JavaVM での可逆圧縮アルゴリズムの選定のためにいくつかのライブラリを集めてベンチマークを行った (ソースや数値は github で)。結果、圧縮アルゴリズムの個人的な認識は以下のようになった。
| アルゴリズム | タイプ | 適していると思われる用途 |
|---|---|---|
| Zstandard | 高圧縮率/低処理速度型 | ファイル単位のデータ保存やサーバ間の転送 |
| lz4 > Snappy | 低圧縮率/高処理速度型 | ストリーミング処理など高スループット/低レイテンシーが必要な局面 |
| bzip2 $\approx$ Brotli | 圧縮率最優先 | 巨大なデータ配布やコールドデータの保存 |
| gzip $\approx$ ZLib (ZIP) | 可搬性最優先 | データの受け渡しや長期保存 |
Java 標準の GZIP や Deflate (ZIP) に加えて以下のアルゴリズムを実装しているライブラリを使用した。それぞれの Maven リポジトリ ID はページ末リンクの build.sbt 参照。
- Zstandard: 圧縮率は gzip 以上 bzip2 未満だがそれらより有意に速い。既存の gzip はもちろん、数%のサイズ差が事業コストに跳ねるようなシビアな世界でなければ bzip2 も Zstd 化を検討する価値あり。レベルで調整可能。
- lz4: 圧縮率で Snappy と同等、速度面で Snappy より有利なため、処理速度優先なら lz4。
- Brotli: 高圧縮率勢の中でも頭一つ抜けることがある。圧縮と展開の速度差が大きく、展開速度は Zstd に劣るが gzip, bzip2 よりは速い。UTF-8 モードを使えばテキスト圧縮の効率は上がる (未確認)。
- Snappy: 高速度型だが速度面で lz4 に劣るため特に出番がなさそう。何らかの理由で lz4 が使えない時の振替手段と理解。
以下のベンチマークにおいて Block は各ライブラリが提供する byte[] to byte[] の API を使用したときの速度、Stream は Java で標準的な InputStream/OutputStream を使用した時の結果である。
テキストデータ圧縮
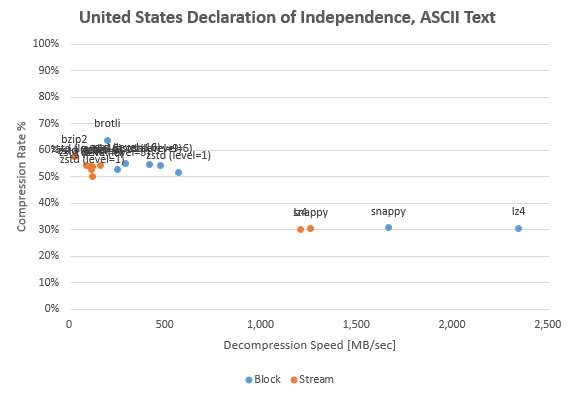
最初に紹介するのは米国独立宣言をサンプルバイナリとした圧縮処理結果。US-ASCII であるためすべてのバイト値が 0x00-0x7F に収まっておりエントロピーも低め。圧縮率は Brotli が最も高く処理速度は lz4 が最も高かった。
次は夏目漱石「こころ」全文をサンプルとして用いた結果。日本語の UTF-8 表現は 1 文字 3 バイトとなりパターンが冗長となるため us-ascii 文書より圧縮率は高い。
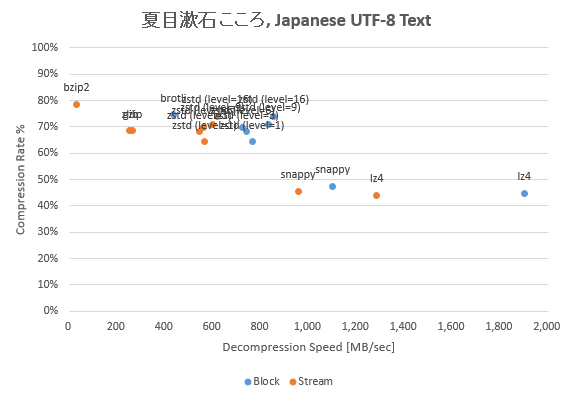
テキストデータに関しては高圧縮率型と高速度型の特性がはっきり出ている。なお Brotli には UTF-8 最適化モードがあるようだがこのベンチマークではバイナリ型との比較のため GENERAL モードを使用している。
数値データ圧縮
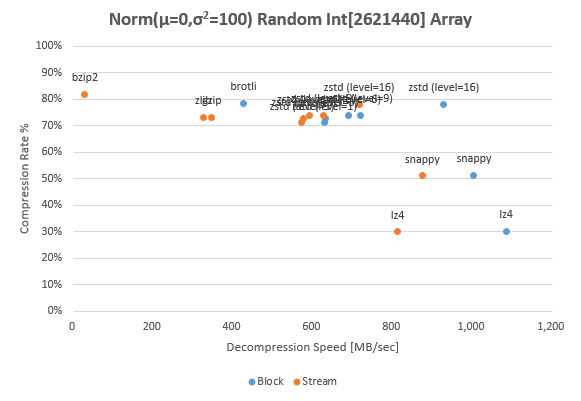
下の図は配列要素を正規乱数 $\lfloor {\rm Norm(\mu=0,\sigma^2=100)} \rfloor$ で初期化した int[] をビッグエンディアンでバイト配列化しサンプルバイナリとしたもの。つまり全配列要素の 68% が $\pm 10$ の範囲にあり、また 95% が $\pm 20$ の範囲に含まれている。言い換えれば、ほとんどの値が最下位 1 バイトを除いた 3 バイトが 0x00 または 0xFF となるバイト配列である。
このようなバイナリの圧縮率は高く、高圧縮率型で 70-80% 程度が削減されている。また速度面において高速型との差が縮むことから高速型の優位性は薄くなる。
下の図は標準正規乱数 ${\rm Norm(\mu=0,\sigma^2=1)}$ で値を生成した double[] を IEEE 754 形式でバイト配列化し圧縮サンプルとしたもの。浮動小数点型データに対しては高圧縮率型でも 5% 未満とほぼ圧縮効果は期待できない結果となった。実際、サンプルバイナリのエントロピーも高く、バイト配列としては各バイト値を一様乱数で生成したケースに近いように見える。
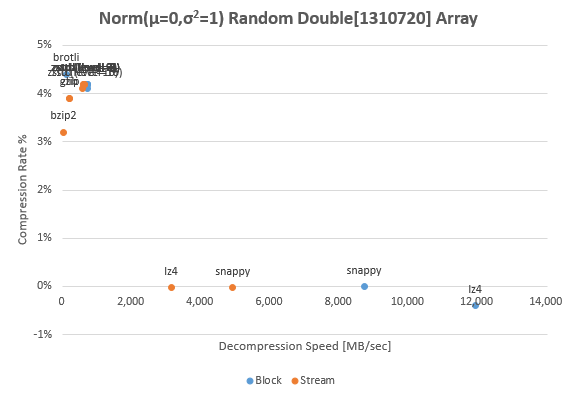
lz4 がマイナス値を取っているのは若干のサイズ増加があったことを示している。