業務において、テーブルに新規インデックスを貼るときに気をつけたポイントがありましたので、まとめておきます!
環境
MySQL 5.7系、ストレージエンジンInnoDB
この記事でわかること
- 今回インデックスを貼るときに気をつけたポイント
- 冗長なインデックスを探すSQL
インデックスを貼るときに気をつけたポイント
DBに詳しい人からしたら『もっと気をつけるべき点はあるぞ!』と思うのかもしれないですが、一旦、今回自分がインデックスを貼るときに気をつけた点です。
- バリエーションが少ないカラム(フラグ値など)に対するインデックスは利用シーンを考慮して要否を判断する
- 既存にあるインデックスで満たされているような冗長なインデックスを作ろうとしていないか
- 複合主キーなど長い主キーが使われている場合は代替キーを主キーにすることでインデックスの容量を減らせないか(若干テーブル設計寄りだが)
一つずつ見ていきましょう!
バリエーションが少ないカラムに対するインデックス
フラグ値(0,1)のようなバリエーションが少ない(カーディナリティの低い)カラムに対するインデックスは、むやみやたらと追加しても効果がない場合があります。
効果がある場合とない場合は以下の通りです。
⭕️ カラム値のほとんどが0であることが明らかで、1を探したいケース
❌ カラム値のほとんどが0であることが明らかで、0を探したいケース
このように、効果がある場合とない場合があることを理解したうえで、インデックスが必要かどうかを判断しないといけません。
今回自分が考えていたインデックスは❌のパターンでしたので、追加しないことにしました!
冗長なインデックスを作らない
例えば、以下のケースは冗長なインデックスに該当するでしょうか?
CREATE INDEX idx_no1 ON mytable (col1);
CREATE INDEX idx_no2 ON mytable (col1, col2);
col1,col2はそれぞれ主キーではないカラムとします
これは、idx_no1が冗長なインデックスと言えます!
というのも、『idx_no1がidx_no2に内包されているから』です。どういうことでしょうか?
例えば、以下のようなSQLを実行した場合
select * from mytable where col1 = xx;
idx_no2はcol1に対するインデックスが効いているので、idx_no1を使わずとも、idx_no2だけで十分だということです。
idx_no1のようなインデックスを単一インデックス、idx_no2のようなインデックスを複合インデックスと呼んだりしますが、複合インデックスを貼るときは、単一インデックスは削除しても構いません!
では、こちらのケースはどうでしょう!?
CREATE INDEX idx_no1 ON mytable (col1);
CREATE INDEX idx_no2 ON mytable (col2, col1);
これもidx_no1が冗長なインデックスでしょうか?
残念ながら、このケースはどちらも必要なインデックスになります。
先のSQLを例に取ると、
select * from mytable where col1 = xx;
idx_no1を削除してしまうと、 col1 を指定した検索へのインデックスが効かなくなるため削除してはいけません!
最初のケースと異なるのは、idx_no2のカラムの順番です。
idx_no2のインデックスが有効になるのは以下のケースです。
select * from mytable where col2 = xx;
select * from mytable where col1 = xx and col2 = xx;
兎にも角にも、複合インデックスを作るときはカラムの順番が大事ということを覚えておきましょう!!
冗長なインデックスを探すSQLは以下になります。
SELECT
i1.TABLE_NAME "テーブル名",
i1.TABLE_SCHEMA "テーブルスキーマ",
CONCAT(i2.INDEX_NAME, " INCLUDING ", i1.INDEX_NAME) "IDX1がIDX2に含まれています",
i1.INDEX_NAME "IDX1の名前",
i1.columns as "IDX1のカラム",
i2.INDEX_NAME "IDX2の名前",
i2.columns "IDX2のカラム"
FROM
(
SELECT
TABLE_SCHEMA,
TABLE_NAME,
INDEX_NAME,
GROUP_CONCAT(COLUMN_NAME ORDER BY SEQ_IN_INDEX) AS columns
FROM
`information_schema`.`STATISTICS`
WHERE
TABLE_SCHEMA NOT IN ('mysql', 'INFORMATION_SCHEMA')
AND NON_UNIQUE = 1
AND INDEX_TYPE = 'BTREE'
GROUP BY
TABLE_SCHEMA,
TABLE_NAME,
INDEX_NAME
) AS i1
INNER JOIN (
SELECT
TABLE_SCHEMA,
TABLE_NAME,
INDEX_NAME,
GROUP_CONCAT(COLUMN_NAME ORDER BY SEQ_IN_INDEX) AS columns
FROM
`information_schema`.`STATISTICS`
WHERE
INDEX_TYPE = 'BTREE'
GROUP BY
TABLE_SCHEMA,
TABLE_NAME,
INDEX_NAME
) AS i2
USING (TABLE_SCHEMA,
TABLE_NAME)
WHERE
i1.columns != i2.columns
AND LOCATE(CONCAT(i1.columns, ','), i2.columns) = 1;
冗長なインデックスを削除することでディスク容量を減らし、メモリ上にキャッシュされるレコード数が増えるため、結果としてパフォーマンス向上に繋がります!
長い主キー(複合主キーなど)を代替キーに変更してインデックス容量を減らす
若干テーブル設計に関わるところではありますが、インデックスに絡むところなので・・・
さて、なぜ長い主キーはインデックス容量的に良くないのでしょうか?
まずそれを理解する前にMySQLのインデックス用語を理解する必要があります。
MySQLはテーブルの主キーに必ずインデックスを貼ります。(=クラスタインデックス)
そして、主キー以外のカラムにインデックスを貼ったものをセカンダリインデックスと呼びます。
クラスタインデックスを使って検索されたら最速です。(主キーで検索されている訳なので直接レコードにアクセスできます)
では、セカンダリインデックスとはどういう動きで検索されるのでしょうか?
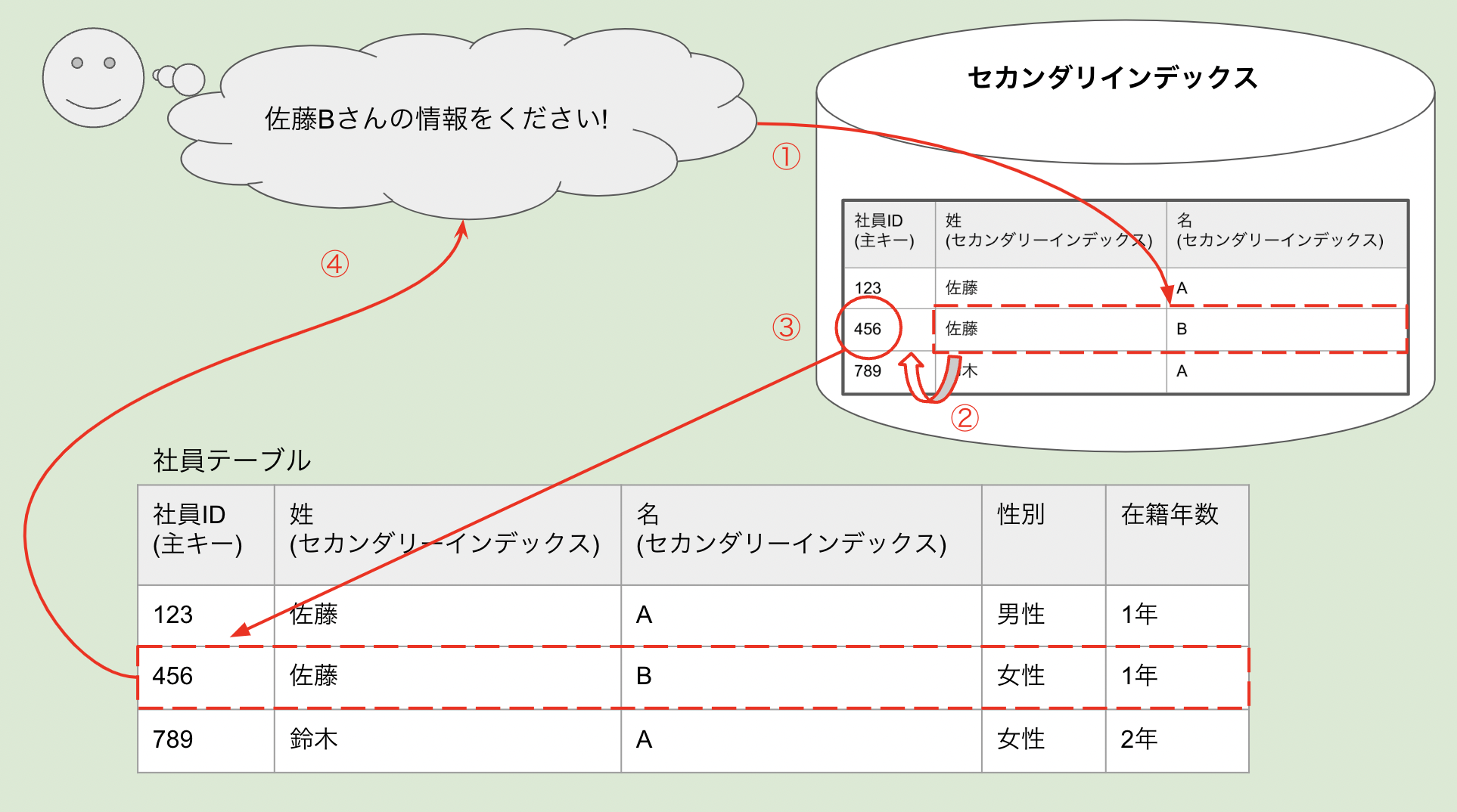
あくまでもイメージですが、ディスク領域にセカンダリインデックス領域があるとイメージしてください。
その中に、クラスタインデックス(主キー)+セカンダリインデックスで指定されたカラムからなるレコードが格納されています。
セカンダリインデックスのカラムを検索条件に検索された場合、条件に合致するレコードを見つけた後に、クラスタインデックス(主キー)が使われます。
セカンダリインデックス領域に主キーが含まれることがポイントです。
つまり、長い主キーであればあるほどインデックス容量が大きくなり(ディスク容量が大きくなる)予期せぬパフォーマンス低下を招くこともあり得ます!
複合主キーなどになっているテーブルは、主キーを代替キー(サロゲートキー)にすることで、インデックス容量を減らすことができます!
一般的に代替キーにはAUTO INCREMENTの数値型が利用されることが多いです。
参考:AUTO_INCREMENTを使う時に注意すること
こちらの記事にまとめています!