はじめに
さて、fiftyoneとはなんぞやと思われたのではないでしょうか?
自分もこの前まではそんな感じでした。
ざっくりと言ってしまえば、アノテーションをmatplotとか使わずに、またlabelImgなどを使わずにお手軽に確認することができるツールです。さらに、フォーマットの変換もすることができる優れものです。
Deep learningとかで物体検知のモデルを学習する際には、絶対と言っていいほどアノテーションがついた画像が必要になってくるはずです。さらに、たくさんのデータセットを集めたときにはフォーマットが違って苦労します。
そんな困った問題を解決してくれるかもしれないのが、何を隠そうfiftyoneなのです。ちなみにここで断言してないのは、まだ対応してないフォーマットがあるからです。
今回はこのfiffyoneなるものを、日本語で書いてる方が見た感じ居られなかったので、自分のほうが簡単に紹介をしていけたらなと思います。
fiftyoneとは
fiftyoneの特徴を以下にまとめてみました。ちなみに僕もまだまだ使い慣れてないので知らない機能はあったりします。
- アノテーションを手軽に確認することができる
- アノテーションのフォーマット変換ができる(できないやつもある)
- pipでインストール可能
- アノテーションをすることができる
個人的によく使うのは、最初の2つかなと思います。アノテーションはコードでしか指定することができないので、流石にlabelImgのほうがいいですね。けど、fiftyoneには事前学習済みモデルがあり、それを使用してアノテーションを自動で付けることができたりします。(意外に精度はいいです)
上記のサイトを開いていただけると分かるのですが、Colabでお手軽に実験することができます。
実際に使ってみよう
まず、fiftyoneを使用するためにインストールを行います。
pythonのバージョンは 3.6 - 3.9が推奨されています。
pip install fiftyone
また、tensorflowがないとエラーを吐くことがあるのでtensorflowもついでにインストールしておくのがいいです。
バージョンは2番台になるとまだ対応してない部分があるので1.14などが無難です。
次にCOCOやKITTIといったそれぞれのフォーマットをfiftyoneで扱うためのフォーマットに変換します。
import fiftyone as fo
name = "test" #fiftyoneのデータセットの名前
dataset_dir = "/content/test" #画像やアノテーションがあるディレクトリ
dataset = fo.Dataset.from_dir(dataset_dir, fo.types.KITTIDetectionDataset, skip_unlabeled=True, name=name)
# skip_unlabeldはオプション
print(dataset)
print(dataset.head())
出力結果が
100% |█████████████| 14420/14420 [6.4m elapsed, 0s remaining, 73.3 samples/s]
のように画像枚数がしっかりと表示されていたら成功です。
表示されていなければ、先程使ったnameと同じ名前は使えないので以下のコードで、一度削除して原因を探し、もう一度実行してみましょう。
print(fo.list_datasets())
dataset = fo.load_dataset("test")
dataset.delete()
print(dataset.deleted)
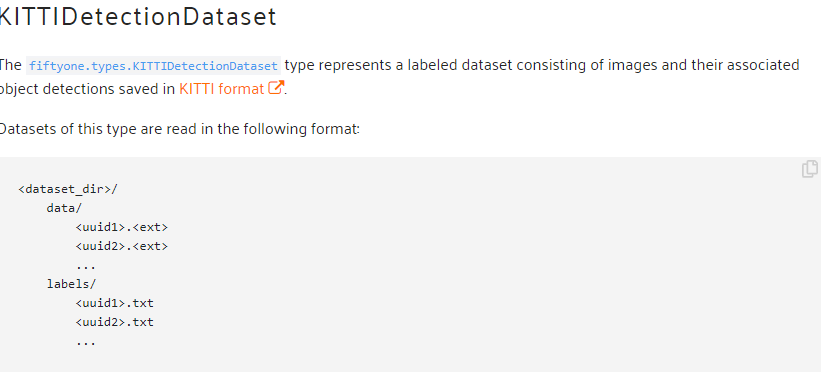
ディレクトリの構造にはfiftyoneの決まりがあり、例えばKITTIフォーマットのデータを読み込もうとした場合は、
下の画像のようにメインディレクトリの中に画像を保存するdata、アノテーションのファイルを保存するlabelsというディレクトリを配置する必要があります。
ディレクトリの名前はfiftyone規定の名前、今回であれば「data」,「labels」という名前しか受け付けないので、
もしディレクトリの名前を変えるのに手間がかかる場合などはシンボリックリンクなどを活用しましょう。
fiftyoneの形にフォーマットを変更できれば後は簡単です。
以下のコードで表示までできます。
session = fo.launch_app(dataset)
ちなみにリモートサーバー上の環境で作業をしていても、fiftyoneを使用することは可能です。ただ、ポートフォワーディングをする必要があり、デフォルトで使用されているポートは5151です。
ポートフォワーディングした状態で、先程のコードにremote=Trueを追加すれば動作させることができます。
session = fo.launch_app(dataset, remote=True) #port=XXXXを追加することで、ポートを変えることも可能
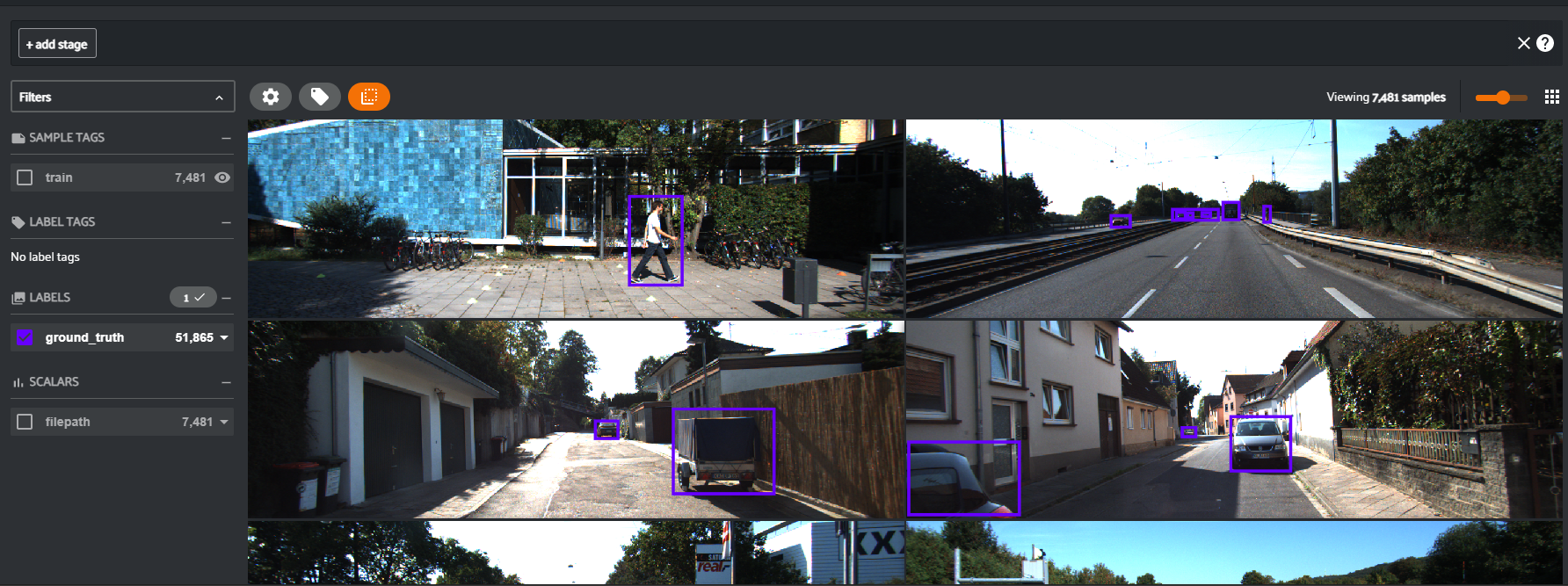
上記を実行すると以下のようにアプリが起動します。LABELSのところで、見たいアノテーションのラベルを選択したり、+add stageのところで
ファイルをソートしたりすることも可能です。
アノテーションのフォーマットを変換
上記では、データをfiftyoneの形式に変換し、表示するところまで行いました。
ここからは、割と重宝されるのではないかなと思ってるフォーマット変換について触れていきたいと思います。
物体検出などのディープラーニングをするときには、学習用にデータセットを探し集めることがありますよね。このモデルはYOLOフォーマットしか受け付けない、あのモデルはKITTIしか受け付けない、といったことがあると思います。
そのときには、自分でjsonやtxt、matをpythonで読み込んで変更するなどの作業をすると思いますが、そこでfiftyoneが使えます。あ、ちなみに見たことないフォーマットは自分でYOLOなどのフォーマットに変換してください笑(一応オリジナルのフォーマットを読み込めるみたいですが、使い方はいまいちわかっていません)
アノテーションのフォーマットの変換自体は意外に簡単に行なえます。実は、アノテーションデータをfiftyoneフォーマットに変換できた時点でほぼ終わっています。以下のコードで変換することができます。
export_dir = "/content/test/fiftyone"
label_field = "ground_truth" #print(dataset)したときの「Sample fields」の欄から選択可能
dataset.export(
export_dir=export_dir, #保存用のディレクトリ
dataset_type=fo.types.VOCDetectionDataset, #exportするアノテーションのフォーマット
label_field=label_field,
overwrite=True,
)
先程見たことないフォーマットを変換するのは自分で、と書きましたがそのときにfifityoneが使えないわけではないです。
例えば、自分でフォーマットを変換するコードを書く → fiftyoneでアノテーションが正しいか確認する → もし、アノテーションを他のフォーマットで使いたいとなればすぐ変換することができる
といったようにfiftyoneを有効に使うことができます。自分もよくそのように使っており、割と手間が省けているので便利だなと感じていたりします。
終わりに
今回はfiftyoneというアノテーションツールを紹介させていただきました。このツールを日本語で紹介されている記事がなく、自分の方から軽くにはなりますが、記事にしました。fiftyoneは奥が深く、いろいろなオプションであったり、モジュールがあります。自分もまだまだ勉強不足でわからない部分もあります。そこで、ぜひ本記事を読んだ方に詳しくなっていただき、ご教授願いたいなと思っていたりします笑。