuickに始めることができ、データ活用の成熟度に応じて段階的に環境を拡張します。プラットフォームの保守運用はNTTデータが一括で実施し、お客様は成果創出に専念することが可能です。また、日々最新のテクノロジーをキャッチアップし、常に活用しやすい環境を提供します。なお、ご要望に応じて上流のコンサルティングフェーズからAI/BIなどのデータ活用支援に至るまで、End to Endで課題解決に向けて伴走することも可能です。
NTTデータとTableauについて
ビジュアル分析プラットフォームのTableauと2014年にパートナー契約を締結し、自社の経営ダッシュボード基盤への採用や独自のコンピテンシーセンターの設置などの取り組みを進めてきました。さらに2019年度にはSalesforceとワンストップでのサービスを提供開始するなど、積極的にビジネスを展開しています。
これまでPartner of the Year, Japanを4年連続で受賞しており、2021年にはアジア太平洋地域で最もビジネスに貢献したパートナーとして表彰されました。
また、2020年度からは、Tableauを活用したデータ活用促進のコンサルティングや導入サービスの他、AI活用やデータマネジメント整備など、お客さまの企業全体のデータ活用民主化を成功させるためのノウハウ・方法論を体系化した「デジタルサクセス」プログラムを提供開始しています。
https://enterprise-aiiot.nttdata.com/service/tableau
NTTデータとAlteryxについて
Alteryx導入の豊富な実績を持つNTTデータは、最高位にあたるAlteryx Premiumパートナーとしてお客さまをご支援します。
導入時のプロフェッショナル支援など独自メニューを整備し、特定の業種によらない多くのお客さまに、Alteryxを活用したサービスの強化・拡充を提供します。
NTTデータとDataRobotについて
NTTデータはDataRobot社と戦略的資本業務提携を行い、経験豊富なデータサイエンティストがAI・データ活用を起点にお客様のビジネスにおける価値創出をご支援します。
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。
https://enterprise-aiiot.nttdata.com/service/informatica
NTTデータとSnowflakeについて
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。