目的
Fluentdを用いてElasticsearchへログを入れます.
<parse>の@type apache2や@nginxで上手くいかない場合は是非見てください!!
最初にログの変換,次にFluentdの設定ファイルの書き方,最後にKibanaで確認という流れで説明します.
今回使用するログはサッカーワールドカップのWebサイト(1998年)のアクセスログです.わざわざログの変換の工程が必要な理由は昔のアクセスログを使っているからです.
一番苦戦したところはアクセスログをElasticsearchへ入れようとした際に,Kibanaでtimestampをdate型で認識してもらうところです.
環境
マシーンは1台です.
- Ubuntu 22.04.1 LTS
-
lsb_release -a1
-
- Elasticsearch 8.5.2
-
curl -s -XGET http://localhost:9200/ | grep number2
-
- td-agent 4.4.2 fluentd 1.15.3
-
td-agent --version3
-
- Python 3.10.6
python3 --version
今回使用するログ
今回使用するログはサッカーワールドカップのWebサイト(1998年)のアクセスログです.
- GitHub - chengtx/WorldCup98: http server access logs of WorldCup 98
- A workload characterization study of the 1998 World Cup Web site | IEEE Journals & Magazine
具体的なアクセスログを1件載せます.
0,-,-,[30/Apr/1998:22:00:02,+0000],GET /images/home_intro.anim.gif HTTP/1.0,200,60349
このアクセスログからは9つの値がとれます.
- IpId (匿名化) :
0 - UserId (値なし) :
- - UserName (値なし) :
- - TimeStamp :
[30/Apr/1998:22:00:02,+0000] - HttpMethod :
GET - Uri :
/images/home_intro.anim.gif - HttpVersion :
HTTP/1.0 - ResponseCode :
200 - Bytes :
60349
csvでデータをとると,「HttpMethod」と「Uri」,「HttpVersion」がひとまとまりになっているので分割します.それと,timestampを読み取らせるためにUNIX timeに変換しておきます.最後にデータのフォーマットをcsvからtsvへ変換しています.tsvに変換した理由は個人的にcsvよりtsvのフォーマットの方が分割した結果の確認がしやすいためです.
import csv
from datetime import datetime as dt
import glob
def convert_tsv(log_file):
log_buffer = []
with open(log_file) as f:
reader = csv.reader(f)
print("check") #実行時のターミナルが寂しいので進捗確認用のprint
for data in reader:
try:
# UNIX time (整数値)に変換
time_stamp = dt.strptime(data[3], '[%d/%b/%Y:%H:%M:%S')
time_ch = time_stamp.timestamp()
data[3] = str(time_ch)[:-2]
# tsv(Tab Separated Values)に変換
elements = data[5].split()
new_list = data[:5] + elements + data[6:]
tsv = "\t".join(new_list)
# ログ1件ごとに改行
log_buffer.append(tsv + "\n")
# エラー出力
except Exception as e:
print(e)
break
# 新しいファイルにログを書き込み
with open(log_file + ".log", mode="w") as f:
f.writelines(log_buffer)
# csvファイル一覧を取得
file_list = glob.glob("*.csv")
# csvファイルをtsvに変換して別ファイルで出力
for file_name in file_list:
convert_tsv(file_name)
実行
python3 convert.py
$ ls
convert.py wc_day18_.csv.log wc_day27_.csv.log wc_day36_.csv.log wc_day45_.csv.log
wc_day10_.csv wc_day19_.csv wc_day28_.csv wc_day37_.csv wc_day46_.csv
wc_day10_.csv.log wc_day19_.csv.log wc_day28_.csv.log wc_day37_.csv.log wc_day46_.csv.log
wc_day11_.csv wc_day20_.csv wc_day29_.csv wc_day38_.csv wc_day47_.csv
wc_day11_.csv.log wc_day20_.csv.log wc_day29_.csv.log wc_day38_.csv.log wc_day47_.csv.log
wc_day12_.csv wc_day21_.csv wc_day30_.csv wc_day39_.csv wc_day48_.csv
wc_day12_.csv.log wc_day21_.csv.log wc_day30_.csv.log wc_day39_.csv.log wc_day48_.csv.log
wc_day13_.csv wc_day22_.csv wc_day31_.csv wc_day40_.csv wc_day49_.csv
wc_day13_.csv.log wc_day22_.csv.log wc_day31_.csv.log wc_day40_.csv.log wc_day49_.csv.log
wc_day14_.csv wc_day23_.csv wc_day32_.csv wc_day41_.csv wc_day6_.csv
wc_day14_.csv.log wc_day23_.csv.log wc_day32_.csv.log wc_day41_.csv.log wc_day6_.csv.log
wc_day15_.csv wc_day24_.csv wc_day33_.csv wc_day42_.csv wc_day7_.csv
wc_day15_.csv.log wc_day24_.csv.log wc_day33_.csv.log wc_day42_.csv.log wc_day7_.csv.log
wc_day16_.csv wc_day25_.csv wc_day34_.csv wc_day43_.csv wc_day8_.csv
wc_day16_.csv.log wc_day25_.csv.log wc_day34_.csv.log wc_day43_.csv.log wc_day8_.csv.log
wc_day17_.csv wc_day26_.csv wc_day35_.csv wc_day44_.csv wc_day9_.csv
wc_day17_.csv.log wc_day26_.csv.log wc_day35_.csv.log wc_day44_.csv.log wc_day9_.csv.log
wc_day18_.csv wc_day27_.csv wc_day36_.csv wc_day45_.csv
変換後のアクセスログの例です.
0 - - 893973602 GET /images/home_intro.anim.gif HTTP/1.0 200 60349
FluentdでElasticsearchにログを入れる流れ
- Fluentdの設定ファイルを書き換え
- Fluentdを再起動
- KibanaのData Viewsを作成
Fluentdの設定ファイルを書き換え
/etc/td-agent/td-agent.confを書き換えます.
今回の設定ファイルではInputを@type tailにして,Outputを@type elasticsearchに指定します.
Inputでは,typeで型を指定します4.keyの型はintegerが整数,timeが時刻を表します5.timeはフォーマットを使用することができ,今回はUNIX timeを使用したので,time:unixtimeを指定します.
time_keyのdefaultsは現在時刻ですが,指定することでログの時刻を参照してtimestampを設定できるようになります4.time_typeはデフォルトでstringなので今回はUNIX timeである,unixtimeを使用します6.
Outputでは,timestampがログに入っていることを明記します.timestampがログに入っていることを示す,include_timestampはdefaultでfalseになっているので,tureにします7.
テキストエディタがvimの場合
sudo vim /etc/td-agent/td-agent.conf
<source>
@type tail
path ~/worldcup/csv_data/*.log # ログファイルのpathを指定
read_from_head true
pos_file /tmp/wc.pos # ログファイルをどこまで送信したかを記録するファイルの場所と名前を指定
tag nginx.access
<parse>
@type tsv
keys IpId,UserId,UserName,TimeStamp,HttpMethod,Uri,HttpVersion,ResponseCode,Bytes # ログの値ごとにkeyを作成
types IpId:integer, TimeStamp:time:unixtime, ResponseCode:integer, Bytes:integer # keyの型を指定 integerは整数,time:unixtimeはUNIX time
time_key TimeStamp # timestampを指定
time_type unixtime # timestampの型を指定
</parse>
</source>
<match nginx.access>
@type elasticsearch
host localhost
port 9200
index_name wc_98 # indexの名前を指定
include_timestamp true # indexにtimestampが含まれているかを入れる(default: false)
</match>
Fluentdを再起動
設定ファイルを書き換えたら,再起動して設定ファイルを読み込ませます.
sudo systemctl restart td-agent.service
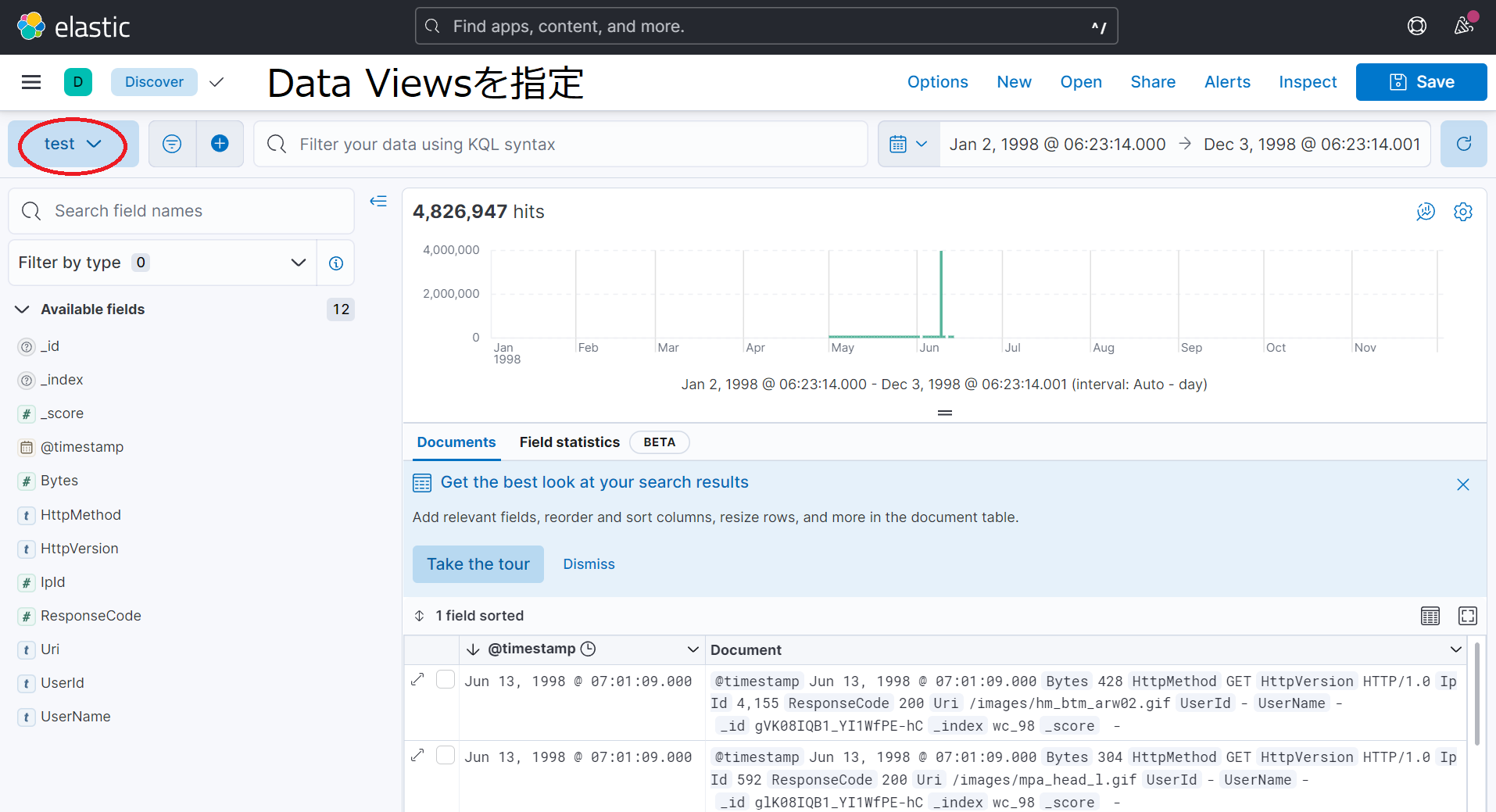
KibanaのData Viewsを作成
サイドメニューからManagement > Data > Index ManagementでIndexが作成されているか確認する.

サイドメニューからManagement > Kibana > Data ViewsでCreate Data ViewsをクリックしてData Viewsを作成する.

名前は何でもいいのでtestと名付けた.
Index patternは先程,/etc/td-agent/td-agent.confのindex_nameで指定した名前を入れる.
必ずTimestamp fieldに@timestampを指定する.
以上の3つが入力していることを確認したらSave data view to Kibanaをクリックする.

作成した Data Viewsの型をManagement > Kibana > Data Viewsから先程作成したData Viewsをクリックする.

クリックしたData ViewsはNameが@timestampでTypeがdate型になっていることを確認する.

サイドメニューからAnalytics > Discoverでログを確認する.Data Viewsの指定を忘れずにすること.