この記事の概要
個人開発で HottyDB という検索エンジンとレコメンドエンジンの機能を搭載したRDBMSを開発し、α版を公開しました!
>> HottyDBの公式サイト
ので、この記事ではHottyDBの特徴的な機能やその使い方について紹介したいと思います!
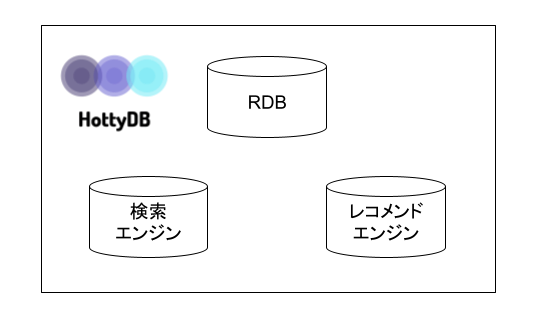
HottyDBとは?

HottyDBとは、検索エンジンとレコメンドエンジンの機能を搭載したRDBMS(リレーショナルデータベース)です。
SQLを用いた通常のデータ操作に加え、文書の全文検索や検索結果の機械学習ランキング(MLR)・アイテムレコメンデーションのロジックなどを全て1つのソフトウェアで担います。
1つのソフトウェアでこれらを実現することで、面倒なデータ伝送システムの構築を一切不要にし、利用者は機械学習などの知識がなくてもSQL LIKEな命令だけでこれらを実現することができます。
3つの機能が同じソフトウェアになることで何が嬉しいか?
従来の機械学習システムの場合
検索エンジンなどを利用して、機械学習ランキングを実現するシステムを作成しようとすると、従来の機械学習システムでは最低でも下記の様なシステム構成になると思います。

また、ストレージ自体には、データ伝送機能がないことが多いので、ストレージ間のデータ伝送には別途サーバーやアプリケーションが必要になります。
アイテムレコメンデーションを実現しようとすると、ここから更に追加のデータ伝送システムが必要となります。
HottyDBで機械学習システムを実現する場合
HottyDBを利用したシステム構成例がこちらです。

このように、HottyDBを利用するとシステム構成がとてもシンプルになります!
各種データ伝送システムは一切不要となり、難しい機械学習のロジックも裏でHottyDBが自動的に学習・推論してくれるので、利用者はSQL LIKEな命令だけで全ての機能を利用することができます。
HottyDB の特徴的な機能
RDBMSの機能
HottyDB はRDBMS(リレーショナルデータベース)なので、RDBMSに通常備わっている機能の多くは利用可能です。
よくあるRDBMSと同じようにSQLによるデータ操作が可能です。
HottyDBのRDBMS関連の特徴
- ACID特性を持つOLTP用のRDBMS
- コミット・ロールバックの機能があり、障害後もリカバリによって整合性を担保します
- CREATE TABLEやDROP TABLEなどのDDL操作
- INSERT, UPDATE, DELETE, SELECTなどのDML操作
- B木によるインデックスに対応
- JOIN, GROUP BY, ORDER BY, サブクエリなどのSELECT処理にも対応
- VIEWも作れます
利用可能なSQLコマンドについては、公式サイトのチュートリアルも参照してください。
>> HottyDBの標準的なSQLコマンド
検索エンジン機能
続いて、HottyDBの特徴的機能である検索エンジン機能の紹介をします。
転置インデックスによる文書の全文検索や、検索結果のランキング学習(MLR)をSQL LIKEなコマンドで実現します。
全文検索
全文検索とは、複数の文書から特定の文字列を含む文書を検索する技術のことを指します。 通常のSQLで全文検索を実現する場合、LIKE句を駆使して部分一致検索をするため、インデックスを利用することができず効率的な検索をすることができません。
HottyDBではSQL LIKEなコマンドで転置インデックスを作成でき、その転置インデックスを利用した全文検索が可能です。 全文検索は通常のSELECT文の中で利用することができます。
転置インデックス作成コマンド(例)
articleテーブルのtitleフィールドに転置インデックスを作成する場合。
CREATE SEARCH INDEX s1 ON article (title)
転置インデックスに対し全文検索を実行(例)
先ほどのs1に対して全文検索を実行する場合、以下のようにSEARCHメソッドを使います。
SELECT id, title, _similarity
FROM SEARCH(article, title, '機械学習')
ORDER BY _similarity DESC
_similarityはSEARCHメソッドが追加で吐き出すフィールドで、検索クエリとそのレコードとの検索マッチ度(TDIDFによるコサイン類似度)を返すようにしています。
ちなみにTokenizerは今のところn-gram方式を採用しています。
将来的にはTokenizerをプラグイン化し、日本語形態素解析などにも対応できるようにしたいと考えています。
検索結果の機械学習ランキング(MLR)
実用的な検索サービスでは、単純にマッチ度だけで検索結果をランキングしていません。
アイテムの人気度など、さまざまな特徴量を組み合わせて機械学習によるランキング学習をしていることが多いです。
HottyDBで機械学習ランキングを実現する場合、以下の2つの準備をする必要があります。
- MLR_TEMPLATEの作成
- 機械学習ランキングで並び替えるテーブルデータを作成するSELECT文のテンプレート
- MLR_MODELの作成
- MLR_TEMPLATEのうち、どのフィールドを特徴量とするかを指定して作成する機械学習モデル
MLR_TEMPLATEの作成例
t1という名前のテンプレートを作成する例。
CREATE MLR_TEMPLATE t1
KEY(id)
SELECT id, title, likes, _similarity
FROM SEARCH(article, title, ?)
テンプレートでは、?のようにプレースホルダーを利用することが可能で、実際に機械学習ランキングの推論を実行するタイミングで実値を代入することができます。
KEY句では、アイテムIDのフィールドがどれになるかを指定します。
MLR_MODELの作成例
t1のテンプレートから2つのフィールドを特徴量に指定し、m1という名前のモデルを作成する例。
CREATE MLR_MODEL m1 WITH t1 (likes, _similarity)
MLR_MODELを使った推論(機械学習ランキングの実行)
テンプレートのプレースホルダーに値を代入し、機械学習ランキングを実行した結果をSELECT文で扱う方法がこちらです。
SELECT
id,
title,
likes,
_similarity,
_request_id,
_key_id,
_score
FROM MLR(m1, '機械学習')
MLRメソッドを使ってm1というモデルの機械学習ランキングを実行します。
MLRメソッドの2つ目以降の引数はMLRテンプレートのプレースホルダーの代入値が入ります。
なのでこの例では、MLRテンプレートで作成したSELECT文に実値を代入し、
SELECT id, title, likes, _similarity
FROM SEARCH(article, title, '機械学習')
の出力結果をMLRモデルm1の推論に基づいてリランキングしたものを返します。
MLRメソッドの出力にテンプレートで指定していないフィールドが追加されてるのが分かると思います。
これらはそれぞれ、
-
_request_id- 検索リクエストを一意に特定するID
- 学習データを送信する際に利用
-
_key_id- 検索結果内でアイテムを一意に特定するID
- MLRテンプレートでKEYに指定したフィールドの値を返す
- 学習データを送信する際に利用
-
_score- アイテムの機械学習ランキングにおけるスコア
という役割があります。
MLRモデルの学習(機械学習ランキングの学習)
先に推論の方法を説明しましたが、MLRモデルは学習されないと意味のあるランキングをしません。
ただし、機械学習ランキングは実際にアイテムのランキングが表示され、そのうちどのアイテムがクリックされたのかを学習する必要があるため、この順番になってしまいます。
機械学習ランキングの学習では、検索結果一覧の中でクリックされたアイテムとそうでないアイテムの違いを学習する必要があります(ペアワイズ学習)。 そのため、HottyDBへはどの検索リクエストにおいて、どのアイテムがクリックされたのかを伝える必要があります。
そのためのコマンドがINSERT MLR_POSITIVE命令です。
INSERT MLR_POSITIVE命令の例文
リクエストID=1の検索リクエストにおいて、アイテムID=4 がクリックされた場合のコマンド例がこちらです。
INSERT MLR_POSITIVE(m1, 1, 4)
このリクエストIDとアイテムIDは、先述のMLRメソッド(推論時のメソッド)で発番された_request_idと_key_idを使います。
以上のように、機械学習ランキングの推論と学習を繰り返すことでMLRモデルの学習は進み、より良いランキングモデルへと最適化されていきます。 学習はオンライン学習(SGD)で行われるので、INSERT MLR_POSITIVE命令が呼ばれれば即座にモデルパラメータは更新されます。
将来的に学習ロジックはプラグイン化し、より高度な学習ロジックも実現できるようにしたいと考えています。
メモリ上にある程度の学習データは貯められるので、ミニバッチの学習なども可能だと考えています。
レコメンデーション機能
レコメンデーション機能の解説は別の記事でしております。
こちらの記事を参照してみてください!
メトリクステーブル機能
機械学習ランキングの特徴量に、アイテムのアクセス数などを使いたい場合があります。
アクセス数の更新は更新頻度が高いので、通常のテーブルでは処理性能に問題が発生する可能性が高いです。
そういった場合に便利な機能が、このメトリクステーブル機能です。
詳しくは以下の記事で解説していますので、ぜひこちらの記事も参照してみてください!
サンプルプログラム
HottyDBのサンプルプログラム(Java)があります。
全体の利用の流れを把握するのに最適なので、ぜひ参照してみてください。
>> HottyDBのサンプルプログラム
今後の展望
HottyDBはまだα版ですので、機能的にも品質的にもまだまだこれからなソフトウェアです。
β版や安定板に向けて、これから追加しようとしている機能を紹介しようと思います。
SQL機能の充実
- ALTER TABLEがまだできないので、その開発
- UNIQUE制約
- OUTER JOIN(機械学習ランキングで重要なので優先度高い)
- 複数フィールドに対するINDEX
- LONG型、Date型などのデータ型の追加
などなど
裏側のDB制御構造の改善
- WAL(Write Ahead Logging)を用いたトランザクション管理
- 現在(v0.3.5)はUndoオンリーの戦略で、コミット時に必ずデータのDISK書き込みが走るようになっています
- WALが実現できれば書き込み性能が向上します
- Buffer管理の最適化
- Bufferの追い出し機構が単純すぎるので、LRUなどで追い出すようにしたいです
- 転置インデックス対象フィールドの更新について
- 現状、転置インデックス対象フィールドが更新されると、そのフィールドが含む全TokenのポスティングリストがUpdateされるので、大量の排他ロックをかけることになります
- もうちょっと工夫したいです
プラグイン化
- 機械学習ランキングロジックのプラグイン化
- Tokenizerロジックのプラグイン化
などなど
フィードバックをお待ちいています!
HottyDBはまだ生まれたばかりのソフトウェアです。
使い方に関すること、分かりづらい点、バグ報告や改善提案、機能の要望など、なんでもOKなので下記のいずれかの方法でフィードバックをいただけると助かります。
- このQiitaのコメント欄
- お問い合わせフォーム