はじめに
目的
Snowflakeで言う「ワークロードごとに仮想ウェアハウスを分離し、リソース競合を防ぎ、コスト管理を分ける」といった使い方がRedshift Serverlessでも可能か確かめる
結果
技術的に可能だが、Snowflakeの方が明らか便利っぽい
背景
気になった点
Redshift Serverlessについて調べていたとき、Snowflakeに馴染みがある僕としては、Redshift Serverlessの名前空間とワークグループという概念にひっかかりました。
Each namespace can have only one workgroup associated with it. Conversely, each workgroup can be associated with only one namespace.
→ ぼく「名前空間とワークグループが1:1??? ということは、各ユーザは名前空間内のテーブルにしかアクセスできないし、紐づけられたワークグループでしかコンピュートできない、ということ???」
もし、「各ユーザは名前空間内のテーブルにしかアクセスできないし、紐づけられたワークグループでしかコンピュートできない」が制約として真に実在する場合、以下の困りごとが発生します。
困りごと: ワークロードの分離の実現が難しい
会社共通のDWHなどを想定した際、複数部門, 組織, PJTが同じDWH基盤を利用することが想定されます。このとき、コンピュートリソースを分ける (以後、「ワークロードの分離」と呼びます) ことで、①リソース競合を防ぐ、②業務単位ごとに消費リソースを把握しコスト管理・賦課を行う、ことが一般的です。
Redshift Serverlessをサッと見て気になった点は、「各ユーザは名前空間内のテーブルにしかアクセスできないし、紐づけられたワークグループでしかコンピュートできない」という制約があると、部門やタスクごとのワークロードの分離の実現が難しいのでは、ということです。例えば、以下の設計は名前空間:ワークグループ=1:2となっているため、Redshift Serverlessでは実現不可能です。
Architecture1

ワークグループを複数作成し、ワークグループごとにタグをつけたいのですが、名前空間:ワークグループ=1:1ルールが結構邪魔な気がします。
次の設計は実現可能ですが、UnitAのDBで作ったtableをUnitBが閲覧する、といったデータの連携は面倒そうです。
Architecture2

Snowflakeなら、部門やタスクごとに仮想ウェアハウスを割り当てることで、リソースを分割することが可能です。また、独立した仮想ウェアハウスの割当により、コストトラックも容易となります。単純に権限を割り当ててしまえばOKで、設計はこんな感じ。
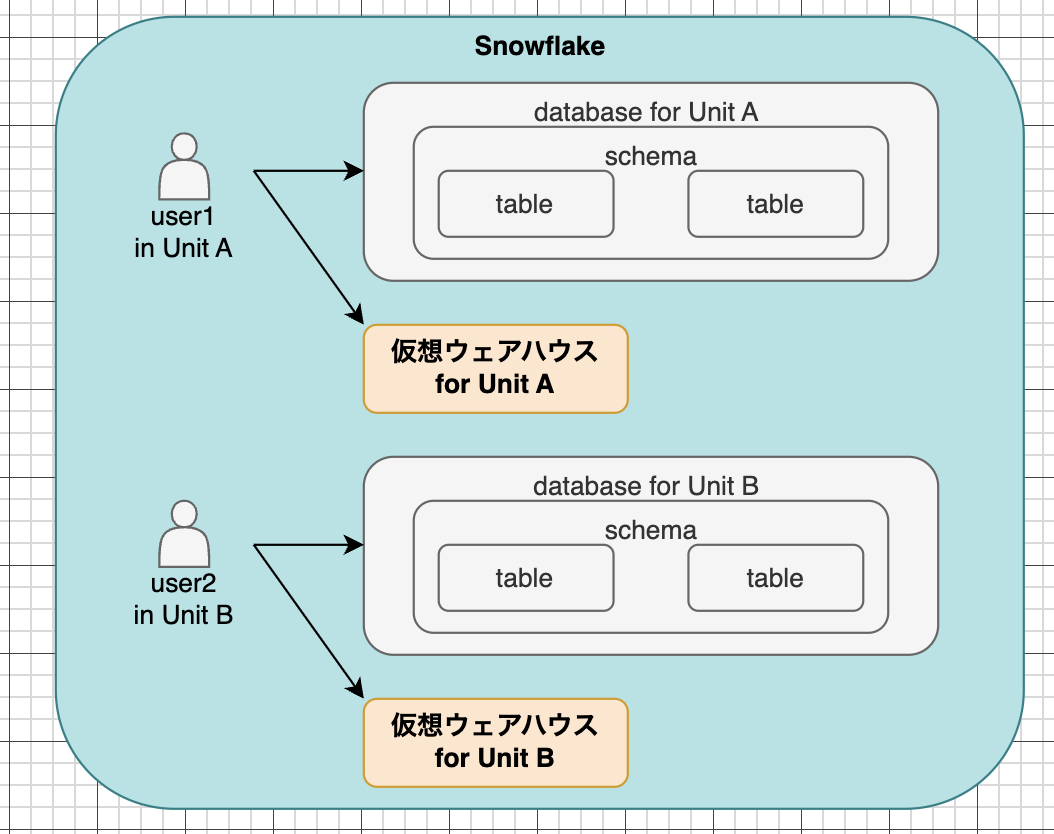
(ワークロードの分離は、Snowflakeを触っているなら必ず登場する話題ですよね)
検証内容
以上を踏まえ、次の前提・要件がRedshift Serverlessでどう実現できそうかを模索してみます。
前提
* DataEngineering, UnitA, UnitB と、3つの部門が存在する
* DataEngineeringはデータ整備を担う開発組織とする
* UnitA, UnitBはデータ利用を行う業務組織とする
要件
必要な機能は以下
* 3つの部門でワークロードを分離する
* 競合を防ぐ
* コストを賦課する
想定イメージ
想定する利用形態をSnowflakeで作ったイメージは以下。
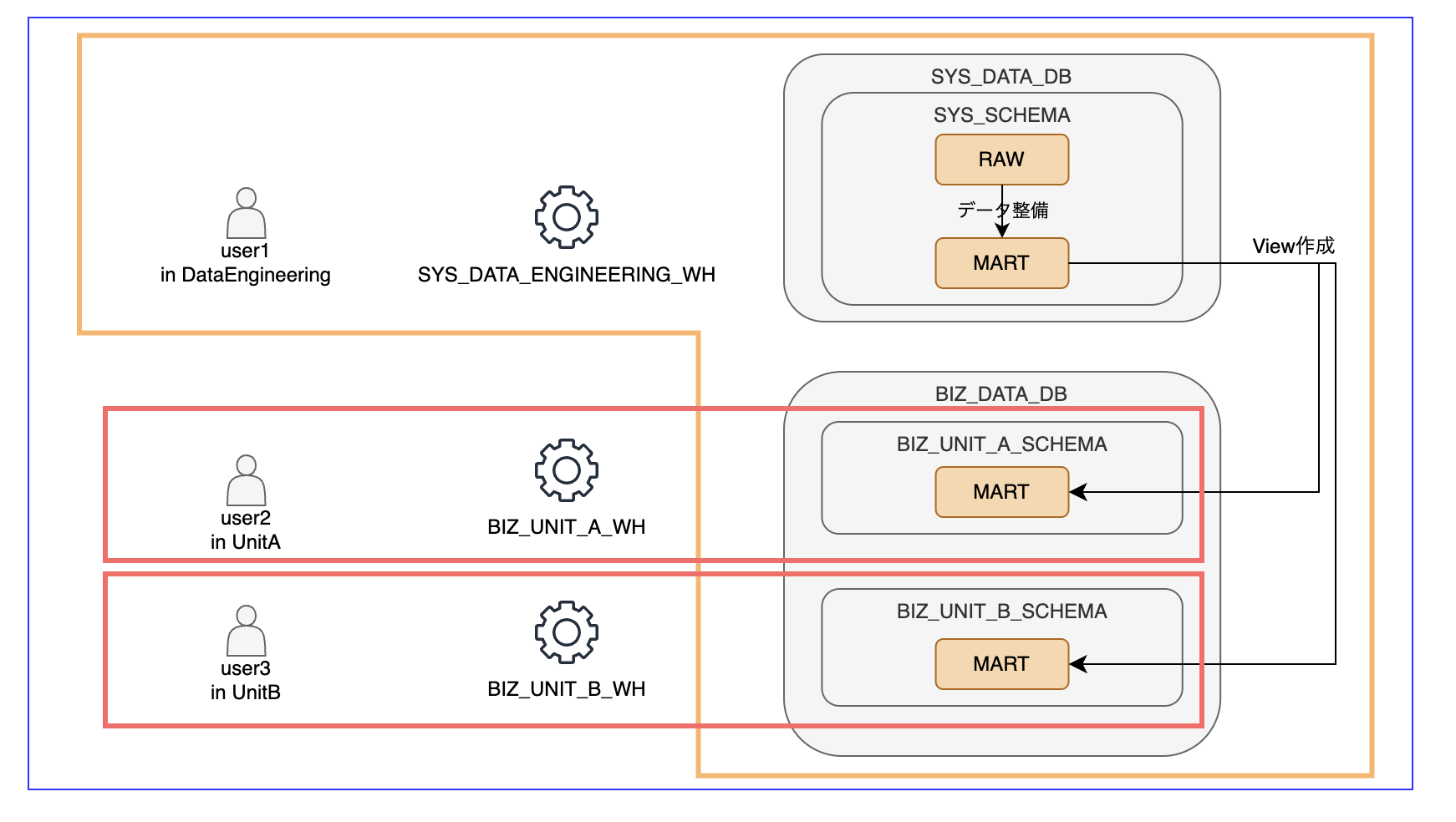
-
DataEngineeringチームのuser1は、緑枠を責任範囲とし、以下タスクを行う。-
SYS_DATA_DB内のデータ整備 -
SYS_DATA_DBからBIZ_DATA_DB内の各業務組織ごとに作成されたスキーマに対するView作成
-
-
UnitA, およびUnitBチームのuser2, 3は、赤枠を責任範囲とし、以下タスクを行う。- 各業務組織ごとに作成されたスキーマ内のTable/Viewの参照
(単なる調べ物なので、機能ロールとかアクセスロールは気にしないってことで。。。)
↑のようなものをRedshift Serverlessで作れるかな?をざっと見ていきます。
調査①
先ほど挙げた以下のような設計ができないことを確かめます。
Architecture1
ワークグループの作成画面から、「既存の名前空間に追加」を試みると以下の通りで、名前空間:ワークグループ=1:2はやはり不可能でした。

調査②
方針: ワークロードごとにワークグループを作成する
結論、この方法なら可能です。ただし、どう見てもめんどくさい。
今回の検証で言う、DataEngineering, UnitA, UnitBごとにワークグループを作り、対応する名前空間を作れば、技術的には要件を満たせるはずです。また、DataEngineeringチームによる各業務組織へのView作成は、データ共有を用いれば可能です。
実現イメージはこんな感じ。

困りごと
データ共有によって、データを参照可能にするためには、データコンシューマ (今回で言うUnitAやUnitBの人たち) 側でも設定が必要となります。
業務ユーザに対して「初期設定してくれや」はやはり極力避けるべきなので、ここは痛いポイントかなあと思います。
まとめ
目的
Snowflakeで言う「ワークロードごとに仮想ウェアハウスを分離し、リソース競合を防ぎ、コスト管理を分ける」といった使い方がRedshift Serverlessでも可能か確かめる
結果
技術的に可能だが、Snowflakeの方が明らか便利
所感
AWSネイティブなRedshiftくん、個人的には推しているので、頑張れ...!
(誤りあればご指摘いただければ幸いです)