この記事は AWS Lambdaアドベントカレンダー 16日目の記事です。
概要
AWS Lambdaはイベント駆動で処理を実行する事ができます。
つまり
「何らかのイベント」>「Lambda実行」>「何らかのイベント」>(繰り返し)
と繰り返すことでcronの代わりに利用できないか?と考えました。
上手く行けばサーバレスであんな事やこんな事ができちゃうかもしれませんね…!
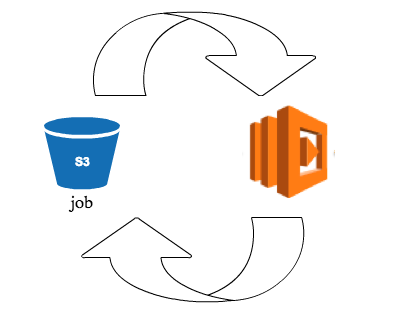
今回試してみた構成
S3のイベントをトリガーにしてみました。
とあるファイルをトリガーにして、
その中身のフラグを見て 処理開始(0)/処理中(1)/処理終了(0/1以外) を判断しています。
% cat job
0
また、cronのインターバルは最大でも60秒です。
これはlambdaのtimeout設定が 60秒までしか設定できない からです。
これより小さい数値でsetTimeoutすることにより、擬似ループのようなことを可能にしています。
実際の処理の時間まで含めると、
setTimeout設定はmaxの60秒だとギリギリすぎるので5-10秒くらい余裕を持たせたほうがよいでしょう。
cronの 開始 / 終了 の流れ
- (事前準備) Lambdaのtimeout設定を60秒(Max)にしておきます
- jobファイルの中身を"0"にしてS3にアップロードします(実は"1"でも動いちゃうんですが、ログ分別のため)
- Lambdaは job ファイルの中身を見て 0 or 1 であれば無限ループに入ります
- 何か任意の処理を行います
- job を "9"(0/1以外であればOK) にしてS3へアップロードすると、ジョブが終了します
何か変な動作になったら中身を "9" にしてアップロードし、cronジョブを停止するとよいでしょう。
ちなみに以下ソースコードも実装もかなり適当です。。。が、一応動作します。
きちんとやるならDynamoDBなどを利用してロック処理を行ったり、
ジョブ管理したほうが良いでしょう。
雛形ソースコード
これが擬似cronの基本形です。間に好きな処理を差し込みましょう。
console.log('Loading event');
var aws = require('aws-sdk');
var s3 = new aws.S3({apiVersion: '2006-03-01'});
var request = require('request');
var jobctl_key_name = "sample/job" // ジョブコントロールを行うファイル名
var interval = 30 * 1000 // 処理のインターバル。ここでは30秒間隔で実行しています。
// s3file ジョブコントロールのステータスをアップデートしています
function change_status(bucket, key, content_type, callback) {
s3.putObject({
Bucket: bucket,
Key: key,
Body: new Buffer("1", 'binary'), // update running...
ContentType: content_type
}, callback);
}
// メインハンドラ
exports.handler = function(event, context) {
console.log('Received event:' + Date.now());
console.log(JSON.stringify(event, null, ' '));
// Get the object from the event and show its content type
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
// set timeoutで擬似cronを実現しています
setTimeout(function() {
if(key == jobctl_key_name) {
s3.getObject({Bucket:bucket, Key:key},
function(err,data) {
if (err) {
console.log('error getting object ' + key + ' from bucket ' + bucket +
'. Make sure they exist and your bucket is in the same region as this function.');
context.done('error','error getting file'+err);
}
else {
var content_type = data.ContentType;
var body = data.Body.toString("utf-8");
//console.log('BODY:('+body+')');
if(body == 0) {
console.log('- start')
change_status(bucket, key, content_type, function(err){
if(err) context.done(err, "- change_status_error");
else context.done(null, "- running...");
});
} else if(body == 1) {
console.log('- runnning...')
change_status(bucket, key, content_type, function(err){
//////////////////////////////////////////////
// この辺りに好きな処理を入れる
if(err) context.done(err, "- change_status_error");
else context.done(null, "- running...");
});
} else {
console.log('- finish')
context.done(null, "- finish");
}
}
}
);
} else {
context.done(null, "");
}
}, interval);
};
それでは具体的な例を見ていきましょう。
※以下のソースコードでは非標準の request モジュールを利用しているため、
zipファイルの中に含める必要があります。
応用例1) BingAPIを利用して、画像収集するcronを設定
定期的にBingAPIを叩いて画像取得して、s3へ保存します。
アレな画像もどんどん収集できてしまいますね…!!
console.log('Loading event');
var aws = require('aws-sdk');
var s3 = new aws.S3({apiVersion: '2006-03-01'});
var request = require('request');
var fs = require('fs');
var jobctl_key_name = "sample1_aggregate/job"
var interval = 30 * 1000 // 30sec
var dest_bucket = "tori-aggregate-files" // ファイルを収集する先のバケット名
// s3file change_status
function change_status(bucket, key, content_type, callback) {
s3.putObject({
Bucket: bucket,
Key: key,
Body: new Buffer("1", 'binary'), // update running...
ContentType: content_type
}, callback);
}
// s3file upload
function s3_upload (bucket, key, body) {
s3.putObject({
Bucket: bucket,
Key: key,
Body: body,
}, function(err, res) {
if (err) {
console.error(err);
context.done('error putting object', err);
} else {
console.log('upload ok');
console.log(JSON.stringify(res, null, 2));
context.done(null, "success putting object");
}
});
}
function shuffle(x){
x = x || []
for(var i = 0, y = [], len = x.length; i < len; i++)
y.push( x.splice( Math.random() * x.length | 0, 1)[0]);
return y;
}
var http = require("http")
var acctKey = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'; // bingアクセスキー
var rootUri = 'https://api.datamarket.azure.com/Bing/Search';
var auth = new Buffer([ acctKey, acctKey ].join(':')).toString('base64');
var option = {
headers : {
'Authorization' : 'Basic ' + auth
}
};
var request = require('request').defaults(option);
var cache_url = {}
function bing_api (bucket, callback) {
var service_op = "Image";
var query = "chome-chome-gazou"; // 検索文字列
request.get({
url : rootUri + '/' + service_op,
qs : {
$format : 'json',
Query : "'" + query + "'", // the single quotes are required!
}
}, function(err, response, body) {
if (err) {
console.log(err)
}
if (response.statusCode !== 200) {
console.log("internal error " + response.statusCode)
}
var results = JSON.parse(response.body);
var sresult = shuffle(results.d.results)
var len = (sresult.length >= 10) ? 10 : sresult.length
var plen = 0;
// ループ
// 最大10件まで(最大アウトバウンドの件数に合わせている?)
for(var i=0;i<len;i++) {
var row = sresult[i];
var media_url = row.MediaUrl
var enc_media_url = encodeURIComponent(media_url)
// 処理済みのURLはスキップ
if(cache_url[enc_media_url]) {
plen++
continue;
}
// HTTPのみ処理する(手抜き)
if(!media_url.match(/^http:\/\//)) {
plen++
continue;
}
var file_name = "/tmp/" + enc_media_url;
var file = fs.createWriteStream(file_name);
// get image
http.get(media_url, function(res) {
res.on('data', function(data) {
file.write(data);
}).on('end', function() {
file.end();
console.log(' downloaded to ' + file_name);
// 一度取得したURLを保持しておく
cache_url[enc_media_url] = true;
// ファイル再読み込み
var body = fs.readFileSync(file_name);
// S3アップロード
s3_upload(dest_bucket, enc_media_url, body);
plen++
});
}).on('error', function(e) {
plen++
console.log(e)
});
}
// check
var timer = setInterval(function(){
// 全処理終了後にcallback
if(plen >= len) {
clearInterval(timer)
return callback()
}
}, 1000);
});
}
// メインハンドラ
exports.handler = function(event, context) {
console.log('Received event:' + Date.now());
console.log(JSON.stringify(event, null, ' '));
// Get the object from the event and show its content type
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
// set timeout
setTimeout(function() {
if(key == jobctl_key_name) {
s3.getObject({Bucket:bucket, Key:key},
function(err,data) {
if (err) {
console.log('error getting object ' + key + ' from bucket ' + bucket +
'. Make sure they exist and your bucket is in the same region as this function.');
context.done('error','error getting file'+err);
}
else {
var content_type = data.ContentType;
var body = data.Body.toString("utf-8");
if(body == 0) {
console.log('- start')
change_status(bucket, key, content_type, function(err) {
if(err) context.done(err, "- change status error");
bing_api(bucket, function(){
context.done(null, "");
})
});
} else if(body == 1) {
console.log('- runnning...')
change_status(bucket, key, content_type, function(err){
if(err) context.done(err, "- change status error");
bing_api(bucket, function(){
context.done(null, "");
})
});
} else {
console.log('- finish')
context.done(null, "- finish");
}
}
}
);
} else {
context.done(null, "");
}
}, interval);
};
ダウンロード出来てるっぽい!ヒュ〜!
※注意点としては、timeoutがあるので一度に多くは収集できないのと、アウトバウンド制限があるので制限内に収める必要がある、といったところでしょうか。
応用例2) 定期的に外部情報を取得して、Cloudwatchのカスタムメトリクスに登録する
今回は はてなブックマーク件数取得API を定期的に取得し、
Cloudwatchのカスタムメトリクスに自動登録してみました。
例では こちら のブクマ数を取得しています。
console.log('Loading event');
var aws = require('aws-sdk');
var s3 = new aws.S3({apiVersion: '2006-03-01'});
var cloudwatch = new aws.CloudWatch();
var request = require('request');
var jobctl_key_name = "sample2_cloudwatch/job"
var interval = 50 * 1000 // 50sec
// put cloudwatch
function put_cloudwatch(count, callback) {
var params = {
MetricData: [ /* required */
{
MetricName: 'hatebu_count',
Dimensions: [
{
Name: 'Site',
Value: 'niconico'
},
],
Timestamp: new Date,
Unit: 'None',
Value: Number(count)
},
],
Namespace: 'CUSTOM/Hatena'
};
// put metrics
cloudwatch.putMetricData(params, callback)
}
// s3file change_status
function change_status(bucket, key, content_type, callback) {
s3.putObject({
Bucket: bucket,
Key: key,
Body: new Buffer("1", 'binary'), // update running...
ContentType: content_type
}, callback);
}
var http = require("http")
// this somewhere at the top of your code:
var rootUri = 'http://api.b.st-hatena.com/entry.count?url=http%3A%2F%2Fnicocas.com%2Fi%2Finfo%2F3';
var request = require('request').defaults({});
var cache_url = {}
function get_hatebu (callback) {
request.get(rootUri, function(err, response, body) {
if (err) {
console.log(err)
}
if (response.statusCode !== 200) {
console.log("internal error " + response.statusCode)
}
// put
put_cloudwatch(body, callback);
});
}
// メインハンドラ
exports.handler = function(event, context) {
console.log('Received event:' + Date.now());
console.log(JSON.stringify(event, null, ' '));
// Get the object from the event and show its content type
var bucket = event.Records[0].s3.bucket.name;
var key = event.Records[0].s3.object.key;
// set timeout
setTimeout(function() {
if(key == jobctl_key_name) {
s3.getObject({Bucket:bucket, Key:key},
function(err,data) {
if (err) {
console.log('error getting object ' + key + ' from bucket ' + bucket +
'. Make sure they exist and your bucket is in the same region as this function.');
context.done('error','error getting file'+err);
}
else {
var content_type = data.ContentType;
var body = data.Body.toString("utf-8");
if(body == 0) {
console.log('- start')
change_status(bucket, key, content_type, function(err){
if(err) {
console.log(err)
context.done("change_status error", err);
} else {
context.done(null, "");
}
});
} else if(body == 1) {
console.log('- runnning...')
change_status(bucket, key, content_type, function(err){
if(err) {
console.log(err)
context.done("change_status error", err);
} else {
get_hatebu(function(err, data){
if(err) {
console.log(err)
context.done("get hatebu error", err);
} else {
context.done(null, "");
}
})
}
});
} else {
console.log('- finish')
context.done(null, "- finish");
}
}
}
);
} else {
context.done(null, "");
}
}, interval);
};
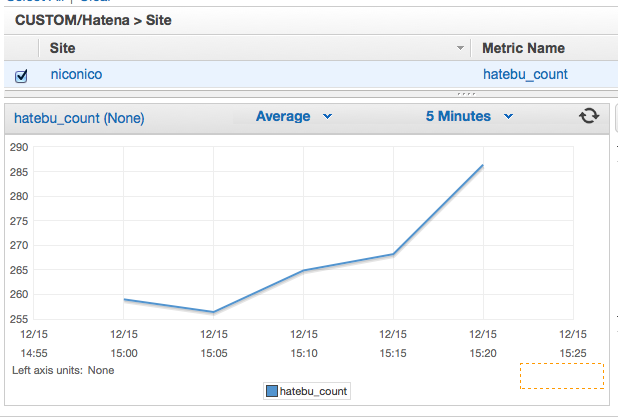
しばらく待つと…
おおー!きちんと自動でグラフ化されている!!!
注意点としては、CloudwatchへのIAMロールポリシーを設定する必要がありますので
忘れずに設定しておきましょう。
{
"Effect": "Allow",
"Action": ["cloudwatch:*"],
"Resource": ["*"]
}
まとめ
Lambdaをcronのように利用してみました。
応用例を見ても分かる通り 一切サーバを使わずにcronっぽいことを実現できている のがポイントですね。
今回のはかなり無理矢理感漂いますが、何かのヒントになれば幸いです。
しかしLambda、アイデアによってはおもしろい使い方ができて楽しいですね!
今後が楽しみ〜